es如何选举 es写入调优 如何避免脑裂 es对于大数据量的聚合 es如何监控集群状态 es更新数据流程
ES
ElasticSearch 分布式搜索和分析引擎。它是基于lucene搜索引擎开发的,拥有全文搜索、结构化搜索、分析等功能。
ES 通过简单的restful API来隐藏lucene的复杂性,来使全文搜索变得简单
Solr的架构不适合实时搜索的应用,随着数据量增加,solr的搜索效率会降低。当实时建立索引时,solr会产生io阻塞。 solr使用zookeeper进行分布式管理,而es有自己的分布式协调管理系统
核心概念
es是面向文档的,一切都是json
- 关系型数据库与es的对比
es将数据存储在索引中,可以使用关系型数据库的结构来类比ES
| DBMS | ES |
|---|---|
| 库(db) | 索引(index) |
| tables | 类型(types) |
| rows | 文档(documents) |
| columns | 字段(fields) |
- 索引
索引时一组文档的集合,当索引一篇文档时,可以通过 索引 -> 类型 -> 文档ID 找到 分片
es把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移。ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配。
当数据被写入分片时,它会定期发布到磁盘上的不可变的 Lucene 分段中用于查询。随着分段数量的增长,这些分段会定期合并为更大的分段。 此过程称为合并。 由于所有分段都是不可变的,这意味着所使用的磁盘空间通常会在索引期间波动,因为需要在删除替换分段之前创建新的合并分段。 合并可能非常耗费资源,特别是在磁盘I / O方面。实际一个分片就是一个lucene索引。es的索引事实是由多个lucene索引组成
主分片与副本分片
索引会自动存储到各个分片上,ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片。主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求。
副本是为提高搜索性能,用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。主分片和副本分片都不会在同一个节点内
文档
es索引和搜索数据的最小单元是文档
文档就是一条条数据,一篇文档包含字段和对应的值{k:v}
ES搜索原理
与传统的数据库不同,在es中,每个字段里面的每个单词都是可以被搜索的。
这种特性是由底层lucene支持的。lucene使用倒排索作为底层,这种结构适用于快速的全文搜索。一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
为了支持这个特性,es中会维护一个叫做“invertedindex”(也叫逆向索引)的表,表内包含了所有文档中出现的所有单词,同时记录了这个单词在哪个文档中出现过。
比如以下有三个文档
- doc1: aaa, bbb, ccc, ddd
- doc2: bbb, ccc
- doc3: aaa, bbb, ddd
那么es会维持以下一个数据结构
| Term | DOC1 | DOC2 | DOC3 |
|---|---|---|---|
| aaa | ✔ | ✔ | |
| bbb | ✔ | ✔ | ✔ |
| ccc | ✔ | ✔ | |
| ddd | ✔ | ✔ |
这样当我们随意搜索任意一个单词,es只要遍历一遍这个表,就可以指导有那些文档被匹配到了。
当我们搜索多个词时,es可以完全过滤掉无关的所有数据,提高效率。
index 设置
每个索引都可以设置索引级别:
- static 只能在索引创建的时候,或在一个关闭的索引上设置
-
static
index.number_of_shards :一个索引应该有的主分片(primary shards)数。默认是5。而且,只能在索引创建的时候设置。(注意,每个索引的主分片数不能超过1024。当然,这个设置也是可以改的,通过在集群的每个节点机器上设置系统属性来更改,例如:export ES_JAVA_OPTS=”-Des.index.max_number_of_shards=128”)
