接下来的4章,会介绍数据分析的核心工作,包括数据清洗、业务模型、数据分析和数据可视化。
不管数据来自外部采集,还是内部系统导出,都会出现不规整的部分,比如不完整、逻辑矛盾、重复、异常等。在正式分析数据前,需要提前处理这些不规整数据,否则会极大影响数据分析的结果。
这部分工作,俗称“数据清洗”,主要任务包括:
- 基本数据处理:修改列名、时间格式、数字格式、字符串去空格。
- 删除无效数据:如空数据,或显示为类似”N/A”的数据,或其他无效数据。
- 剔除无关数据:只选取所需要的数据列,其他的忽略。
- 删除重复数据:剔除完全一样的数据。
- 缺失数据处理:用平均值替代,或按特征值处理,如负数或零等。
- 异常数据处理:删除、按缺失处理、其他具体情况处理。
数据清理工作占整体数据分析工作的80%以上,任务繁琐但至关重要。
本章内容安排如下:
- 介绍Python数据分析两大利器:
numpy、pandas。 - 常用数据操作:索引切片、筛选过滤、统计函数、缺失和字符串处理等。
- 演示数据清理环节关键任务的实战操作。
NumPy基本用法
在本系列第一篇文章中,我们已经对比过numpy和Python内置数组的性能差异。
那么关于数据分析,它有哪些实用方法?numpy最大的特点就是基于整个数组运算,无需用for循环遍历数组中的每个元素。
比如,想把一个数组中每个元素都乘以某个整数:
相比之下,import numpy as nparr = [1, 2, 3]# 用numpy的ndarray做乘法nparr = np.array(arr) * 10print(nparr)# 转为listprint(list(nparr))# 用Python内置数组arr10 = [a*10 for a in arr]print(arr10)# 两个矩阵相加print(nparr + nparr)
numpy对数组操作更方便。广播机制
numpy在处理两个不同维度矩阵时,如果满足2个原则,会触发广播机制,把低维矩阵与高维矩阵中的各“数据块”进行计算。
比如,一个1维数组和2维数组相加,2维数组的每行都与1维数组元素相加,结果是2维数组。
成功触发广播机制的2个原则:import numpy as nparr_low = np.array([1,2,3])arr_high = np.array([[1,2,3],[4,5,6]])# (3,) (2, 3)print(arr_low.shape, arr_high.shape)arr_result = arr_low + arr_highprint(arr_result)# [[2 4 6]# [5 7 9]]
- 维度少的矩阵,其各维度数据长度从后往前与维度多的矩阵能完全匹配上。
- 当某维度数据长度不一致时,其中一方长度为1,仍视为匹配。
可以通过数据的shape属性查看各维度长度,比如:
- (2, 3, 4)和(3,4)能匹配
- (2,3,4)和(1,4)能匹配
- (2,3,4)和(2,1,4)能匹配
- (2,3,4)和(3,3,4)不能匹配
统计函数
在基础系列中,我们用sum、min、max等内置函数对数组计算,比如:
- 计算数组总和:
sum([1,2,3]) - 找数组最大值:
max([1,2,3]) - 找数组最小值:
min([1,2,3])
对于一维数组,Python内置函数够用,如果是2维数组,用列表生成式也能处理:[sum(x) for x in [[1,2,3], [4,5,6], [7,8,9]]]
如果维度不断增加,3维、4维、5维……就没那么简单了。
但对于numpy而言,不管多少维,都可以轻松应对。
import numpy as np# 生成一个3x4的矩阵data = np.arange(12).reshape(3,4)# 显示数据维度以及各维长度print(data.ndim, data.shape)# 按第1个维度迭代,各行内元素按位相加,结果长度4print(data.sum(axis=0))# 按第2维度迭代,各列内元素按位相加,结果长度3print(data.sum(axis=1))# 更高维度矩阵data_3x = np.arange(24).reshape(2,3,4)print(data_3x)# 输出其维度print(data_3x.ndim, data_3x.shape)# 根据每个维度迭代累加数据# 累加结果和原数据相比少了一维for i in range(data_3x.ndim):print(data_3x.sum(axis=i))
其中包含了几个常见的numpy用法:
numpy中最基本的类是ndarray,比如上面的data对象,它能表达多维矩阵。arrange,用来生成序列,和Python的range相似。reshape,用来调整矩阵形状,比如3行x4列。ndim和shape属性分别代表维度(也叫轴),以及各维度上的数据长度。sum方法能直接累加所有数据,如果指定axis参数则在某维度累加,结果比原数据降一维。
