异常检测用于检测指标当前值是否偏离正常模式,或是区间。
一般情况下,可以把异常检测看成是数据不平衡下的分类问题。如果数据有标签,我们可以采用监督学习方法。如果数据部分有标签,我们可以采用半监督学习方法,如果数据完全没有标签,我们可以采用无监督学习方法。通常情况下,监督学习比无监督学习更加准确快速,所以在有条件的情况下,我们应该尽量使用有标签的数据。
无监督方法
1 概率统计方法
异常检测的统计学方法对数据的正常性做假定。假定数据集中的正常对象由一个随机过程(生成模型)产生。因此,正常对象出现在该随机模型的高概率区域中,而低概率区域中的对象是异常点。
异常检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。有许多不同方法来学习生成模型,一般而言,根据如何指定和如何学习模型,异常检测的统计学方法可以划分成两个主要类型:参数方法和非参数方法。
参数方法假定正常的数据对象被一个假定参数的分布产生。该分布的概率密度函数给出对象被该分布产生的概率。该值越小,越可能是异常点。非参数方法并不假定先验统计模型,而是试图从输入数据确定模型。非参数方法的例子包括直方图和核密度估计。
1.1 正态分布方法
正态分布是一种常见的分布,它基本上能描述所有常见的事物和现象:正常人群的身高、体重、考试成绩、家庭收入等等。就是说这些指标背后的数据都会呈现一种中间密集、两边稀疏的特征。以身高为例,服从正态分布意味着大部分人的身高都会在人群的平均身高上下波动,特别矮和特别高的都比较少见。在对数据进行正态性假设之后,我们可以用3σ等方法进行异常检测。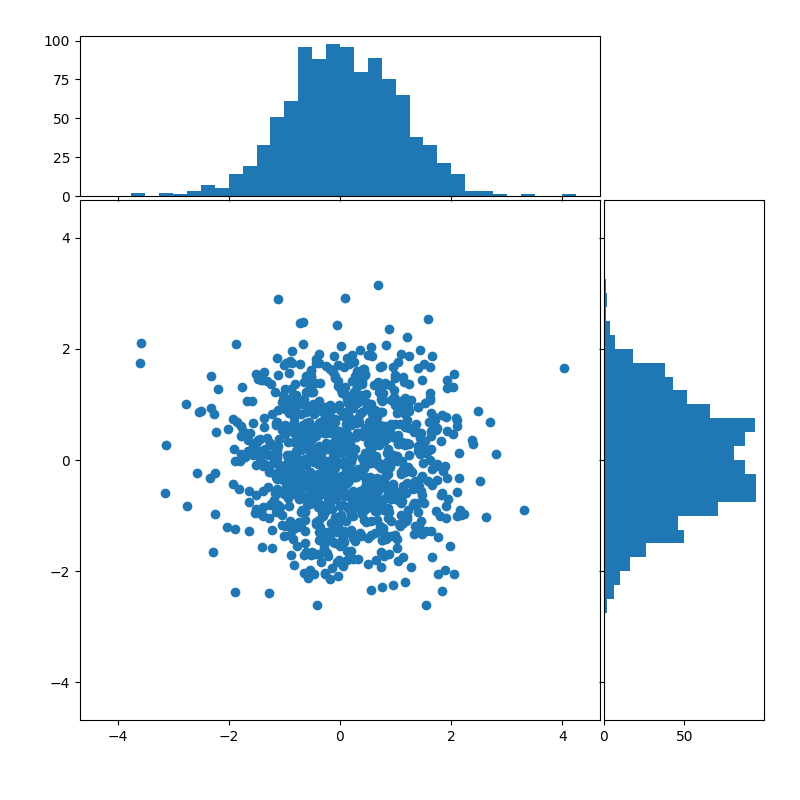
1.2 分位数方法
和3σ原则相比,箱线图依据实际数据绘制,真实、直观地表现出了数据分布的本来面貌,且没有对数据作任何限制性要求(3σ原则要求数据服从正态分布或近似服从正态分布),其判断异常值的标准以四分位数和四分位距为基础。四分位数给出了数据分布的中心、散布和形状的某种指示,具有一定的鲁棒性,即25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值通常不能对这个标准施加影响。鉴于此,箱线图识别异常值的结果比较客观,因此在识别异常值方面具有一定的优越性。
箱型图提供了识别异常值的一个标准,即异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。其中,QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小;QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大;IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。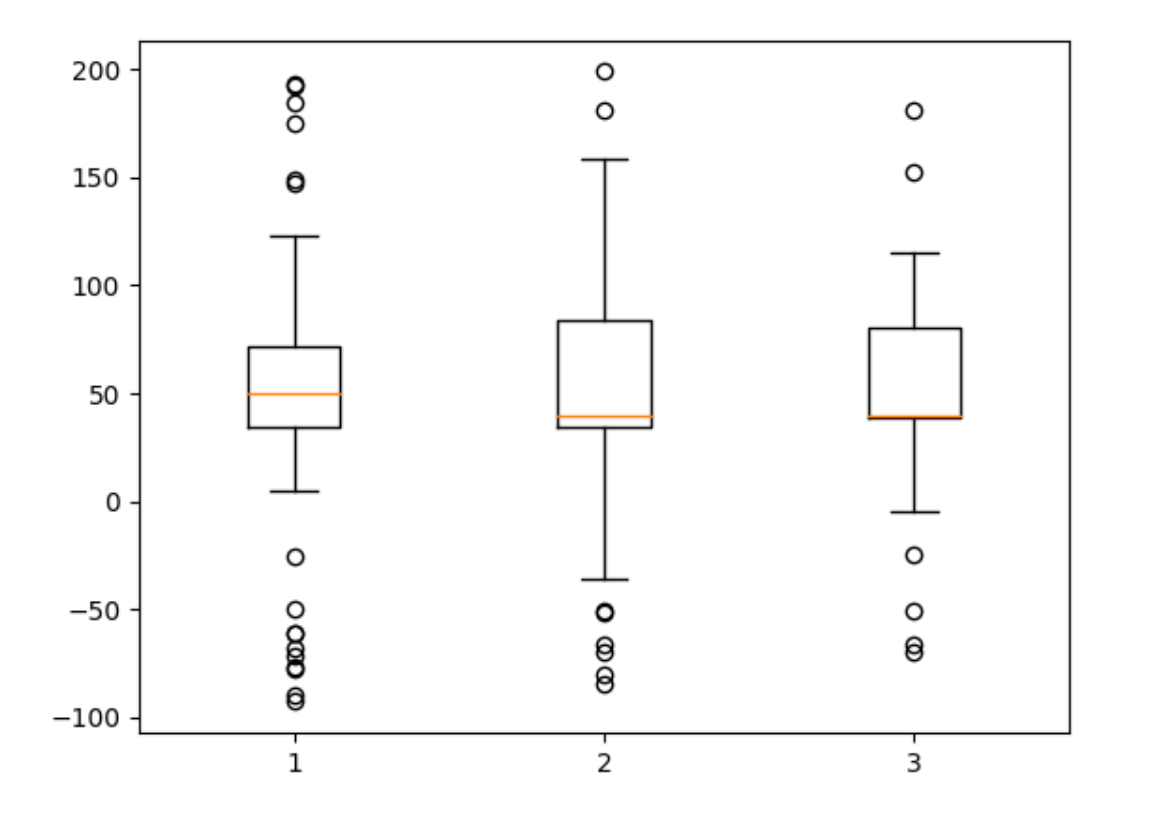
