mysql事物日志:
1,基本概念: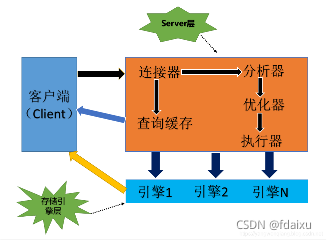

redo log:重做日志 数据页的修改 物理日志
undo log:回滚日志,记录某行的版本
binlog:存储引擎之上的日志,redo是innodb的日志,先记录binlog再记录redo 逻辑日志
redolog binlog:事物提交后写入binlog redolog则是事物提交前修改数据了就写入日志 redolog不同事物之间是并发写入的。redolog满足幂等性,数据页就是标识,而binlog不满足 逻辑日志
2,redolog: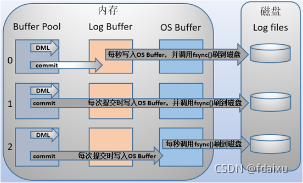
组成:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。force log at commit 先写日志 再提交事物 持久性
缓存通过os系统调用fsync从用户空间刷新到磁盘中,缓冲到达一定程度才写到日志文件,redolog一般指缓冲buffer
innodb_flush_log_at_trx_commit:用户通过控制该变量来实现不同的刷新策略,
主从复制结构中,要保证事务的持久性和一致性,需要对日志相关变量设置为如下,如果启用了二进制日志,则设置sync_binlog=1,即每提交一次事务同步写到磁盘中。
总是设置innodb_flush_log_at_trx_commit=1,即每提交一次事务都写到磁盘中。每次提交都写入了bin和redo log中,保证了两个日志的同步以及恢复的一致。
测试效率:即每次提交都刷日志到磁盘 10w数据 15.48s
每次提交都刷新到os buffer,但每秒才刷入磁盘中 3.41s ,
每秒才刷到os buffer和磁盘 2.10s 最后两个相差不多但是每次提交都刷新到os 更安全,因为用户空间可能宕机
但是每秒会丢失上万条数据,因此最好设置为1,并且将存储过程提交次数,尽可能减少
注:用户空间表示用户的代码和数据,内核空间是内核的代码和数据,用户态下的代码和数据有可能丢失 宕机
3,日志块(log block):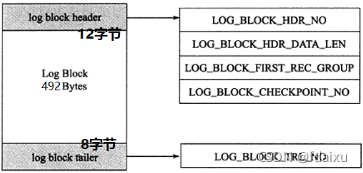
log_block_hdr_no:(4字节)该日志块在redo log buffer中的位置ID。
log_block_hdr_data_len:(2字节)该log block中已记录的log大小。写满该log block时为0x200,表示512字节。
log_block_first_rec_group:(2字节)该log block中第一个log的开始偏移位置。
lock_block_checkpoint_no:(4字节)写入检查点信息的位置。
每个redo log block由3部分组成:日志块头、日志块尾和日志主体,所以不管是log buffer中还是os buffer中以及redo log file on disk中,都是这样以512字节的块存储的。因为redo log记录的是数据页的变化,当一个数据页产生的变化需要使用超过492字节()的redo log来记录,那么就会使用多个redo log block来记录该数据页的变化。如果一个数据页记录不完一个数据页产生的日志,那么就可以分两个,某一数据页产生了552字节的日志量,第一个日志块占用492字节,第二个日志块需要占用60个字节,那么对于第二个日志块来说,它的第一个log的开始位置就是73字节(60+12)如果该部分的值和 log_block_hdr_data_len 相等,则说明该log block中没有新开始的日志块,即表示该日志块用来延续前一个日志块。日志尾no和日志头相同
4, log group和redo log file: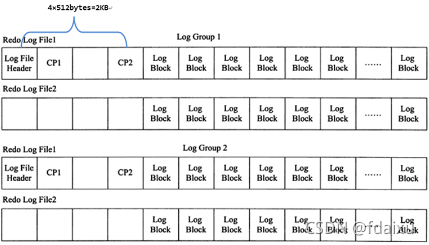
一个组内logfile数量和大小都可以设置,默认是两个日志文件,每个组的日志文件会记录满切换到下一个,logfile太大就恢复的太慢,太小容易经常切换日志文件。文件太大打开的时候太慢,文件小了一个个的一个个打开快,切换logfile是通过循环的方式切换的
