数据可视化,是处理数据最后的关键一步,用图形方式从大量数据中压缩信息。
数据分析结果最终需要为人所用,每个人对数据的理解能力和角度各不相同,可视化有助于降低数据理解门槛。
相比直接看数据表格,图表可以包含更多信息量,也更能直接体现数据间的关系。
Python的可视化模块非常多,按实现方式可以分为2类:
- 原生Python:如
matplotlib、seaborn。 - JavaScript封装:如
pyecharts、plotly。
模块安装:pip install matplotlib seaborn plotly。
从实战角度看,原生类模块更适合应用在分析过程中,通过查看图表辅助分析;
JavaScript封装类的模块,视觉渲染效果更佳,更适合用于输出最终报告图表。
但不管采用何种模块或软件,可视化最关键的两步:理解数据、选对图例。pandas内置了matplotlib模块基础功能,方便开箱使用。
Matplotlib
在上一节数据分析基础上,可以用柱状图、折线图、面积图、饼图这4个基本图表直观地理解数据: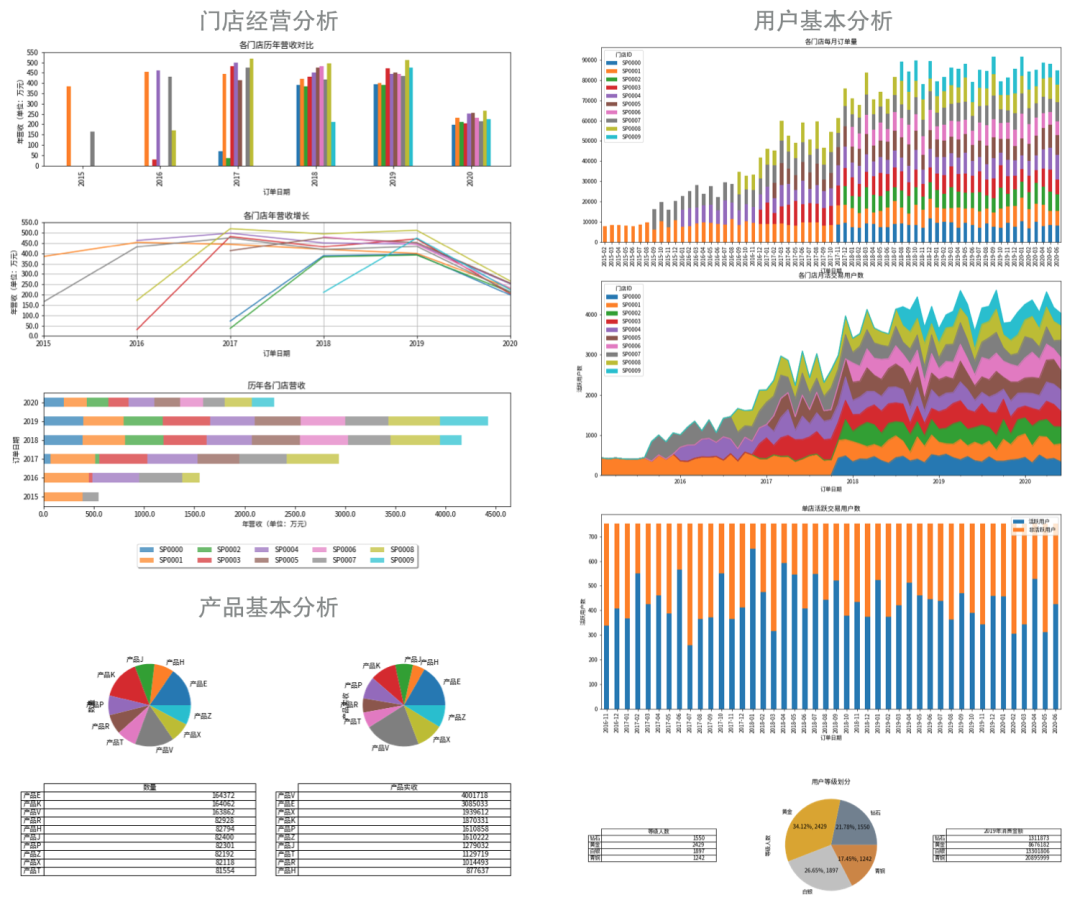
在Notebook中,调用数据对象的plot方法后就可以看到数据的图表。
pandas自带图例种类不是很多,都是最基本如柱状图、饼图、折线图、箱线图等。
如果涉及到更复杂绘图,或需要配置格式、生成多图表集等,就需要用到matplotlib更多功能。
通用的绘制流程有3个步骤:
- (可选)创建图表的图像容器:
Figure对象; - (可选)设置
x和y轴特征,比如单位、格式、标签等; - 调用
DataFrame或Series对象的plot方法开始绘图。
比如上面案例中关于门店分析的图表集:
import numpy as npimport pandas as pdimport matplotlibimport matplotlib.pyplot as pltimport matplotlib.dates as mdatesfrom pandas.plotting import table# 设置中文显示matplotlib.rcParams['font.sans-serif'] = ['Source Han Sans CN']matplotlib.rcParams['font.family']='Source Han Sans CN'matplotlib.rcParams['axes.unicode_minus'] = False# 门店分析df_shop = pd.read_excel('sample_SP0000.xlsx')df_shop_ym = df_shop.resample('A').sum().to_period('A')['实付']df_shops_ym = df_shops.reset_index().groupby([pd.Grouper(key='订单日期',freq='A'),pd.Grouper(key='门店ID')])['实付'].sum().unstack('门店ID').to_period('A')# 开始绘图fig = plt.figure(figsize=(12, 12))plt.subplots_adjust(wspace=0.5,hspace=0.5)ax1 = fig.add_subplot(311) # 从3x1矩阵的图集中返回第1个位置ax2 = fig.add_subplot(312)# 从3x1矩阵的图集中返回第2个位置ax3 = fig.add_subplot(313)# 从3x1矩阵的图集中返回第3个位置# 图1ax1.set_xlabel('年份')ax1.set_ylabel('年营收(单位:万元)')ax1.set_title('各门店历年营收对比')# 用FixedFormatter定义轴刻度ax1.yaxis.set_major_formatter(plt.FixedFormatter(np.arange(0,600,step=50)))df_shops_ym.plot(ax=ax1, kind='bar', legend=False, yticks=(np.arange(6000000,step=500000)))# 图2ax2.set_xlabel('年份')ax2.set_ylabel('年营收(单位:万元)')ax2.set_title('各门店年营收增长')# 用自定义函数定义轴刻度ax2.yaxis.set_major_formatter(plt.FuncFormatter(lambda x,p: f'{x/10000}'))df_shops_ym.plot(ax=ax2, kind='line', grid=True, legend=False, yticks=(np.arange(6000000,step=500000)))# 图3ax3.set_xlabel('年营收(单位:万元)')ax3.set_ylabel('年份')ax3.set_title('历年各门店营收')ax3.xaxis.set_major_locator(plt.MultipleLocator(5000000))ax3.xaxis.set_major_formatter(plt.FuncFormatter(lambda x,p: f'{x/10000}'))df_shops_ym.plot(ax=ax3, kind='barh',stacked=True, alpha=0.7)# 统一显示图例ax3.legend( loc='upper center', bbox_to_anchor=(0.5, -0.3),fancybox=True, shadow=True, ncol=5)