- index.shard.check_on_startup :分片在打开前是否要检查是否有坏损。默认是false。
index.routing_partition_size :自定义的路由值可以路由到的分片数。默认是1
dynamic
index.number_of_replicas :每个主分片所拥有的副本数,默认是1。
- index.auto_expand_replicas :根据集群中数据节点的数量自动扩展副本的数量。默认false。
- index.refresh_interval :多久执行一次刷新操作,使得最近的索引更改对搜索可见。默认是1秒。设置为-1表示禁止刷新。
- index.max_result_window :在这个索引下检索的 from + size 的最大值。默认是10000
PS:也就是说最多可以一次返回10000条
分析器
索引分析模块是一个可配置的分析器注册表,可用于将字符串字段转换为以下各个场景中的Term:
- 添加到反向索引( inverted index)以使文档可搜索
- 用于高级查询,如match查询
- 分析器用于将一个字符串转成一个一个的Term;
- 这些Term可以被添加到反向索引中,以使得该文档可以通过这个Term被检索到;
- 这些Term还可以高级查询,比如match查询
segment(端)
向索引中插入文档时,文档首先被保存在内存缓存(in-memory buffer)中,同时将操作写入到translog中,此时这条刚插入的文档还不能被搜索到。默认1秒钟refresh一次,refresh操作会将文件写到操作系统的文件系统缓存中,并形成一个segment,refresh后文档可以被检索到。
当flush的时候,所有segment被同步到磁盘,同时清空translog,然后生成一个新的translog
Lucene把每次生成的倒排索引叫做一个segment,也就是说一个segment就是一个倒排索引。
一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。 由于词典的size会很大,全部装载到heap里不现实,因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。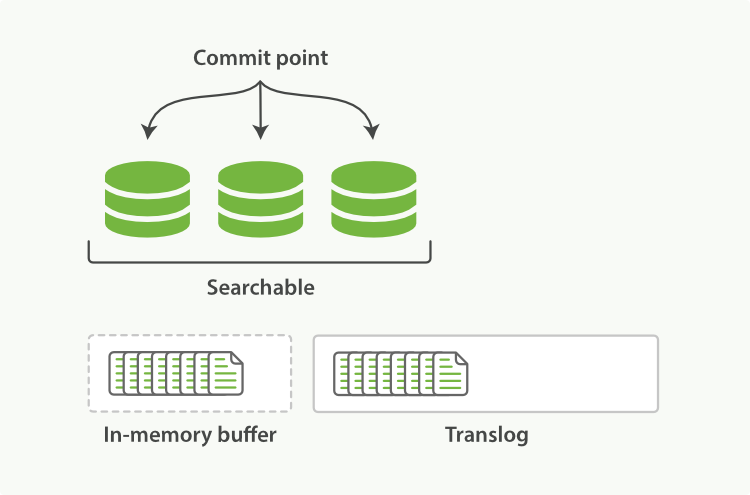
merge
在Elasticsearch中,一个分片就是一个Lucene索引,而且一个Lucene索引被分解成多个段(segments)。段是索引中存储索引数据的内部存储元素,并且是不可变的。较小的段定期合并到较大的段中,以控制索引大小。
合并调度程序(ConcurrentMergeScheduler)在需要时控制合并操作的执行。合并在单独的线程中运行,当达到最大线程数时,将等待进一步的合并,直到合并线程可用为止。
慢日志
search slow log 查询慢日志
分片级慢查询日志,允许将慢查询记录到专用的日志文件中(都是动态设置,而且是按索引设置的,可以设置时间,级别等)
index slow log 索引慢日志
es写入过程
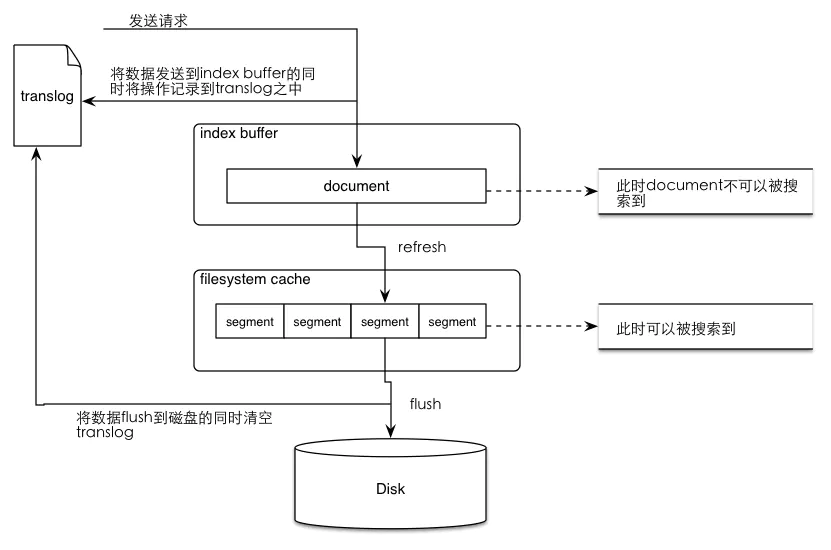
- 数据写入
- 进入ES index buffer (同时记录到translog)
- 生成倒排索引分片(segment)
- 将 buffer 中的 segment 先同步到文件系统缓存中,然后再刷写到磁盘,同时清空translog
使用golang操作ES
当ES用作日志分析时,日志通常由filebeat和logstash收集并写到ES中,以下仅介绍ES在golang中的读方法。
golang有两个es的操作库,其中官方库是github.com/elastic/go-elasticsearch使用起来并不方便,而第三方开发的github.com/olivere/elastic各个版本都有对应的sdk,文档也丰富,因此选择使用这个库
初始化
