- 数据持久化
- prometheus架构图
- prometheus集群
时序数据库
TSDB(Time Series DataBase),时序数据库,用于保存时间序列(按时间顺序变化)的数据,它的每条记录都有完整的时间戳,给予时间的操作都比较方便.
- 时间作为它的主轴,数据按顺序到达
- 大多数操作是插入新数据,偶尔伴随查询,更新数据比较少
- 时间序列数据累计速度非常快,更高的容纳率、更快的大规模查询以及更好的数据压缩
- TSDB通常还包括一些共通的对时间序列数据分析的功能和操作:数据保留策略,灵活的时间聚合等。
Prometheus架构
Prometheus是一个开源的时序数据库系统,它通过HTTP协议从远程机器上收集数据并存储到本地的时序数据库中。他提供了功能强大的查询语言PromQL以及HTTP接口等,
Prometheus通过安装在远程机器或者服务中的exporter来收集监控数据。
- 多维数据模型
- 提供灵活的查询语言PromQL
- 不依赖于分布式存储,单主节点工作
- 通过http的pull方式来采集时序数据
- 可以通过push gateway进行时序数据推送
- 可以通过服务发现或静态配置去获取要采集的目标服务器
- 多种可视化图表和仪表盘支持
Kubernetes其中一个功能是提供了弹性动态的部署能力,而Prometheus则提供了动态的监控能力
数据存储在TSDB中,通过Server经过http去pull数据更新数据。
pull方式
Prometheus采集数据是用的pull也就是拉模型,通过HTTP协议去采集指标,只要应用系统能够提供HTTP接口就可以接入监控系统,相比于私有协议或二进制协议来说开发、简单。
push方式
对于定时任务这种短周期的指标采集,如果采用pull模式,可能造成任务结束了,Prometheus还没有来得及采集,这个时候可以使用加一个中转层,客户端推数据到Push Gateway缓存一下,由Prometheus从push gateway pull指标过来。(需要额外搭建Push Gateway,同时需要新增job去从gateway采数据)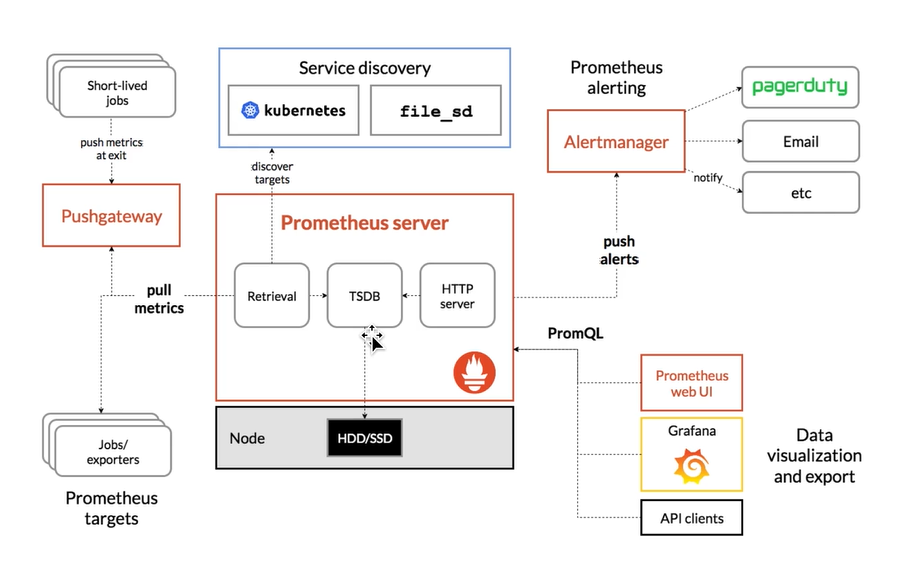
storage
prometheus使用了Gorilla的 levelDB 来做索引,对于大量的采样数据有自己的存储层。Prometheus为每个时序数据创建一个本地文件,以1024byte大小的chunk来组织
tsdb 存储设计有这几个难点:
- 指标数据有
Writes are vertical,reads are horizontal的模式;Writes are vertical,reads are horizontal的意思是 tsdb 通常按固定的时间间隔收集指标并写入,会垂直地写入最近所有时间序列的数据,而读取操作往往面向一定时间范围的一个或多个时间序列,“横向” 地跨越时间进行查询
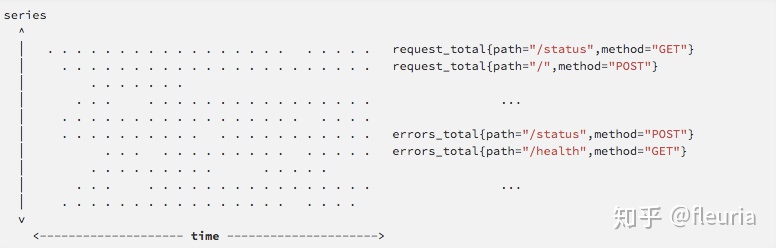
鉴于此,prometheus 写入的方法与 LSM Tree 类似,会通过一个缓冲攒够批次再落盘,使单个时间序列的一段 chunk 在存储上相邻,从而允许能够较为快速地横向读取到时间序列数据。prometheus tsdb 会像 Gorilla 那样,对一个 chunk 做压缩,使单个监控数据点的存储成本小到 1.4 bytes 这个水平。这点跟列存的设计比较相似,压缩不只是对存储成本的优化,也对计算的加速能够起到很大作用。