除了sum,还有一系列类似的统计函数,方便对矩阵数据统计:
import numpy as np# 随机生成4x4的矩阵,元素值范围[1,100)data = np.random.randint(1, 100, size=(3,4))print(data)# 查找最小元素print(f'最小值:{np.amin(data)}')# 按第2维度查找每行最小值print(f'每行最小值:{np.amin(data, 1)}')# 按第1维度查找每列最小值print(f'每列最小值:{np.amin(data, 0)}')# 查找中位数print(f'中位数:{np.median(data)}')# 查找算数平均值print(f'算数平均值:{data.mean()}')# 加权平均值 average=sum(x*wt)/sum(wt)wt = np.array([1, 2, 3, 4])print(f'加权平均值:{np.average(data, axis=1, weights=wt)}')# 方差 var=mean((x - x.mean())**2)print(f'方差:{np.var([1,2,3,4])}')# 标准差 std=sqrt(var)print(f'标准差:{np.std([1,2,3,4])}')
索引和切片
和Python中list一样,numpy数组也支持索引和切片访问数据。
import numpy as nparr = np.arange(10)print(f'1维数组:{arr}')# 单值索引print(f'单值索引:{arr[3]}')# 多值索引print(f'多值索引:{arr[[1, 2, 4]]}')# [3, 8),步进2s = slice(3,8,2)print(f'切片索引:{arr[s]}')# 等价于print(f'等价于:{arr[3:8:2]}')# 布尔索引print(f'找出大于3的元素:{arr[arr>3]}')# 数组索引,用数组值当下标索引# 与切片不同,会把结果复制到新数组print(f'数组索引:{arr[[7, 5, 7]]}')# 2维矩阵索引arr2 = np.arange(20).reshape(4,5)print(f'2维矩阵{arr2}')# 多维索引:第3、4行,第4、5列print(f'多维索引:{arr2[2:4, 3:5]}')# 获取(0,1)和(2,3)两个坐标元素print(f'获取坐标{arr2[[0, 2], [1,3]]}')# 数组索引,用数组值当行下标print(f'2维矩阵数组索引:{arr2[[3,0, 1]]}')# 第4列后数据print(f'第4列后:{arr2[:, 3:]}')# 看上去省略号和纯冒号效果一样,其实不同print(f'省略号效果:{arr2[..., 3:]}')# 3维矩阵看省略号和冒号不同arr3 = np.arange(24).reshape(2,3,4)print(f'3维矩阵:{arr3}')print('省略号用法')print(arr3[..., 3:])print('冒号用法')print(arr3[:, :,3:])
在数据分析中,我们经常会用布尔索引清理数据,比如剔除一些无效数据:
import numpy as np# np.nan一般表示缺失元素arr = np.array([1, 2, np.nan, 3])# 剔除非数字元素print(arr[~np.isnan(arr)])
排序和筛选
import numpy as nparr = np.random.randint(1, 100, (3,4))print(f'原数据:{arr}')# 默认按最后轴用quicksort算法排序# 用np.sort会生成副本,不改变原数据print(f'np.sort生成副本:{np.sort(arr)}')# axis=1按行排序arr.sort()print(f'就地排序后:{arr}')# axis=0按列排序arr.sort(axis=0)print(arr)# 筛选元素,返回坐标序列x, y = np.where(arr>60)# 根据坐标索引元素print(f'条件筛选: {arr[x, y]}')# 多个条件的逻辑组合x, y = np.where((arr>60) & (arr<80))print(f'组合条件筛选:{arr[x,y]}')# 用where实现类似Python的三元操作a = np.array([1,2,3])b = np.array([4,5,6])cond = np.array([True, False, True])print(f'where三元操作:{np.where(cond, a, b)}')# 等同于这样的Python实现result = [(ia if ic else ib) for ia, ib, ic in zip(a, b, cond)]print(f'同等Python实现:{result}')# 根据条件筛选元素,如挑选偶数print(f'布尔矩阵:{arr%2==0}') # 生成布尔矩阵# 根据布尔值抽取元素print(f'偶数:{np.extract(arr%2==0, arr)}')# 去重复元素data = np.array([1,2,3,1,2,3])print(np.unique(data))
