前两节内容已介绍如何清理数据,以及常用的分析模型。
本文会重点介绍pandas分析功能应用,包括:
多层索引、结构重塑、合并关联、交叉透视、分组聚合、时间序列。
然后以一个完整门店型业务项目,演示如何应用功能完成数据分析任务。
行和列的多层索引
在介绍功能前,先通过案例快速理解一个关键概念:多层索引。
在新媒体运营工作中,我们需要记录每篇文章的阅读量,而阅读量主要由标题和发送渠道有关。
我们可以用两种形式来记录数据: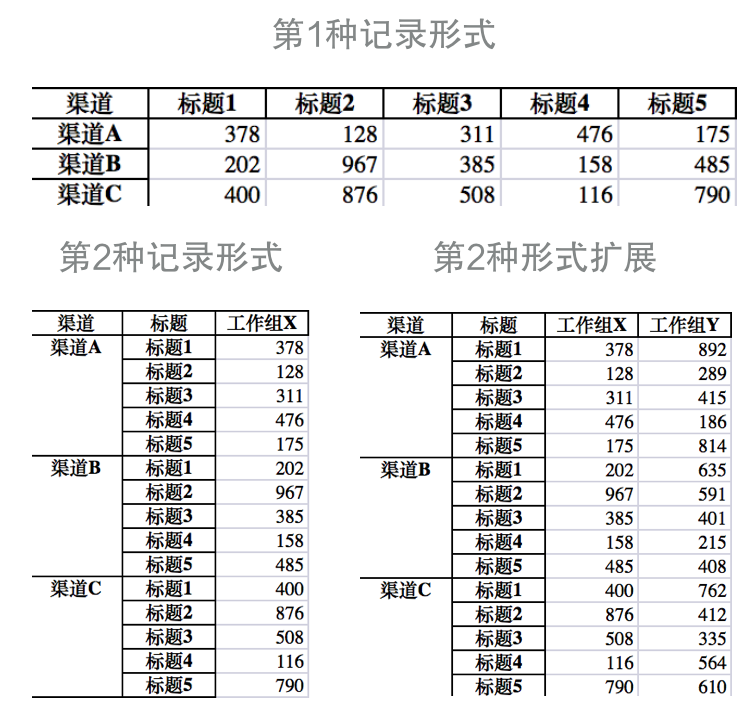
其中第1种更简洁,也经常是首先;第二种比较臃肿,标题名被重复记录。
但如果在此基础上,增加工作组维度,即X、Y、Z三个组分别做同样的事,该如何记录?
第1种形式中已经无法用单个表格表示,只能增加第2、第3张表来表示不同工作组;
但第2种形式可以完美解决,只需要增加一列“工作组”即可,如上图右下所示。
如果再想增加更多维度,比如增加多个自媒体账号;或者想再增加更多数据,比如点赞和转发等,该如何记录呢?
可以参考第2种形式,把工作组和账号从列改成行,用3列记录阅读、点赞、转发数据;
也可以把现有列扩充成2个维度:工作组和账号,一个工作组下分为多个账号,然后在各个账号下增加阅读、点赞、转发的数据。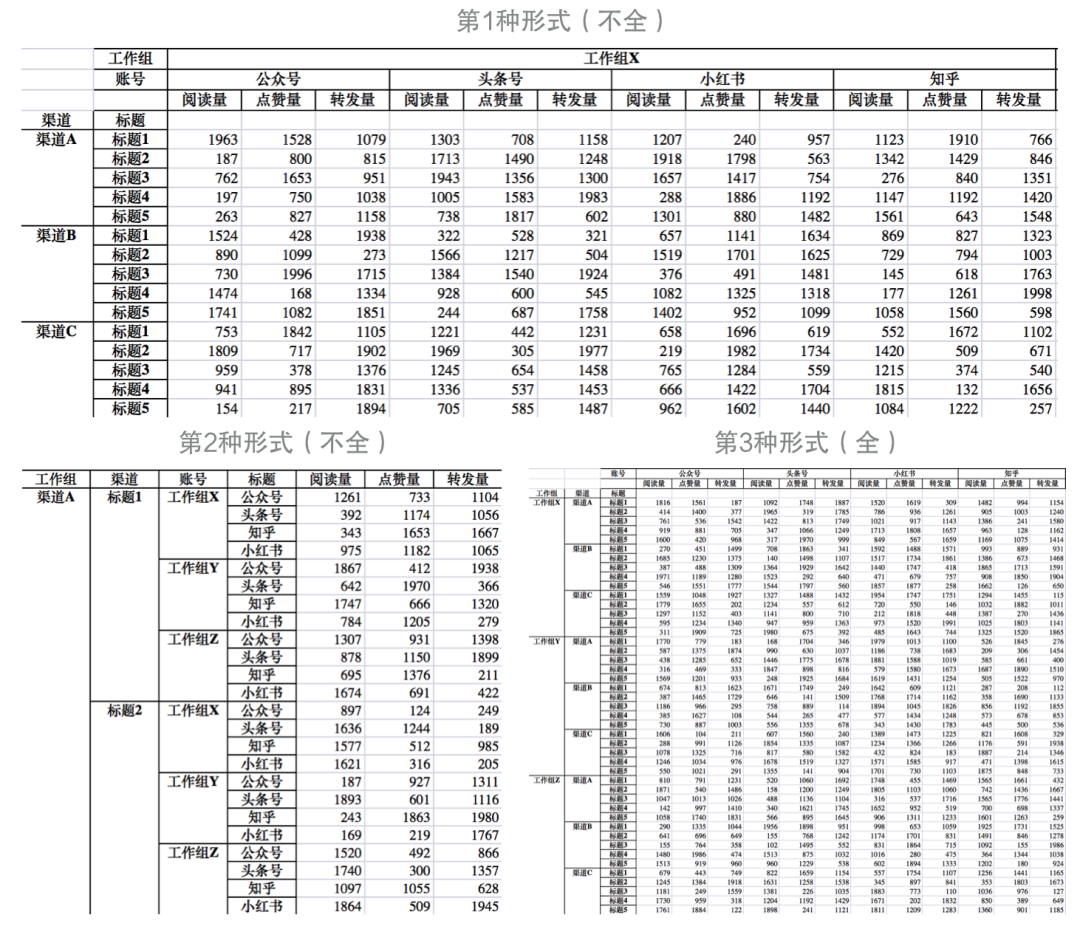
可以看到,同样的数据,可以通过行和列之间转换,呈现出不同的形态。
在数据分析过程中,常需汇总不同维度的数据,或关联对比多维度数据间的关系。
Pandas分析核心功能
pandas提供了多层次索引结构,处理多维度数据非常方便。
上面演示的多维度表格数据,就是用pandas随机生成和处理。
import pathlibimport numpy as npimport pandas as pdfrom pandas import MultiIndex as MIpath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/006analysis')excel_A_path = path.joinpath('testA.xlsx')excel_B_path = path.joinpath('testB.xlsx')excel_C_path = path.joinpath('testC.xlsx')excel_D_path = path.joinpath('testD.xlsx')excel_E_path = path.joinpath('testE.xlsx')excel_F_path = path.joinpath('testF.xlsx')excel_G_path = path.joinpath('testG.xlsx')# 定义维度列表channel_list = ['渠道A','渠道B','渠道C']title_list = ['标题1','标题2','标题3','标题4','标题5']group_list = ['工作组X','工作组Y','工作组Z']account_list = ['公众号','头条号','知乎','小红书']# 定义某个新媒体工作组在多个渠道下多篇文章标题测试数据team1 = pd.Series(np.random.randint(100,1000,15),index=MI.from_product([channel_list,title_list],names=['渠道','标题']),name='工作组X')# 导出Excel表team1.unstack().to_excel(excel_A_path)team1.to_excel(excel_B_path)# 定义更多工作组team2 = pd.Series(np.random.randint(100,1000,15),index=MI.from_product([channel_list,title_list],names=['渠道','标题']),name='工作组Y')# 合并两个Series到DataFramedf = pd.concat([team1, team2], axis=1)df.to_excel(excel_C_path)# 增加账号维度,和工作组一起并入行内df = pd.DataFrame(np.random.randint(100,2000,(180,3)),index=MI.from_product([channel_list, title_list, group_list,account_list],names=['渠道','标题','工作组','账号']),columns=['阅读量','点赞量','转发量'])df.to_excel(excel_D_path)# 把工作组和账号放到列df.stack().unstack('工作组').unstack('账号').unstack().to_excel(excel_E_path)# 只把账号维度放到列df_result = df.stack().unstack('账号').unstack()df_result.to_excel(excel_F_path)# 调整下行内各维度顺序df_result.index=MI.from_product([group_list,channel_list,title_list],names=['工作组','渠道','标题'])df_result.to_excel(excel_G_path)