- high churn:云原生环境下会产生大量的临时性的时间序列;
high churn 现象导致 graphite 那种每个时间序列一个文件的做法变得不那么容易续了,每个 pod 一生一死就一个时间序列,一来一回就多一个文件,很容易撑爆 inode,此外跟随查询频繁打开、关闭文件也不那么经济。 prometheus v1 的存储架构仍是一个文件对应一个时间序列的存储设计,到 v2 架构中做了一项大重构,改为每两小时落一个 Block,使这个 block 包含最近两小时的所有时序数据与索引,通过 mmap访问 block 数据。每个 block 实质上相当于一个独立的小数据库,存储着这两小时内的所有时间序列的 chunk 数据与索引。
index结构
每个 block 中的 index 文件包含这几个部分:
symbol table:数据字典,使每个 label 的名字和 label 值,都在 symbol table 中记录为唯一 id,存储时只保存 id 值就可以了。series 列表:记录当前 block 中有哪些 series(时间序列),每个 series 有哪些 label 值,有哪些 chunks,每个 chunk 的开始、结束时间;倒排索引(posting):每个 label 值到 series id 列表的倒排;倒排索引的 offset table:每个倒排列表的起始 offset;toc:index 文件中各部分的起始 offset;
v2 的目录结构大约长这样:
$ tree ./data./data├── b-000001│ ├── chunks│ │ ├── 000001│ │ ├── 000002│ │ └── 000003│ ├── index│ └── meta.json├── b-000004│ ├── chunks│ │ └── 000001│ ├── index│ └── meta.json├── b-000005│ ├── chunks│ │ └── 000001│ ├── index│ └── meta.json└── b-000006├── meta.json└── wal├── 000001├── 000002└── 000003
每个 block 中时序数据的存储大致上长这样: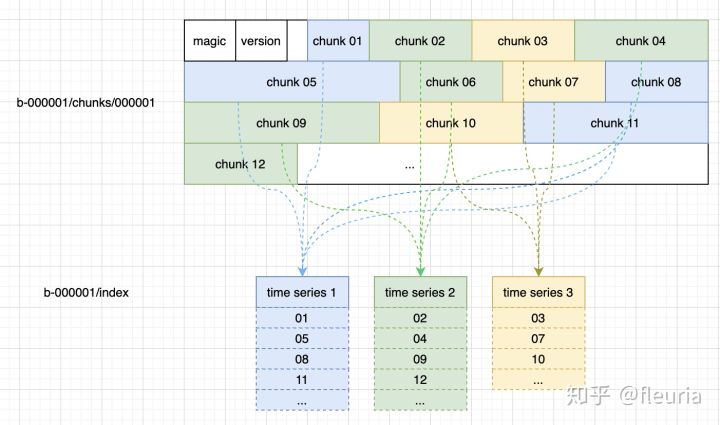
每个 chunk可以理解为 kv 存储中的一条 kv 数据,按索引中 chunk id 的列表,形成完整的时间序列数据。
至于 prometheus 能够根据 label 做灵活的过滤、聚合等操作,这就都属于倒排索引的功劳了,每个倒排索引都是有序的 id 排列,这样能够很高效的做到交集、并集操作:

磁盘结构
Prometheus在storage.local.path指定的路径存储文件,默认为./data。关于chunk编码有三种
- type0 第一代的编码格式,simple delta encoding
- type1 目前默认的编码格式,double-delta encoding
type2 variable bit-width encoding,facebook的时间序列数据库Beringei采用的编码方式
内存使用
prometheus在内存里保存了最近使用的chunks,具体chunks的最大个数可以通过storage.local.memory-chunks来设定,默认值为1048576,即1048576个chunk,大小为1G。
