1. 数据定义语言DDL: 数据定义语言DDL用来创建数据库中的各种对象——-表、视图、索引、同义词、聚簇等如: CREATE TABLE/VIEW/INDEX/SYN/CLUSTER DDL操作是隐性提交的!不能rollback
2 .数据操纵语言DML,数据操纵语言DML主要有三种形式: 1) 插入:INSERT 2) 更新:UPDATE 3) 删除:DELETE
_3,GTID 的作用:每一个 DML/DDL 操作都增加 一个唯一标记,叫作 GTID,这个标记在整个复制环境中都是唯一的,可以直接通过 GTI 定位到需要发送的 binary log 位置,_binary log 关闭,不生成GTID
4,Event:在主从间, Event 起到了 载体的作用,它们在主从之间传递, 可以说是一组协议 这里将用一定的篇幅来解释常用 vent 。针对每 Event 会给出 函数接口,为想调试的用户提供函数入口,即对应于redolog的多种redo日志类型
Query Event:记录语句,第一条语句的修改时间,环境状态
Map Event:映射table id和实际访问表
Write Event:插入的event
Delete Event:删除的event
Update Event:更新的event
XID Event:记录innodb与 binlog之间的事物的一致性,主要用于恢复
一条Delete Event需要写的Event数:其中GTID直接写入log,而不需要写入buffer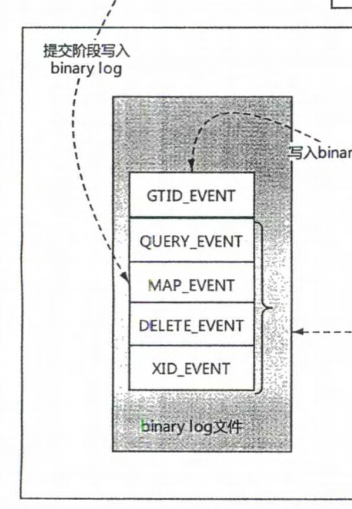
5,binlog cache:envent 中转站,
6,事务提交的流程
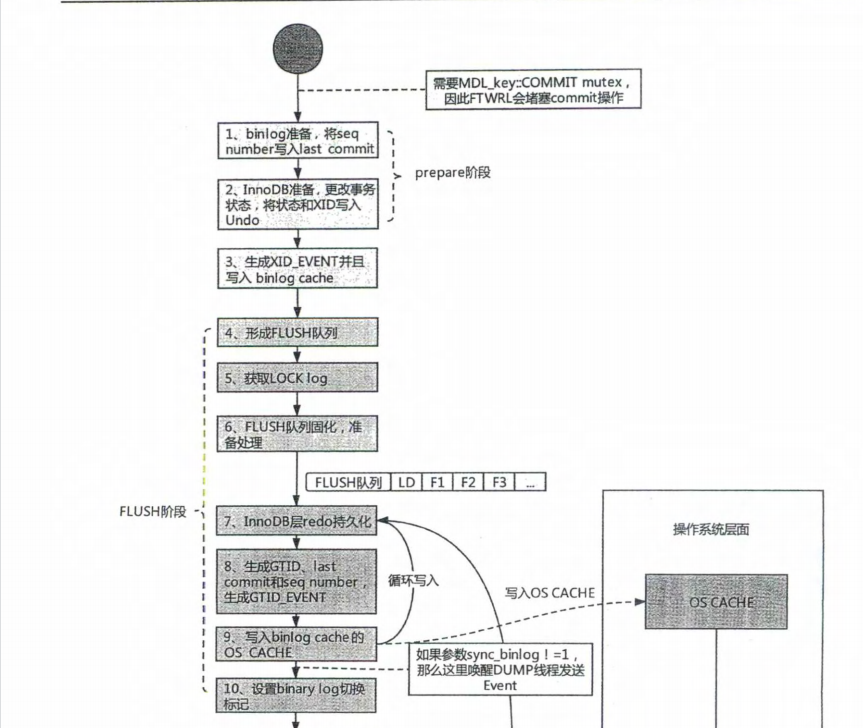
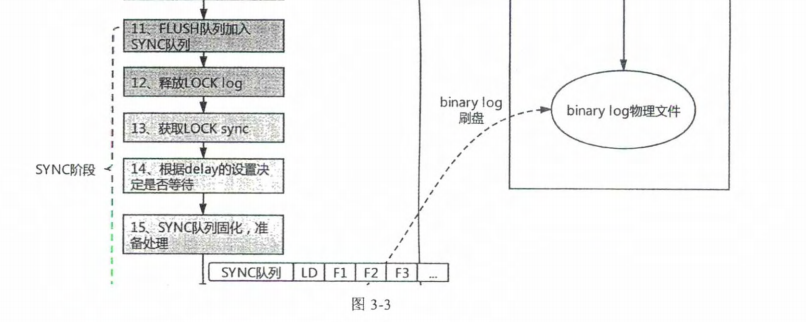

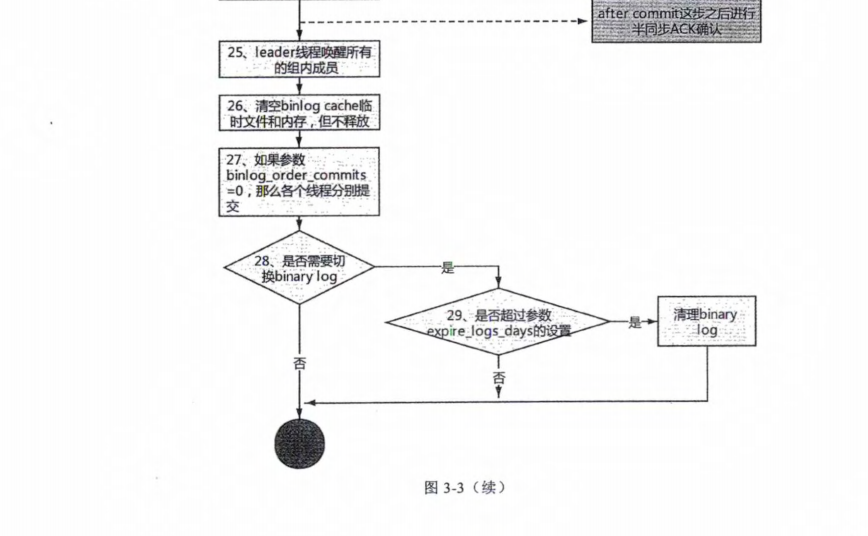
7,概念对比
gtid全局唯一事务号,没什么可说的,两个不同事务的gtid必定不相同,MySQL官方版本binlog中形式这样_
sequence_number
last_committed=1155164 sequence_number=1155168
这个在每个binlog产生时从1开始然后递增,每增加一个事务则sequencenumber就加1,你可能好奇有了gtid何必多此一举再加个sequencenumber来标识事务呢,请看下面
lastcommitted
这个在binlog中用来标识组提交,同一个组提交里多个事务gtid不同,但lastcommitted确是一致的,MySQL正是依据各个事务的lastcommitted来判断它们在不在一个组里;一个组里的lastcommitted与上一个组提交事务的sequencenumber相同,这样sequencenumber就必须存在了:
8,并行处理:详情见WRITESET
9,主库的 DUMP 线程,负责发送redolog:
