mysql
主从复制

Master:当主库的数据自更新的时候,将更新的操作记录到binlog文件中,这个过程叫二进制日志事件binary log events,并通知Slave文件有更新。当Slave向Master请求时,将binlog发送给Slave
Slave:当接收到Master的binlog文件时,会写入本地的中继日志relay log中。slave重做中继日志的事件,将改变应用到自己的数据库中。mysql复制是异步且是串行化的。
每一个slave只有一个master,每个slave只能有唯一一个服务器ID,每个master可以有多个slave
集群高可用方案
Mysql主从架构
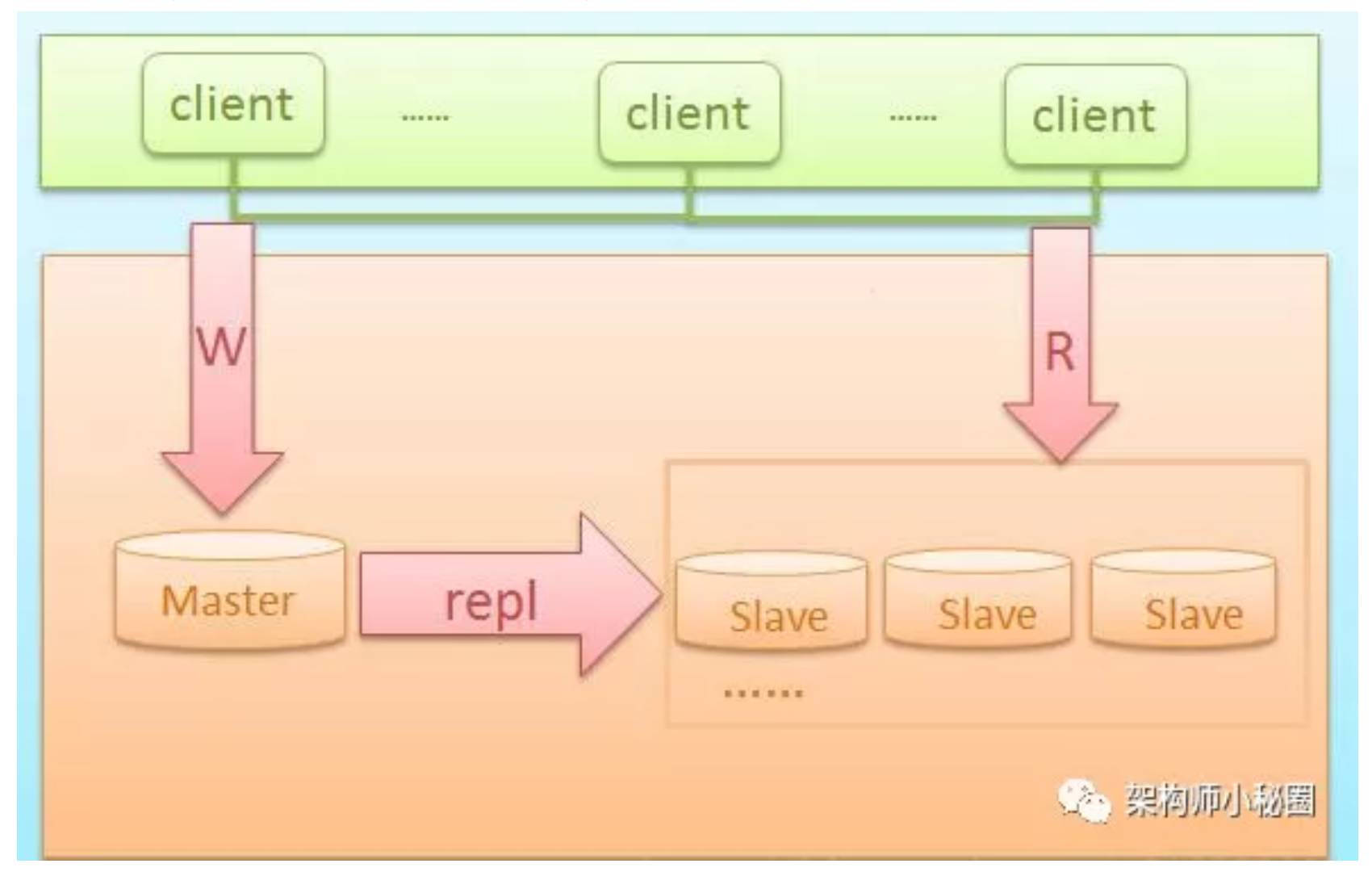
此种架构完全依赖于mysql的主从复制,它的特点:
- 成本低,部署快速且方便
- 读写分离
- 可以通过及时增加从库来减少读库压力
不过它还是存在一些问题,如:
- 主库单点故障
- 数据一致性问题(同步延迟造成)
MySQL + DRBD 架构
通过DRBD基于block块的复制模式,快速进行双主故障切换,很大程度解决了主库单点故障问题DRBD(分布式复制块设备)是一个和用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。它可以实现活动节点存储数据更动后自动复制到备用节点相应存储位置。