其中,用到了2个核心功能:结构重塑、合并关联,此外通过to_excel导出xlsx文件方便截图。
结构重塑
pandas中,Series是1维结构,包含1维的索引;DataFrame是2维结构,包含行和列两个维度索引。DataFrame可以看成是由多个Series共享行索引后的组合体,如上述案例中用concat方法把两个Series合并成1个DataFrame。DataFrame在行和列维度,都可以有多层索引,并且可以用stack和unstack方法转换行列维度。
还有4个常用方法用于设置行列索引:reset_index、set_index、T、melt。
# 把所有行索引转为列索引df = df_result.reset_index()# 设置行索引df.set_index(['工作组','渠道','标题'])# melt选择部分id列,其他列转为行数据放在id列后df.melt(id_vars=['工作组','渠道','标题'])# 行和列转换df.T
固定数据结构后,就可以用索引、筛选、切片等方式访问数据了。
# 获取行索引df.index# 获取列索引df.columns# 按列索引print(df[('头条号','阅读量')])# 按列的某个level索引print(df['头条号'])# 按列索引,效果相同print(df['头条号']['阅读量'])# 按行level索引df.loc['工作组X']# 按行多层索引df.loc[('工作组X','渠道A')]df.loc[('工作组X','渠道A','标题1')]# 按行列索引df.loc[('工作组X','渠道A','标题1')][('头条号')]df.loc[('工作组X','渠道A','标题1')][('头条号','阅读量')]# 指明某个维度索引# 按行索引df.loc(axis=0)['工作组X',:,['标题1','标题3']]# 按列索引df.loc(axis=1)[['公众号','头条号'],['阅读量','转发量']]# 借助切片器索引idx = pd.IndexSlicedf.loc[idx['工作组X', :, ['标题1', '标题3']], idx['公众号':,'阅读量']]# 借助xs交叉选取,任意选取某个层级索引# 按行df.xs('标题1',level='标题')# 按列df.xs('阅读量',level=1,axis=1)# 行列交叉df.xs('渠道A',level='渠道').xs('阅读量',level=1,axis=1)
合并关联
pandas用于合并关联数据的操作主要有4种:
concat,可以在行和列上拼接数据,支持inner和outer两种连接模式,支持不同维度数据连接;append,concat的简化版,方便向列和行尾部追加数据;merge,在列维度按某个key合并数据,和SQL数据库的JOIN操作相似,支持inner、outer、right和left4种连接模式;join,当key正好是索引时merge方法的特例,其内部用merge实现。
关于数据合并的4个方法:import numpy as npimport pandas as pddf1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']},index=range(4))df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],'B': ['B4', 'B5', 'B6', 'B7'],'C': ['C4', 'C5', 'C6', 'C7'],'D': ['D4', 'D5', 'D6', 'D7']},index=range(4,8))df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],'B': ['B8', 'B9', 'B10', 'B11'],'C': ['C8', 'C9', 'C10', 'C11'],'D': ['D8', 'D9', 'D10', 'D11']},index=range(8,12))df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],'D': ['D2', 'D3', 'D6', 'D7'],'F': ['F2', 'F3', 'F6', 'F7']},index=[2, 3, 6, 7])# 按行叠加,可以选择增加一层行索引,比如表示数据来自哪个数据库df_concat = pd.concat([df1,df2,df3], keys=['X','Y','Z'])# 也可以用dict传递,效果相同df_concat_0 = pd.concat({'X': df1, 'Y': df2, 'Z': df3})# 按列叠加,行索引默认按outer并集,默认填充NaNdf_concat_1 = pd.concat([df1, df4], axis=1, sort=False)# 按列叠加,行索引按inner交集df_concat_2 = pd.concat([df1, df4], axis=1, join='inner')# 