检查从库的 GTID SET 是否大于主库的 GTID SET• 根据主库的 gtid_purged 量检查 从库需要的 Event 是否已经被清理• 实际扫描主库的 binary log, 检查从库需要的 Event 是否已经被清理• 过滤 GTID, 决定发送哪些事务给从库。
10,从库:
- 并行回放:seq last commit,一句并行复制
- 如果 last commit 小千或等于 rrent_lwm 则表示可以并行回放,继续。
- 如果 last commit 大千 current_ wm, 则表示不能并行回放,需要等待。
11,主从延迟:

此外aliSQL给了我们一些思想火花:
1,apply时,先应用系统表空间,再是用户表空间,确保先形成先形成undo段可以回滚
2,文件循环写问题:1)归档 2)不循环 3)切换文件性能,文件回收池 4)清理日志文件不允许清理超过checkpoint,并且不允许清理未传到备库的文件 5)由于可能会被清理,所以需要新建一个check point文件,因为传统文件存储在checkpoint0上
3,节点的三种状态:master slave maste-salve
4,备库的鉴权
5,防止后台进程对数据修改:不允许开启purge线程,这个不太理解
6,对元数据信息的修改:MySQL在Server层另外冗余了一些元数据信息,需要记录到redo中,其实在binlog中也会有
7,DDL复制,当MySQL在执行DDL修改元数据时,是不允许访问表空间的,这种行为需要在备库中保持一致,在修改元数据前后需要通过日志传递锁。这时候从库崩溃,如何继续保持此排它锁
8,Cache失效,从库更新完数据库后,需要感知cache失效
9,权限操作:需要执行acl reload
10,crud存储过程:需要更新缓存
11,表级统计信息:需要通过日志传递
12,mvcc:需要传递事务的开始与结束的日志,确保事务日志结束后,可以更新read view。主库崩溃?:崩溃恢复后,初始化事务的状态
13,Purge控制
14,B+树结构变更:page合并或分裂,禁止用户线程对btree进行检索,当主库上的mtr在commit时,如果是持有索引的排他锁,并且一个mtr中的变更超过一个page时,则将涉及的索引id写到日志中;备库在解析到该日志时,会产生一个同步点:完成已经解析的日志;获取索引X锁;完成日志组Apply;释放索引X锁。
15,change buffer:不懂
Wal日志的类型
| 资源管理器ID主要用于日志系统中 #define RM_XLOG_ID 0 该条日志记录的是一个检查点信息。 #define RM_XACT_ID 1 该条日志记录的是一个事物的提交或者终止信息 #define RM_SMGR_ID 2 #define RM_CLOG_ID 3 CLOG中某一页的初始化 #define RM_DBASE_ID 4 #define RM_TBLSPC_ID 5 #define RM_MULTIXACT_ID 6 #define RM_RELMAP_ID 7 #define RM_STANDBY_ID 8 #define RM_HEAP2_ID 9 #define RM_HEAP_ID 10 该条日志记录的是对队中元组进行修改的信息 #define RM_BTREE_ID 11 该条日志记录的是对BTree进行修改 #define RM_HASH_ID 12 #define RM_GIN_ID 13 #define RM_GIST_ID 14 #define RM_SEQ_ID 15 info位: #define RM_XLOG_ID 0 该条日志记录的是一个检查点信息。 #define RM_XACT_ID 1 该条日志记录的是一个事物的提交或者终止信息 #define RM_SMGR_ID 2 #define RM_CLOG_ID 3 CLOG中某一页的初始化 #define RM_DBASE_ID 4 #define RM_TBLSPC_ID 5 #define RM_MULTIXACT_ID 6 #define RM_RELMAP_ID 7 #define RM_STANDBY_ID 8 #define RM_HEAP2_ID 9 #define RM_HEAP_ID 10 该条日志记录的是对队中元组进行修改的信息 #define RM_BTREE_ID 11 该条日志记录的是对BTree进行修改 #define RM_HASH_ID 12 #define RM_GIN_ID 13 #define RM_GIST_ID 14 #define RM_SEQ_ID 15 info 高4位 #define XLOG_XACT_COMMIT 0x00 //事务提交 #define XLOG_XACT_PREPARE 0x10 //预备 #define XLOG_XACT_ABORT 0x20 //事务取消 #define XLOG_XACT_COMMIT_PREPARED 0x30 //准备提交事务 #define XLOG_XACT_ABORT_PREPARED 0x40 //准备取消事务 #define XLOG_XACT_ASSIGNMENT 0x50 //不详。。。(之后补充) #define XLOG_HEAP_INSERT 0x00 //插入元组日志 #define XLOG_HEAP_DELETE 0x10 //删除元组日志 #define XLOG_HEAP_UPDATE 0x20 //更新元组日志 细心的同学会发现,下面的元组操作和上面的事务操作的编码(0x00)重复了,不要忘记之前我们说过,要通过xl_rmid字段来判断属于何种操作:先判断属于那种操作,在做具体的操作内容。 |
|---|
最后不同redo的解决方式是最关键的,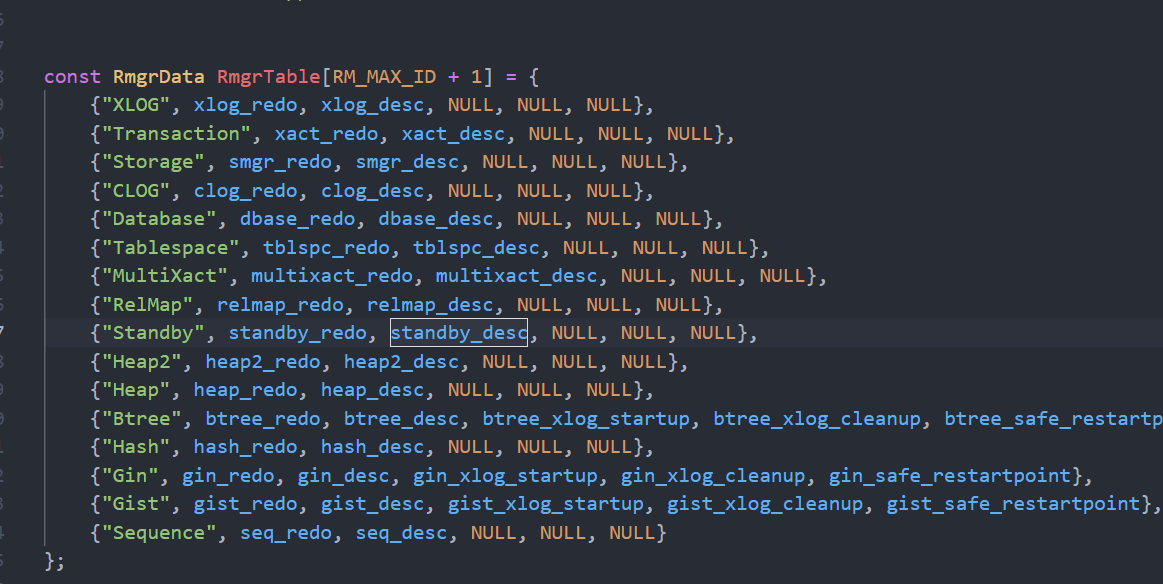
最后让我们再重新温习一下mysql的基础知识,因为redo日志的过程设计到方方面面

若有收获,就点个赞吧
0 人点赞