matplotlib功能很强大,可以通过组合绘制出几乎任何图形。
但它提供的现成图例相对有限,更多图例需要通过自定义代码实现。
绘制一些较新图例,或者调整风格,都需要额外花不少时间。
对于数据分析工作而言,我们需要更“高级”的模块。
Seaborn增强
seaborn模块是matplotlib的高级API封装,可以用更少代码绘制更美观的图表。
两者常被一起使用,比如,用seaborn可以轻松设置绘图格式:
import matplotlib.pyplot as pltimport seaborn as sns# 设置场景、主题、风格sns.set(context='notebook', style='darkgrid', palette='coolwarm_r')# 设置中文plt.rcParams['font.sans-serif'] = ['Source Han Sans CN']plt.rcParams['font.family']='Source Han Sans CN'plt.rcParams['axes.unicode_minus'] = Falseax = df_shops_ym.plot(kind='bar', stacked=True, figsize=(12,12))ax.set_xlabel('年营收(单位:百万元)')
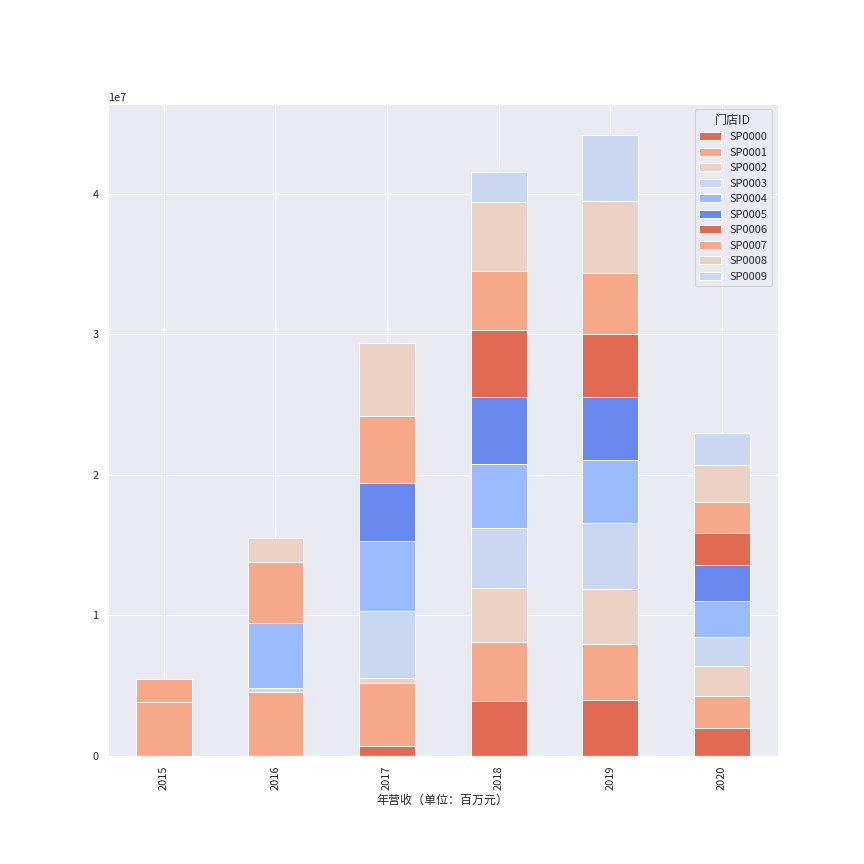
生成的图表会更美观,可以省不少调样式时间。
此外,seaborn也提供了更多图例绘制API,共分5大类:关系型、分布型、分类型、回归型、矩阵型。
不同类别的API适用于不同分析场景,如观察数据维度间关系、数据分布、线性回归、聚集度等。
比如可以用热力图观察用户的产品喜爱度:
df_shopsa = df_shops.reset_index().merge(df_shopsx, on='订单ID', suffixes=['_总订单','_单项产品'])df_user_prod_n = df_shopsa.pivot_table(index='用户ID',columns='产品',values='数量', aggfunc=np.sum).fillna(0)f, ax = plt.subplots(figsize=(20,20))sns.heatmap(df_user_prod_n)