用append追加数据,但不能增加行索引df_concat_3 = df1.append(df2).append(df3)df_concat_4 = df1.append([df2, df3])# 按列追加,列不完全一致时会增加行df_concat_5 = df1.append(df4)# 按列追加,忽略行索引,已有数据不会被覆盖df_concat_6 = df1.append(df4,ignore_index=True)# 类数据库SQL的合并操作left = pd.DataFrame({'key1': ['K0', 'K1', 'K2', 'K3'],'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1':['K0', 'K1', 'K2', 'K3'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})# 列合并,默认用inner连接模式,即key同时出现在两组数据时包含该key对应行数据df_merge = pd.merge(left, right, on='key1')# 用两列key,inner连接模式,必须同时存在key1和key2才会包含在结果中df_merge_inner = pd.merge(left, right, on=['key1','key2'])# left连接模式,以left内(key1,key2)为键,right内没有的数据填NaNdf_merge_left = pd.merge(left, right, how='left', on=['key1','key2'])# right连接模式,以right内(key1,key2)为键df_merge_right = pd.merge(left, right, how='right', on=['key1','key2'])# outer连接模式,包含left和right内所有(key1,key2)键组合df_merge_outer = pd.merge(left, right, how='outer', on=['key1','key2'])pd.merge(left, right, how='inner', on=['key1', 'key2'])# 当key正好是索引时,可以用merge的简化版:joinleft = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']},index=['K0', 'K1', 'K2'])right =pd.DataFrame({'C': ['C0', 'C2', 'C3'],'D': ['D0', 'D2', 'D3']},index=['K0', 'K2', 'K3'])# join默认left连接模式df_join_left = left.join(right)# 等价的merge操作df_join_left_0 = pd.merge(left, right, left_index=True, right_index=True, how='left')# right连接df_join_right = left.join(right, how='right')df_join_right_0 = pd.merge(left, right, left_index=True, right_index=True, how='right')# outer连接df_join_outer = left.join(right, how='outer')df_join_outer_0 = pd.merge(left, right, left_index=True, right_index=True, how='outer')# inner连接df_join_inner = left.join(right, how='inner')df_join_inner_0 = pd.merge(left, right, left_index=True, right_index=True, how='inner')
concat和append相对容易理解,常用于合并多个数据源。merge可以理解为pandas在内存中执行SQL连接操作,功能强大但使用相对复杂;join使用相对更频繁,也更易用。
初学者只需了解4个方法使用场景,掌握常见用法即可。对于复杂情况,可在使用时参考官方文档应用。
交叉透视
变换数据结构,有助于发现各维度数据间的关系。
数据结构整理好后,我们可以通过透视表和分组统计等功能,对数据展开分析。
比如,我们想了解“渠道和标题对头条账号文章数据的影响”:
# 把数据所有维度都变成列df = df_result.stack().reset_index()# 查看渠道和标题对头条号的影响df_pv = df.pivot_table(index=['渠道','标题'],columns=['文章数据'],values=['头条号'],aggfunc=[np.mean])
首先,我们把数据还原为列,然后通过pivot_table方法从数据生成透视表。pandas透视表效果和Excel类似,都可以方便观察不同维度数据间的关系。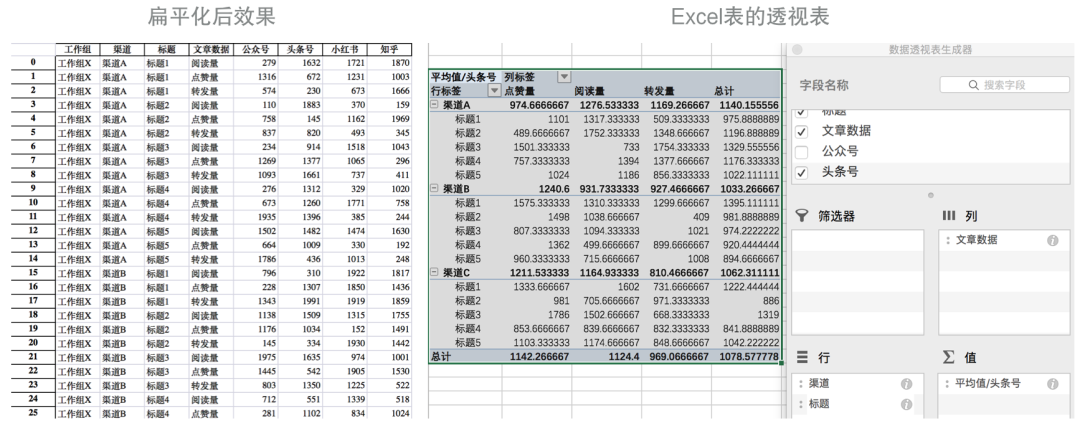
