1,总体概述:
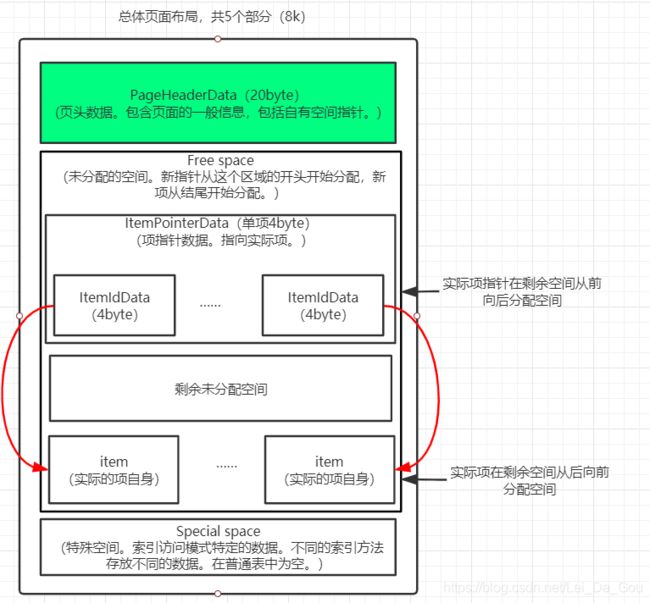
说明:页是8K,有五部分,页头,item指针,free space,items,特殊空间
实际存储页的结构是pageHeaderData,而上图并不代表实际数据结构
2, PageHeaderData以及page
typedef struct PageHeaderData<br />{<br />/_ XXX LSN is member of _any_ block, not only page-organized ones _/<br />PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog//lsn 64位记录lsn 记录上次对该页的修改<br />_ record for last change to this page _/<br />uint16 pd_checksum; /_ checksum _/ 校验和<br />uint16 pd_flags; /_ flag bits, see below _/标志位<br />LocationIndex pd_lower; /_ offset to start of free space _/空闲位首<br />LocationIndex pd_upper; /_ offset to end of free space _/空闲位尾<br />LocationIndex pd_special; /_ offset to start of special space _/特殊空间的开始<br />uint16 pd_pagesize_version; 版本<br />TransactionId pd_prune_xid; /_ oldest prunable XID, or zero if none _/最老的事物id<br />ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /_ line pointer array _/行数据<br />} PageHeaderData;
Page初始化:page是char* 转换成pageheader size固定为8k pageheader其实就是page,通过page初始化来去观测联系


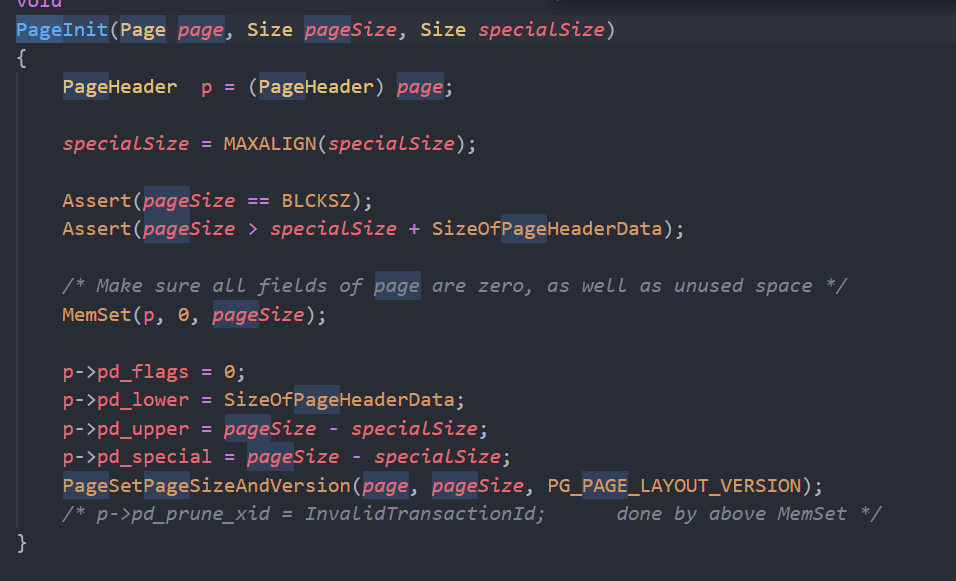
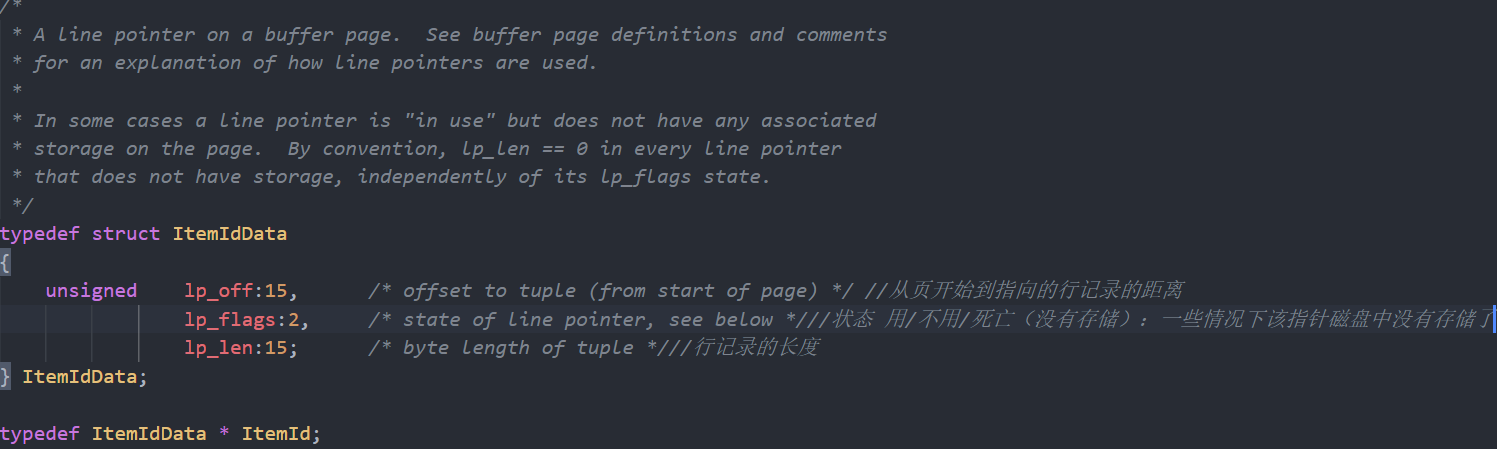
page:char * :8k = pageheader: pageheader 空闲位置就是用来插入tuple的,而itemiddata作为tuple的指针,可以直接定位到该行数据,具体可以参考图一
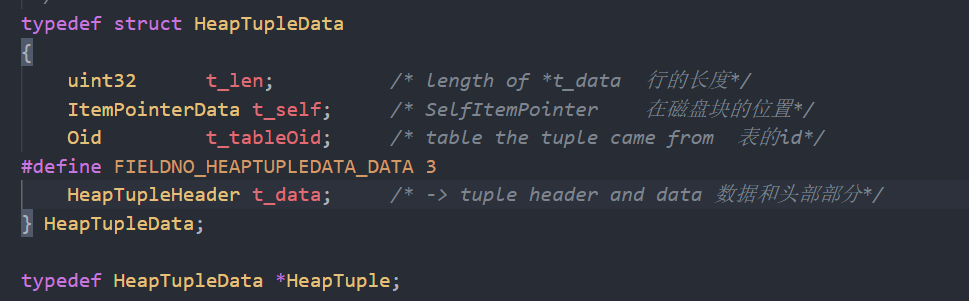
3,Items(Tuples):行头部和行实际的数据
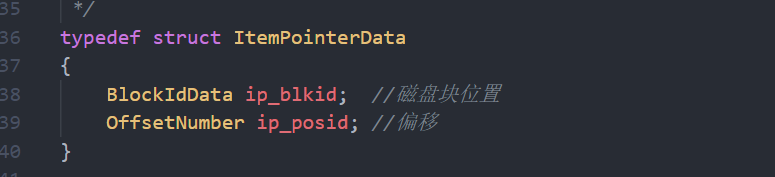