除了采用的数据,prometheus还需要对数据进行各种运算,因此整体内存开销肯定会比配置的local.memory-chunks大小要来的大,因此官方建议要预留3倍的local.memory-chunks的内存大小。持久化
-storage.local.retention 168h0m0s \-storage.local.max-chunks-to-persist 3024288 \-storage.local.memory-chunks=50502740 \-storage.local.num-fingerprint-mutexes=300960
storage.local.retention用来配置采用数据存储的时间,168h0m0s即为24*7小时,即1周storage.local.memory-chunks设定prometheus内存中保留的chunks的最大个数,默认为1048576,即为1G大小storage.local.series-file-shrink-ratio用来控制序列文件rewrite的时机,默认是在10%的chunks被移除的时候进行rewrite,如果磁盘空间够大,不想频繁rewrite,可以提升该值,比如0.3,即30%的chunks被移除的时候才触发rewrite。storage.local.max-chunks-to-persist该参数控制等待写入磁盘的chunks的最大个数,如果超过这个数,Prometheus会限制采样的速率,直到这个数降到指定阈值的95%。建议这个值设定为storage.local.memory-chunks的50%。Prometheus会尽力加速存储速度,以避免限流这种情况的发送。storage.local.num-fingerprint-mutexes 当prometheus server端在进行checkpoint操作或者处理开销较大的查询的时候,采集指标的操作会有短暂的停顿,这是因为prometheus给时间序列分配的mutexes可能不够用,可以通过这个指标来增大预分配的mutexes,有时候可以设置到上万个。storage.local.series-sync-strategy控制写入数据之后,何时同步到磁盘,有’never’, ‘always’, ‘adaptive’. 同步操作可以降低因为操作系统崩溃带来数据丢失,但是会降低写入数据的性能。默认为adaptive的策略,即不会写完数据就立刻同步磁盘,会利用操作系统的page cache来批量同步。storage.local.checkpoint-interval进行checkpoint的时间间隔,即对尚未写入到磁盘的内存chunks执行checkpoint操作。有见过间prometheus使用influDB做持久化的方案,但是这样有多出一个DB。考虑在一段时间内本地持久化,然后采集关键数据存储或形成周报,月报等
基本语法
- 瞬时向量选择器:
- 瞬时向量选择器可以只指定度量名称来获取该度量名的所有的即时向量。
kong_http_status - 也可以进行标签筛选,数据埋点的时候我们会对采集的数据打上不同的tag标签
kong_http_status{code="200",service="sky-cmdb"}PromQL使用度量名来索引数据,在此基础上可以跟花括号进行tag标签的k-v筛选。