当index和column对应的数据值唯一时,可以用简化的pivot方法,省去用aggfunc聚合。
此外,也可以通过crosstab函数快速交叉对比2个序列数据关系,它默认统计数据出现频率。
df_s = pd.DataFrame({'A':['A1','A2','A3'],'B':['B1','B2','B3'],'C':['C1','C2','C3'],'D':['D1','D2','D3']})# 当index和column应对的数据唯一时,可用简化的pivot方法df_s.pivot(index='A',columns='B',values='C')# 交叉对比任意两个Series间数据关系,不要求是DataFrame,默认aggfunc统计频率pd.crosstab(index=df_s['A'],columns=df_s['B'])# 单层交叉pd.crosstab(index=df['标题'],columns=df['文章数据'],values=df['头条号'],aggfunc=np.mean,margins=True,margins_name='总计')# 多层交叉pd.crosstab(index=[df['渠道'],df['标题']],columns=df['文章数据'],values=df['头条号'],aggfunc=np.mean)
分组聚合
分组聚合,就是先把数据分为多个组,然后对各组进行计算,最后把各组计算结果合并到一起。
比如,为了统计“各工作组的文章总阅读量”,可以按3步计算:
- 把数据按工作组划分成X、Y、Z三组;
- 分别统计3个工作组的文章总阅读量,包括各渠道、账号和标题;
- 最后,输出每个工作组对应的阅读量。
用pandas计算非常方便:首先用IndexSlice对多层索引切片,筛选出“阅读量”所在列,再以“工作组”分组,然后用sum统计出各个账号阅读量的总和,最后在列维度用sum(axis=1)计算各个账号阅读量总和。
idx = pd.IndexSlice# 统计各个工作组的总阅读量df.loc[:,idx[:,'阅读量']].groupby(level='工作组').sum().sum(axis=1)# 统计各组在各渠道下总阅读量df.loc[:,idx[:,'阅读量']].groupby(['工作组','渠道']).sum()
groupby返回的是一个GroupBy对象,它有一个groups属性,包含着每个分组名和对应的索引。
常见的分组方式有4种:
- 先过滤再分组,就像上面使用的;
- 先分组,再过滤,在
GroupBy中过滤出所需要的列; - 以标签形式过滤,可以把列打上不同标记进行统计;
以函数分组,函数会被作用在每个分组列。
df = df_resultidx = pd.IndexSlice# 统计各个工作组的总阅读量# 方式1: 先过滤再分组df.loc[:,idx[:,'阅读量']].groupby(level='工作组').sum().sum(axis=1)# 统计各个渠道的总阅读量df.loc[:,idx[:,'阅读量']].groupby('渠道').sum().sum(axis=1)# 统计各组在各渠道下总阅读量df.loc[:,idx[:,'阅读量']].groupby(['工作组','渠道']).sum()# 不用分组生成索引df.loc[:,idx[:,'阅读量']].groupby('工作组', as_index=False).sum()# groupby返回的是GroupBy对象grp_by = df.loc[:,idx[:,'阅读量']].groupby('工作组')grp_by.groups # 返回一个dict对象# 方式2: 先分组,再过滤df.groupby('工作组')[[('公众号', '阅读量')]].sum()df.groupby('工作组')[MI.from_product([account_list,['阅读量']])].sum().sum(axis=1)# 方式3: 以标签形式过滤,传入一个dict,聚合所需列mapping = {c:c[1] for c in list(df.columns)}# 统计各标题总的文章数据df.groupby(mapping,axis=1).sum()# 方式4: 以函数分组,函数会应用在每个分组列# 如各标题各账号数据总和df.groupby(lambda x: x[1],axis=1).sum()# 像dict一样迭代GroupBy对象for name, group in grp_by:print(name)# 多层索引下可以多层分组形式迭代for (k1,k2), group in df.groupby(['工作组','渠道']):print(k1,k2)# 把GroupBy转为dictpieces = dict(list(df.groupby('工作组')))pieces['工作组X']# 获取某个组groupx = grp_by.get_group('工作组X')
分组后,可以按组进行聚合统计,主要有3种方式:
直接在
GroupBy对象上调用sum等统计方法;- 通过
aggregate方法(或agg缩写)指定统计函数; - 通过