var hostlist []string{"http://ip1:9200/","http://ip2:9200/","http://ip3:9200/"}var ESClient *elastic.Clientfunc InitEs() {var err error// 创建es连接,如果通过nat地址访问,为防止地址被自动转换,可加elastic.SetSniff(false)ESClient, err = elastic.NewClient(elastic.SetURL(hostlist...))if err != nil {logs.Error(err)os.Exit(1)}for _, v := range hostlist {// 尝试请求esinfo, code, err := ESClient.Ping(v).Do(context.Background())if err != nil {logs.Error(err)os.Exit(1)}logs.Info("Elasticsearch Node %s returned with code %d and version %s\n", v, code, info.Version.Number)esversion, err := ESClient.ElasticsearchVersion(v)logs.Info("Elasticsearch Node %s version %s\n", v, esversion)}}
搜索
以下展示一个文档样例
{"_index": "eventti-2020.08.05","_type": "doc","_id": "AA5ivXMBJrDaLyIboWGQ","_version": 1,"_score": null,"_source": {"logid": "878f5e31-f2f9-40dd-b0c4-ffe3302a7182","@version": "1","logtime": 1596610219685,"agent": {"hostname": "filebeat-cm2nn","type": "filebeat","ephemeral_id": "49ba4ce1-8479-45b6-a872-0de7985d92d2","version": "7.6.2","id": "220b2714-01bd-421d-b052-20af980b187b"},"logmessage": "模型 [dataui] 实例 [ea8b2815-ed5d-4fdd-b0ac-1be1e0e8d2ea] 被删除","logtype": "CMDB_NODE_DELETE","username": "admin","log": {"offset": 11247,"file": {"path": "/var/log/eventti/eventti.log"}},"input": {"type": "log"},"message": "2020/08/05 14:50:19 [I] id:878f5e31-f2f9-40dd-b0c4-ffe3302a7182 message:模型 [dataui] 实例 [ea8b2815-ed5d-4fdd-b0ac-1be1e0e8d2ea] 被删除 type:CMDB_NODE_DELETE timestamp:1596610219685 user:admin","logdate": "2020/08/05 14:50:19","tags": ["beats_input_codec_plain_applied"],"host": {"hostname": "filebeat-cm2nn","architecture": "x86_64","os": {"version": "7 (Core)","codename": "Core","name": "CentOS Linux","kernel": "3.10.0-693.el7.x86_64","platform": "centos","family": "redhat"},"containerized": false,"name": "filebeat-cm2nn"},"loglevel": "[I]","fields": {"log_source": "eventti"},"@timestamp": "2020-08-05T06:50:19.685Z","ecs": {"version": "1.4.0"}},"fields": {"@timestamp": ["2020-08-05T06:50:19.685Z"],"logdate": ["2020-08-05T14:50:19.000Z"]},"sort": [1596610219685]}