其中where的条件筛选中,逻辑运算可以用&(并且)、|(或者)等运算符组合。
字符串
前面的功能介绍主要集中在数字类型功能上,numpy也支持其他数据类型,如时间、字符串等。
可以通过ndarray.dtype查看数据类型,如np.int64、np.int8、np.float64等。
字符串的数据类型对应numpy.string_、numpy.unicode_:
import numpy as nparr = np.array(['hello', 'world3'])isinstance(arr[0],np.unicode_) # True
常用操作包括:大小写转换、查找替换、前后去空格、分割合并等。
import numpy as nparr = np.array(['Python', ' 1,024 ', '程一初', '只差一个程序员了', '数据分析系列'])print(f'原数据{arr}')# 大小写转换print(f'大写:{np.char.upper(arr)}')print(f'小写:{np.char.lower(arr)}')# 查找替换print(f'查找:{np.char.find(arr, "程序")}')print(f'替换:{np.char.replace(arr, "分析", "处理")}')# 前后去空格print(f'前后去空格:{np.char.strip(arr)}')# 分割合并sep = np.char.split(arr, ",")print(f'分割:{sep}')print(f'合并:{np.char.join("-", sep)}')
相比Python列表,numpy大部分操作都是直接修改原数据,不产生副本,达到高性能省空间效果。
常见产生副本的场景主要有4类,可以通过id函数验证:
np.array,让它接受一个ndarray作为参数时,会产生副本np.asarray则不产生副本。- 数组索引,会生成副本。
ndarray.copy方法可以主动生成副本。- 调用
np顶层方法,比如用np.sort、np.char,会返回数据副本。
当然,numpy还支持更多线性代数和矩阵运算,建议先掌握上述最常用功能,其他需要时查找即可。
Pandas基本用法
pandas基于numpy构建,使用风格很相似,此外增强了表格数据处理能力。
如果把numpy看成是Python内置list的升级版,那么pandas就是dict的升级版,它支持更复杂数据类型,以及更丰富的数据顺序。pandas中最主要的两个数据结构:Series、DataFrame。
可以借助inspect标准模块查看它们的继承结构:
import inspectimport pandas as pds = pd.Series([1, 2, 3])print(inspect.getmro(type(s.index)))print(inspect.getmro(type(s.values)))print(inspect.getmro(pd.Series))print(inspect.getmro(pd.DataFrame))
Series基本使用
Series是加了索引的1维数组,就像dict,key是索引,value是ndarray。
import pandas as pds = pd.Series([1, 2, 3])print(s.index, s.values)s2 = pd.Series([4,5,6], index=['x', 'y', 'z'])print(s2.index, s2.values)
Series默认使用从0开始的整数序列作为索引,也能指定索引。
访问数据时,既可以用dict形式也可以用numpy形式:
import pandas as pd# 默认用0开始的整数序列作为indexs = pd.Series([1, 2, 3])print(s.index, s.values)# 指定indexs2 = pd.Series([4,6,8,5], index=['x', 'y', 'z','a'])print(s2.index, s2.values)# 从dict创建,key即索引s3 = pd.Series({'x':4,'y':6,'z':8,'a':5})print(s3)print(f'比较s3和s2\n{s3==s2}') # 每个元素都相等print(f'但非同一对象:{id(s2)==id(s3)}') # False# dict式访问数据print(s[0], s2['x'])# 判断index是否在seriesprint('x' in s2) # True# numpy式访问数据print(s2[1:]) # 5,6print(s2[s2>4]) # 5,6print(s2[(s2>4) & (s2<6)]) # 5# 排序print(f'按index排序:\n{s2.sort_index()}')print(f'按value排序:\n{s2.sort_values()}')
