消息模式
消息系统中所使用的消息模式有两种
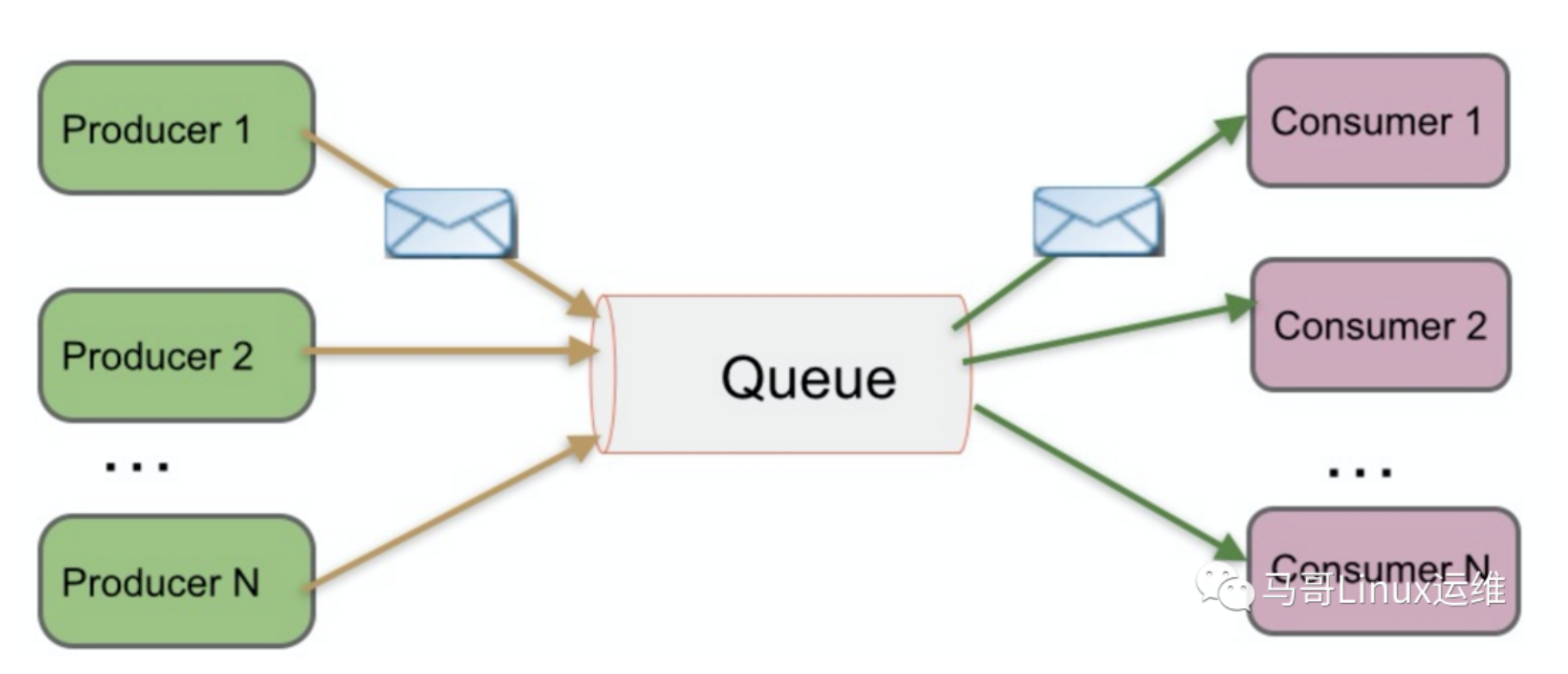
生产者生产消息到Queue,然后消费者从Queue中取出并且消费消息- 消息被消费后,Queue将不再存储消息,其他所有
消费者不可能消费到已经被其他消费者消费过的消息 - Queue支持存在多个
生产者,但是对一条消息而言,只会有一个消费者可以消费,其他的消费者则不能再次消费 但
消费者不存在时,消息则由Queue一直保存,直到有消费者把它消费Publish/Subscribe
发布/订阅模式

工作模式:生产者将消息发布到主题Topic中,同时有多个消息订阅者消费该消息- 和PTP方式不同,发布到Topic的消息会被所有
订阅者消费 - 当发布者发布消息,不管是否有订阅者,都不会报错消息
- 一定要现有
消息发布者,后有消息订阅者Kafka所采用的就是发布/订阅模式,被称为一种高吞吐量、持久性、分布式的发布订阅的消息队列系统
Kafka
- 高吞吐量:可以满足每秒百万级别消息的生产和消费
- 持久性:有一套完善的消息存储机制,确保数据高效安全且持久化。