golang在查询es时使用链式调用,比如models.ESClient.Search().Index("eventti-*").Type("doc").Query(boolQuery).Size(size).From((page - 1) * size).Do(context.Background()),仅需要连续调用搜索函数,最后执行搜索即可
查询范例实现如下
// 查询入参type EventParam struct {User string `json:"username"`Type string `json:"logtype"`Message string `json:"logmessage"`Time int64 `json:"logtime"`}func Search(req *EventParam, start,end,page, size int) ([]*eventti.EventParam, int, error) {// 定义分页if page < 1 {page = 1}if size < 0 {size = 10000}// 定义搜索的queryboolQuery := elastic.NewBoolQuery()if req.User != "" {boolQuery.Filter(elastic.NewMatchQuery("username", strings.ToLower(req.User)))}if req.Type != "" {boolQuery.Filter(elastic.NewMatchQuery("logtype", req.Type))}if req.Message != "" {boolQuery.Filter(elastic.NewMatchPhraseQuery("logmessage", req.Message))}// 定义查询时间范围if req.Start != 0 && req.End != 0 {boolQuery.Filter(elastic.NewRangeQuery("logtime").Gte(start), elastic.NewRangeQuery("logtime").Lte(end))}// 执行搜索res, _ := models.ESClient.Search().Index("eventti-*").Type("doc").Query(boolQuery).Size(size).From((page - 1) * size).Do(context.Background())var typ EventParamresitemlist := make([]*eventti.EventParam, 0)//从搜索结果中取数据,只会取EventParam定义的字段for _, item := range res.Each(reflect.TypeOf(typ)) {if t, ok := item.(EventParam); ok {tmp := eventti.EventSearchResItem{User: t.User,Message: t.Message,Time: strconv.FormatInt(t.Time, 10),Type: t.Type,}resitemlist = append(resitemlist, &tmp)}}return resitemlist, len(resitemlist), nil}
ES集群
Elasticsearch的任意一个节点都可以设置node.master和node.data属性,该属性的意义如下表所示
| master \ data | true | false |
|---|---|---|