- 范围向量选择器
- 在瞬时向量的基础上加上时间范围,具体语法是在向量选择器末尾的方括号中填上持续时间,用来指定每个结果
范围向量元素提取多长时间值。 - 持续时间指定为数字,紧接着是以下单位之一:
- s - seconds
- m - minutes
- h - hours
- d - days
- w - weeks
- y - years
- 在范围向量中取的是这个时间范围之内的数据,我们会使用内置的函数让数据更加直观,也就是将这段时间内获取的数据变成这段时间内的变化率展示在图中
rate(kong_http_status[5m])代表kong_http_status这个瞬时向量每五分钟的变化
- 偏移修饰符
- offset 偏移修饰符允许在查询中改变单个
瞬时向量和范围向量中的时间偏移 kong_http_status{code="200",service="sky-cmdb"} offset 1d返回一天前的瞬时向量
- PromQL的常见内置函数
- abs 绝对值
- delta 参数是一个区间向量,返回一个瞬时向量。它计算一个区间向量 v 的第一个元素和最后一个元素之间的差值。由于这个值被外推到指定的整个时间范围,所以即使样本值都是整数,你仍然可能会得到一个非整数值。
- increase 获取区间向量中的第一个和最后一个样本并返回其增长量
- rate 直接计算区间向量 v 在时间窗口内平均增长速率
Prometheus水平扩展方案
从一开始,Prometheus设计成可以很好地完成一小部分工作,并与其他可选组件无缝协作
- 长期存储 : 单个Prometheus实例提供持久存储时间序列数据,但它们不能作为分布式数据存储系统,不提供像具有跨节点复制和自动修复等功能。这意味着,耐久性保证仅限于单台机器。
- 全局数据视图 : Prometheus实例充当隔离数据存储单元。Prometheus实例可以联邦,但这会给Prometheus设置增加很多复杂性,而且Prometheus不是设计为分布式数据库。这意味着,没有简单的途径来实现时间序列数据的单一,一致的“全局”视图。
- 多租户 : Prometheus本身没有的租户概念。这意味着,它无法对特定于租户的数据访问和资源使用配额等事物,提供任何形式的细粒度控制。
Prometheus 自带的时序数据库不支持集群模式,难以承接海量的时序数据。RemoteRead 和 RemoteWrite 机制,主要解决了数据的存放问题,海量数据的查询依然是严重的瓶颈。
Prometheus高可用有几种方案:
- 基本HA: 两套Prometheus采集完全一样的数据,外挂负载均衡
- HA+远程存储 : 除了基础的多副本Prometheus,还通过remote write写入到远程存储,解决存储持久化问题
- 联邦集群: 即Federation,按照功能进行分区,不同的shard采集不同的数据,由Global节点来统一存放,结局监控数据规模的问题
- 使用Thanos或Victoriametrics来解决全局查询、多副本数据Join问题
高可用的解决方案是在存储、查询两个角度上保证数据的一致:
- 存储角度: 如果remote write远程存储,A和B后面可以都加一个Adapter,Adapter做选主逻辑,只有一份数据可以推送到TSDB,这样可以保证一个异常,另一个也能推送成功。数据不丢,同时远程存储只有一份,是共享数据