分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
kafka概念
kafka作为一个集群运行在一个或多个服务器上,这些服务器可以跨多个机房,所以说kafka是分布式的发布订阅消息队列系统
- kafka集群将记录流存储在称为Topic的类别中
- 每条记录由键值
key/value和一个时间戳组成
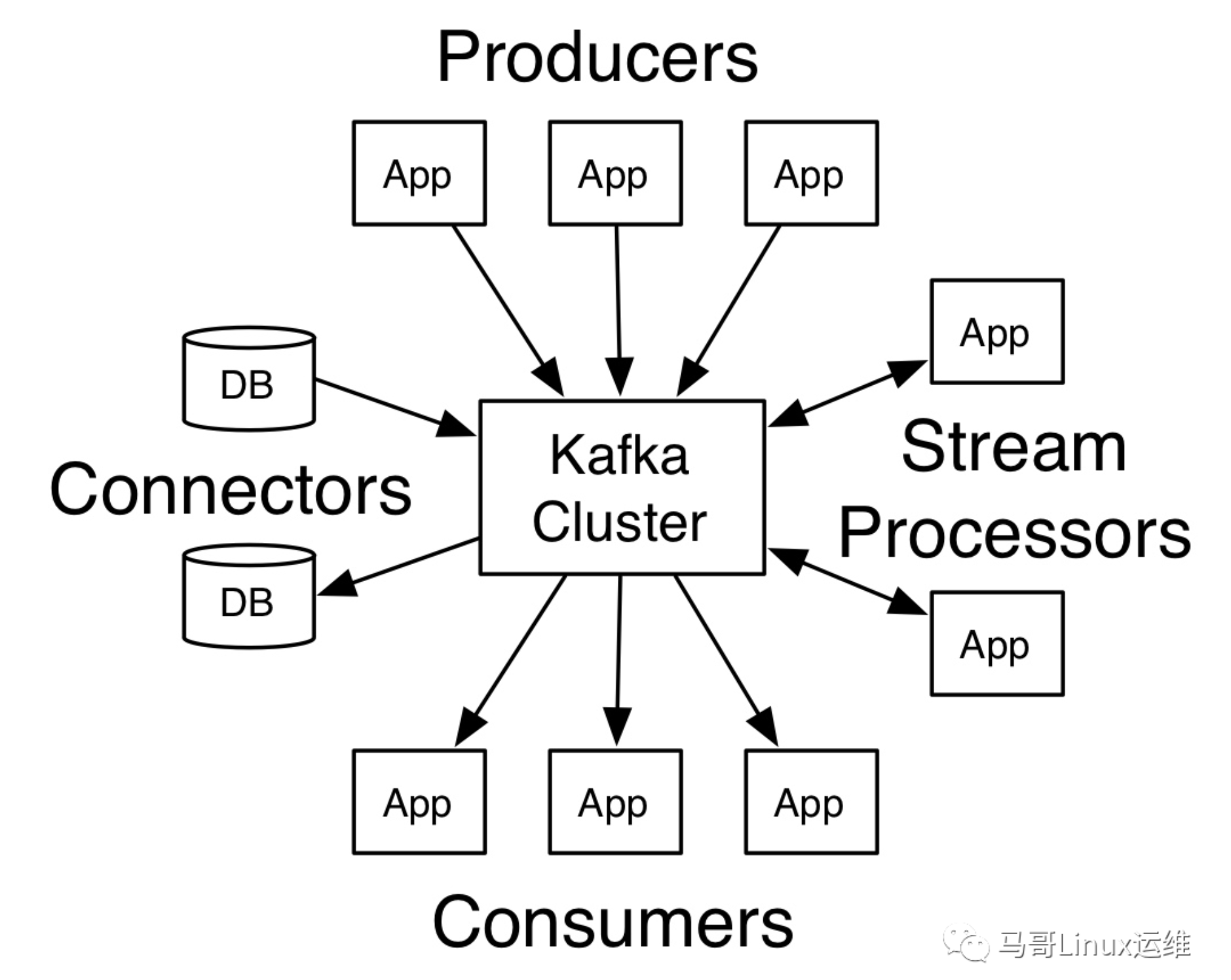
- Producer API: 生产者API允许应用程序将一组记录发布到一个或多个Kafka Topic中
- Consumer API:消费者API允许应用程序订阅一个或多个Topic,并处理向他们传输的记录流
- Streams API:流API允许应用程序充当流处理器,从一个或多个Topic中消费输入流,并将输出流生成一个或多个输出主题,从而将输入流有效地转换为输出流
- Connector API:连接器API允许构建和运行可重用地生产者或消费者,这些生产者或消费者将Kafka Topic连接到现有的应用程序或数据系统。例如:连接到关系型数据库的连接器可能会捕获对表的每次更改