apply自定义对每个分组数据处理。# 数据基本简述统计grp_by.describe()# 在GroupBy对象上应用聚合类统计函数grp_by.aggregate(np.mean) # 算数平均# 应用多个聚合函数,agg是aggregate缩写grp_by.agg([np.min, np.max, np.mean])grp_by.agg([np.min, np.max, np.mean]).rename(columns={'amin': '最小值','amax': '最大值','mean':'算数平均'})# 在不同列应用不同聚合统计函数# 如果是多层次索引,先扁平化再处理df_flat = df.stack().reset_index()df_flat[df_flat['文章数据']=='阅读量'].groupby('工作组').agg({'公众号':np.min,'头条号':np.max,'知乎':np.mean,'小红书':np.median})# 或者动态生成不同统计函数dictagg_dict = {}agg_calc = [np.min, np.max, np.mean, np.median]for ac, calc in zip(account_list, agg_calc):agg_dict.update({col:calcfor col in df.columns[(df.columns.get_level_values(0)==ac) &(df.columns.get_level_values(1)=='阅读量')]})grp_by.agg(agg_dict)# 使用自定义聚合函数,如统计最大最小值的差grp_by.agg(lambda x: x.max()-x.min())# 使用更通用的方法处理各个分组数据:applygrp_by.apply(lambda x: x.describe())# 显示各组的各账号阅读量最高的标题max_title_f = lambda x: x.groupby('标题').max().max()# 显示标题阅读量grp_by.apply(max_title_f)max_title_f2 = lambda x: x.unstack().stack('账号').groupby('账号').max().idxmax(axis=1)# 显示哪个标题grp_by.apply(max_title_f2)# 统计文章数据最优标题df.stack().groupby(['工作组','文章数据']).apply(lambda x:x.unstack('标题').max().idxmax(axis=1))
时间序列
在数据分析中,时间是一个重要维度,比如:按年/季/月统计销量、同比/环比增长率等。
Python内置了2个模块处理时间:datetime和time(处理时间戳)。
import timefrom datetime import datetime# 当前时间now = datetime.now()print(now.year, now.month, now.day, now.hour, now.minute, now.second, now.microsecond)# 时间差delta = datetime(2020, 9, 1) - datetime(2020, 8, 1, 10, 10, 10)print(delta.days, delta.seconds, delta.microseconds)# 转为字符串print(str(now))print(now.strftime('%Y-%m-%d'))# 从字符串转回datatime数据print(type(datetime.strptime('2020-10-1', '%Y-%m-%d')))# 获取当前时间的时间戳,时间戳是个数字now_ts = time.time()# datetime 转 时间戳print(now.timestamp())# 时间戳转为datetimeprint(datetime.fromtimestamp(now_ts))
在实际项目中,为了增强时间数据处理能力,可以借助三方模块dateutil:
- 安装:
pip install python-dateutil。from dateutil.parser import parsefrom dateutil import tz, zoneinfofrom dateutil.rrule import rrule, MONTHLY,DAILY,WEEKLY,SU# 从文字解析print(parse('Wed'), parse('Sep 12'), parse('2020-08-01'))print(parse('Today is January 1, 2047 at 8:21:00AM', fuzzy_with_tokens=True))parse('2020-02-24T20:30:20+08:00')# 获取所有时区zonefile = zoneinfo.get_zonefile_instance()zonefile.zones.keys()# 获取上海时区当前时间tz_sh = tz.gettz('Asia/Shanghai')now_sh = datetime.now(tz=tz_sh)# 时间段生成start_date = datetime(2020, 1, 1)# 从start_date开始连续生成4个月的首日list(rrule(freq=MONTHLY, count=4, dtstart=start_date))# 从start_date开始连续生成10天list(rrule(freq=DAILY, count=10, dtstart=start_date))# 生成两个时间之间的所有周日list(rrule(WEEKLY,byweekday=(SU),dtstart=parse('2020-01-01'),until=parse('2020-12-31')))