- 查询角度:存储角度实现复杂且有一定风险,所以现在大部分方案都是在查询层面做文章,比如Thanos或Victoriametrics , 仍然是两份数据,但是铲鲟是做数据去重和join,只是thanos是通过sidecar把数据放在对象存储,victoriametrics十八数据remote write到自己的server实例,但查询层逻辑基本一致
Cortex
Thanos
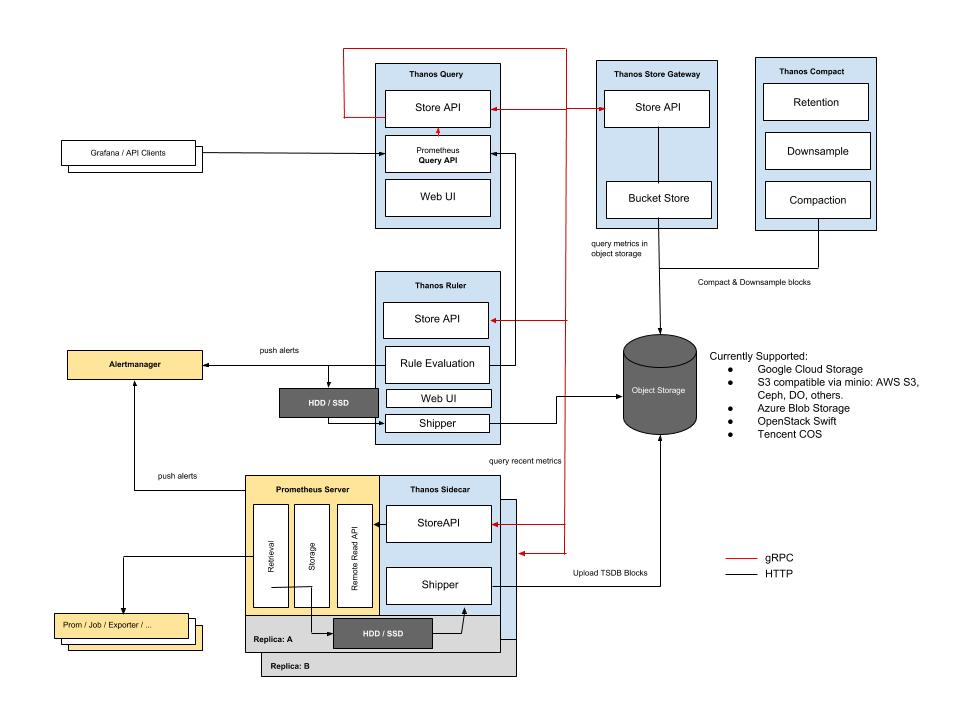
Thanos包含以下组件:
- Sidecar :这是Prometheus运行的主要组件,它读取并存储object store中的数据。此外,它管理Prometheus的配置和声明周期。为了区分每个Prometheus实例,Sidecar组件将外部标签注入Prometheus配置中。Sidecar组件能够在Prometheus服务器的PromQL接口上运行查询。Sidecar组件还侦听Thanos gRPC协议,并在gRPC查询和REST查询之间转换。
- Store :此组件在object store中的历史数据之上实现Store API。它主要充当API网关,因此不需要大量的本地磁盘空间。它在启动时加入Thanos集群,并公布它可以访问的数据。它会在本地磁盘上保留有关所有远程块的少量信息,并使它与object store保持同步。通常,在重新启动时可以安全地删除此数据,但会增加启动时间。
- Query:查询组件,负责侦听HTTP并将查询转换为Thanos gRPC格式。它汇总了来自不同来源的查询结果,并且可以从Sidecar和Store中读取数据。在高可用性设置中,它甚至可以对重复数据进行删除。
现有方案中:
- cortex 基于Prometheus实现,支持水平扩展、支持PromQL,是CNCF沙盒项目,但过于复杂,没有正式 release
- thanos实现了Prometheus数据的汇聚、转储、查询,也是CNCF沙盒项目,但prometheus 通过 thanos 进行 remote read 内存开销增加1倍,还有oom问题
- m3db 是Uber开源的分布式时间序列数据库,但复杂,学习、管理成本高。
Victoria Metrics
Victoria Metrics 是一个支持水平扩展的时序数据库,可以作为 Prometheus 的远端存储,并且实现了 PromSQL,可以直接通过 VictoriaMetrics 查询时序数据,避开 Prometheus 查询时的单点瓶颈。方案
VictoriaMetrics 分为 单机版本 和 集群版本,单机版本和集群版本用法不同,以下介绍集群版。
时间序列(time series)是时序数据库的最小管理单位,每个 time series 对应一系列按时间分布的的采样点。我们需要考虑以下几个问题:
- 能存储多少个
time series,total number of time series; - 能支持多少个
time series的并发写入,number of active time series; - 能支持多高速度的采样数据写入,每秒写入点数;
- 能支持多高查询频率,
average query rate; - 每次查询耗时,
query duration;
以下是几个公司公开的 使用情况 (源自VictoriaMetrics github),不代表 Victora 的性能上限:
- wix.com 使用的 单机版 承接的业务量:
- 累计序列数 4 亿;
- 并发序列数 2000 万;
- 每秒写入点数 80 万;
- 查询频率每分钟 1000 次;
- 查询耗时平均 70ms,99th 是 2 秒;
- Dreamteam 使用 单机版 承接的业务量:
- 累计序列数 3.2 亿
- 并发序列数 72.5 万
- 数据点总数 1550 亿
Wedos.com 使用 集群版 承接的业务量:
vminsert 和 vmselect 是无状态的写入、查询节点
vmstorage 是有状态的存储节点。数据平均分配到 vmstorage 节点,每个 vmstorage 分担一部分数据,没有冗余,如果 vmstorage 节点丢失,那么数据对应丢失。
部署
用下面的 VictoriaMetrics/docker-compose.yaml 在本地启动一个最小集群:
$ git clone https://github.com/introclass/docker-compose-files.git
分别访问下面三个地址,查看组件的状态数据:
insert: http://127.0.0.1:8480/metrics
- select: http://127.0.0.1:8481/metrics
- storage:http://127.0.0.1:8482/metrics

打开 grafana 地址 127.0.0.1:3000,用 admin/admin 登陆后,进入设置密码。
在 grafana 中添加 prometheus 数据源:http://vmselect:8481/select/0/prometheus/
这个数据源地址要和 Prometheus 中的 remote write 相对应
验证数据:
$ curl http://127.0.0.1:8481/select/0/prometheus/api/v1/labels
可以导入 victoria metrics 的dashboards/11176,查看 victoria 的状态。
数据写入
vminsert 的写入 API 格式如下:http://<vminsert>:8480/insert/<accountID>/<suffix>
accountID 是不同用户/租户的 ID,必须是数字,否则通过 vmselect 查询的时候会遇到下面的问题:
# localcluster 不是数字,vmselect 报错auth error: cannot parse accountID from "localcluster": strconv.Atoi: parsing "localcluster": invalid syntax
VictoriaMetrics 支持多种写入方式,通过 sufficx 区分,suffix 支持以下几种:
- prometheus :for inserting data with Prometheus remote write API
- influx/write :for inserting data with Influx line protocol
- influx/api/v2/write :for inserting data with Influx line protocol
- opentsdb/api/put :for accepting OpenTSDB HTTP /api/put requests.