当两个Series执行计算,如相加,pandas会按索引对齐数据。
import pandas as pds1 = pd.Series([4,6,8], index=['x', 'y', 'z'])s2 = pd.Series([1,3,5,7,9], index=['a','x','y','b', 'c'])print(f's1+s2:\n{s1 + s2}')
注意,由于s2没有z索引,所以结果里z索引值也为NaN(Not a Number),pandas会用NaN表示缺失数据。
可以用isnull和notnull判断缺失数据,处理时可以丢弃也可以填充。
import pandas as pds = pd.Series([1,2,None,4,4])print(s)print(f'isnull判断:\n{s.isnull()}')print(f'notnull判断:\n{s.notnull()}')print(f'过滤缺失值1:\n{s[~s.isnull()]}')print(f'过滤缺失值2:\n{s[s.notnull()]}')# 填充或删除操作默认会产生副本,可用inplace=True参数就地修改原数据print(f'用0填充缺失值:\n{s.fillna(value=0)}')print(f'向前填充缺失值:\n{s.fillna(method = "ffill")}')print(f'向后填充缺失值:\n{s.fillna(method = "bfill")}')# 删除缺失值print(f'删除缺失值:\n{s.dropna()}')# 删除重复值print(f'删除重复:\n{s.drop_duplicates()}')
DataFrame基本使用
DataFrame是一种表格型数据结构,行和列都有索引,可以看成多个Series共享了一套索引。
你可以简单把它理解成升级版2维Excel表,但其实它能用层次化索引处理更高维数据。
访问DataFrame内数据主要有4种形式:
- 像
dict一样用关键词索引; - 像
numpy一样切片、布尔索引和数组索引; - 通过
loc、iloc属性,按标签名和下标切片索引; - 通过
`at、iat属性,直接获取某个坐标值。import numpy as npimport pandas as pddata = {'文章ID': ['WX10001', 'WX10002', 'WX10003', 'WX10004'],'标题': ['标题1', '标题2', '标题3', '标题4'],'阅读量': [1000, 800, 1400, 800]}# 从dict创建,默认索引是从0开始的整数序列df = pd.DataFrame(data)print(df)print(f'所有列:{df.columns}')print(f'行和列都有索引:{type(df.columns), type(df.index)}')print(f'值是2维ndarray:{type(df.values), df.values.shape}')# 指定列及其顺序,指定indexdf = pd.DataFrame(data, columns=['标题', '文章ID','阅读量','点赞量'],index=['a','b','c','d'])print(df) # "点赞量"列值NaN# 列索引,用dict或属性操作形式访问print(df['标题'] == df.标题)# 用dict形式判断是否在列索引中print(f'判断是否在列中:{"阅读量" in df.columns}')# 每个列是一个Seriesprint(f'列的数据类型:{type(df["标题"])}')# 整列赋值df['点赞量'] = np.random.randint(100,1000,4)print(df)df['在看数'] = pd.Series([100,200,300], index=['a','b','c'])df['是否爆文'] = df['阅读量'] >=1000print(df)# 删除列del df['是否爆文']print(df)print(f'drop列:{df.drop("标题", axis=1)}')# 删除行,drop默认会生成副本# inplace参数可以就地修改原数据print(f'drop行:{df.drop("a")}')# 