pandas提供了3种时间索引:DatetimeIndex、TimedeltaIndex、PeriodIndex。
import pandas as pd# DatetimeIndex类型序列# 生成连续的时间,默认频率是天pd.date_range('2020-01-01', '2020-06-30')# 生成20天的序列pd.date_range(start='2020-04-01', periods=20)# 生成每月最后一天pd.date_range('2020-01-01', '2020-12-31', freq='M')# 生成每月最后一个工作日pd.date_range('2020-01-01', '2020-12-31', freq='BM')# 生成4小时频率生成时间pd.date_range('2020-01-01', '2020-01-02', freq='4h')# 生成每月第三个周五pd.date_range('2020-01-01', '2020-06-30', freq='WOM-3FRI')# Timedelta类型pd.Timedelta(days=3, hours=4)td = pd.Timedelta('31 days 5 min 3 sec')print(td.days, td.seconds, td.microseconds)pd.timedelta_range(start='1 days', periods=5)# 比如每隔1小时生成100个打点序列s = pd.Series(np.arange(100),index=pd.timedelta_range('1 days', periods=100, freq='h'))# 再按天统计打点平均值s.resample('D').mean()# PeriodIndex类型序列# 月度时间pd.period_range('2020-01-01', '2020-06-30', freq='M')# 季度时间p_q = pd.PeriodIndex(['2020Q1', '2020Q2', '2020Q3'], freq='Q-DEC')# 转为月度时间,首月和最后月p_q.asfreq('M', 'start')p_q.asfreq('M', 'end')# 年度时间,以12月作为结束的一整年p_y = pd.period_range('2006', '2009', freq='A-DEC')# 转为每年最后一个工作日p_y.asfreq('B', how='end')
其中,主要处理方法有3个:
to_period:改变显示单位,但不做统计,数据量不变;asfreq:重塑间隔单位,按单位压缩数据量;resample:统计时间段内数据,聚合计算。
时间序列在业务分析中,主要用于观察数据增长趋势,或间隔数据统计,如年度/季度/月度等。import numpy as npimport pandas as pds = pd.Series(np.random.randint(0,100,1000),index=pd.date_range('2020-01-01',periods=1000,freq='H'))print(type(s.index)) # DatetimeIndex# 按天/月/季/年显示,但不统计,数量不变s.to_period('D') # 天s.to_period('M') # 月s.to_period('Q') # 季s.to_period('A') # 年type(s.to_period('A').index) # PeriodIndex# 按天显示,数量减少s.asfreq('D')s.asfreq('M')type(s.asfreq('M').index) # DatetimeIndex# 按日/月/季/年统计s.resample('D').sum().to_period('D')s.resample('M').sum().to_period('M')s.resample('Q').sum().to_period('Q')s.resample('A').sum().to_period('A')# 按时间字符串过滤s['2020-01']
门店型业务分析实战
还是那句话:数据分析必须回归业务,第一步就是设定分析目标。
根据上一节介绍的门店型业务分析重点,制定具体分析目标:
- 门店经营维度:单店日/月订单量和营收,全国门店年度营收排名。
- 用户运营维度:用
FRM模型划分用户等级。 - 产品服务维度:单店畅销/滞销产品,全国TOP10畅销产品。
下面就以最常见的奶茶连锁加盟店作为分析对象,完成上面3个分析目标。
源数据格式介绍
大部分门店型业务品牌在早期开展业务时,主要借助POS机收银完成交易闭环,较少具备全国门店统一分析能力,数据需要从POS系统导出。