5,redolog的格式:
log block中492字节的部分是log body,该log body的格式分为4部分
redo_log_type:日志类型,space:表空间的id page_no:页的偏移量 redo_log_body:数据部分
6,日志刷盘的规则:
log buffer中未刷到磁盘的日志称为脏日志,默认情况下事务每次提交的时候都会刷事务日志到磁盘中,变量设置为1,只有commit才会刷盘:1,commit发出后是否刷日志由变量控制 2,.每秒刷一次,由innodb_flush_log_at_timeout变量控制,这个刷日志频率和commit动作无关 3,当log buffer中已经使用的内存超过一半时 4,当有checkpoint时,checkpoint在一定程度上代表了刷到磁盘时日志所处的LSN位置
7 数据页刷盘的规则及checkpoint:
于数据和日志都以页的形式存在,所以脏页表示脏数据和脏日志
数据刷盘的规则只有一个:checkpoint,checkpoint触发后,会将buffer中脏数据页和脏日志页都刷到磁盘。
checkpoint类型: 1,sharp checkpoint,重用redo log文件,例如切换日志文件,将所有已记录到redo log中对应的脏数据刷到磁盘
2,fuzzy checkpoint:一次只刷一小部分的日志到磁盘 1,master thread checkpoint,,每秒或每10秒刷入一定比例的脏页到磁盘 2,flush_lru_list checkpoint:程的目的是为了保证lru列表有可用的空闲页 3,async/sync flush checkpoint:同步刷盘还是异步刷盘 4,dirty page too much checkpoint:脏页太多时强制触发检查点,检查点在 redolog中记录,,所以记录检查点的位置是在每次刷盘结束之后才在redo log中标记(MySQL停止时是否将脏数据和脏日志刷入磁盘,由变量innodb_fast_shutdown={ 0|1|2 }控制,默认值为1,即停止时只做一部分purge,忽略大多数flush操作(但至少会刷日志),在下次启动的时候再flush剩余的内容,实现fast shutdown)
8 LSN超详细分析: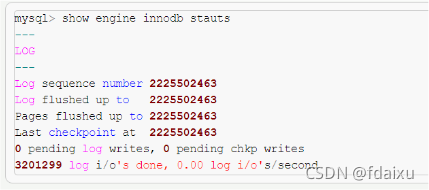
LSN日志的逻辑序列号, 通过lsn可以知道:数据页的版本信息,写入的日志总量,可知道检查点的位置,数据页和redolog都会有LSN,通过对比可以知道确实的数据。数据刷新是根据日志来的,检查点是刷新的位置。log sequence number就是当前的redo log(in buffer)中的lsn;
log flushed up to是刷到redo log file on disk中的lsn;
pages flushed up to是已经刷到磁盘数据页上的LSN;
last checkpoint at是上一次检查点所在位置的LSN。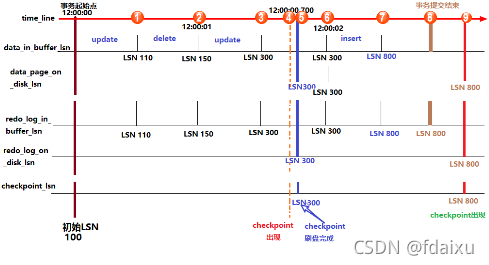
具体算法:
1)首先修改内存中的数据页,并在数据页中记录data_LSN
2)并且在修改数据页的同时,在记录redolog
3)当触发了日志刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN
4)会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置
5)也就是说要刷入所有的数据页需要一定的时间来完成,途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
注意点:检查点日志和数据都会刷,数据刷盘慢于日志刷盘,因为日志更重要,检查点刷盘刷完检查点才更新,否则等于上次的位置
9,innodb的恢复行为:
启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作,checkpoint表示已经完整刷到磁盘上data ,如果小于,则从检查点开始恢复。事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次 这里更详细的规则