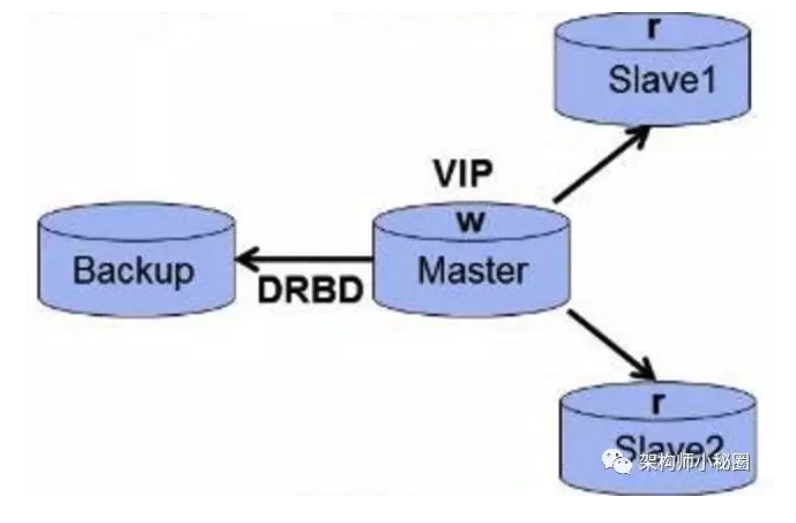
当Master节点接收到数据发往内核的数据通路上,DRBD在数据通路中注册钩子检查数据(类似ipvs),当接收到的数据是发往自己管理的存储位置,就复制一份,一份存到本机的存储,另一份就发给TCP/IP协议栈,通过网卡网络传输到Backup主机的网上TCP/IP协议栈;而Backup主机节点运行的DRBD模块同样在数据通路上检查数据,当收到传输过来的数据时,就存储到DRBD存储设备对应的位置。
此架构特点:
- 高可用软件可使用心跳全面负责VIP、数据与DRBD服务的管理
- 主故障后可自动快速切换,并且从库仍然能通过VIP与新主库进行数据同步
MySQL + MHA架构
MHA 目前在 Mysql 高可用方案中应该也是比较成熟和常见的方案,它由日本人开发出来,在 mysql 故障切换过程中,MHA 能做到快速自动切换操作,而且还能最大限度保持数据的一致性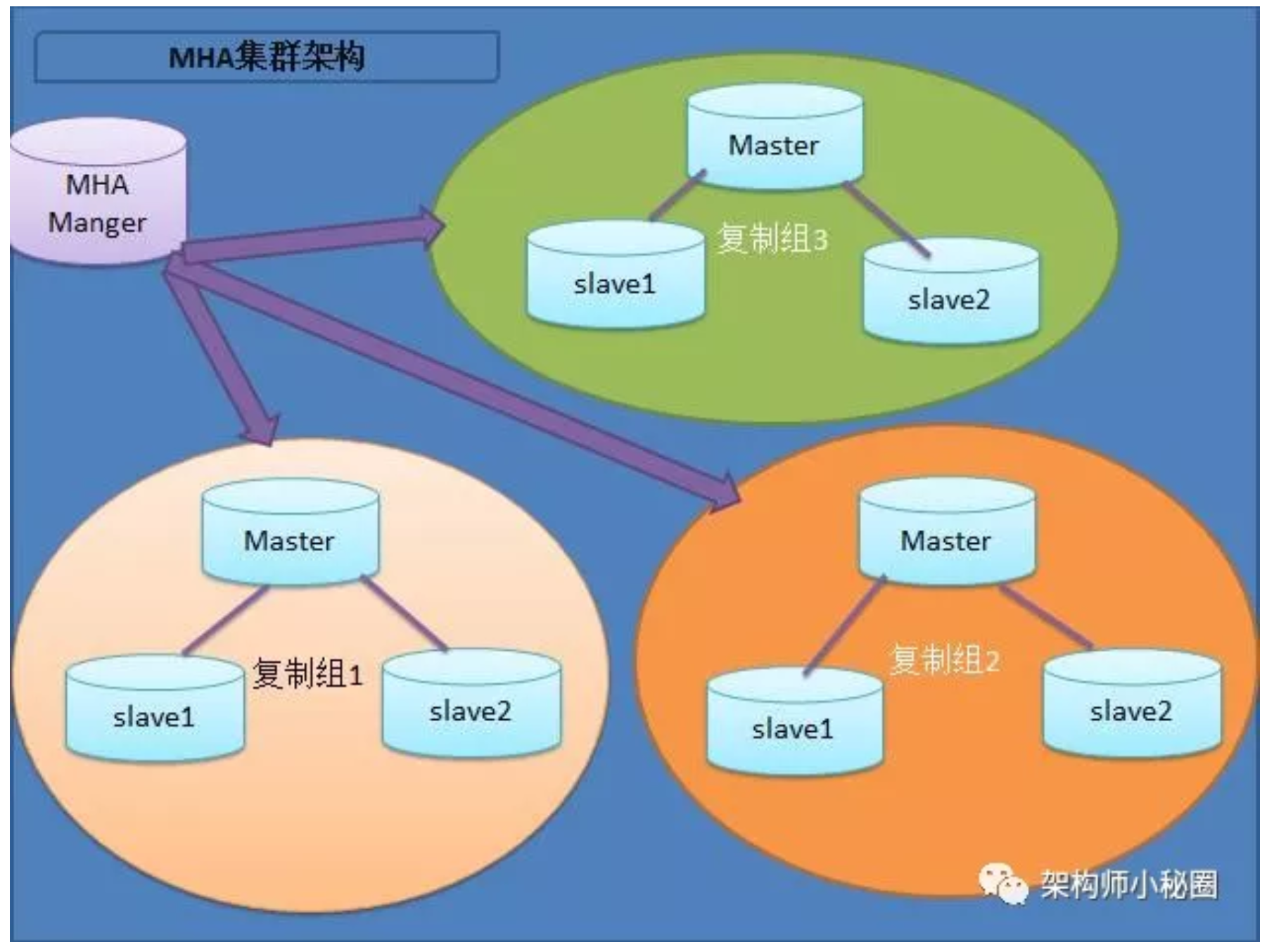
MHA服务有两种角色,MHA Manager(管理节点)和MHA Node(数据节点):
- MHA Manager: 通常单独部署在一台独立机器上管理多个master/slave集群(组),每个master/slave 集群称为一个application,用来管理统筹整个集群