行索引print(f'切片行索引:\n{df[2:4]}')# 按下标索引,效果相同,但更通用print(f'iloc行索引:\n{df.iloc[2:4]}')# 行列索引,支持切片和数组索引混合print(f'iloc行列索引:\n{df.iloc[2:4,[0,2,3]]}')print(f'iloc数组索引:\n{df.iloc[[2,3],[2,3]]}')print(f'loc行索引:\n{df.loc["a"]}')# 按标签索引,标签切片包含两端[a,b],而非[a,b)print(f'loc行索引:\n{df.loc["a":"b",["标题","阅读量"]]}')# 访问某个值print(f'at访问:{df.at["a","标题"]}')print(f'iat访问:{df.iat[0,2]}')# 扩充和缩减索引print(f'缩减行和列:\n{df.reindex(index=["a","b"],columns=["标题","阅读量"])}')print(f'扩大行和列:\n{df.reindex(index=["d","e"],columns=["标题","新增列"])}')print(f'自动填充:\n{df.reindex(index=["d","e"],columns=["阅读量"], fill_value=0)}')
实战中,我们可以先选出需要的列,然后用条件筛选数据。```python import pandas as pd df = pd.DataFrame(np.arange(12).reshape(3,4), index=list(‘XYZ’), columns=list(‘ABCD’)) print(df)
布尔筛选
print(f’大于5的元素:\n{df[df>5]}’) print(f’A大于5的元素:\n{df[df.A>5]}’)
isin筛选出元素范围
print(f’A列值匹配选项:\n{df[df.A.isin([4,5,6])]}’)
组合筛选
print(f’A大于5或B大于4的C和D列:\n{df[[“C”,”D”]][(df.A>5)|(df.B>4)]}’)
`DataFrame`间可进行算数计算,与`Series`间计算也适用“广播原则”。```pythonimport pandas as pddf = pd.DataFrame(np.arange(12).reshape(3,4),index=list('XYZ'), columns=list('ABCD'))print(f'两个形状相同的df相加:\n{df + df}')# df和series相加,默认按行相加print(f'df和同形series相加:\n{df + df.iloc[0]}')# 如果series形状相同,但列标签不同,结果是索引并集,填充NaNs = pd.Series(range(4), index=list('BCDE'))print(f'df和通型不同index的Series相加:\n{df + s}')# df和series按列相加s2 = pd.Series(range(3), index=list('XYZ'))print(f'df和series按列相加:\n{df.add(s2, axis="index")}')
numpy的顶级函数可直接作用于DataFrame,此外可以通过apply和applymap两个方法分别作用于行列和单个元素。```python
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(1,100,(3,4)),
index=list(‘XYZ’), columns=list(‘ABCD’))
print(df)
对每列统计
print(df.describe())
统计方法默认对行操作得出每一列结果汇总
print(f’每列算数平均值:\n{df.mean()}’) print(f’每行求和:\n{df.sum(axis=”columns”)}’) print(f’每列累加:\n{df.cumsum()}’) print(f’每列累积:\n{df.cumprod()}’)
统计某一列各值出现次数
print(f’A列各值频率:\n{df[“A”].value_counts()}’)
列元素去重
print(f’A列元素去重:\n{df[“A”].unique()}’)
numpy的全局函数可以应用在dataframe
np.sort默认就地修改原数据
print(f’按行排序\n{np.sort(df)}’)
sort_values保持数据间关联
print(f’按某列排序\n{df.sort_values(by=”A”)}’)
sort_index保持数据关联