- prometheus/api/v1/import :for importing data obtained via api/v1/export on vmselect
例如在 prometheus 中配置远程写入,使用的 suffix 是 prometheus:
remote_write:- url: http://<vminsert>:8480/insert/<accountID>/prometheusqueue_config:max_samples_per_send: 10000capacity: 20000max_shards: 30
建议根据需要在 Prometehus 中设置全局 label:
global:external_labels:datacenter: dc-123
Prometheus 在 remote_write 时,本地的数据依旧会保存,本地数据保留时间设置:
--storage.tsdb.retention.time=
Victoria Metrics 的数据查询
vmselect 采用 prometheus 的查询语法,API 格式如下:http://<vmselect>:8481/select/<accountID>/prometheus/<suffix>
- suffix 可以是下面的字符串,和 prometheus 的 api 对应:
- api/v1/query :performs PromQL instant query
- api/v1/query_range :performs PromQL range query
- api/v1/series :performs series query
- api/v1/labels :returns a list of label names
- api/v1/label/
/values :returns values for the given according to API - federate :returns federated metrics
- api/v1/export :exports raw data. See this article for details
通过 Prometheus 的 API 查询:
$ curl -g 'http://localhost:9090/api/v1/series' --data-urlencode 'match[]=vm_rows{}' |jq{"status": "success","data": [{"__name__": "vm_rows","instance": "172.29.128.2:8482","job": "victoria","type": "indexdb"},{"__name__": "vm_rows","instance": "172.29.128.2:8482","job": "victoria","type": "storage/big"},{"__name__": "vm_rows","instance": "172.29.128.2:8482","job": "victoria","type": "storage/small"}]}
通过 VictoriaMetrics 的 API 查询:
$ curl 'http://127.0.0.1:8481/select/0/prometheus/api/v1/series' --data-urlencode 'match[]=vm_rows{}' |jq
{
"status": "success",
"data": [
{
"__name__": "vm_rows",
"job": "victoria",
"type": "indexdb",
"instance": "172.29.128.49:8482"
},
{
"__name__": "vm_rows",
"job": "victoria",
"type": "indexdb",
"instance": "172.29.128.2:8482"
},
{
"__name__": "vm_rows",
"job": "victoria",
"type": "indexdb",
"instance": "172.29.128.7:8482"
},
...
Victoria 自身的监控
Victora 官方提供了一个 grafana 面板
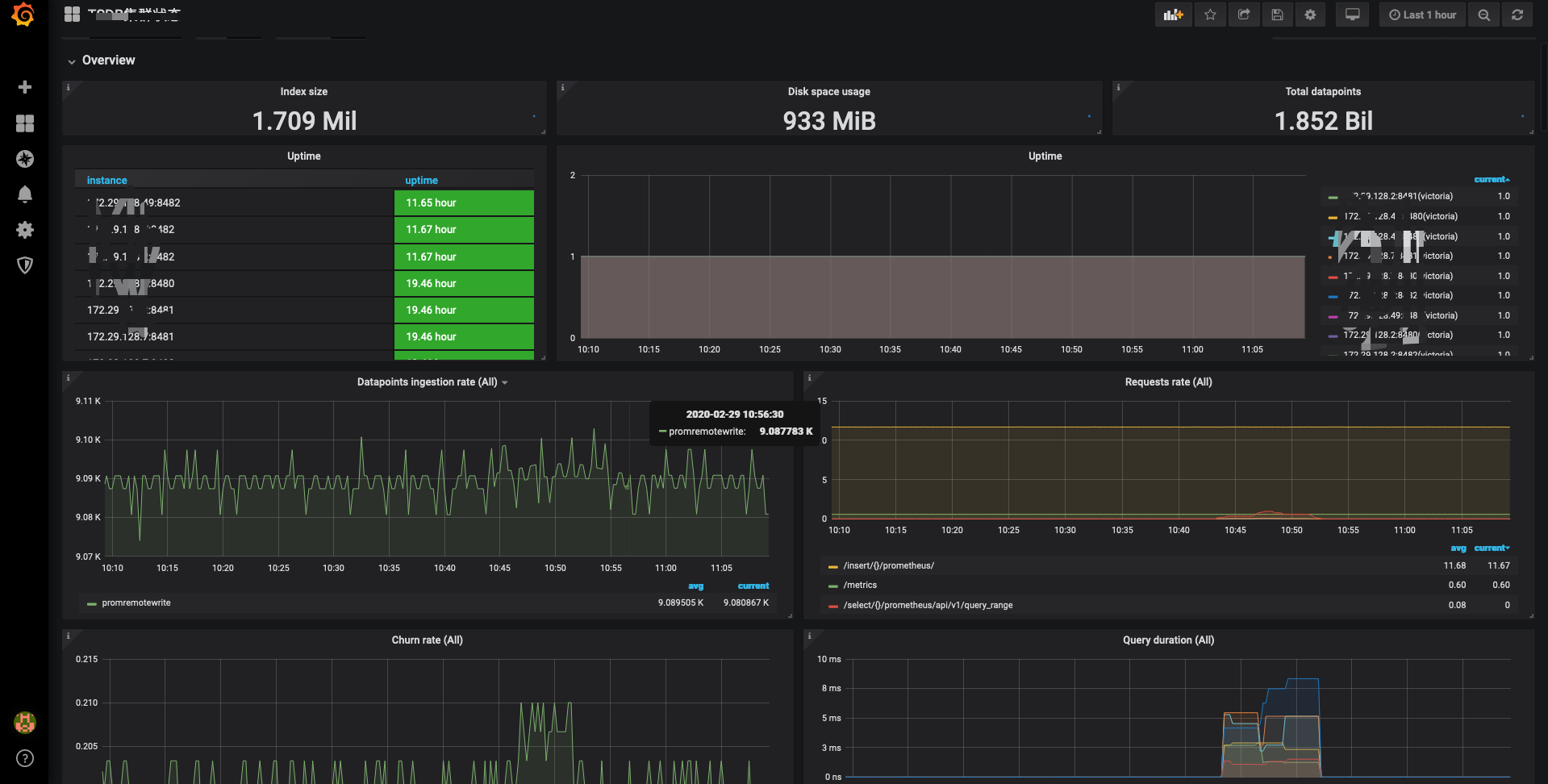
基于Victora的查询
