本文重点分析innodb,主要参考书籍为mysql技术内幕,自上到下分析
一:基本数据结构与算法
InnoDB:采用memmory heap的方式来进行内存对象管理,可以一次性分配大块内存,而不是按需分配,多次分配可以合并为单次,还允许从缓冲池中分配内存建立内存堆,这样可以更快请求整个内存页
mem_block_t:内存块,内存堆即一系列相链的内存块,内存块一次比一次分配的空间大

mem_heap_t: 使用内存块的第一个节点中的base,将内存块连接起来,调用者请求内存对象获取最后一个内存块用于分配,如果已经分配完毕,则分配新块并插入到块链表中
mem_pool_struct
mem_arer_t
伙伴系统:防止内存碎片,将一块内存分成适合请求大小的内存
hash_table_struct: 类似concurenthashmap
void* :泛型
双链表
动态数组
同步机制
spin lock:适用与代码较少的,否则会忙等,占用cpu执行时间
mutex:类似,synchronized
rw-lock:读写锁
redo log
innodb_flush_log_at_trx_commit:控制重做日志刷新到磁盘的策略,1:事务提交强制刷盘 0 不一定强制刷盘

log_struct:控制重做日志的写入
组提交:一个事务提交都需要一次fsyc,为了提高性能,允许将一组事务提交,组
提交后可以一起写。
recv_sys_struct:恢复数据结构,哈希值为:space, page_no,因此恢复也是这么弄的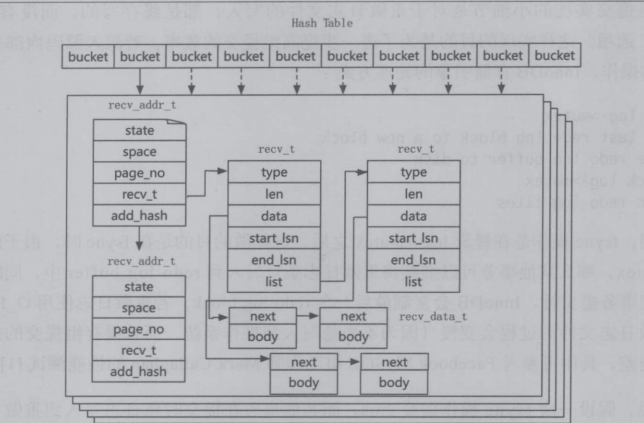
p62
重做日志恢复:
是否需要恢复:file_header定义了file_flush_LSN,该值理论上与重做日志中保存的检查点值相等。恢复的时候会寻找值最大的那个,恢复的区间是checkpoint-lastRedoLSN,并且在读取到重做日志的重做日志块后,会判断重做日志块中的内容是否包含上一个日志的内容,因为一个日志可能存放于多个重做日志块中。事务T1的日志有可能在两个日志块中存放,页的回放通过hash并行回放
checkpoint:负责刷数据页等
恢复的意义:先写日志(快),再刷数据页(慢),有可能日志写完了,宕机了,这时候需要从日志中提取数据,然后恢复到数据页上,当然这里面肯定设计到大量的锁或者同步机制,因此,对于不同redo的处理需要谨慎,那么我们设想:恢复的细节其实与主从恢复的细节相同,因此这部分完全可以参考的,复用的。
innodb中:binlog->主备 + PITR redo:恢复
MTR: (明确:LSN是日志的num,每个页都有,代表着该页已经写入了LSN的数据,页是具有分裂合并属性的)
当数据库访问或者修改一个页,需要持有该页的latch,MTR保证一个页的一致性(日志),而事务是保证多个页的一致性
force-log-at-commit:为了保证事务持久性,当一个事务提交时,所有mini_transaction产生的日志都必须刷新到持久存储设备上。
物理逻辑日志的实现:重做日志的开始信息由类型,表空间ID,页在表空间中的偏移量。
组提交:多个事务可以同事fsyn磁盘
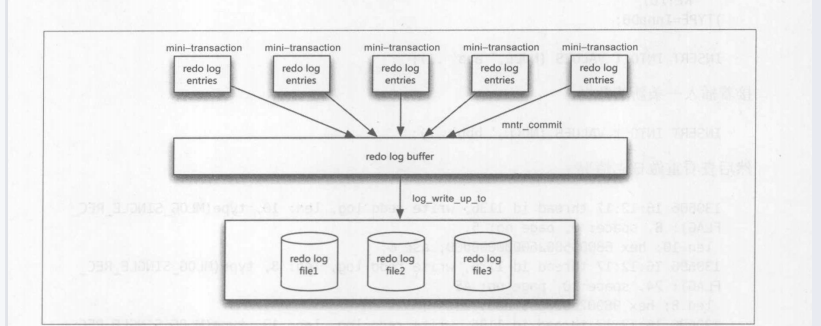
一条插入语句产生的redo:

存储结构
页: 
区:64个页
表空间等
页的结构:
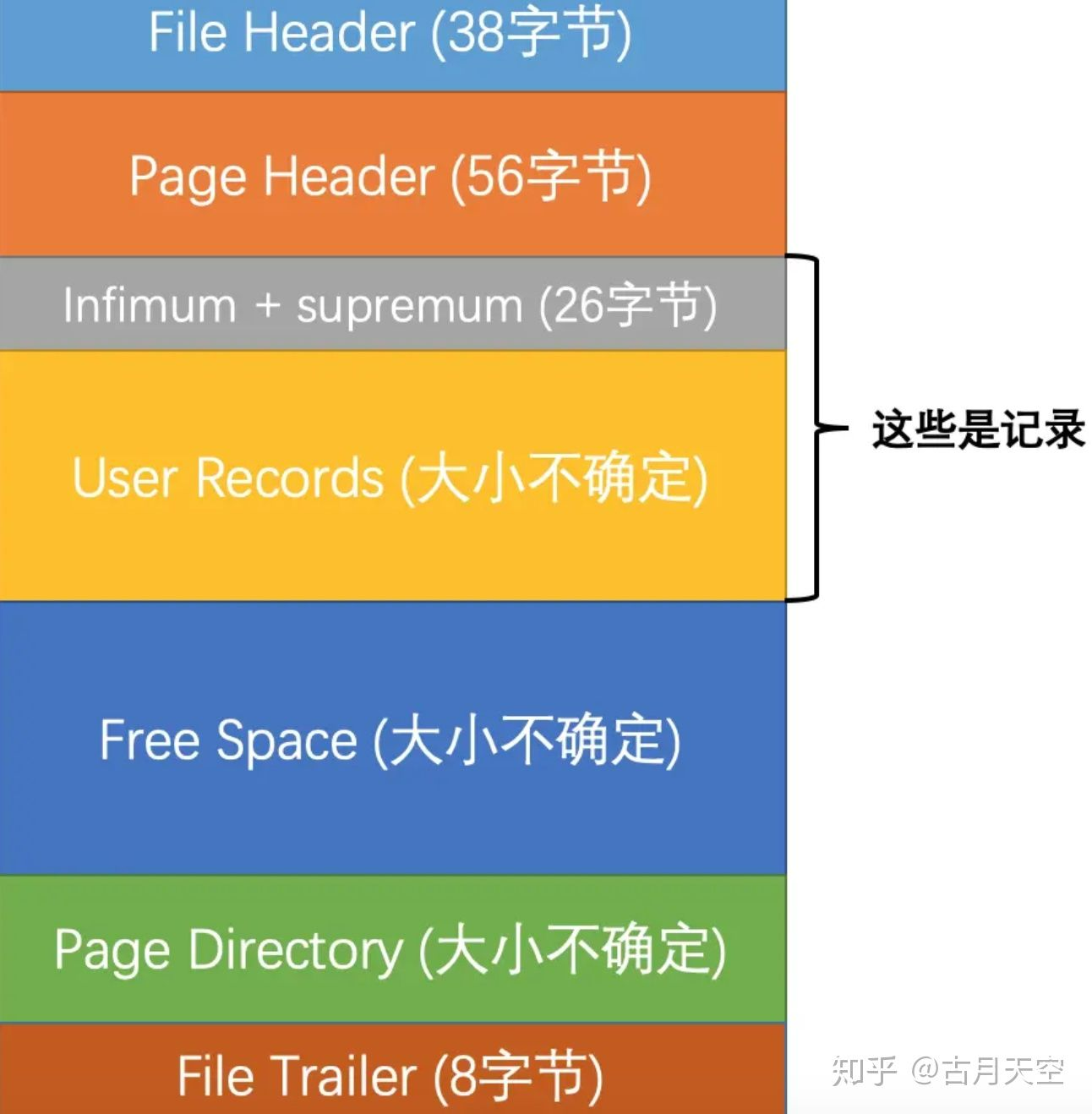
- 1、File Header
- 文件头部,针对页的一些通用信息,eg:页的校验和,编号,上一页,下一页等;
- 2、Page Header
- 页面头部,数据页专有的一些信息,页中记录的状态信息,eg:本页有多少条记录,第一条记录的地址,页目录中有多少slot,最后插入记录的位置等;
- 3、Infimum+supremum
- 两个虚拟的行记录,最小记录和最大记录;
- 4、User Records
- 存储用户插入的记录内容;
- 详解记录头信息:
- delete_mask:当前记录是否被删除的标记;被删除的记录没有立即从磁盘上移除,因为移除需要重新排列磁盘上的其他记录,需要消耗性能;被删除的记录会组成一个垃圾链表,占用的空间称为可重用空间;
- heap_no:当前记录在本页中的位置,插入的记录值从2开始,值0和1就是指的最小和最大两条虚拟记录;记录比较大小,对一条完整的记录来说,比较记录的大小就是比较主键的大小,注意这两条记录没有在user records部分;
- record_type:当前记录的类型;分为4种记录类型,0:普通记录,1:B+树非叶子节点,2:最小记录,3:最大记录;我们自己插入的记录就是普通记录;
- next_record:当前记录真实数据到下一条记录真实数据的地址偏移量,是一个链表,可以通过一条记录找到下一条记录;链表顺序是按照主键的值从小到大的顺序;无论我们对页中的记录做任何操作,innoDB会一直维护一条记录的单链表,各个节点按照主键的大小排序;