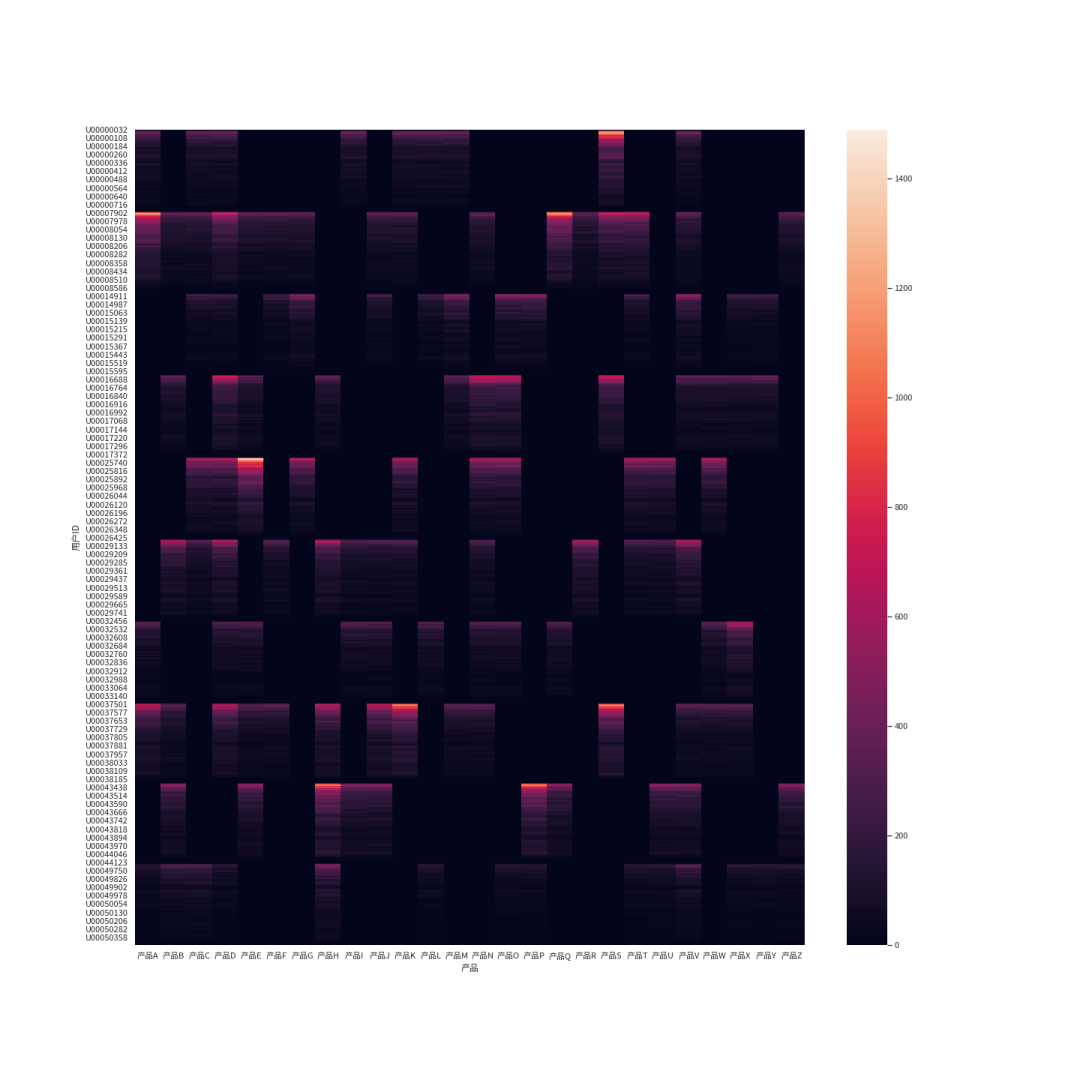
热力图颜色越浅表示用户经常下单,更喜欢某个产品。
可以用聚集图方便观察各门店历年来各月订单量:
grp_orders = df_shops.reset_index().groupby([pd.Grouper(key='订单日期',freq='M'),pd.Grouper(key='门店ID')])df_orders_year_shop = grp_orders['订单ID'].count().unstack('门店ID').to_period('M').fillna(0).astype('int')sns.clustermap(df_orders_year_shop, figsize=(20,20))
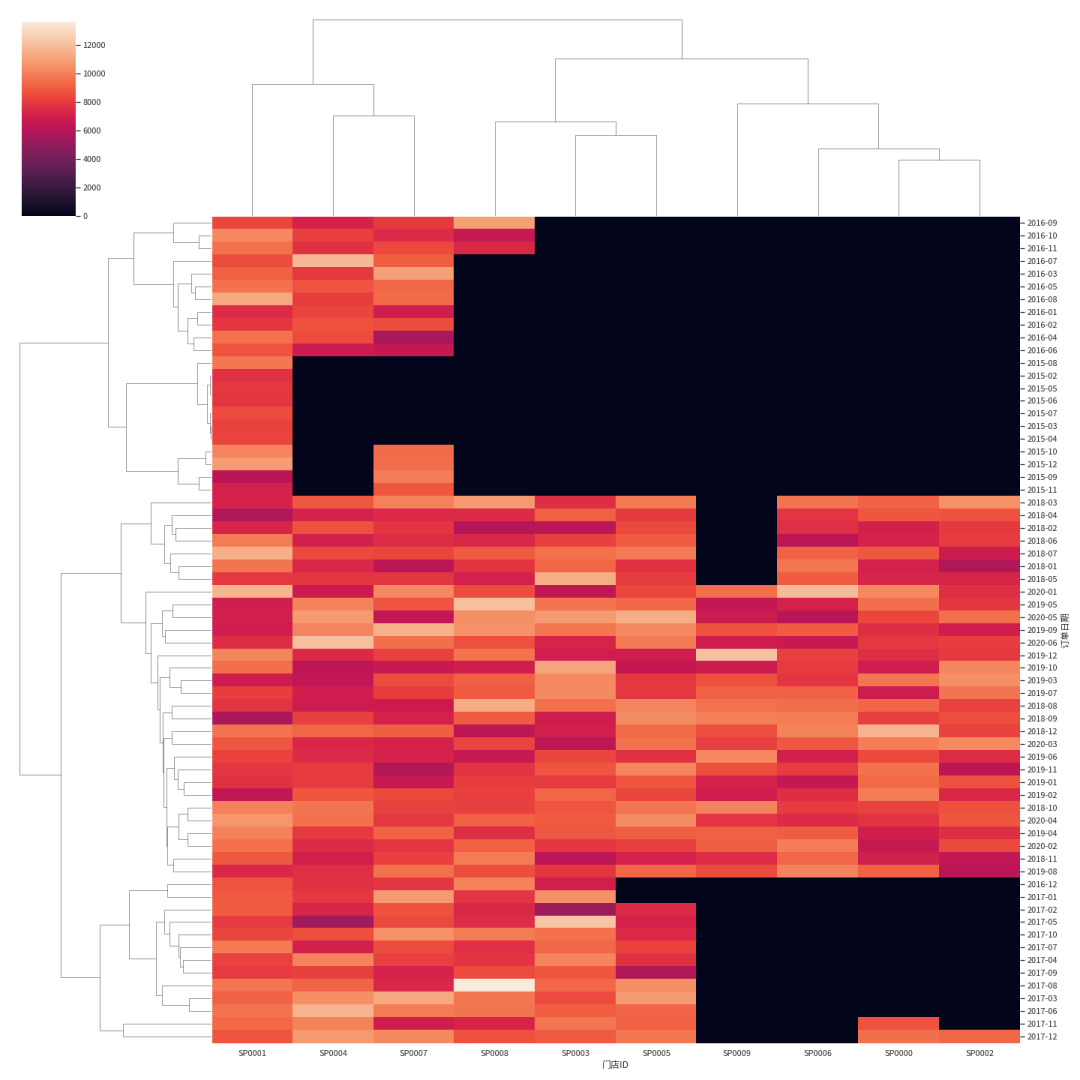
黑色表示所在时间段还未开店,颜色越淡说明越“旺”。
通过查表就知道:每个月订单量较多/少的是哪些门店,以及各门店在哪些月份订单量较多/少。
seaborn还提供了PairGrid和FacetGrid、JointGrid等组图功能,帮助快速观察不同变量对数据影响。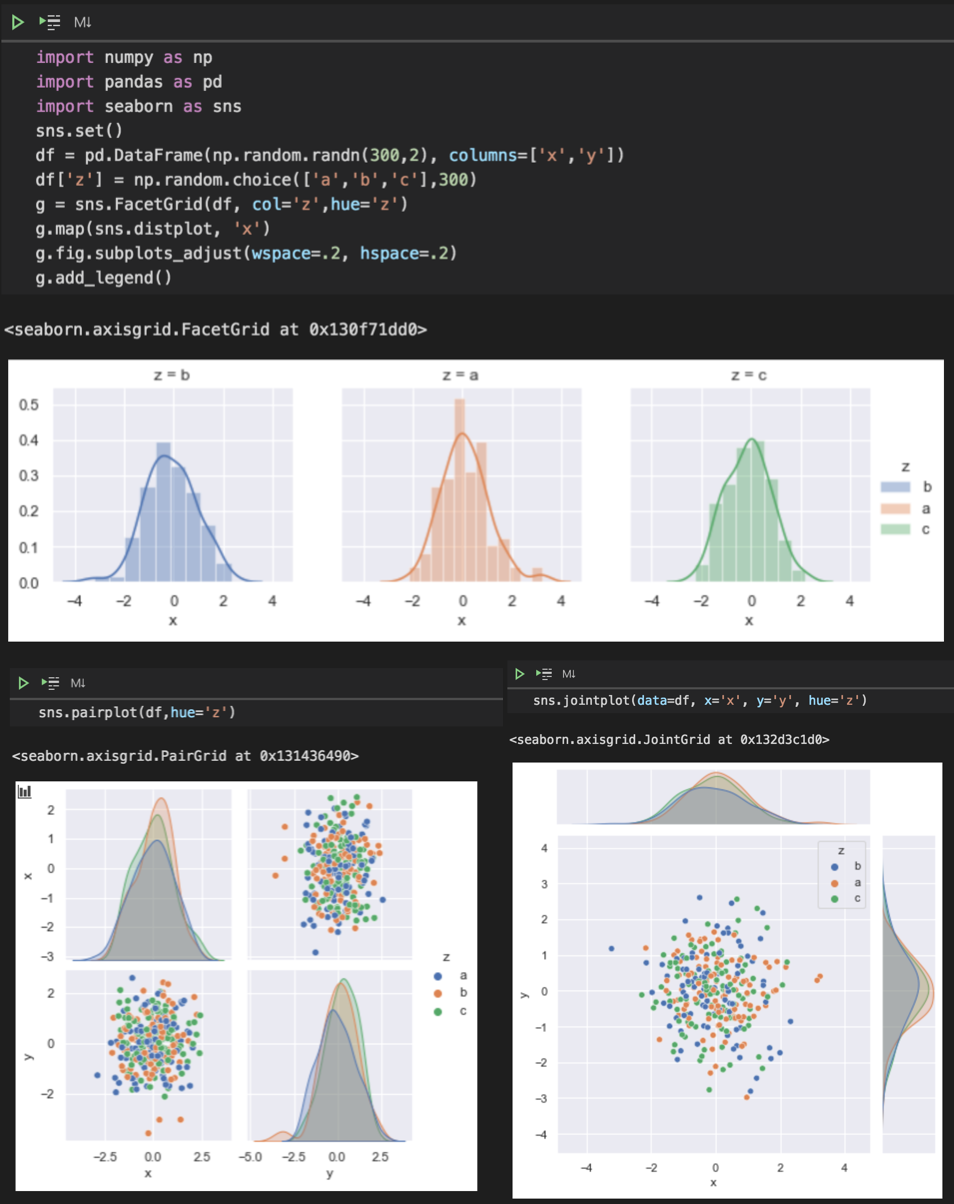
matplotlib提供了底层强大的绘图能力,而seaborn则补充了更多分析类的绘图API。
通过综合应用matplotlib和seaborn,基本已能够满足日常数据分析需求。
但如果需要输出更丰富的图例,比如漏斗图、桑基图等,可以借助三方模块。
Plotly另一种选择
seaborn只是matplotlib的一种增强补充,plotly则是一种替换选择。plotly底层基于plotly.js,一个基于d3js的JavaScript模块,由Python封装成API。
相比前两者,plotly包含更丰富图例和效果,如3D、可交互、动画等,其中plotly.express子模块更是提供了快速绘图的高级API。
支持Pandas
pandas从0.25版本开始支持指定内置绘图功能的引擎,装好plotly后,可以把pandas的绘图后端指定为plotly。
import pandas as pdpd.options.plotting.backend = 'plotly'# 之前统计的各门店年营收数据df_shops_ym.to_timestamp().plot(kind='bar')