- MHA Node : 运行在每台MySQL服务器上,它通过监控具备解析和清理logs功能的脚本来加快故障转移,主要是接收管理节点所发出指令的代理,代理需要运行在每一个 mysql 节点上。简单讲 node 就是用来收集从节点服务器上所生成的 bin-log 。对比打算提升为新的主节点之上的从节点的是否拥有并完成操作,如果没有发给新主节点在本地应用后提升为主节点。
工作原理有以下几点:
- 从宕机崩溃的
master保存二进制日志事件(binlog events); - 识别含有最近更新的
slave; - 应用差异的中继日志(
relay log) 到其他slave; - 应用从 master 保存的二进制日志事件(binlog events);
- 提升一个 slave 为新 master ;
- 使用其他的 slave 连接新的 master 进行复制。
特点:
- 安装部署简单,不影响现有架构
- 自动监控和故障转移
- 保障数据一致性
- 故障切换方式可使用手动或自动多向选择
-
MySQL + MMM架构
MMM即Master-Master Replication Manager for Mysql(主主复制管理器),是关于mysql主主复制配置配置的监控。
MySQL 本身没有提供 replication failover 的解决方案,通过 MMM 方案能实现服务器的故障转移,从而实现 mysql 的高可用。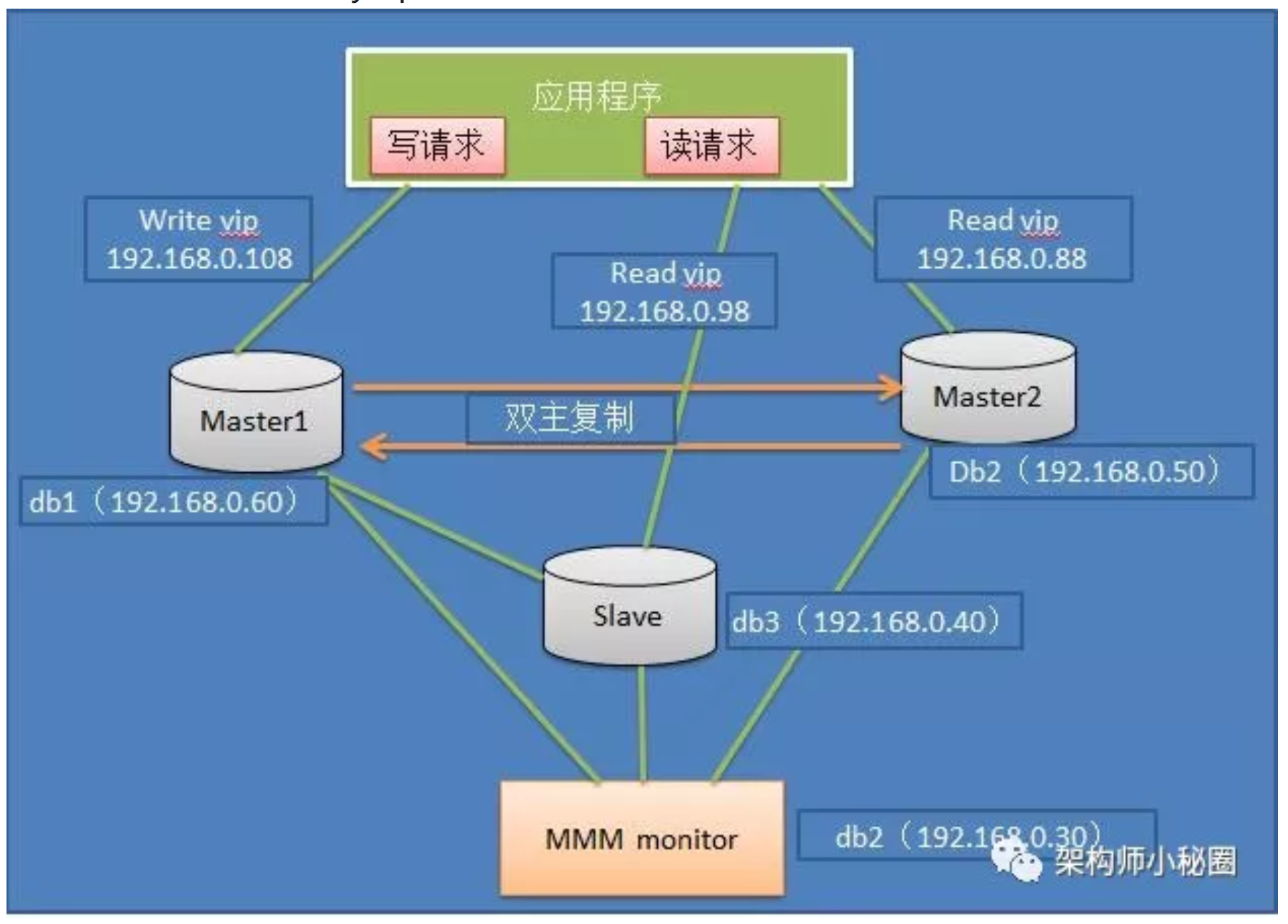
特点: 安全,稳定性较高,可扩展性好