- 5、Free Space
- 页中尚未使用的空间;
- 6、Page Directory
- 页面目录,页中某些记录的相对位置;
- 一条查询语句查找数据的过程:
- 所有记录(包括最小和最大记录,不包括被删除的记录)划分为几个组;
- 每个组的最后一条记录的头信息中的n_owned属性表示改组有几条数据;
- 将每个组的最后一条记录的地址偏移量单独提取出来,按顺序存储到靠近页的尾部地方,这个地方就是页目录,页目录中的这些地址偏移量称为slot(槽),页面目录由槽组成;
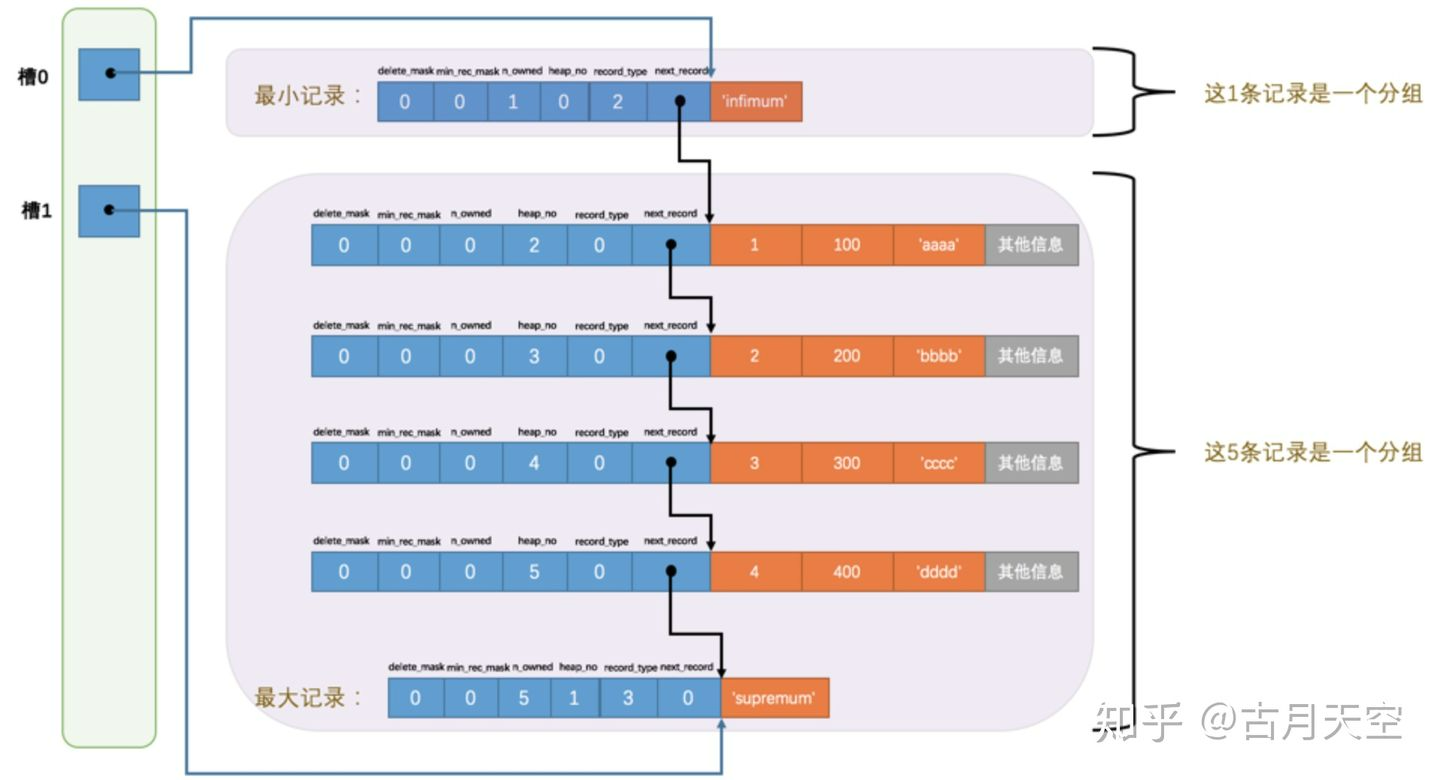
- 分组规定:最小记录所在的分组只能有一条;最大记录所在的分组只能是1~8条之间;剩下的分组4~8条之间;- 通过二分法确定记录所在的槽,找到槽所在分组中主键值最小的记录;通过记录的next_record属性遍历槽所在的组;
- 7、File Trailer
- 文件尾部,校验页的完整性;
- 数据存在磁盘上,磁盘速度慢,需要以页为单位把数据加载到内存中处理,页的数据在内存中被修改后需要把数据同步到磁盘中,如果同步一半出现异常后,页已经不再完整,所以在页的尾部加上了file trailer,由页的校验和和页被修改时对应的日志序列位置(LSN);
事务:
事务数据结构:全局
trx_sys_struct
每个事务数据结构:
trx_struct
double write


若有收获,就点个赞吧
0 人点赞
