我们每天都需要获取和过滤大量数据和信息。
比如一个产品运营人员,每天都需要了解:
- 互联网热点,从微博、微信、知乎、头条等平台了解当天的热点内容;
- App和小程序榜单,看看有哪些冒出来的热门应用;
- 从业内常关注的微信号中寻找选题素材,建立自己的素材库;
- 跟踪媒体数据,阅读率、打开率、转化率、分享裂变率等;
- 跟踪用户数据,用户新增、留存、活跃等;
- 拆解和复盘爆款案例,从中学习亮点……
获取和过滤数据的能力,决定了每个人的效率。
日常工作中,我们会用各类软件来处理数据。
其中使用频率最高、数量最多的,就是浏览器。
浏览器
历史上曾发生过3次浏览器大战:
- 90年代微软的IE用捆绑免费策略打败了网景付费的Netscape。
- 2004年网景核心团队成立Mozilla开源组织,推出Firefox打破微软IE垄断。
- 2008年Google以简洁、安全、免费的Chrome向IE发起挑战。
目前Chrome浏览器已占有7成PC端市场,1/3移动端市场,成为行业老大。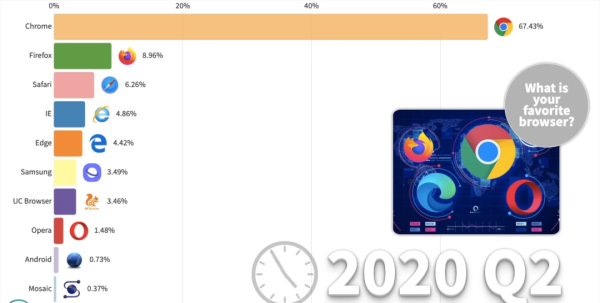
互联网诞生之初只能显示文本信息,应用非常有限。
随着技术标准化和商业化推进,浏览器慢慢把图片、音频、视频、动画等元素带入互联网,成了如今的模样。
浏览器,最基本的3大核心模块:
- 网络模块,处理网络连接和数据传送。
- 渲染模块,解析数据后展示成图像,即浏览器内核。
- JS模块,执行JavaScript程序。
当然,浏览器工作远不止这些,它还得管人机交互、多进程资源分配、数据存储以及插件扩展等等。
但只要具备3大核心模块的功能,我们就能处理互联网上的数据。
处理互联网数据
就像Word软件,可以把一个装着XML和图片等文件的“压缩包”,显示为一篇文档;
浏览器,则是把HTML、CSS、JS、JSON和图像等文件,显示为可浏览的页面。
简单看下浏览器的工作流程:
- 首先,浏览器根据我们给出的网址,发出网络请求,获取网址背后对应的资源文件。
- 其次,内核根据文件内容进行渲染,JS模块负责执行脚本,在屏幕上输出可视的页面。
- 最后,我们通过和页面上元素的交互,“通知”浏览器发出进一步的数据请求。
对于获取数据而言,我们不必太关心浏览器内核渲染页面的过程。
结构化的数据主要包含在HTML和JSON这两类文本文件中。
二进制文件,如图片、音视频等,其访问地址都会包含在以上两类文本文件中。
处理互联网数据的关键,是获取结构化文本,并从中提取所需内容。
- 通过访问地址从网络端获取HTML或JSON文件
- 从文件中解析出所需的文本内容,或其他文件访问地址
- 继续第1步操作。
网络文件下载
和自动办公系列相比,处理文件多了一步,那就是得先从网上下载文件。
网络分很多层,互联网属于应用层,用HTTP协议规定了客户端和服务器间的通信格式。
浏览器就是一种客户端,服务器就是网页和文件存放的地方。
当我们输入某个网址按下回车:
- 首先,浏览器会通过网络模块帮我们找到那台服务器。
- 接着,它会向服务器发出HTTP格式请求,比如
GET /index.html。 - 然后,服务器会按约定的HTTP格式响应,返回数据。
- 最后,浏览器按内部流程开始渲染,等待我们下一个操作指令。
最常用HTTP请求动作就2个:
GET:用来下载数据,比如页面、各类文件等。POST:用来上传数据,比如表单、文件等。
Python用于处理HTTP协议的模块中,requests门槛最低,简单易用。
比如用它来获取头条的首页:
import requestsr = requests.get('https://www.toutiao.com/')print(r.content)
只不过,打印出来的内容没有经过排版,看起来比较乱。
当然,我们也可以用它上传数据,比如上传图片:
import timeimport pathlibimport requestspath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')img_path = path.joinpath('tifa.jpg')url = 'https://zh-cn.imgbb.com/json'data = {'type': 'file','action': 'upload','timestamp': int(time.time()*1000),}files = [('source', (img_path.stem, open(img_path, 'rb')))]r = requests.post(url, data=data, files=files)j = r.json()url = j['image']['url']print(url)
POST操作中需要指定提交的数据,那么应该提交哪些数据呢?