2 基于邻近性的方法
给定特征空间中的对象集,可以使用距离度量来量化对象间的相似性。基于邻近性的方法假定:异常点对象与它最近邻的邻近性显著偏离数据集中其他对象与它们近邻之间的邻近性。有两种类型的基于邻近性的异常点检测方法:基于距离的和基于密度的方法。基于距离的异常点检测方法考虑对象给定半径的邻域。一个对象被认为是异常点,如果它的邻域内没有足够多的其他点。基于密度的异常点检测方法考察对象和它近邻的密度。这里,一个对象被识别为异常点,如果它的密度相对于它的近邻低得多。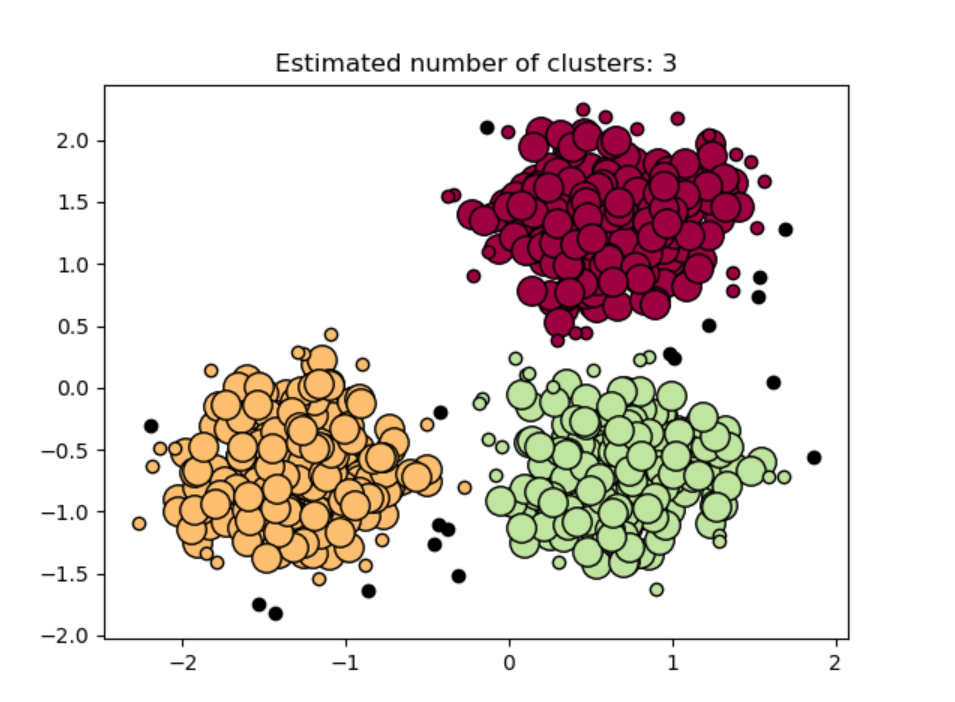
有监督方法
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。简单来说,就像有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。监督学习中的数据中是提前做好了分类信息的, 它的训练样本中是同时包含有特征和标签信息的。常用的监督学习方法有逻辑回归,决策树,支持向量机等都。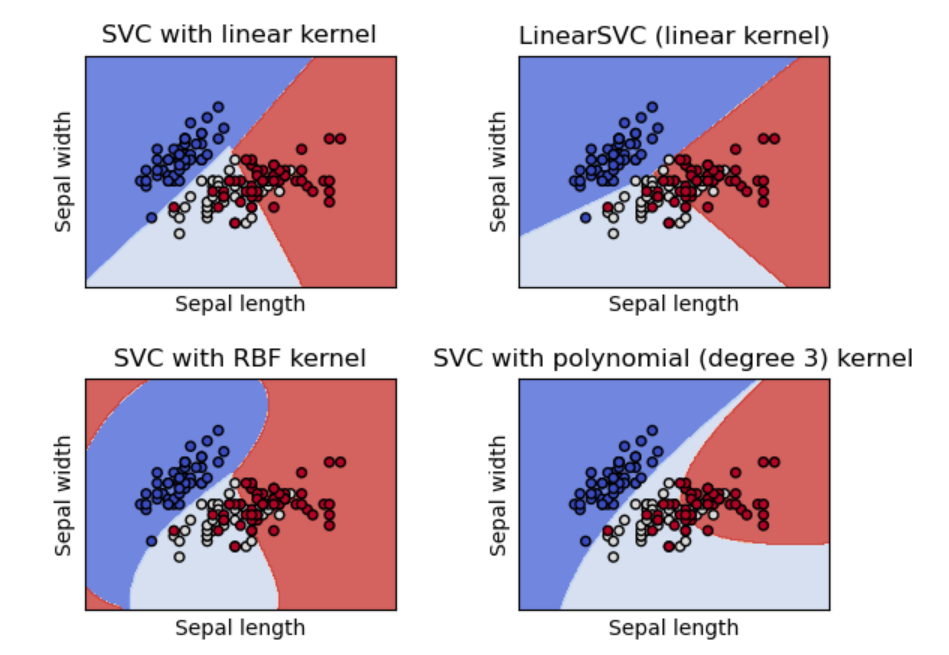

若有收获,就点个赞吧
0 人点赞