在Notebook中,相比matplotly绘制的静态图形,plotly还支持更多交互操作: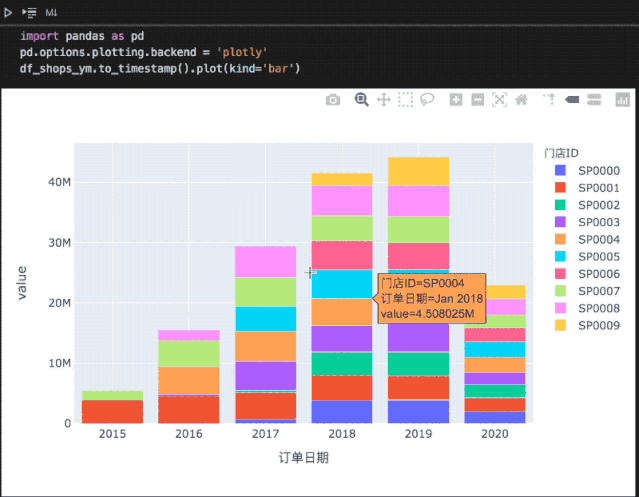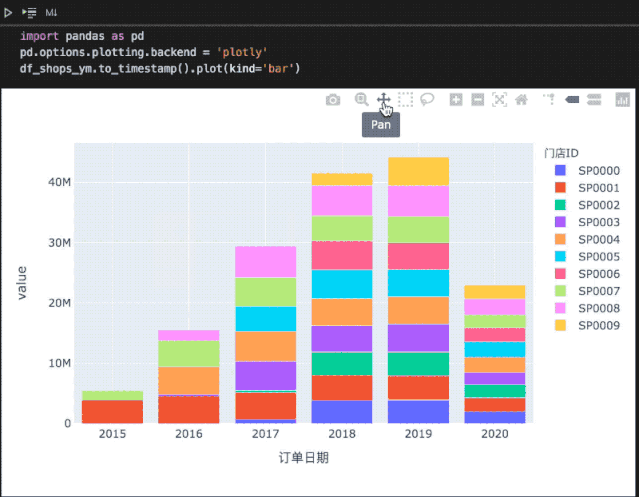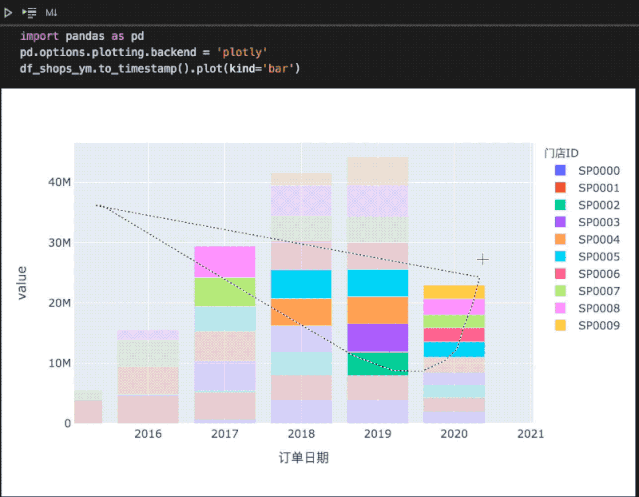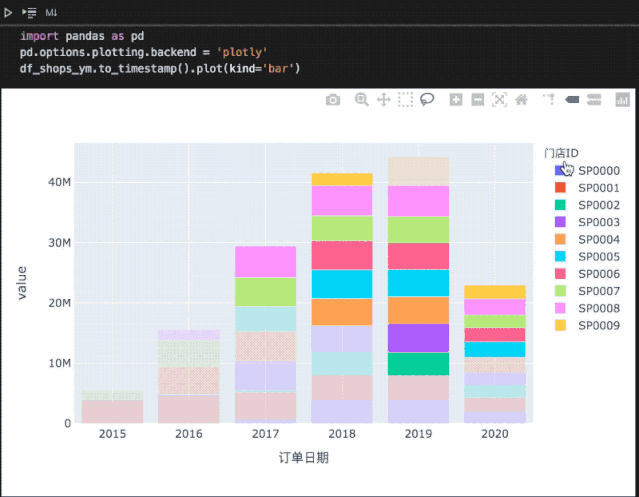
但是,在调用绘图API时,plotly会和matplotly使用不完全一样的参数,即之前绘制的图表如果需要转为plotly后端,需要做一定修改。
用户等级分类:饼图
比如目前还无法直接在pandas中生成饼图,需要使用plotly的API:
import plotly.express as pxfig = px.pie(title='用户等级',color=s_ucs.index,names=s_ucs.index, values=s_ucs.values,color_discrete_map={'钻石':'slategrey','黄金':'goldenrod','白银':'silver','青铜':'peru'})fig.update_traces(hole=.4)# 导出绘图数据fig.write_html('pie_plotly.html')fig.write_image('pie_plotly.png') # 导出pngfig.write_image('pie_plotly.pdf') # 导出pdffig.to_dict() # 转dict数据格式fig.to_json() # 转JSON数据格式img = fig.to_image(format='png') # 转图像数据
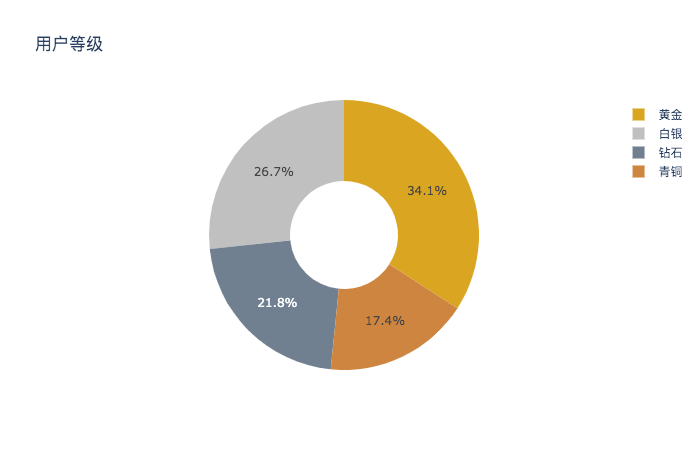
不管是通过pandas内的plot,还是通过poltly.express的API,调用绘图后都会返回plotly的Figure对象,可以把它保存为网页或各种图片类型,或者转为其他数据格式。
分析过程中也可以借助plotly丰富的图例来理解数据。
门店级用户等级划分:多级饼图
除了观察全部门店的用户等级,也可以细粒度到每个门店:
# 用户ID、门店ID、等级、数量df_users_RFM['等级'] = df_users_ym['等级']# 各门店各用户等级数量统计df_shop_ulvs = df_users_RFM.groupby([pd.Grouper(key='门店ID'),pd.Grouper(key='等级')])['R'].count().reset_index()df_shop_ulvs.columns = ['门店ID', '等级', '数量']fig_shop_ulvs = px.sunburst(df_shop_ulvs, path=['门店ID', '等级'], values='数量',color='数量', hover_data=['数量'])
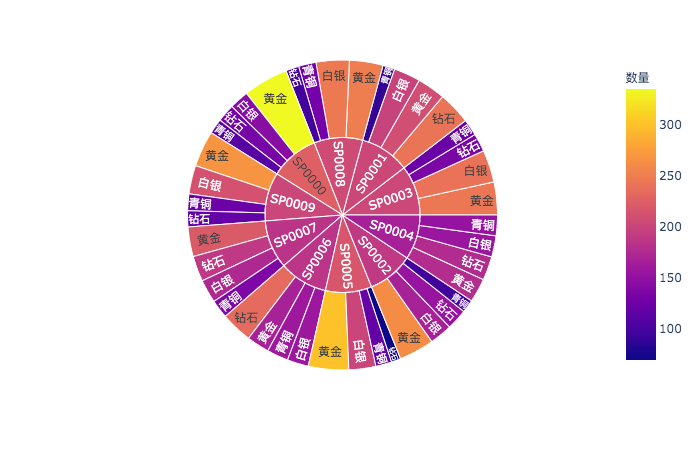