- 对服务器数量要求至少三台以上
- 对双主(主从复制性)要求较高
- 同样可以实现读写分离
postgresql
流复制
postgreSQL是通过wal日志来进行数据同步的。wal日志传送的方式有两种:
- 基于文件的日志传送
- 流复制
不同于基于文件的日志传送,流复制的关键在于流,所谓流,就是没有界限的一串数据,类似于河里的水流,是连成一片的。因此流复制允许一台后备服务器比使用基于文件的日志传送更能保持为最新的状态。
比如我们有一个大文件要从本地主机发送到远程主机,如果是按照流接收到的话,我们可以一边接收,一边将文本流存入文件系统。这样,等到流接收完了,硬盘写入操作也已经完成。
流复制:备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record。
PG物理流复制按照同步方式分为两类:
- 异步流复制
- 同步流复制
物理流复制具有以下特点:
- 延迟极低,不怕大事务
- 支持断点续传
- 支持多副本
- 配置简单
- 备库与主库物理完全一致,并支持只读
WAL日志机制保证了事务的持久性和数据完整性,同时又避免了频繁IO对性能的影响。每当发生事务提交,只需要通过提交wal日志即可,而且wal日志的提交是顺序的,性能也很高
对数据库操作会以record为单位首先记录到wal日志中,在checkpoint时才对数据进行刷盘(background writer会定时刷脏数据,但最终还是都由checkpoint确认都刷盘成功)。