位置指针:定位到磁盘块有利于查找
真正的数据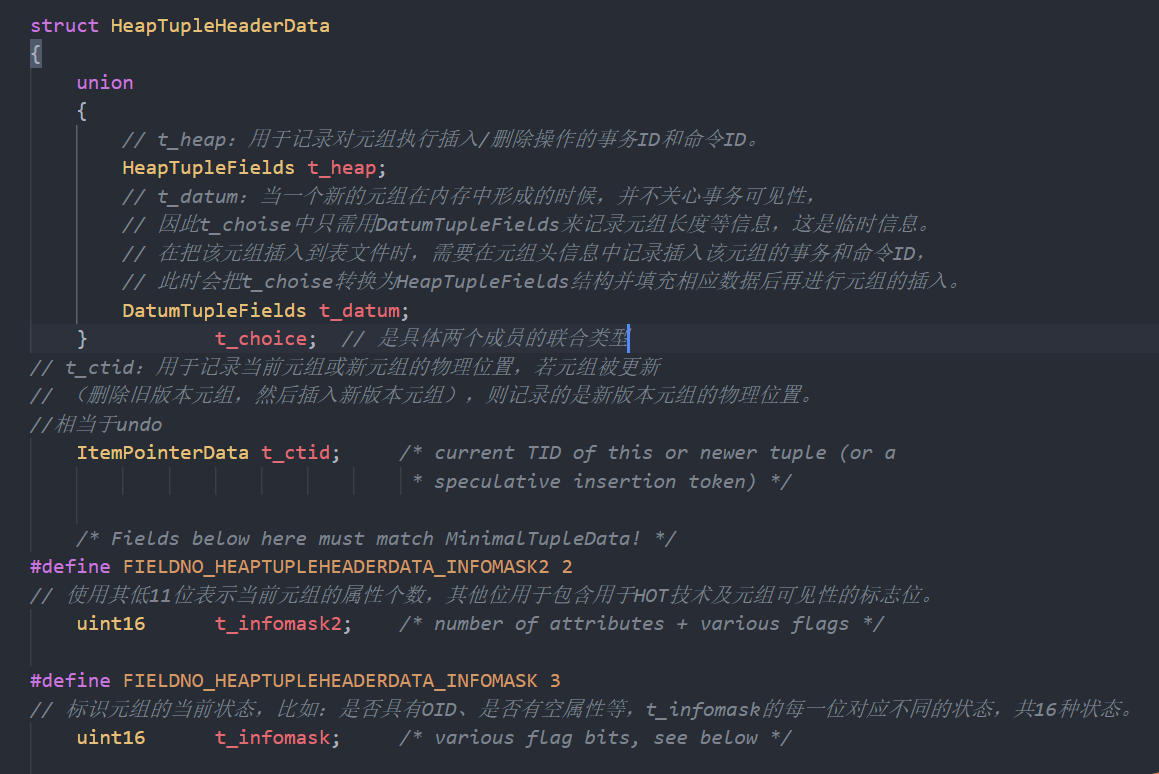
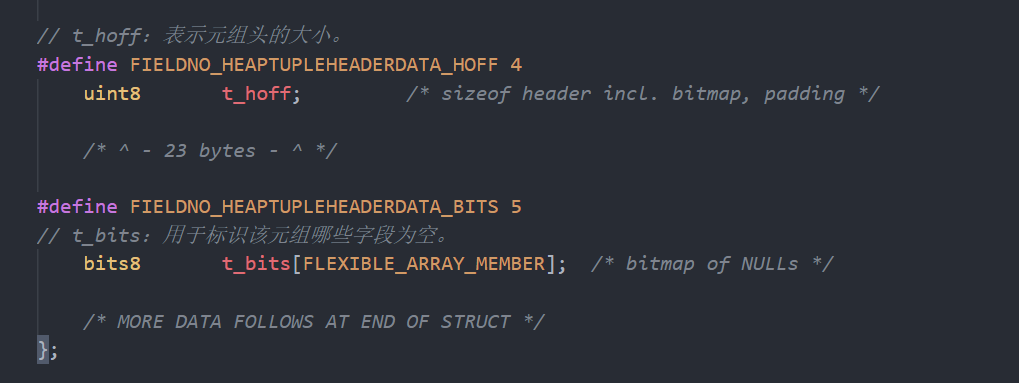
注:具体行的数据部分在头部后面一直到结构体尾部
etc:Mysql与pg一点区别
update数据表导致数据表占用空间“暴涨”的原因:
1、保留原数据:PG没有回滚段(mysql有),在执行更新/删除操作时并没有真正的更新和删除,而是保留原有数据,在合适的时候通过vacuum机制清理垃圾数据;
2、避免长事务:为了避免垃圾数据暴涨,在业务逻辑允许的情况下应尽可能的尽快提交事务,避免长事务的出现;
3、查询操作:使用JDBC驱动或者其他驱动连接PG,如明确知道只执行查询操作,请开启自动提交事务。
B+树索引:
索引物理结构: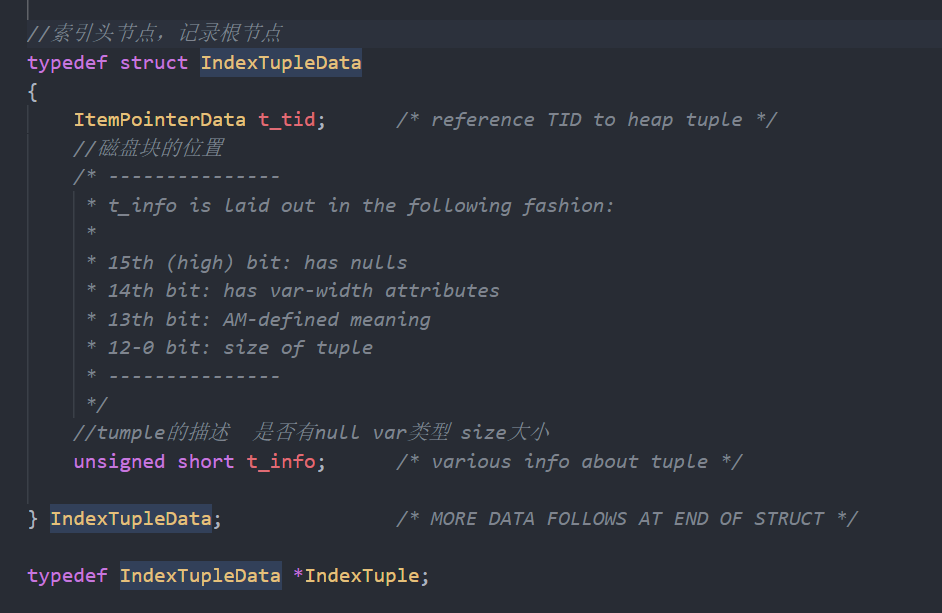