用户产品偏好:气泡图
分析用户对产品的偏爱度,除了用上面的热力图外,也可以用气泡图:
# 把之前的透视表数据转为3列:用户ID、产品、数量df_user_prod_n_flat = df_user_prod_n.stack('产品').reset_index()df_user_prod_n_flat.columns = ['用户ID', '产品', '数量']# 筛选100名钻石用户df_user_diamond_100 = df_user_prod_n_flat[df_user_prod_n_flat['用户ID'].isin(df_users_ym[df_users_ym['等级']=='钻石'].index[:100])]fig = px.scatter(df_user_diamond_100, x='产品', y='用户ID',size='数量',color='产品',hover_name='用户ID',size_max=60)
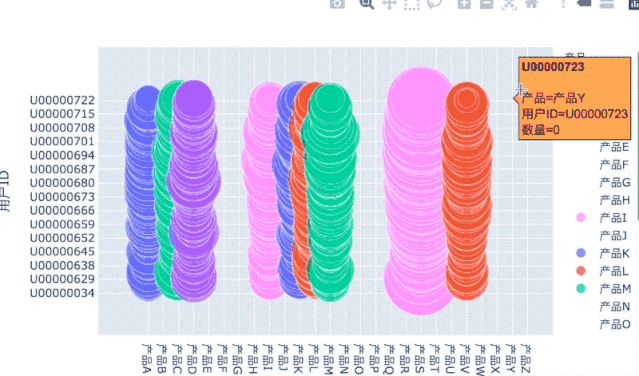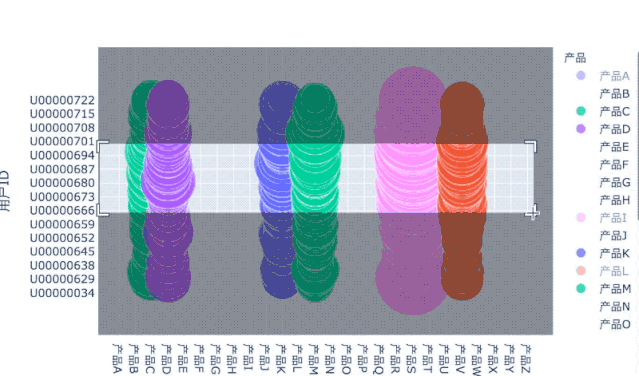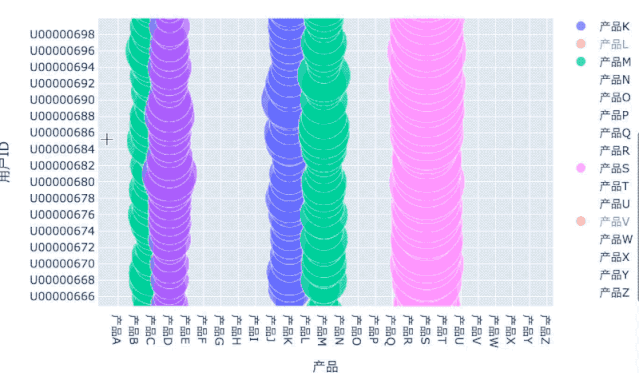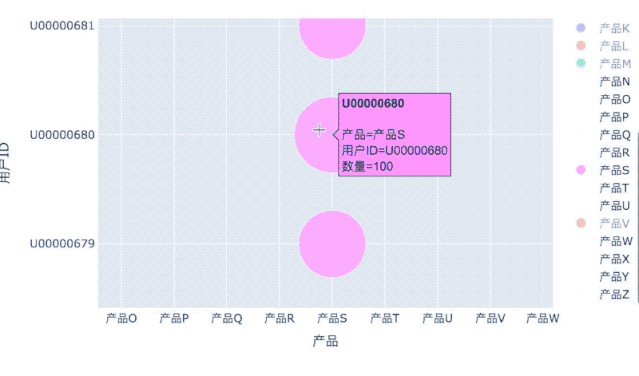
交互式的操作可以更方便地观察数据,包括切换宏观和微观视角。
RFM模型分析:3D散点图
用3D散点图来呈现RFM模型:
# 最近一次消费时间s_user_last = df_shops.sort_index().reset_index().groupby('用户ID')['订单日期'].last()today = pd.to_datetime('2020-07-01') # 数据最后时间time_delta_list = [pd.Timedelta(days=d*30) for d in [70,18,12,6,3,1,0]]# 按最后消费时间分级映射: A:最近30天内消费、B:90天、C:180天、D:360天、E:540天、F:540天外R = pd.cut(s_user_last,bins=[today-dt for dt in time_delta_list],labels=['F','E','D','C','B','A'])# 