| true | 既是Master Eligible,又是data节点 | 单纯的Master Eligible节点 |
| false | 单纯的data节点 | 纯粹的Coordinating Node,协调节点负责查询时的数据收集、合并以及聚合等操作,ES中所有节点都是协调节点 |
conf/elasticsearch.yml:node.master: true/falsenode.data: true/false
当node.master为true时,其表示这个node是一个master的候选节点,可以参与选举,在ES的文档中常被称作master-eligible node,类似于MasterCandidate。ES正常运行时只能有一个master(即leader),多于1个时会发生脑裂。
当node.data为true时,这个节点作为一个数据节点,会存储分配在该node上的**shard**的数据并负责这些**shard**的写入、查询等。
此外,任何一个集群内的node都可以执行任何请求,其会负责将请求转发给对应的node进行处理,所以当node.master和node.data都为false时,这个节点可以作为一个类似proxy的节点,接受请求并进行转发、结果聚合等。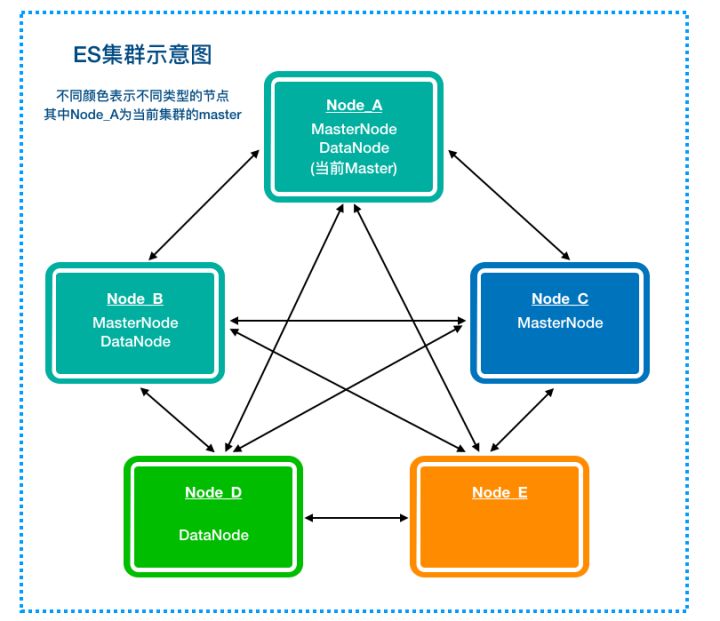
选主
ZenDiscovery是ES自己实现的一套用于节点发现和选主等功能的模块,没有依赖Zookeeper等工具
简单来说,节点发现依赖以下配置:(在k8s中使用环境变量写入,以及确定发现类型和集群名称)
conf/elasticsearch.yml:discovery.zen.ping.unicast.hosts: [1.1.1.1, 1.1.1.2, 1.1.1.3]
这个配置可以看作是,在本节点到每个hosts中的节点建立一条边,当整个集群所有的node形成一个联通图时,所有节点都可以知道集群中有哪些节点,不会形成孤岛。
上面提到,集群中可能会有多个master-eligible node,此时就要进行master选举,保证只有一个当选master。如果有多个node当选为master,则集群会出现脑裂,脑裂会破坏数据的一致性,导致集群行为不可控,产生各种非预期的影响。
为了避免产生脑裂,ES采用了常见的分布式系统思路,保证选举出的master被多数派(quorum)的master-eligible node认可,以此来保证只有一个master。这个quorum通过以下配置进行配置:
conf/elasticsearch.yml:discovery.zen.minimum_master_nodes: 2
- master选举谁发起,什么时候发起
master选举当然是由master-eligible节点发起,当一个master-eligible节点发现满足以下条件时发起选举:
- 该
master-eligible节点的当前状态不是master。 - 该
master-eligible节点通过ZenDiscovery模块的ping操作询问其已知的集群其他节点,没有任何节点连接到master。 - 包括本节点在内,当前已有超过
minimum_master_nodes个节点没有连接到master。
总结一句话,即当一个节点发现包括自己在内的多数派的master-eligible节点认为集群没有master时,就可以发起master选举。
- 选举谁?
- 当
clusterStateVersion越大,优先级越高。这是为了保证新Master拥有最新的clusterState(即集群的meta),避免已经commit的meta变更丢失。因为Master当选后,就会以这个版本的clusterState为基础进行更新。(一个例外是集群全部重启,所有节点都没有meta,需要先选出一个master,然后master再通过持久化的数据进行meta恢复,再进行meta同步)。 - 当
clusterStateVersion相同时,节点的Id越小,优先级越高。即总是倾向于选择Id小的Node,这个Id是节点第一次启动时生成的一个随机字符串。之所以这么设计,应该是为了让选举结果尽可能稳定,不要出现都想当master而选不出来的情况。
- 什么时候选举成功?