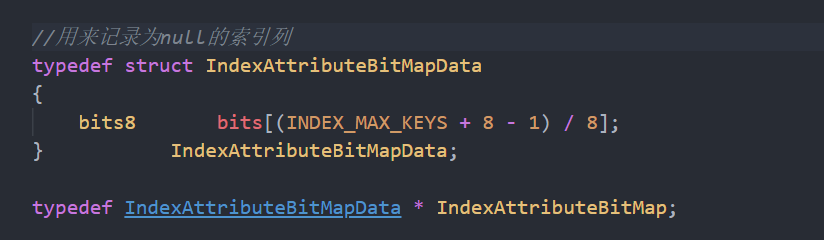
索引结构: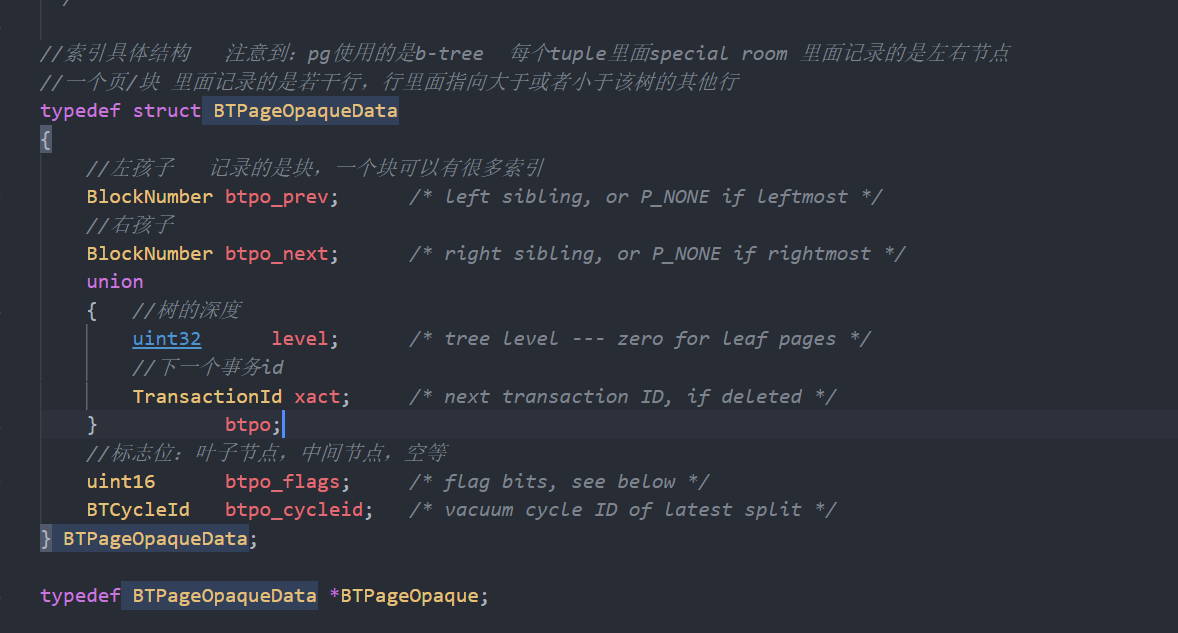
etc:行数据大小对于存储的影响
在一行数据大于Block Size时,Oracle使用行链接的方式实现跨块存储。pg有4中解决方案,其中包括压缩或行链接等
表的数据结构:还有很多属性,这里不一一列举了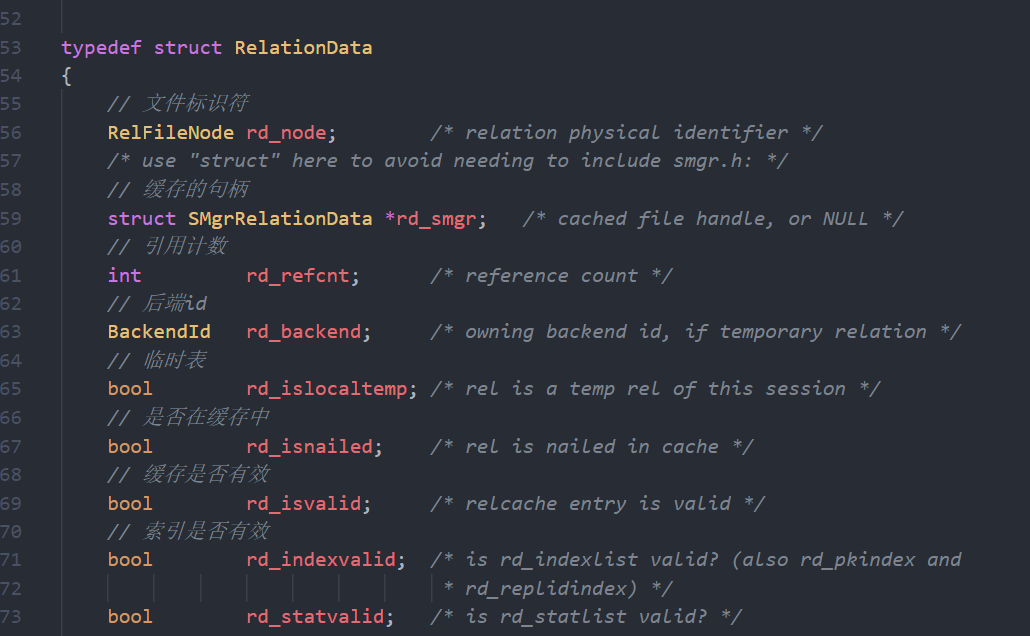
buffer:
localbuffer是指进程内独有的数据;sharedbuffer则是共享内存里的数据,会共
享给多个进程。
PostgreSQL里,比如用户表数据的缓存在共享内存中,这样多个后台进程可以共同读取
或者修改,还有好多比如锁、进程状态信息等。
除了这些,其他的都是存在localbuffer里的,比如程序中用到的很多的变量。
etc:pg为多进程,mysql为多线程,由于时线程的发展有关

若有收获,就点个赞吧
0 人点赞