在用requests模块自动执行上传操作前,我们可以借助浏览器观察所需要的所有参数。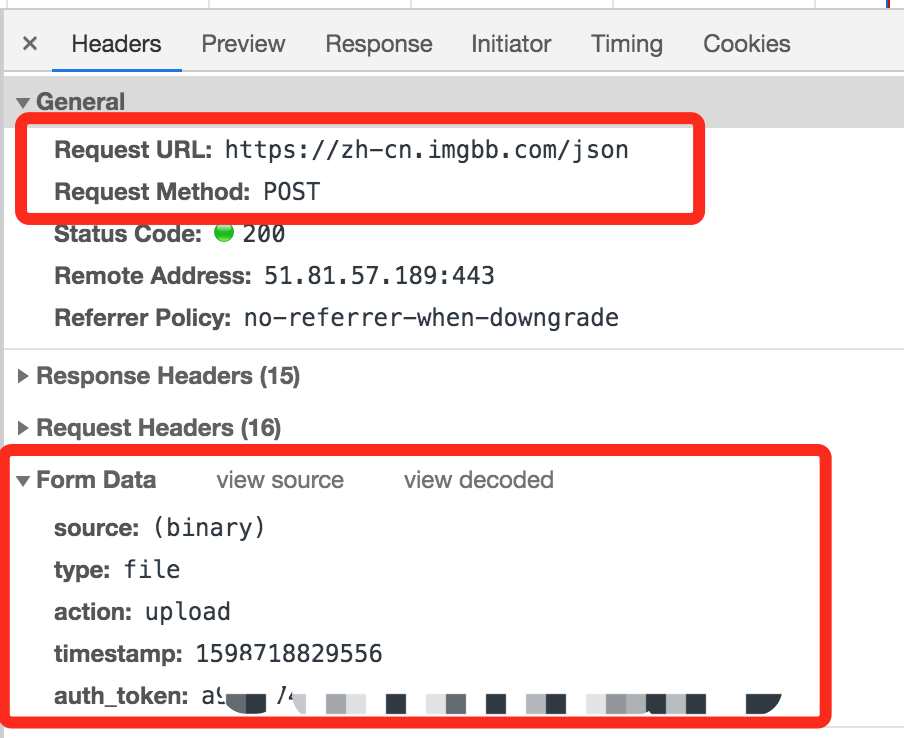
这里只是用公开的图床服务演示,所以在权限校验等方面比较宽松,正常情况下需要在请求头部中设定使用的账户信息等内容。
解析HTML文件
拿到HTML文件后,想要提取其中的内容,我们就得解析文件。
HTML是一种标签格式的文本文件,属于一种特殊应用的XML文件。
比如: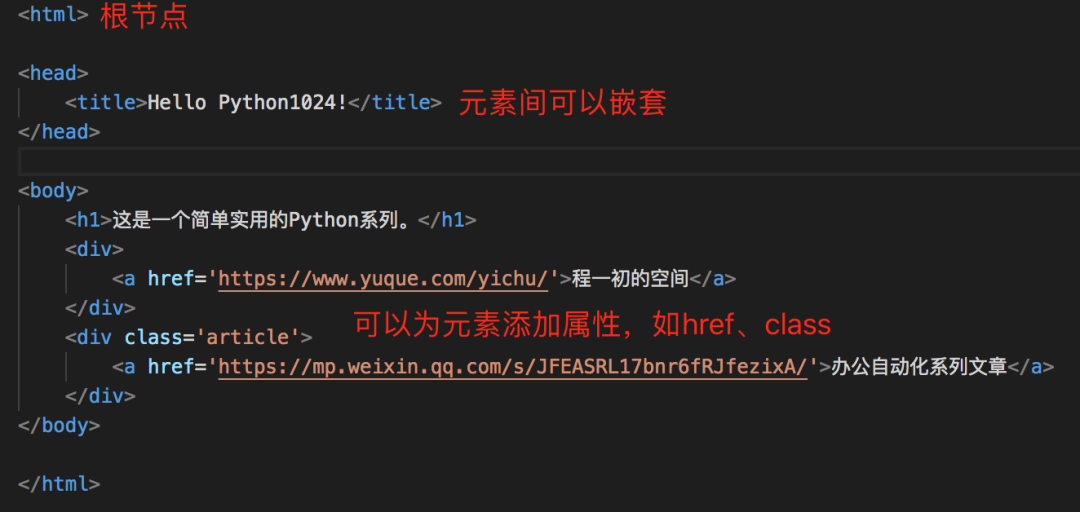 它本质上还是个文本文件,所以直接用之前打开文本文件的方式也能处理。
它本质上还是个文本文件,所以直接用之前打开文本文件的方式也能处理。
但如果想要提取其中的数据,每次都得用字符串匹配标签,再获取数据。
好在,这些基础工作已经有人更好地完成了,我们只需要使用对应的模块即可。
Python中常用语处理HTML的模块主要有2个:
lxml:用于处理XML文档结构,解析成树型数据结构。beautifulsoup4:提供操作HTML文档的简易Python接口。
两者定位不同,前者侧重文档解析,速度快;后者是数据访问接口接口易用,底层基于其他模块解析文档,如lxml、Python标准库里的HTML解析模块html.parser。
模块安装:
pip install lxmlpip install beautifulsoup4
lxml基本使用
import pathlibfrom lxml import etreepath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')html_path = path.joinpath('test.html')# 使用HTML方法从字符串中解析HTMLwith open(html_path, 'r') as f:root = etree.HTML(f.read())# 使用parse方法从某个文件中解析HTML# root = etree.parse(str(html_path))print(root.xpath('//a/text()')) # 所有a元素文本print(root.xpath('//a/@href')) # 所有a元素链接# 根据属性查找元素print(root.xpath('//div[@class="article"]/a/text()'))# 模糊匹配print(root.xpath('//div[contains(@class,"article")]/a/@href'))print(root.xpath('//div[starts-with(@class, "art")]/a/@href'))
lxml模块支持用xpath语法查找数据:
/表示根节点//a表示匹配所有a元素//a/text()表示选取所有a元素的文本数据@表示选取元素的属性//div[@class="article"]表示所有class属性为article的div元素
xpath也支持更复杂的匹配方式,刚开始只需掌握最基本的使用,就足够应付80%常见情况。
如果不熟悉xpath语法,也没关系,我们可以借助Chrome浏览器获取。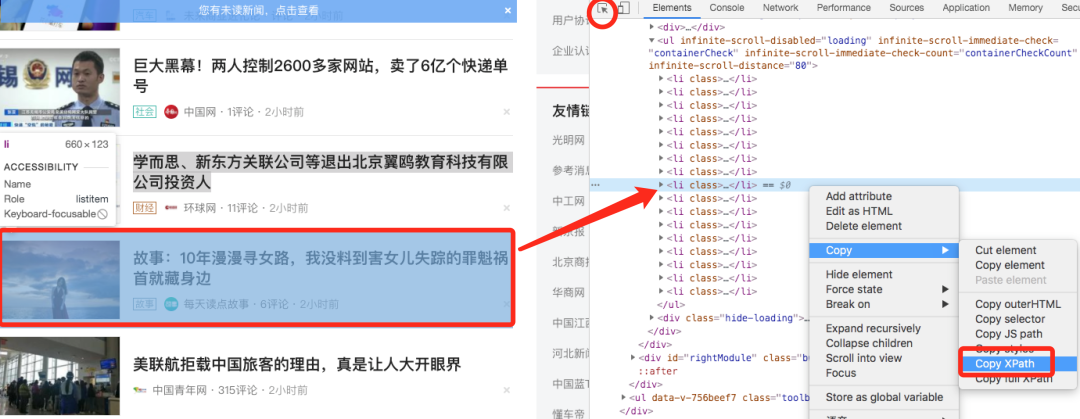
- 打开浏览器的调试模式,点击选取元素的小箭头(图中红色圆圈标记)
- 点击页面上所需内容所在位置,会出现元素对应代码
- 右击代码,选择“复制”->“复制xpath”,即可获取到元素对应的xpath值。
当然,lxml模块也支持Python语法查询数据,但没有xpath简洁,更适合逐个遍历元素。
import pathlibfrom lxml import etreepath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')html_path = path.joinpath('test.html')root = etree.parse(str(html_path)).getroot()print(root.tag) # 