print(f’按行索引排序\n{df.sort_index(ascending=False)}’) print(f’按列索引排序\n{df.sort_index(ascending=False,axis=1)}’)
对每行/列应用函数,如计算最大最小差
f = lambda x: x.max() - x.min()
默认按行计算,得出每列结果
print(f’每列最大最小差:\n{df.apply(f)}’)
按列计算,得出每行结果
print(f’每行最大最小差:\n{df.apply(f,axis=”columns”)}’)
describe的简单实现
f = lambda x: pd.Series([x.min(), x.max(),x.mean(),x.std(),x.count()], index=[‘min’,’max’,’mean’,’std’,’count’]) print(f’简单的describe:{df.apply(f)}’)
元素级映射
fmt = lambda x: f’{x:.2f}’ print(f’2位小数:\n{df.applymap(fmt)}’)
单列元素级映射
print(f’单列格式化2位小数:\n{df[“A”].map(fmt)}’)
`pandas`中对字符串的操作,通过`Series.str`操作,基本与Python内建`str`方法同名。```pythonimport pandas as pds = pd.Series(['Python','1,024','程一初','只差一个程序员了','数据分析系列'])print(f'原数据\n{s}')# 大小写转换print(f'大写:\n{s.str.upper()}')print(f'小写:\n{s.str.lower()}')# 查找替换print(f'查找:\n{s.str.find("程序")}')print(f'替换:\n{s.str.replace("分析", "处理")}')# 前后去空格print(f'前后去空格:\n{s.str.strip()}')# 分割合并sep = s.str.split(",")print(f'分割:\n{sep}')print(f'合并:\n{sep.str.join("-")}')# 连接各元素print(f'合并所有元素:\n{s.str.cat(sep=",")}')# 根据是否包含字符串生成布尔矩阵print(f'根据包含字符串生成布尔矩阵:\n{s.str.contains("程序")}')
pandas中大部分的操作都不会修改原数据,而是生成副本,需要就地修改原数据时可以添加inplace参数。
上面是pandas的基础功能和常见用法,包括:索引切片访问、筛选过滤、统计函数、缺失和字符串处理等,这些功能会贯穿数据分析的整个过程,需要熟练掌握。
更多分析功能会放在数据分析章节中介绍,比如:合并(Merge)、分组(Group by)、重塑(Reshaping)、透视表(Pivot Table)、时间序列(TimeSeries)、分类(Categorical)等。
数据清理实战操作
Python处理数据的第1步,是把数据装入内存。pandas提供了多种主要数据格式读写功能,包括:CSV、JSON、HTML、Excel、HDF、SQL、SAS等,甚至还支持本地剪切板。
负责对应文件格式读写的函数分别由read_和to_开头,比如:
- CSV格式读写:
read_csv、to_csv - HTML格式读写:
read_html、to_html - 以此类推。
比如我们从CSV文件读取数据,然后快速看看前10行的模样:
import pathlibimport pandas as pdpath = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/004preproc')csv_path = path.joinpath('test.csv')df = pd.read_csv(csv_path)df.head(10)
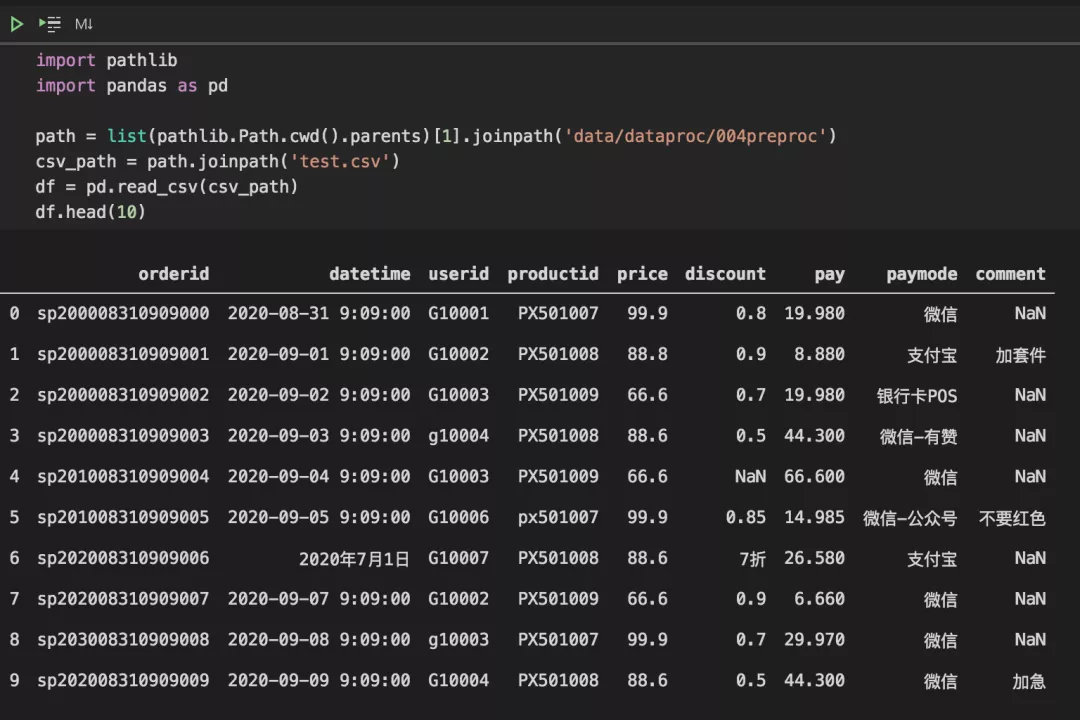
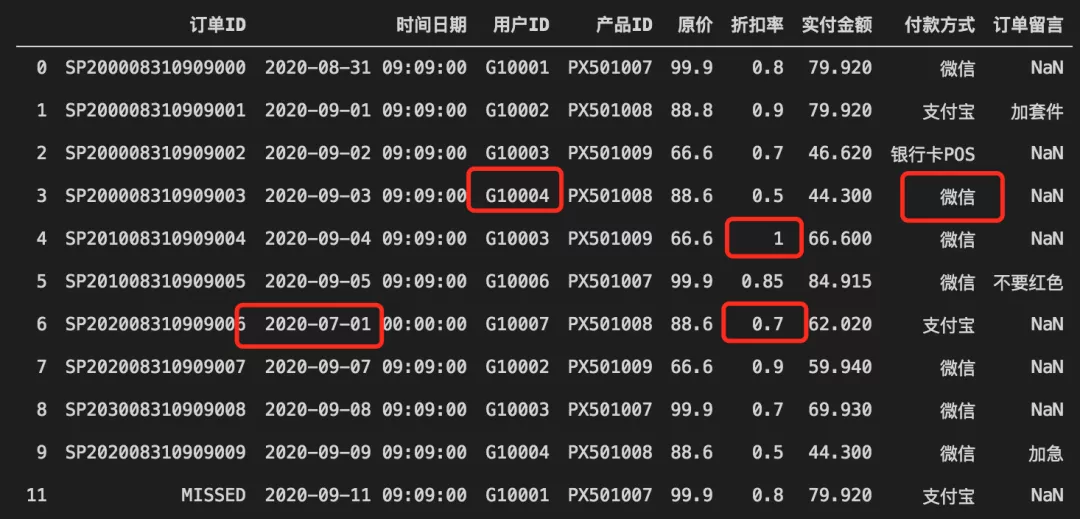
可以看到,数据并不规整,比较杂乱。
一般而言,数据源越少、导出数据的系统越成熟,数据就会相对规整。
但,大部分情况下,我们都会面临历史遗留数据,经常会出现这些不规整情况:
- 数据结构不一致,有些字段在后期运营过程中加入,之前的数据就会出现空值;
- 数据格式不一致,如开始用户编号没设计好,达到极限后重新设计编码,导致前后格式不一致;
- 部分数据由用户直接输入,会出现如空格、格式符号、全/半角、中英文标点等数据;
- 有些数据导出自不同表格,会出现重复现象,甚至逻辑矛盾不一致;
- 有些系统数据包含多国语言或多国货币符号;
- ……还有无数可能出现情况……
总之:数据不规整,是常态,如果遇到像上面这样的,值得庆幸。
那该如何清理数据?有什么标准流程?