本案例会根据实战项目数据结构,模拟生成各门店导出的交易数据。
其中1张门店清单表,记录了门店基本信息;N张主订单表和副订单明细表记录了每个门店订单数据。
- 主订单描述了“谁在什么时候哪个店消费了多少钱”;
- 副订单表描述了“每个订单具体包括哪些产品及其数量”。
具体数据在学习群获取,可以直接用生成好的数据,也可以用Notebook生成自己的数据。
门店经营分析
通过pandas的时间索引,可以很方便统计时间序列的数据。
# 单个门店,以订单时间为索引df_shop = df_shop.set_index('订单日期')# 按日/月/季/年统计df_shop.resample('D')['实付'].sum().to_period('D') # 日营收df_shop.resample('M')['实付'].sum().to_period('M') # 月营收df_shop.resample('Q')['实付'].sum().to_period('Q') # 季营收df_shop.resample('A')['实付'].sum().to_period('A') # 年营收df_shop.resample('D')['订单ID'].count().to_period('D') # 日单量df_shop.resample('M')['订单ID'].count().to_period('M') # 月单量
单门店和多门店统计方式一致,当我们从多个表中加载完数据,可以用concat方法合并成一个大的DataFrame操作。
# 全国门店df_shop_list = []df_shop_x_list = []for i in range(10):print(f'Reading SP{i:04d}...')df_shop_x_list.append(pd.read_excel(path.joinpath(f'SP{i:04d}_X.xlsx')))df_shop_list.append(pd.read_excel(path.joinpath(f'SP{i:04d}.xlsx')))print(len(df_shop_list), len(df_shop_x_list))# 合并成大表df_shops = pd.concat(df_shop_list, ignore_index=True)df_shops_x = pd.concat(df_shop_x_list, ignore_index=True)# 调整索引df_shops.set_index('订单日期', inplace=True)del df_shops['Unnamed: 0']# 统计历年全国门店年度营收s_all_ym = df_shops.reset_index().groupby([pd.Grouper(key='订单日期',freq='A'),pd.Grouper(key='门店ID')])['实付'].sum().unstack('门店ID').to_period('A').stack('门店ID')# 历年来单店年营收排名df_all_ym = pd.DataFrame({'年营收':s_all_ym})df_all_ym.sort_values(by='年营收')df_all_ym['全对比排名']=df_all_ym['年营收'].rank(ascending=False)df_all_ym['按年排名']=df_all_ym.groupby(level=0, as_index=False).apply(lambda x: x['年营收'].rank(ascending=False)).droplevel(0)# 全国门店年度营收统计df_shops.groupby('门店ID')['实付'].apply(lambda x: x.resample('A').sum().to_period('A'))
用户运营分析
通过时间维度的聚合,可以很方便观察用户消费频率和金额。
# 近半年消费过的用户s = df_shop.loc['2020-01-01':'2020-06-30']['用户ID'].value_counts()# 按客户维度统计:首次/最后一次消费时间,近Q/半年/1年消费次数grp_user = df_shop.reset_index().groupby('用户ID')grp_user_q = df_shop.loc['2020-04-01':'2020-06-30']grp_user_h = df_shop.loc['2020-01-01':'2020-06-30']grp_user_y = df_shop.loc['2019-07-01':'2020-06-30']df_user_rf = pd.DataFrame({'首次消费':grp_user.first()['订单日期'],'最后一次消费':grp_user.last()['订单日期'],'近Q消费次数':grp_user_q['用户ID'].value_counts(),'近半年消费次数':grp_user_h['用户ID'].value_counts(),'近1年消费次数':grp_user_y['用户ID'].value_counts(),'截止目前总消费次数':df_shop['用户ID'].value_counts()}).fillna(0)# 