根元素标签名head, body = root.getchildren() # 获取root之下的元素for div in body:if div.tag == 'div': # 根据tag判断元素标签links = div.findall('a') # 获取div元素下所有a子元素for link in links:# text获取元素内容,attrib获取属性print(link.text, link.attrib['href'])# 纯粹遍历文档所有元素for ele in root.iter('*'):print(ele.tag)
beautifulsoup4基本使用
相比lxml,beautifulsoup4提供的Python接口更丰富,也更易用。
import pathlibfrom bs4 import BeautifulSouppath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')html_path = path.joinpath('test.html')with open(html_path, 'r') as f:# 用Python内置标准库解析文档soup = BeautifulSoup(f.read(), 'html.parser')# 用lxml解析文档# soup = BeautifulSoup(f.read(), 'lxml')# 支持点操作访问元素print(soup.html.name)# 等价于print(soup.find('html').name)# 也等价于print(soup.find_all('html')[0].name)print(soup.title.text)# 获取所有链接元素links = soup.find_all('a')for link in links:print(link.text, link.attrs['href'])# 也支持get方法获取属性# print(link.get('href'))# 用属性查找元素div = soup.find('div', class_='article')# 支持[]获取属性值print(div.a.text, div.a['href'])# 遍历子元素for div in soup.body.children:if div.name == 'div':print(div.get_text())
可以看到,它通过重写__getattr__方法,提供了点操作符方便元素查找。
同时也提供了支持按属性查找元素的find方法,比lxml中的find方法更易用。
在选择lxml还是beautifulsoup时,可以根据个人习惯,但个人比较推荐用lxml的xpath语法获取元素,这种方式更简洁。
浏览器上的xpath插件
此外,如果是Chrome系浏览器,可以安装xpath_helper插件,可以方便在单个页面中根据xpath语法批量获取数据。
举个例子,如何可以把自动办公系列中所有文章及其链接都保存到Excel中?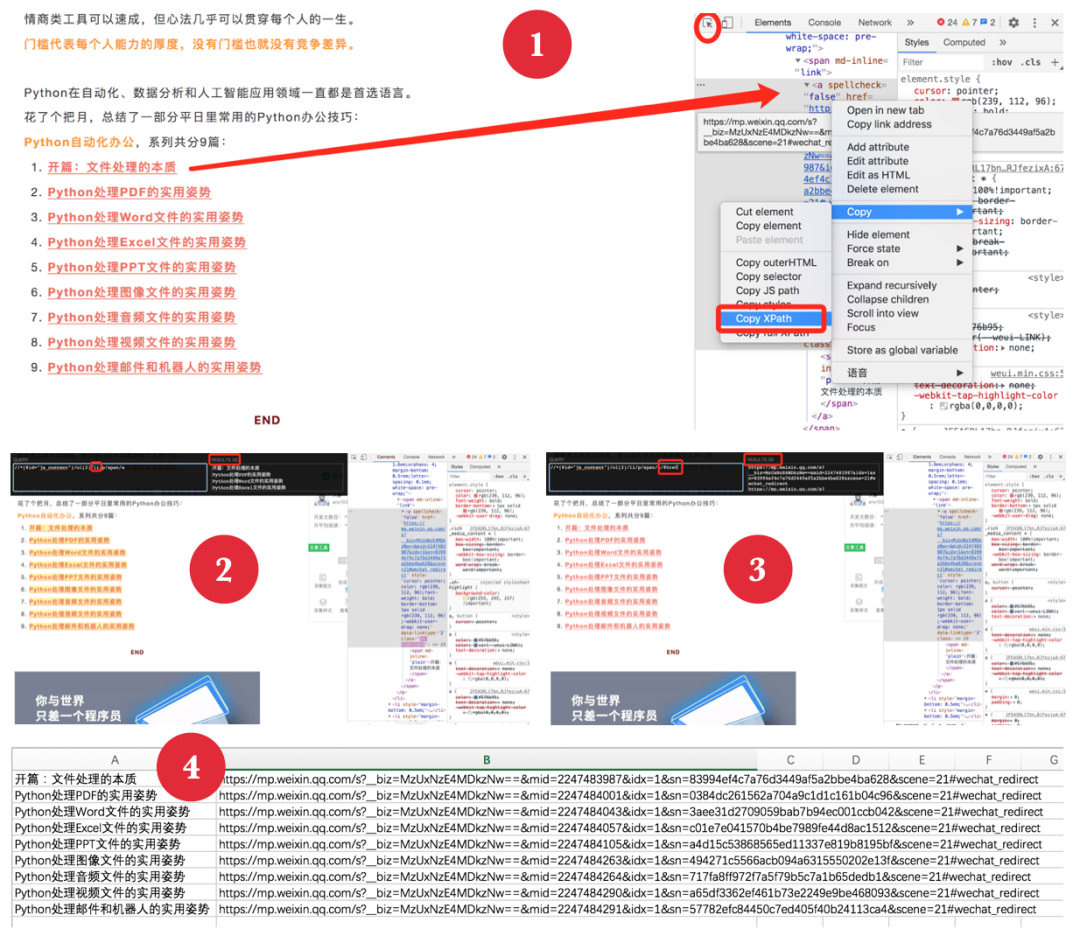
- 找到元素并复制其xpath值,开启
xpath_helper插件。 - 把xpath值贴入其中,并删除
li元素后的具体索引值。 - 复制结果到Excel第一列,在xpath值后增加
/@href,获取文章链接。 - 复制结果到Excel第二列,就获得了所有文章及其链接。
这个方法适用于所有单个网页上批量获取元素的情况,简单实用。
用Python自动获取文章并保存文件
结合requests和lxml模块,我们可以很方便获取页面数据,并保存如csv等文件。
import csvimport pathlibimport requestsfrom lxml import etreepath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')csv_path = path.joinpath('002dataget_csv.csv')url = 