其实,数据清理工作,并没有统一标准,不同业务、不同经验的人,处理同一份数据可能都会得到不一样的结果。
但面对常见的场景,行业内有一些通用方法和原则:
- 打开数据后,先直观感受,尝试从业务角度理解数据,比如有多少字段、每个字段什么意思、字段间是否有关联等。
- 明确分析的目标,找到目标相关的字段,可以另行标注记录方便查找。
- 观察相关数据不规整的具体情况,建议列出清单,方便自己后续逐项检查,如某列大小写不一致、某列存在缺失数据、某列数字格式不一致等。
- 根据清单逐项检查不规整情况,用Python处理完毕。
- 保存预处理后的数据,如果数据量大,建议过程中保存多个副本,对应清单某项或某几项的不规整处理结果。
从数据前几行以及表头看,案例数据是一份电商交易数据。
我们可以先调用df.info()、df.describe()等方法查看数据分布。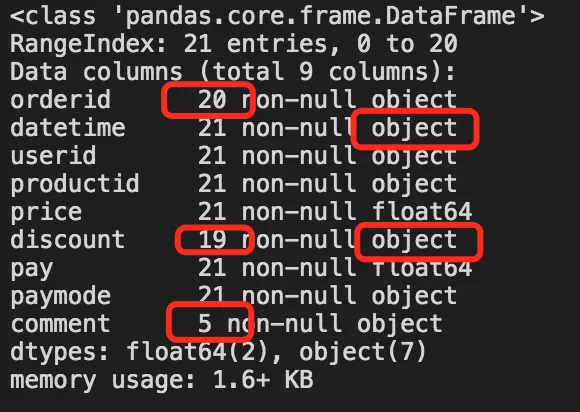
运行后发现上面案例数据里有几个潜在不规整现象:
discount列和comment列存在缺失数据;datetime列数据类型为object,后续尝试转换为日期类型;discount列数据应为数字,但却是object类型,说明有数据格式不一致。
先不着急处理这些问题,我们检查下每一列数据,看看各个值的出现频率。
在统计频率前,我们先把每列的大小写转换好,不然会因为大小写影响统计结果。
此外,可以把表头换成更容易理解的名字,降低阅读门槛。
colname_dict = {'orderid':'订单ID', 'datetime':'时间日期','userid':'用户ID','productid':'产品ID','price':'原价','discount':'折扣率','pay':'实付金额','paymode':'付款方式','comment':'订单留言'}# 重命名列名称df.rename(columns=colname_dict, inplace=True)# '订单ID'列有数据缺失,如果直接转大小写,会提示float对象无upper方法# 因为缺失数据用NaN代表,它是float类型。# 用isnull生成布尔矩阵,用any判断是否存在Trueprint(df['订单ID'].isnull().any())# 这里订单ID不影响统计,可指定缺省值,如MISSEDdf['订单ID'].fillna('MISSED', inplace=True)# ID类信息,全部转为大写模式,去前后空格df[['订单ID','用户ID','产品ID']] = df[['订单ID','用户ID','产品ID']].applymap(lambda x : x.upper().strip())
注意:在大小写转换等过程中,如果发生异常,也可能意味着部分列中存在数据缺失或格式错误,如案例中“订单ID”列。
经过基本转换后,数据更容易观察了: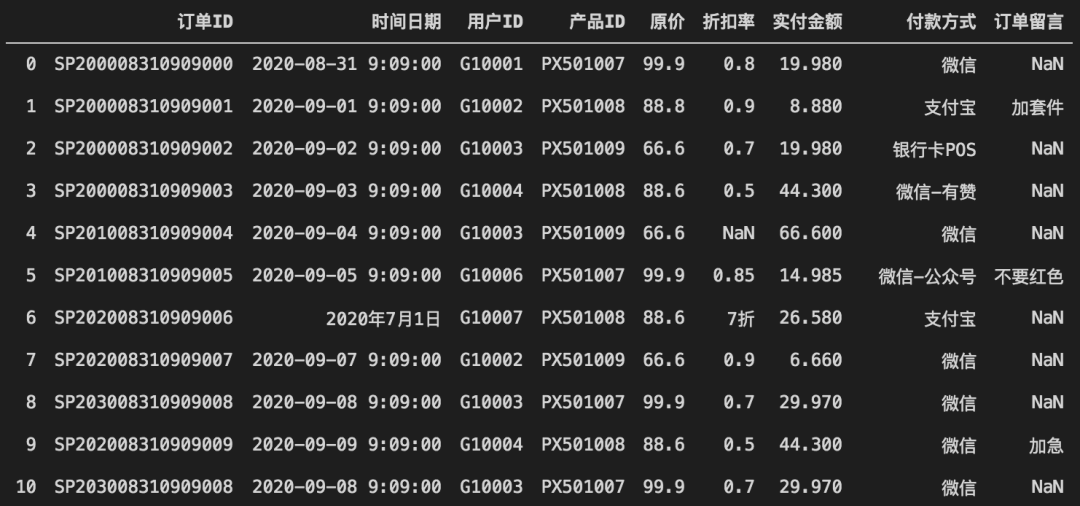
然后,我们可以观察每列数据频率:
for n, s in df.items():# 列名称和对应列Seriesprint(f'----{n}----')print(s.value_counts())
从输出中,可以进一步看到数据不规整的现象,比如订单ID有重复、折扣率里有中文格式。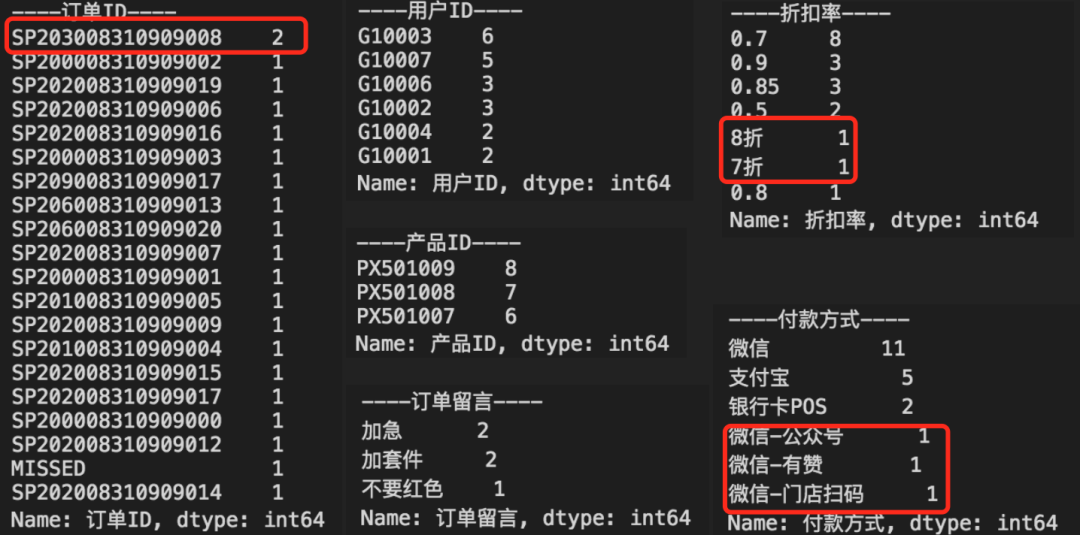
也可以从中看到一些基本统计信息,进一步帮助理解数据,比如:
- 哪些用户下单频率更高?