当一个master-eligible node(我们假设为Node_A)发起一次选举时,它会按照上述排序策略选出一个它认为的master。
- 假设Node_A选Node_B当Master:
Node_A会向Node_B发送join请求,那么此时:
- 如果Node_B已经成为Master,Node_B就会把Node_A加入到集群中,然后发布最新的cluster_state, 最新的cluster_state就会包含Node_A的信息。相当于一次正常情况的新节点加入。对于Node_A,等新的cluster_state发布到Node_A的时候,Node_A也就完成join了。
- 如果Node_B在竞选Master,那么Node_B会把这次join当作一张选票。对于这种情况,Node_A会等待一段时间,看Node_B是否能成为真正的Master,直到超时或者有别的Master选成功。
- 如果Node_B认为自己不是Master(现在不是,将来也选不上),那么Node_B会拒绝这次join。对于这种情况,Node_A会开启下一轮选举。
- 假设Node_A选自己当Master:
此时NodeA会等别的node来join,即等待别的node的选票,当收集到超过半数的选票时,认为自己成为master,然后变更cluster_state中的master node为自己,并向集群发布这一消息。
- 选举怎么保证不脑裂
集群扩缩容
扩容dataNode
当节点存储不足或计算资源不足时,需要扩容,只针对dataNode
缩容dataNode
首先需要将node的shards迁移到其他节点: 设置allocation规则,禁止分配Shard,然后rebalance
PUT _cluster/settings{"transient" : {"cluster.routing.allocation.exclude._ip" : "10.0.0.1"}}
扩容master
由于ES采用了多数派策略,则需要修改
discovery.zen.minimum_master_nodesdiscovery.zen.minimum_master_nodes的值curl -XPUT localhost:9200/_cluster/settings -d '{"persistent" : {"discovery.zen.minimum_master_nodes" : 3}}
缩容
与raft相比
raft算法是近几年很火的一个分布式一致性算法,其实现相比paxos简单,在各种分布式系统中也得到了应用。这里不再描述其算法的细节,我们单从master选举算法角度,比较一下raft与ES目前选举算法的异同点:
相同点
多数派原则:必须得到超过半数的选票才能成为master。
选出的leader一定拥有最新已提交数据:在raft中,数据更新的节点不会给数据旧的节点投选票,而当选需要多数派的选票,则当选人一定有最新已提交数据。在es中,version大的节点排序优先级高,同样用于保证这一点。
不同点
正确性论证:raft是一个被论证过正确性的算法,而ES的算法是一个没有经过论证的算法,只能在实践中发现问题,做bug fix,这是我认为最大的不同。
- 是否有选举周期term:raft引入了选举周期的概念,每轮选举term加1,保证了在同一个term下每个参与人只能投1票。ES在选举时没有term的概念,不能保证每轮每个节点只投一票。
- 选举的倾向性:raft中只要一个节点拥有最新的已提交的数据,则有机会选举成为master。在ES中,version相同时会按照NodeId排序,总是NodeId小的人优先级高。
ES的写入调优
在ES的默认设置下,是综合考虑数据的可靠性,搜索实时性,写入速度等因素的。当离开默认设置,追求极致写入速度时,很多是以牺牲可靠性和搜索实时性为代价的。有时候,业务上对数据可靠性和搜索实时性要求不高,反而对写入速度要求很高,此时可以调整一些策略,最大化写入速度。
综合来说可以从以下几个方面入手:
- 加大
translog flush间隔,目的是降低iops,writeblock(可靠性降低) - 加大
index refresh间隔,除了降低I/O,更重要的是降低segment merge频率 - 调整
bulk请求(批处理) - 优化磁盘间的任务均匀情况,将
shard尽量均匀分布到物理机各个磁盘 - 优化节点间的任务分布,将任务尽量均匀地发到各节点
优化Lucene层建立索引的过程,目的是降低CPU占用率,例如,禁用_all字段
加大translog flush间隔
ES请求进行,先会写入到translog文件中,在ES 2.x开始,默认情况下,translog的持久化策略为:每个请求都