10,一些变量:
innodb_log_buffer_size:# log buffer的大小,默认8M
innodb_log_file_size:#事务日志的大小,默认5M
innodb_log_files_group =2:# 事务日志组中的事务日志文件个数,默认2个,innodb_flush_log_at_trx_commit={0|1|2} # 指定何时将事务日志刷到磁盘,默认为1
undolog
1,基本概念:提供回滚和多个行版本控制(MVCC) 如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚,可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
二阶段提交: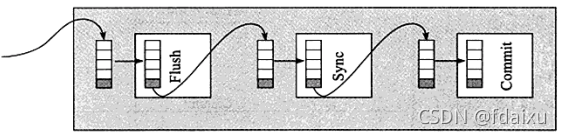
1.binlog和事务日志的先后顺序及group commit
即发出commit指令,进入prepare阶段后,写入binlog,然后开始写binlog,然后将两个日志刷盘,为了保证binlog和redolog一致性,先刷二进制,再刷事务日志。
flush阶段:向内存中写入每个事务的二进制日志。sync阶段:将内存中的二进制日志刷盘,commit阶段:leader根据顺序调用存储引擎层事务的提交。group commit
主从复制架构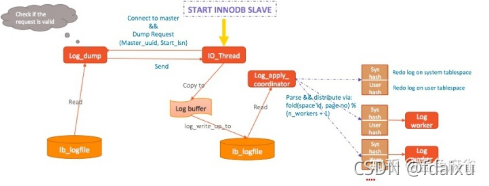
GTID
binlog与undolog对比
优点:Binary Log更加可读,由于记录了行级别的更改。我们可以通过解析binlog,转换成DML语句来将数据变更同步到异构数据库,而redo并没有此特点,因为存储引擎定义的与其他数据库可能有所不同,可以在主备使用不同的存储引擎,
缺点:redo及binlog,只有当两份日志都fsync到磁盘,才认为事务是持久化的,fsync开销比较昂贵,更多日志写入增加磁盘的io压力。主库事务提交后,日志才会写入到binlog文件并传递到备库,库至少延迟一个事务的执行时间,备库还会继续执行这些大事务,长时间占用某个worker进程,最终可能导致没有空闲的worker线程
性能:当我们事先了物理复制后,就可以关闭binlog和gtid,大大减少了数据写盘量,多只需要一次fsync既可以将事务持久化到磁盘,整体吞吐量和响应时间都会提升(从操作系统认识,os的线程数 切换,占用cpu的时间,以及磁盘写入)
事务在执行过程中只要写入redolog就会传递到备库,无需等待主库执行完成,并且还可以根据幂等性合并,最大程度保证主备一致,但是缺点是只能支持innodb引擎,只能基于特定的场景,例如高并发场景。
前提:主库可以查询修改 备库只能查询
过程:从库执行START INNODB SLAVE,备库开启io线程,innodb会开启协调线程和worker线程,从库并发送一个dump请求,其中包括mater id和开始复制的点,
主库:主库上,一个log_dump线程被创建,先检查dump请求是否是合法的,就去从本地的ib_logfile中读取日志,并发送到备库
从库:接受到日志,写入到logbuffer,再写入到logfile,Log Apply协调线程解析日志,系统表空间的变更存放到sys hash中,用户表空间的变更存储到user hash中,Apply日志时,先应用系统表空间,再是用户表空间,原因是我们需要保证undo日志先应用,否则外部查询检索用户表的btree,试图通过回滚段指针查询undo page,可能对应的Undo还没构成
(系统表空间:innodb数据字典,undo logs,the change buffer,默认情况下,其包含一个叫ibdata1的系统数据文件,由于系统表空间可以存储多张表,因此,其为一个共享表空间 用户表空间:单个表)
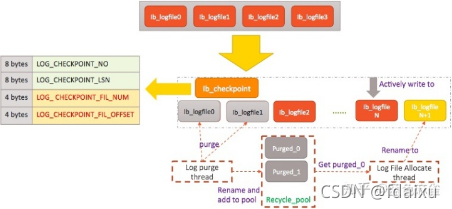