统计:总消费金额、近Q/半年/1年消费金额df_user_m = pd.DataFrame({'累计总消费金额':grp_user['实付'].sum(),'近Q消费金额':grp_user_q.groupby('用户ID')['实付'].sum(),'近半年消费金额':grp_user_h.groupby('用户ID')['实付'].sum(),'近1年消费金额':grp_user_y.groupby('用户ID')['实付'].sum()}).fillna(0)# 活跃人群:统计近Q有消费的人群df_user_rf[df_user_rf['近Q消费次数']>0]# 流失预警:统计近半年有消费,近一个Q没消费的人群df_user_rf[(df_user_rf['近半年消费次数']>0) & (df_user_rf['近Q消费次数']<1)]# 流失用户:统计近1年都没有消费的人群df_user_rf[df_user_rf['近1年消费次数']<1]# 年消费额中位数之上人群median = df_user_m['近1年消费金额'].median()df_user_m[df_user_m['近1年消费金额']>median].sort_values(by='近1年消费金额',ascending=False)# 查看消费最高用户在2020年的消费记录df_shop['2020'][df_shop['用户ID']=='U00000059']
根据RFM模型,我们可以把用户划分成多个等级,可以借助cut方法对区间段划分。
# 汇总用户表df_user=pd.concat([df_user_rf,df_user_m], axis=1)# 假设按近1年消费额定义4个用户等级# (0, 2000], (2000, 5000], (5000, 10000], (10000, ~]bins = [0, 2000, 5000, 10000, df_user_m['近1年消费金额'].max()]user_cut = pd.cut(df_user_m['近1年消费金额'], bins,labels=['钻石','黄金','白银','青铜'])user_cut.value_counts()
产品服务分析
一般交易系统都会把订单和订单明细单独存放,好在pandas支持重复索引,当分别加载完2张表后,可以用merge方法按订单号合并后分析。
# 单店分析df_shop = pd.read_excel(path.joinpath('sample_SP0000.xlsx'))df_shopx = pd.read_excel(path.joinpath('sample_SP0000_X.xlsx'))# 合并订单表和订单明细表df_shopa = df_shop.reset_index().merge(df_shopx, on='订单ID', suffixes=['_总订单','_单项产品']).set_index('订单日期')# 单店分析产品,统计各产品销售数量# 历年产品销量统计df_prod = pd.DataFrame({'总销量':df_shopa.groupby('产品')['数量'].sum().sort_values(ascending=False)})df_prod['总销量排名'] = df_prod.rank(ascending=False)# 统计各年产品销量榜df_shopa.reset_index().groupby([pd.Grouper(key='订单日期',freq='A'),pd.Grouper(key='产品')])['数量'].sum().unstack('产品').to_period('A')# 统计2019年最畅销产品df_shopa['2019'].groupby('产品')['数量'].sum().sort_values(ascending=False)# 全国范围分析df_shopsa = df_shops.reset_index().merge(df_shops_x, on='订单ID', suffixes=['_总订单','_单项产品']).set_index('订单日期')df_prods = pd.DataFrame({'总销量':df_shopsa.groupby('产品')['数量'].sum().sort_values(ascending=False)})df_prods['总销量排名'] = df_prods.rank(ascending=False)df_prods[df_prods['总销量排名']<=10]
以上分析都是围绕门店、用户和产品3大重要维度的常见分析内容。
实战中还会根据实际情况制定更多分析目标,如成本毛利、日增客户、复购率、节日活动销量、推广转化、人效坪效等等。
总结
本文介绍了pandas分析中常用的功能,包括多层索引、结构重塑、合并关联、交叉透视、分组聚合、时间序列。
此外,通过门店型业务案例,演示如何应用分析功能,完成分析目标。
实战中,需要灵活应用各个分析功能,学习的关键是建立起各功能应用效果的直观感受。
下一节会介绍数据可视化,可以借助图表帮助加强数据的直观感受。
扫码加入学习群,前100名免费。


若有收获,就点个赞吧
0 人点赞
