innodb存储引擎:
1,mysql体系结构和存储引擎: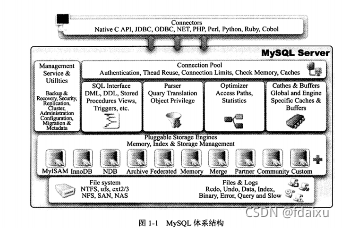

概念:一个mysql进程即一个实例
2,数据库体系结构:右图(注意:存储引擎是基于表的,而不是基于数据库,每个存储引擎都有自己的特点) mysam:不支持事物,只缓存索引不缓存事务。NDB:集群存储引擎,数据都放到内存
线程:主线程:脏页刷新,合并插入缓冲等 iothread:负责异步io 的回调 异步io如何实现的
purge thread:事物提交后,回收undolog page clean thread:脏页刷新,从主线程脱离
缓冲池:见右图,通过LRU算法来管理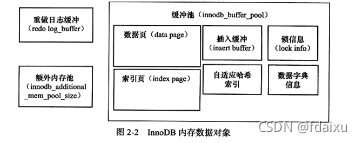
数据库是先写redolog 再修改页,check point技术:缩短恢复时间,缓冲池不可用,脏页刷新到磁盘,redolog不可用,刷新脏页。check point之前的页都刷新,因此只需要刷新之后的即可,缓冲不可用,强制执行checkpoint,刷到磁盘。重做日志不可用是因为是循环使用的,重做日志已经不需要了,数据库宕机已经不需要这部分日志了,可以checkpoint刷到磁盘。 LSN:标记数据或日志版本。
checkpoint类型:sharp:数据库关闭刷到磁盘 可用性不高。fuzzy:前面三种。 redo不可用:需要切换了,需要刷新一下,保证切换正常。
master thread:主循环: 每秒一次的操作:刷新日志到磁盘 合并插入缓冲:如果io压力小会进行合并。 刷新100个脏页:触发条件为页比例,每秒一次可能sleep,根据压力决定是否sleep一秒。 十秒一次的操作:刷新100个脏页到 磁盘,合并五个插入缓冲,将日志刷新到磁盘,删除无用的undo
磁盘io性能
后台循环:数据库空闲时,删除undo,合并插入缓冲,跳回到主循环,刷新脏页:当大于一定比例才刷新
刷新循环:若没有什么事就跳到暂停线程挂起主线程
暂停循环
特性:1,插入缓冲:一般情况下 主键自增长,插入不需要读取其他的页,插入比较快,但是非聚集索引叶子节点插入不再是顺序的,就需要离散访问非聚集索引页,导致性能下降。可能根据时间插入,一个在头 另一个在尾,虽然id自增。插入的时候,判断是否在缓存中,以一定的频率插入,进行insert buffer与叶子节点的合并,辅助索引不能唯一,需要判断,insetbuffer最多使用二分之一缓冲
changgebuffer:对一条记录update分为将记录标记为删除,真正将记录删除,deletebuffer标记,purgebuffer:真正删除。插入缓冲在共享表空间,通过独立表空间恢复数据可能失败,因为共享表可能有。为了merge成功,还需要记录辅助索引页的空间
merge:时机:页读取到缓冲池中,该辅助索引页无可用空间,主线程。
2,两次写:insertbuffer性能提升,两次写:数据页可靠性
脏页刷新的时候,可能突然掉点,导致前2k是新的,后面14k是旧的,因此发生了页损坏,也就是说这个块坏了,不能用了innodb没法处理了。将缓冲中的先顺序写到共享表空间,比较快,然后离散写到数据文件中
一旦断电有可能磁盘上的页不断裂的不正确不完整的,可能不能正确读取了。
自适应哈希索引:根据某个也的访问频率,来构建hash索引,不用去b树中查找了
AIO:异步io,回调处理
刷新临近页:刷新该页,会检查旁边页是否也需要刷新
关闭恢复:innodb_fast_shutdown: 0:完成刷新脏页,purge,merge, 1:刷新脏页 ,2:写日志 下次启动会恢复
3,文件
参数文件:配置参数
日志文件:错误日志,慢查询文件:记录运行时间超过阈值的日志,binlog redolog
套接字文件 pid文件:进程号
表结构定义文件:定义表结构
innodb存储引擎文件:表空间文件 ibdata1 共享表空间:undo日志一些数据 独立表空间:单表的数据
redolog:循环切换日志文件,写满了切换,redolog结构 见右图。commit参数:见上篇博客
页的数据结构:
file header:头信息:check sum,偏移,pageheader:数据页的状态信息,堆中第一个记录的指针:记录在页中是堆存储的,堆中的记录数,最后记录的数量,最后记录的位置。
user record:实际行记录的内容,会有索引节点和叶子节点
page directory:记录的相对位置,按照槽来划分,一个槽可能有多个记录
file tailor:检测页是否完整的写入磁盘

若有收获,就点个赞吧
0 人点赞