**flush**。对应配置index.translog.durability:requestes的各个shard会每个30分钟进行一次
flush操作。- 当translog的数据达到某个上限的时候会进行一次
flush操作。
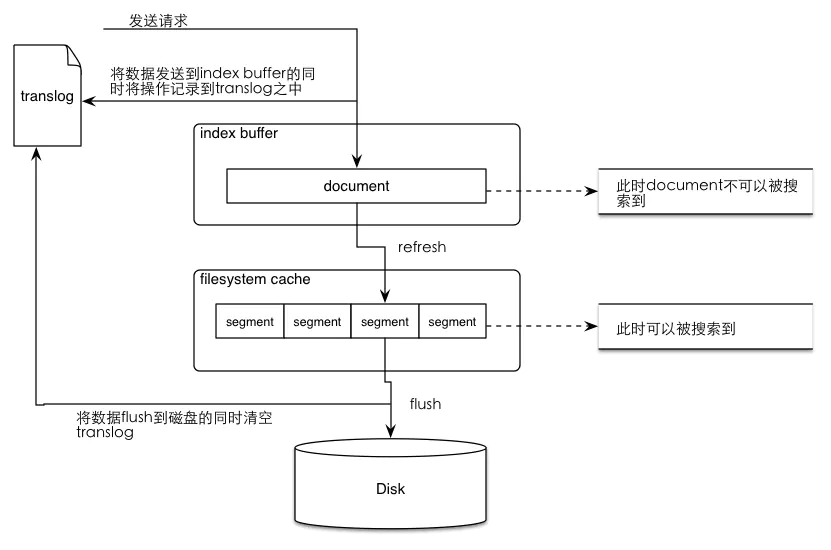
这是影响ES写入的最大因素。但是只有这样,写操作才可能是最可靠的,如果系统允许接收一定概率的数据丢掉,则可以调整translog持久化策略为周期性和一定大小的时候flush
# 设置translog策略为异步,时间120sindex.translog.durability:async# 设置刷盘时间为120s,默认5sindex.translog.sync_interval:120s# 超过设置大小会导致refresh操作,产生新的Lucene分段。默认为512MBindex.translog.flush_threshold_size:1024mb
默认translog的策略是request,即所有写操作都会同步的写一次到translog,即它必须修改完translog之后才会向客户端报告写操作。如果改为async,加长刷盘时间,则可以使得写操作变快,不过在硬件失败的情况下,translog提交之前(未刷盘)的数据都会丢失
索引刷新间隔refresh_interval
默认情况下索引的refresh_interval为1秒,这意味着数据写如1秒后就可以被搜索到,每次索引的refresh会产生一个新的Lucene段(segment),试想以下,如果segment过多会怎么样,因此ES 会进行segment merge 段合并,如果不需要这么高的搜索实时性,可以适当降低refresh周期
# 多久执行一次刷新操作,使得最近的索引更改对搜索可见index.refresh_interval:120s
segment段合并优化
segment merge 操作对系统I/O和内存占用都比较高,从ES 2.0 开始,merge操作不再由ES 控制,而是由Lucene 控制,改为以下:
# 最大线程数index.merge.scheduler.max_thread_count# segment合并策略index.merge.policy.*
最大线程数max_thread_count默认值是:Math.max(1,Math.min(4,Runtime.getRuntime().availableProcessors()/2))
这是一个比较理想的值,如果只是一块硬盘而非SSD,则应该设置为1,因为在旋转存储介质上并发写,由于寻址原因,只会降低写入速度。
merge策略index.merge.policy有三种:
- tiered(默认)
- log_byete_size
- log_doc
索引创建时合并策略就已确定,不能进行修改,但是可以动态更新策略参数,可以不做此项调整。
如果堆栈经常有很多merge,则可以尝试调整以下策略配置:
- segments_per_tier: 该属性指定了每层分段的数量,取值越小最终segment越少,因此需要merge操作越多,可以考虑适当增加值,默认10,其应该大于等于
index.merge_at_once加大触发合并的段的时机
index.merge.policy.segments_per_tier
- 调整segment最大容量
让段变小,它就不能总是合并;
# 指定单个segment最大容量
index.merge.policy.max_merged_segment
index buffer
indexing buffer 在为doc建立索引时使用,当缓存满时会刷入磁盘,生成一个新的segment,这是除了refresh_interval 刷新索引外,另一个生成新segment的机会。每个shard有自己的indexing buffer,下面的这个buffer大小的配置需要除以这个节点上索引shard的数量:
# 默认是整个堆空间的10%
indices.memory.index_buffer_size
# 默认48MB
indices.memory.min_index_buffer_size
# 默认无限制
indices.memory.max_index_buffer_size
在执行大量的索引操作时,indices.memory.index_buffer_size的默认设置可能不够,这和可用堆内存,单节点上的shard数量相关,可以考虑适当增大该值。
执行大量索引时(插入即创建索引),如果过buffer大一点,可以创建的更快,写入也快
bulk
批量写比一个索引请求只写单个文档的效率高得多,但是要注意bulk请求的整体字节数不要太大,太大可能给集群带来内存压力,因此每个请求最好避免超过几十MB,即使较大得请求看上去执行可能更好。