用户ID、门店ID、R、F、Mdf_users_RFM = pd.DataFrame({'门店ID':df_shops['2019'].groupby('用户ID')['门店ID'].first(),'R':R,'F':df_shops['2019'].groupby('用户ID')['订单ID'].count(),'M':df_shops['2019'].groupby('用户ID')['实付'].sum()}).dropna() # 排除2019年后未消费过的,或2020后才进来的新用户fig_RFM = px.scatter_3d(df_users_RFM, x='R', y='F', z='M',color='门店ID')

历年各门店经营统计:树图
TreeMap图例可以方便查看层次结构数据,比如我们可以把全国所有门店按年份和区域组织起来观察。
# 年份、门店ID、年营收、区域、年订单量、年消费用户数# 给门店假设一些分类:如地理分区华中、华北、华南shop_area = {'SP0000':'华南区', 'SP0001':'华南区','SP0002':'华南区','SP0003':'华中区', 'SP0004':'华中区','SP0005':'华中区','SP0006':'华北区', 'SP0007':'华北区','SP0008':'华北区','SP0009':'华北区'}# 各门店年营收,转Series格式s_shops_ym = df_shops_ym.stack('门店ID')# 各门店年订单量s_shops_yo = df_shops.reset_index().groupby([pd.Grouper(key='订单日期',freq='A'),pd.Grouper(key='门店ID')])['订单ID'].count().unstack('门店ID').to_period('A').stack('门店ID')# 各门店年消费用户数s_shops_yu = df_shops.reset_index().groupby([pd.Grouper(key='订单日期',freq='A'),pd.Grouper(key='门店ID')])['用户ID'].apply(lambda x: x.unique().size).unstack('门店ID').to_period('A').stack('门店ID')df_shops_ysum = pd.DataFrame({'年营收':s_shops_ym,'年订单量':s_shops_yo,'年消费用户数':s_shops_yu})df_shops_tree = df_shops_ysum.reset_index()df_shops_tree.columns = ['年份','门店ID','年营收','年订单量','年消费用户数']df_shops_tree['区域'] = df_shops_tree['门店ID'].apply(lambda x: shop_area[x])fig_shop_tree = px.treemap(df_shops_tree, path=[px.Constant('全国品牌'), '年份', '区域','门店ID'], values='年营收',color='年营收', hover_data=['年订单量','年消费用户数'])
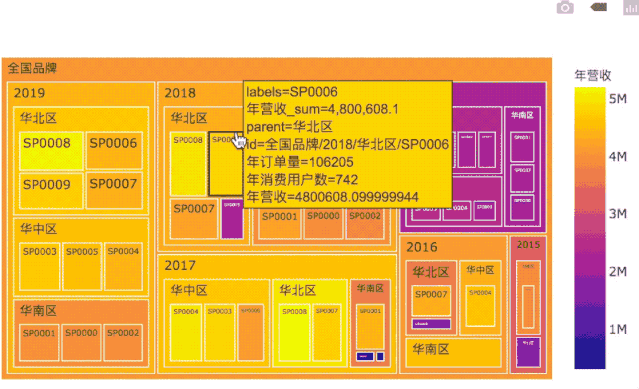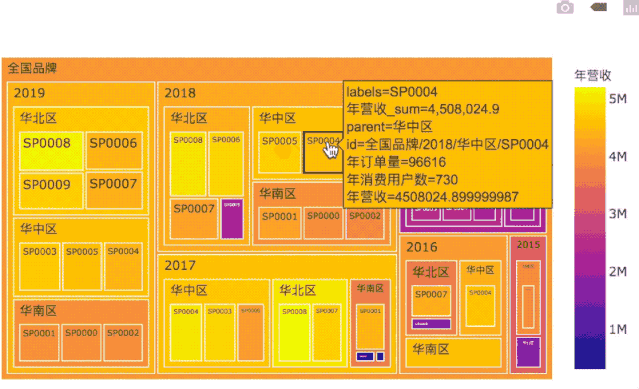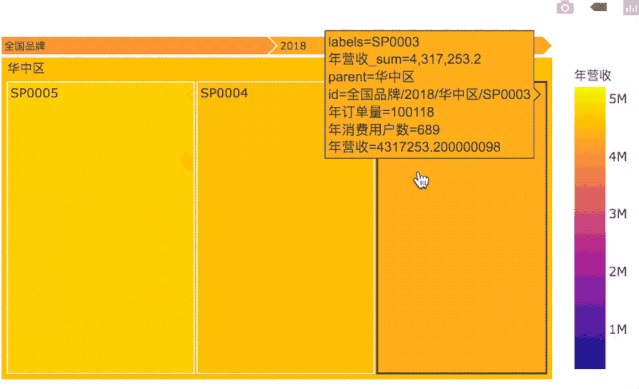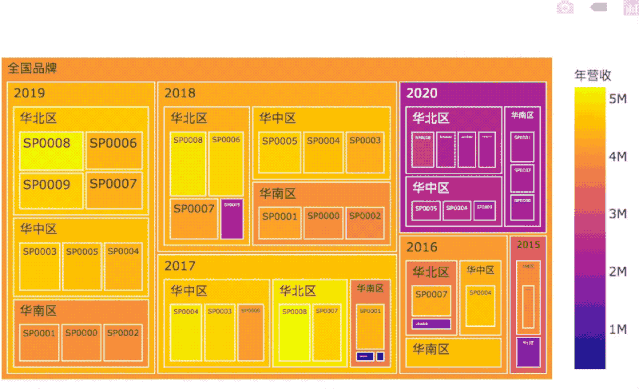
TreeMap是一个自顶向下快速观察数据的工具:
通过色彩深浅,可以快速判断各年份、各区域、各门店的业绩高低。
鼠标悬停在某个板块时,还可以观察板块总业绩,以及门店级用户量、订单量等相关细节数据。
其他实用图例
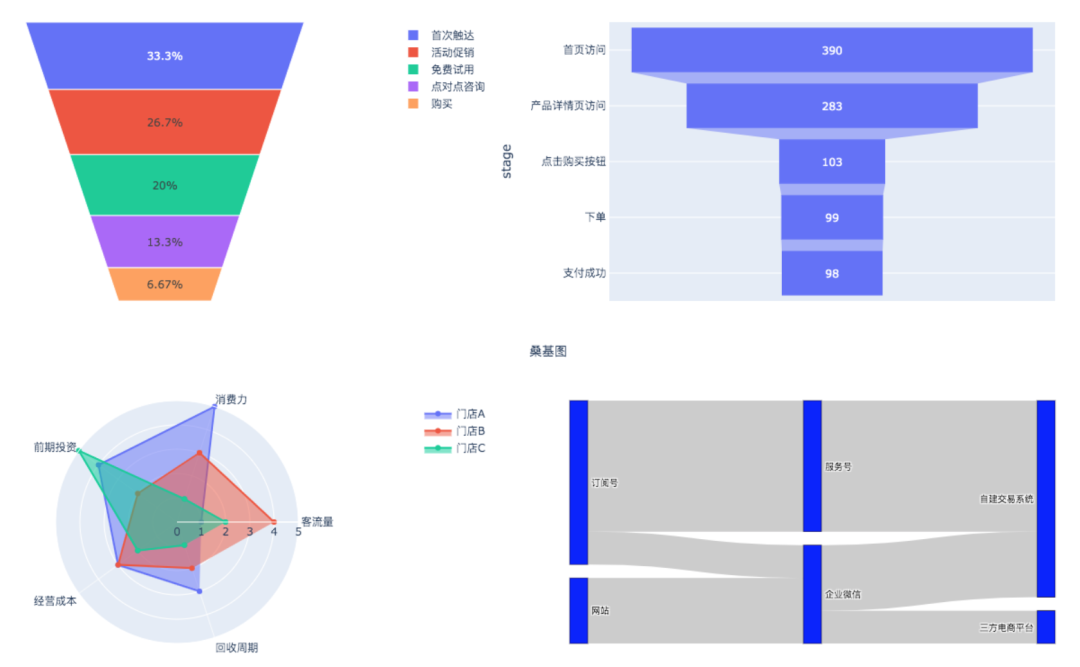
此外,plotly还有更多实用图例,比如:
- 漏斗图(
funnel):如观察用户从访问网站到下单购买的转化率; - 桑基图(
sankey):观察流量流向趋势,识别其中主要路径; - 雷达图(
Scatterpolar):如从客流量、成本、投资等多因素综合评估门店。
以上主要介绍了用plotly的express子模块快速绘图,其实plotly还有更多强大功能,比如:
subplots多图绘制,可以合并多图表实现自定义dashboard或工作面板;用
graph_objects绘图时可加入自定义按钮,实现更灵活的数据交互功能。
总结
本文介绍了Python可视化的3个模块,其中
matplotlib基本功能内置于pandas中,可以开箱使用;seaborn基于matplotlib补充了更多辅助分析的高级API;plotly则提供了更丰富的可交互式图例,也便于发布最终分析成果。
三个模块可以在不同场景下互补应用。
学习时,关键不是记住所有绘图命令,而是理解图例的适用场景。绘图时,能想起哪个图例能更好表达数据;
- 分析时,知道用哪些个图例帮助理解数据。
这才是数据可视化的意义所在。
扫码加入学习群,前100名免费。


若有收获,就点个赞吧
0 人点赞