metrics name
Prometheus 查询所有的 metrics(limit限制查询数量)
$ curl "127.0.0.1:9090/api/v1/metadata?limit=2" |jq
{
"status": "success",
"data": {
"prometheus_tsdb_head_min_time": [
{
"type": "gauge",
"help": "Minimum time bound of the head block. The unit is decided by the library consumer.",
"unit": ""
}
],
"prometheus_tsdb_vertical_compactions_total": [
{
"type": "counter",
"help": "Total number of compactions done on overlapping blocks.",
"unit": ""
}
]
}
}
Series
Prometehus 查询 Series Value,注意这个方法只是查询满足条件的时间序列,没有数值:
$ curl -g 'http://127.0.0.1:9090/api/v1/series' --data-urlencode 'match[]=vm_rows{}' --data-urlencode 'start=2020-03-02T00:00:00Z|jq
{
"status": "success",
"data": [
{
"__name__": "vm_rows",
"instance": "vmstorage:8482",
"job": "victoria",
"type": "indexdb"
},
{
"__name__": "vm_rows",
"instance": "vmstorage:8482",
"job": "victoria",
"type": "storage/big"
},
{
"__name__": "vm_rows",
"instance": "vmstorage:8482",
"job": "victoria",
"type": "storage/small"
}
]
}
Victora 会支持
$ curl 'http://127.0.0.1:8481/select/0/prometheus/api/v1/series' --data-urlencode 'match[]=vm_rows{}' |jq
Label & Label Value
$ curl 127.0.0.1:9090/api/v1/labels |jq
{
"status": "success",
"data": [
"GOARCH",
"GOOS",
"GOROOT",
"__name__",
"accountID",
"action",
...
$ curl 127.0.0.1:9090/api/v1/label/job/values | jq
{
"status": "success",
"data": [
"prometheus",
"victoria"
]
}
Victora 会支持
$ curl 127.0.0.1:8481/select/0/prometheus/api/v1/labels |jq
$ curl 127.0.0.1:8481/select/0/prometheus/api/v1/label/job/values | jq
数值查询
Prometheus进行当前值查询
$ curl 'http://localhost:9090/api/v1/query?query=vm_rows' |jq
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "vm_rows",
"instance": "vmstorage:8482",
"job": "victoria",
"type": "indexdb"
},
"value": [
1583123606.056,
"14398"
]
},
...
Victora 会支持
$ curl 'http://localhost:8481/select/0/prometheus/api/v1/query?query=vm_rows' |jq
具体更多查询操作还需要参考github VictoriaMetrics / VictoriaMetrics
知识链接

若有收获,就点个赞吧
0 人点赞