'https://mp.weixin.qq.com/s/JFEASRL17bnr6fRJfezixA'r = requests.get(url)root = etree.HTML(r.content)# 获取所有文章链接# 根据浏览器中获取xpath修改link_list = root.xpath('//*[@id="js_content"]/ol[2]//a')# 获取文章标题和URLarticles = [(link.xpath('.//text()')[0], link.get('href')) for link in link_list]# 写入csv文件with open(csv_path, 'w') as f:csv_f = csv.writer(f)# 添加表头csv_f.writerow(('标题', '链接'))csv_f.writerows(articles)
这样就完成了从获取页面内容,到抽取所需信息,再保存到本地文件的自动流程。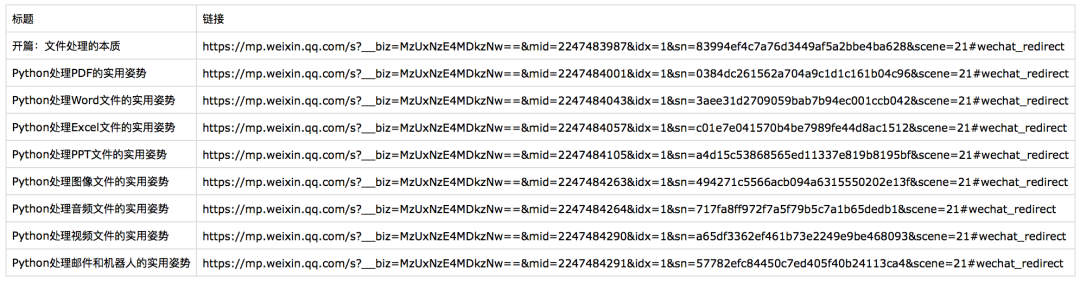
如果需要从多个页面获取数据,需要先识别页面数据间相同的定位特征,比如微信公众号正文内容都在//*[@id="js_content"]范围之内,然后通过循环方式处理页面即可。
解析JSON文件
目前互联网上有不少应用都通过JSON格式传送数据,尤其是移动端应用。
之前也介绍过用Python的json标准库来解析此类数据。
import pathlibimport jsonpath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')json_path = path.joinpath('test.json')with open(json_path, 'r') as f:data = json.loads(f.read())print(data['data'])
一般JSON格式的数据请求都是异步的,在浏览器调试模式中属于XHR类数据,可以打开预览。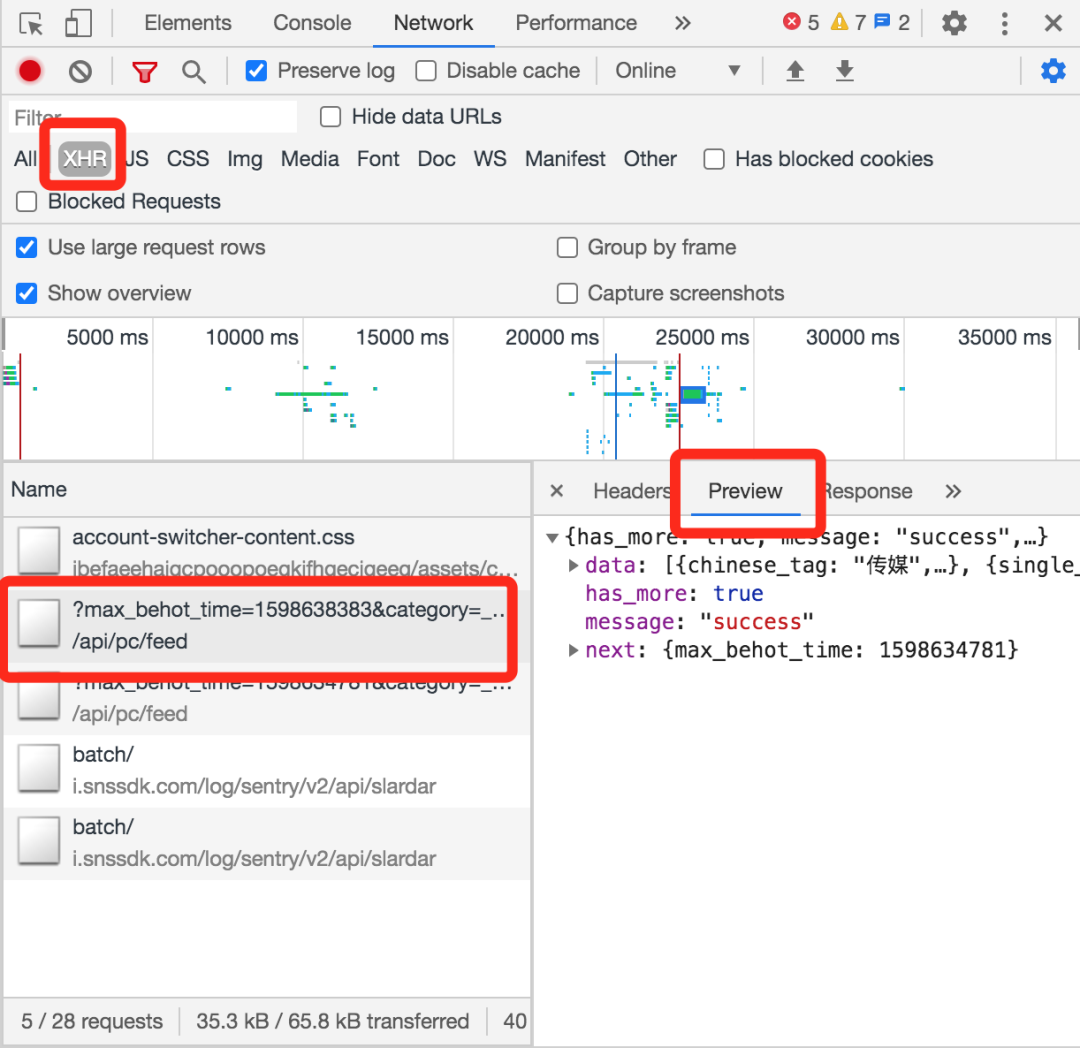