索引建立过程属于CPU密集型任务,应该使用固定大小的线程池,来不及处理的任务放入队列。这样可以减少上下文的切换带来的性能消耗,队列大小要适当,过大的队列导致较高的GC压力,并可能导致FGC频繁发生。
bulk写请求是一个长任务,为了给系统增加足够的写入 压力,写入过程应该多个客户端,多个线程冰箱执行。
磁盘间的任务均衡
ES 在分配shard的时候,落到各个磁盘的shard可能并不均匀,这种不均匀可能导致某些磁盘繁忙,对写入性能会产生一定的影响
节点间的任务均衡,为了节点间的任务尽量均衡,数据写入客户端应该把bulk请求轮询发送到各个节点。
优化索引
索引建立过程是CPU密集型任务
- 自动生成docID(避免ES对自定义ID验证的操作)
- 调整字段Mapping
- 减少不必要的字段数量
- 将不需要建立索引字段的index属性设置为not_analyzed或no。对字段不分词或不建立索引,减少相应的操作,特别是binary类型
- 减少字段内容长度
- 使用不同的分析器(analyzer),不同分析器之间的运算复杂度也不相同
- 调整_source字段
_source字段用于存储doc原始数据,对于部分不需要存储的字段,可以通过includes excludes过滤,或者禁用_source,一般实际场景不会禁用
- 禁用_all
从ES 6.0开始,_all字段默认不启用,_all字段中包含所有字段分词后的关键词,作用是可以搜索的时候不指定特定字段,从所有字段所有中减少。
对Analyzed的字段禁用Norms
Norms用于在搜索时计算doc的评分,如果不需要评分,则可以将其禁用:
"title":{"type":"string","norms":{"enabled":false}}index_options设置
index_options用于控制在建立倒排索引过程中,哪些内容会被添加到倒排索引中,例如,doc数量,词频, positions,offsets等信息,优化这些设置可以一定程度上降低索引过程中的计算任务,接收CPU占用率(注:实际场景一般不会用,除非方案一开始很明确)
ES如何监控集群状态
ES查看集群的状态实际上也是使用RESTful的接口,而且一般用的是GET方法
查看集群健康状态
$ curl http://127.0.0.1:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1506327257 16:14:17 ruan_ES green 2 2 12 6 0 0 0 0 - 100.0%
- 集群状态
- 节点数
- 数据节点数
- 分片数
- 主分片数
-
查看集群的索引数
$ curl http://127.0.0.1:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .kibana fOZj7Gw4TcCh2J-NqqN7kw 1 1 1 0 6.4kb 3.2kb green open school 3siCj6cRSHGdP7kvXPWQgw 5 1 2 0 14.1kb 索引健康
- 状态
- uuid
- 分片数
- 文档数
- 已删除文档数
- 索引存储的总容量
-
磁盘分配状态
$ curl http://127.0.0.1:9200/_cat/allocation?v shards disk.indices disk.used disk.avail disk.total disk.percent host ip node 6 10.2kb 41.6gb 4.3gb 45.9gb 90 127.0.0.1 127.0.0.1 ruan-node-1 6 10.2kb 41.6gb 4.3gb 45.9gb 90 127.0.0.1 127.0.0.1 ruan-node-2 分片数
- 索引所占空间
- 磁盘使用容量
- 磁盘可用容量
- 磁盘总容量
-
查看集群节点
$ curl http://127.0.0.1:9200/_cat/ ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 127.0.0.1 19 99 6 2.86 mdi * ruan-node-1 127.0.0.1 13 99 6 2.86 mdi - ruan-node-2 堆内存使用情况
- 内存使用情况
- cpu使用情况
ES对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。
其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);
小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。知识链接

若有收获,就点个赞吧
0 人点赞