原理: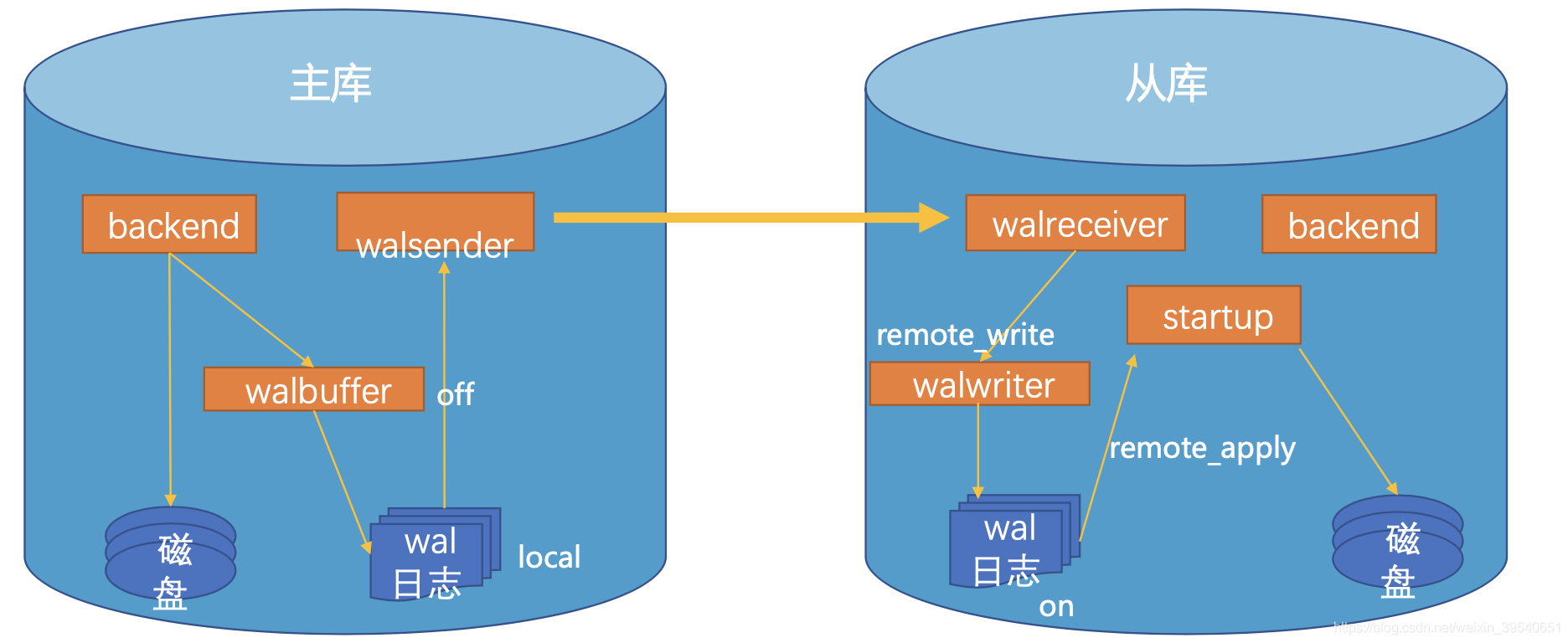
- 事务commit之后,日志在主库写入WAL日志,还需要根据配置的日志同步级别,等待从库反馈的接受结果
- 主库通过日志传输进程将日志块传给从库,从库接受进程收到日志开始回放,最终保证主从数据一致
同步级别:
- remote_apply:事务commit或rollback时,等待其redo在primary、以及同步standby(s)已持久化,并且其redo在同步standby(s)已apply。
- on:事务commit或rollback时,等待其redo在primary、以及同步standby(s)已持久化。
- remote_write:事务commit或rollback时,等待其redo在primary已持久化; 其redo在同步standby(s)已调用write接口(写到 OS, 但是还没有调用持久化接口如fsync)。
- local:事务commit或rollback时,等待其redo在primary已持久化;
- off:事务commit或rollback时,等待其redo在primary已写入wal buffer,不需要等待其持久化;
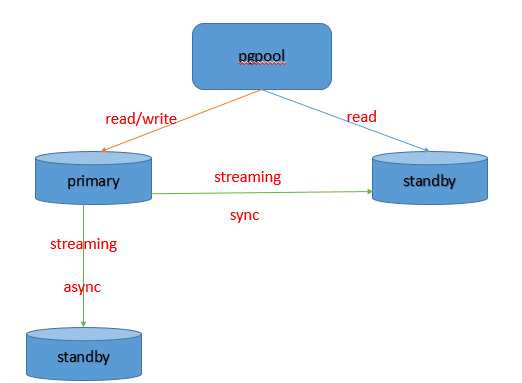
主备切换流程

若有收获,就点个赞吧
0 人点赞