requests模块为返回的数据提供了JSON格式转换的方法。
import requestsHEADERS = {'User-Agent': 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135'}url = 'https://www.toutiao.com/api/pc/feed/'# 头条会检测浏览器类型r = requests.get(url, headers=HEADERS)# 用Response对象的json方法获取JSON数据j = r.json()data = j['data']article_list = [ (d['title'], f'https://www.toutiao.com{d["source_url"]}') for d in data]print(article_list)
有两个注意点:
- 不少网站都对数据访问有限制,比如这里是最基本的浏览器特征。
- 只有当返回的数据是JSON格式时,调用
json方法才有效,否则会提示错误。
爬虫工程
爬虫,可以大幅提高数据获取效率;而数据拥有方,会设法拦截爬虫类操作。
爬虫和反爬虫,是一对围绕数据获取的技术较量。
反爬虫措施一般都以限制访问为主,但首先得准确识别出恶意爬虫。
比如,常见的反爬虫措施:
- 识别浏览器特征,如
User-Agent、是否开启窗口等; - 分析爬虫行为,如访问频率、访问来源、账号归属等;
- 跟踪识别账号,如cookie、token、请求签名等;
- 随机码验证,如要求人工输入随机码,判定真人操作。
比如在上面“获取头条PC推荐数据”案例中,除非指定User-Agent,否则无法获取数据。
原因是对方服务器会检查User-Agent这个头部参数,判断是否用了“正常”浏览器。
在用requests模块发出HTTP请求时,如果不单独指定头部信息,它就会用python-requests/2.24.0作为默认的User-Agent。
可以用下面代码来验证:
import requestsHEADERS = {'User-Agent': 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135'}sess = requests.Session()# 显示requests默认UAprint(sess.headers)# 不指定UA访问r = requests.get('https://www.toutiao.com/api/pc/feed/')print(r.content)# 指定UA为浏览器所用UAr = requests.get('https://www.toutiao.com/api/pc/feed/', headers=HEADERS)print(r.content)
很明显,对方服务器会拦截python-requests/2.24.0这类UA;但当我们把请求“模拟”成浏览器发出时,就可以正常获取到数据了。
HTTP头部信息参数,是服务方权限校验和反爬虫的常用信息,比如User-Agent、cookie、referer等。
我们可以通过浏览器调试模式查看到每个请求对应的头部信息: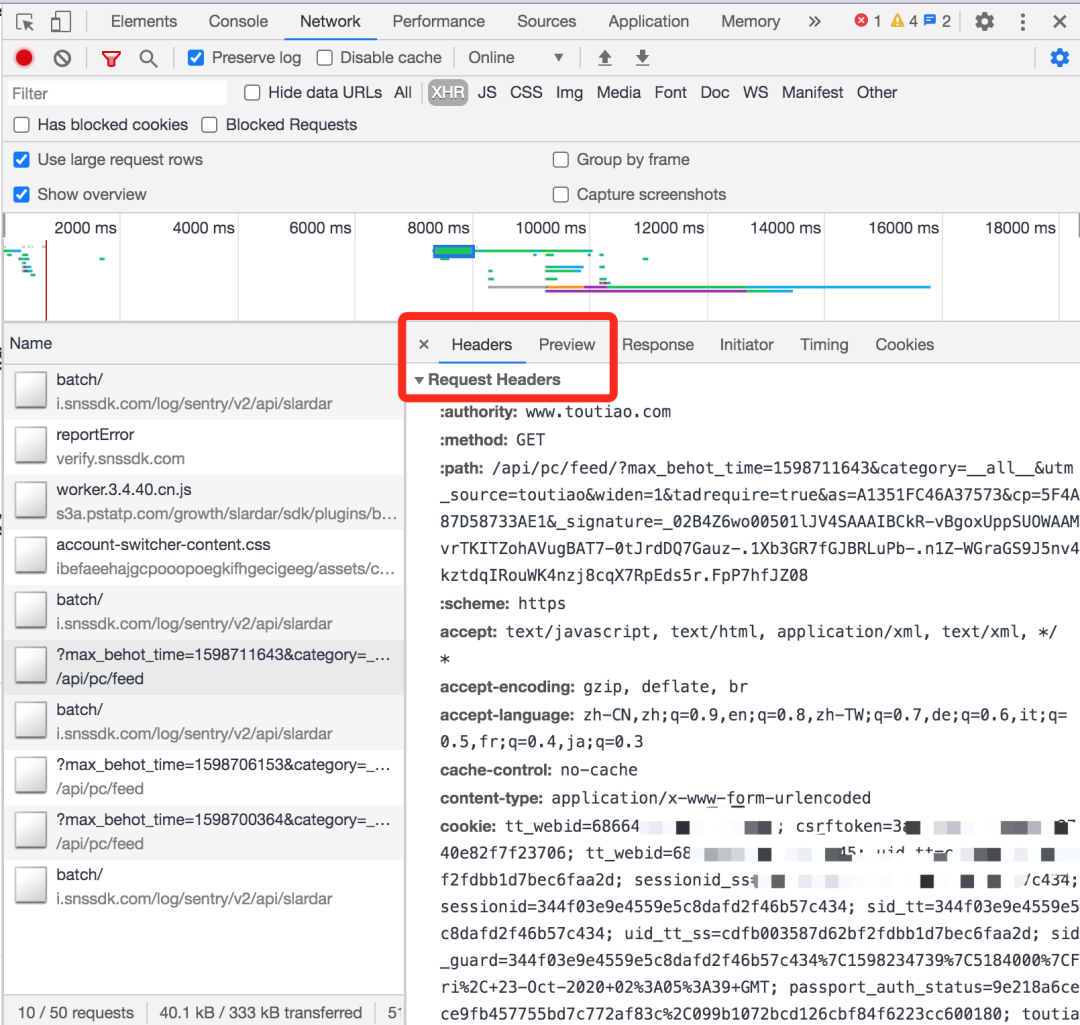
实战时,如果浏览器访问正常,而程序无法访问,可以对照浏览器修改头部信息,用排除法去检查各个参数的影响。能做到这一点,就足够应付大部分普通网站。
对于背后有大型技术团队的平台,反爬虫措施会相对复杂;如果涉及到数据上传,检查会更严格。
总结
本文重点介绍了如何用Python从互联网获取数据和解析数据。
实战中,大部分网站数据的自动获取并不复杂,结合Python基本循环和文件读写,能大幅提高效率。
但对于一些大型平台,则需要研究测试,这部分工作量占整体爬虫的90%以上。
关于爬虫,还必须要说明的是:有2条非常明确的红线不能突破!
- 非法获取个人信息、商业秘密与国家秘密的行为。
- 大规模使用爬虫,导致网站服务受影响。
扫码加入学习群,前100名免费。

若有收获,就点个赞吧
0 人点赞