需要解决的问题: 1,需要重新整理InnoDB的日志文件, 因为原生逻辑中,InnoDB采用循环写文件的方式,设置innodb_log_files_in_group为4时,会创建4个ib logfile文件,当第四个文件写满时,会回到第一个文件循环写入,切换文件需要尽量减小对性能的影响。解决:增加了一个新的文件ib_checkpoint,原生逻辑中,checkpoint信息是存储在ib_logfile0中的,而在新的架构下,该文件可能被删除掉,需要单独对checkpoint信息进行存储,包含checkpoint no, checkpoint lsn,后台清理线程被称为log purge thread,为了避免性能抖动,线程总是预先将下一个文件准备好,回收池中有空闲文件。
实例状态:master, slave,以及upgradable-slave(中间状态 刚指定主为服务器1,还没来得及切换)
MySQL Server层数据复制:MySQL在Server层另外冗余了一些元数据信息,这些元数据文件包括FRM,PAR,DB.OPT,TRG,TRN以及代表数据库的目录,对这些文件和目录的操作都没有写到redo中。主要扩展了三种新的日志类型,创建表都会增加三种日志,
DDL复制:当MySQL在执行DDL修改元数据时,是不允许访问表空间的,否则可能导致各种异常错误,MySQL使用排他的MDL锁来阻塞用户访问,我们需要在备库保持相同的行为,主库崩溃,从库可能mdl锁无法释放,因此主库崩溃会发送一条特殊日志,从库会释放mdl锁。从库崩溃了 恢复时也要继续持有mdl。
Cache失效:备库在应用完redo后,需要感知到哪些Cache是需要进行更新的,分为下面几种情况
权限操作,备库上需要进行ACL Reload,才能让新的权限生效;存储过程操作,例如增删存储过程,在备库需要递增一个版本号,以告诉用户线程重新载入cache;知备库进行内存统计信息更新。
备库MVCC:视图控制
备库一致性读的最基本要求是用户线程不应该看到主库上尚未执行完成的事务所产生的变更,只有在完成apply一批日志后才对全局事务状态进行更新:主库发送事物开始日志以及事物结束日志给从库,跟主库mvcc类似
Purge控制
Undo log,那些仍然可能被读视图引用的Undo不应该被清理掉:
方案一:控制备库上的Purge
B-TREE结构变更复制,Page合并或分裂,我们需要禁止用户线程对btree进行检索,并且一个mtr中的变更超过一个page时,则将涉及的索引id写到日志中,完成已经解析的日志;获取索引X锁
页分裂
复制Change Buffer(二级索引即辅助索引:随机io,查到辅助索引范围查询,查到叶子是范围查询结果是一系列的主键id,但不一定连续,因此需要随机去主键索引中查询):change buffer的核心思想,当数据库需要对2级缓存进行修改时,先不从外存读页面,而是将这些更新缓存在内存中,在特定的条件下,统一将这些更新apply到相应的2级索引页面上,这样做可以减少读IO的次数,并且相邻的页面的读IO可以合并。当插入/更新会引发索引树SMO时,Ibuf不可用。(由于关闭了binlog 主从复制不能正常进行,因此需要开发redolog的主从复制)注意:非聚集索引插入会带来主键插入离散性,随机。非聚集索引的插入更新,页如果在缓存则更新,不在则放入缓存,然后以一定的频率merge到页中,前提不是唯一索引,唯一索引需要检查。在备库为了保证对数据不做任何的变更,只读操作不应该对物理数据产生任何的影响,对比binlog的主从复制很简单,只需要在从库重新做一遍即可。flushlist:修改了之后会放到脏页里面,刷到磁盘,当将Page读入内存,如果发现其需要进行ibuf merge,则为其分配一个shadow page,将未修改的数据页保存到其中;,定期merge就不需要flush了,当数据页从buffer pool驱逐或者被log apply线程请求时,shadow page会被释放掉。
复制change buffer合并:为了保证在合并的过程中,用户线程不能访问到正在被修改的数据页,备库解析到时apply所有已解析的日志并释放block锁
主备切换:种场景下需要解决的问题是:老主库在恢复访问后,如何确保和新主库的状态一致。更具体的说,如果老主库上还有一部分日志还没传送到新主库,这部分的不一致数据该怎么恢复。

若有收获,就点个赞吧
0 人点赞