- 哪些产品订单更多?
- 常见客户留言是什么?
- 有哪些支付渠道更多?
很多时候,这些看似简单的信息,能在分析过程中起到关键作用。
接下来,就可以开始逐项处理清单内的任务,比如:
- 订单去重
- 日期时间格式转换
- 折扣率转为数字格式
- 合并部分付款方式,如微信
# 订单去重# 默认保留第一次出现的项,修改原数据df.drop_duplicates('订单ID', inplace=True)# 日期时间格式转换# 通常情况下,用自动推断日期格式,或指定某个格式format='%Y-%m-%d'即可# df['时间日期'] = pd.to_datetime(df['时间日期'], infer_datetime_format=True)# 但如果遇到多种格式数据,就得分情况匹配def to_date(x):import dateutiltry:result = pd.to_datetime(x, infer_datetime_format=True)except dateutil.parser.ParserError:try:result = pd.to_datetime(x, format='%Y年%m月%d日')except dateutil.parser.ParserError as e:print('日期格式解析失败', e)return resultdf['时间日期'] = df['时间日期'].map(to_date)# 用实付金额/原价,填补折扣率缺失值disc_f = lambda x: x['实付金额']/x['原价']df_cond = df['折扣率'].isnull() # 布尔矩阵# 计算缺失值,返回Seriess_disc = df[df_cond].apply(disc_f,axis='columns')# 为Series设置名字后,就可以用update方法就地更新数据s_disc.name = '折扣率'df.update(s_disc)# 折扣率转为数字格式df_cond_chn = df['折扣率'].str.contains('折').fillna(False)disc_chn_f = lambda x: float(x.replace('折',''))/10s_disc_chn = df[df_cond_chn]['折扣率'].map(disc_chn_f)s_disc_chn.name = '折扣率'df.update(s_disc_chn)# 合并微信付款方式paym_cond = df['付款方式'].str.contains('微信-')s_paym = df[paym_cond]['付款方式'].map(lambda x: x.split('-')[0])s_paym.name = '付款方式'df.update(s_paym)
总结
本文介绍了numpy和pandas两大数据利器的基本使用,包括索引切片、筛选过滤、统计函数、缺失和字符串处理等常见操作。
同时通过案例数据,演示了实战中数据清理的思路、通用方法,以及常见操作。
数据清理完毕后,就可以进入数据分析环节。
实战中,数据往往会更复杂,需要耐心多尝试一些方法,比如:
- 看多几行数据,比如随机排序或采样抽检数据
- 多观察列和列之间的关系
- 对每个列多做些测试或验证,比如排序、排名、筛选等
- 对于无关分析结果的数据,可以直接按丢弃处理
- 对于部分缺失数据,可用中位数、平均数等填充
扫码加入学习群,前100名免费。

若有收获,就点个赞吧
0 人点赞