在Kafka中,客户端和服务端之间的通信采用TCP协议完成,该协议经过版本控制,新版本和旧版本保存向后兼容性。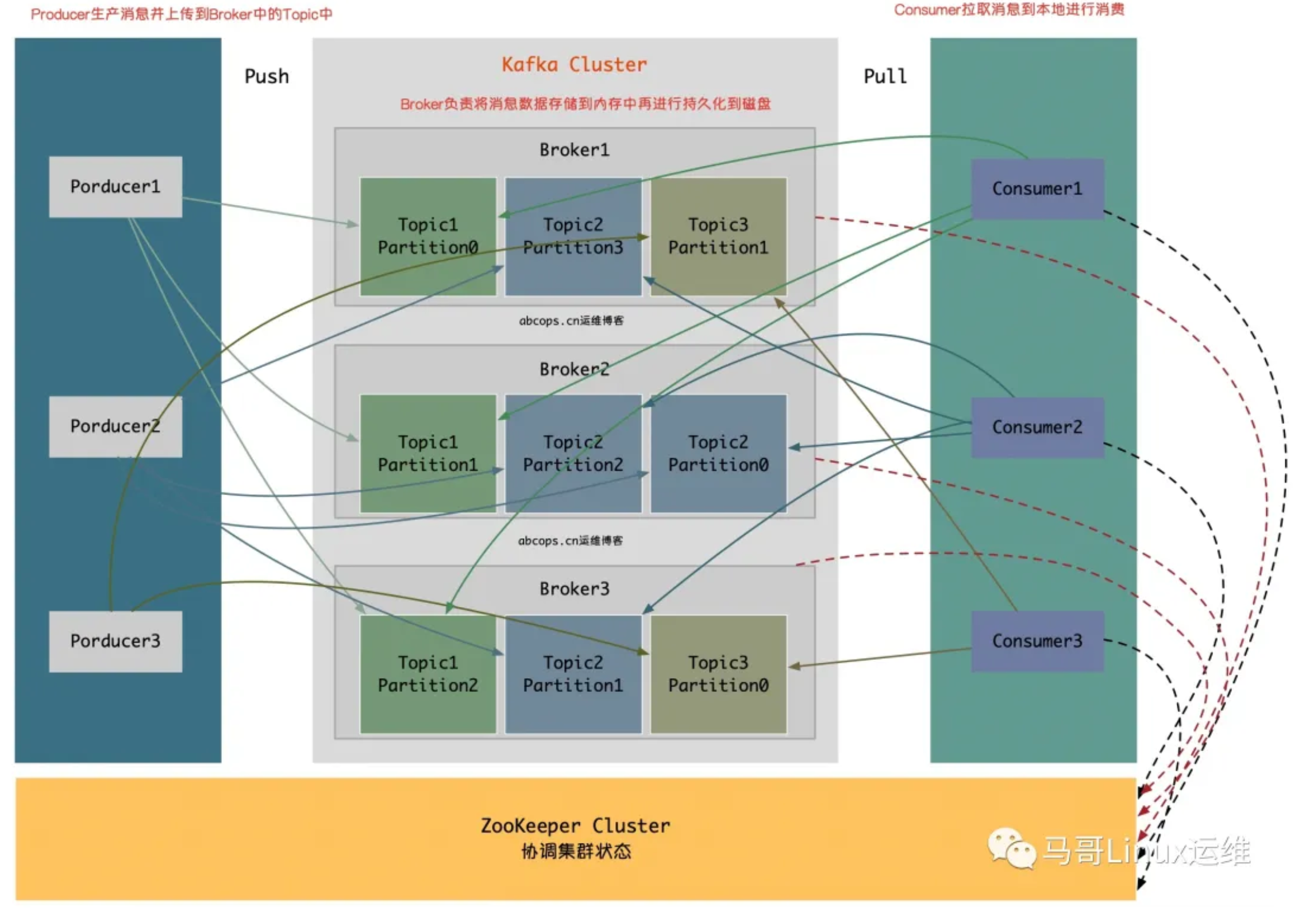
- Producer 消费和数据的生产者,主要负责生产
push消息到指定Broker的Topic中 - Broker Kafka节点就是被称为Broker,Broker主要负责创建Topic,存储Producer所发布的消息,记录消息处理的过程,现是将消息保存到内存中,然后持久化到磁盘。
- Topic 同一个Topic的消息可以分布在一个或多个Broker上,一个Topic包含一个或多个Partition分区,数据被存储在多个Partition中
- replication-factor:复制因子;这个名词在上图中从未出现,在我们下一章节创建Topic时会指定该选项,意思为创建当前的Topic是否需要副本,如果在创建Topic时将此值设置为1的话,代表整个Topic在Kafka中只有一份,该复制因子数量建议与Broker节点数量一致。
- Partition:分区;在这里被称为Topic物理上的分组,一个Topic在Broker中被分为1个或者多个Partition,也可以说为每个Topic包含一个或多个Partition,(一般为kafka节. 点数CPU的总核心数量)分区在创建Topic的时候可以指定。分区才是真正存储数据的单元。
- Consumer:消息和数据的消费者,主要负责主动到已订阅的Topic中拉取消息并消费,为什么Consumer不能像Producer一样的由Broker去push数据呢?因为Broker不知道Consumer能够消费多少,如果push消息数据量过多,会造成消息阻塞,而由Consumer去主动pull数据的话,Consumer可以根据自己的处理情况去pull消息数据,消费完多少消息再次去取。这样就不会造成Consumer本身已经拿到的数据成为阻塞状态。
ZooKeeper:ZooKeeper负责维护整个Kafka集群的状态,存储Kafka各个节点的信息及状态,实现Kafka集群的高可用,协调Kafka的工作内容。
主题和日志
主题和日志官方被称为是
Topic and log。Topic是记录发布到的类别或者订阅源的名称,Kafka的Topic总是多用户的;也就是说,一个Topic可以有零个、一个或者多个消费者订阅写入它的数据。每个Topic Kafka集群都为一个Partition分区日志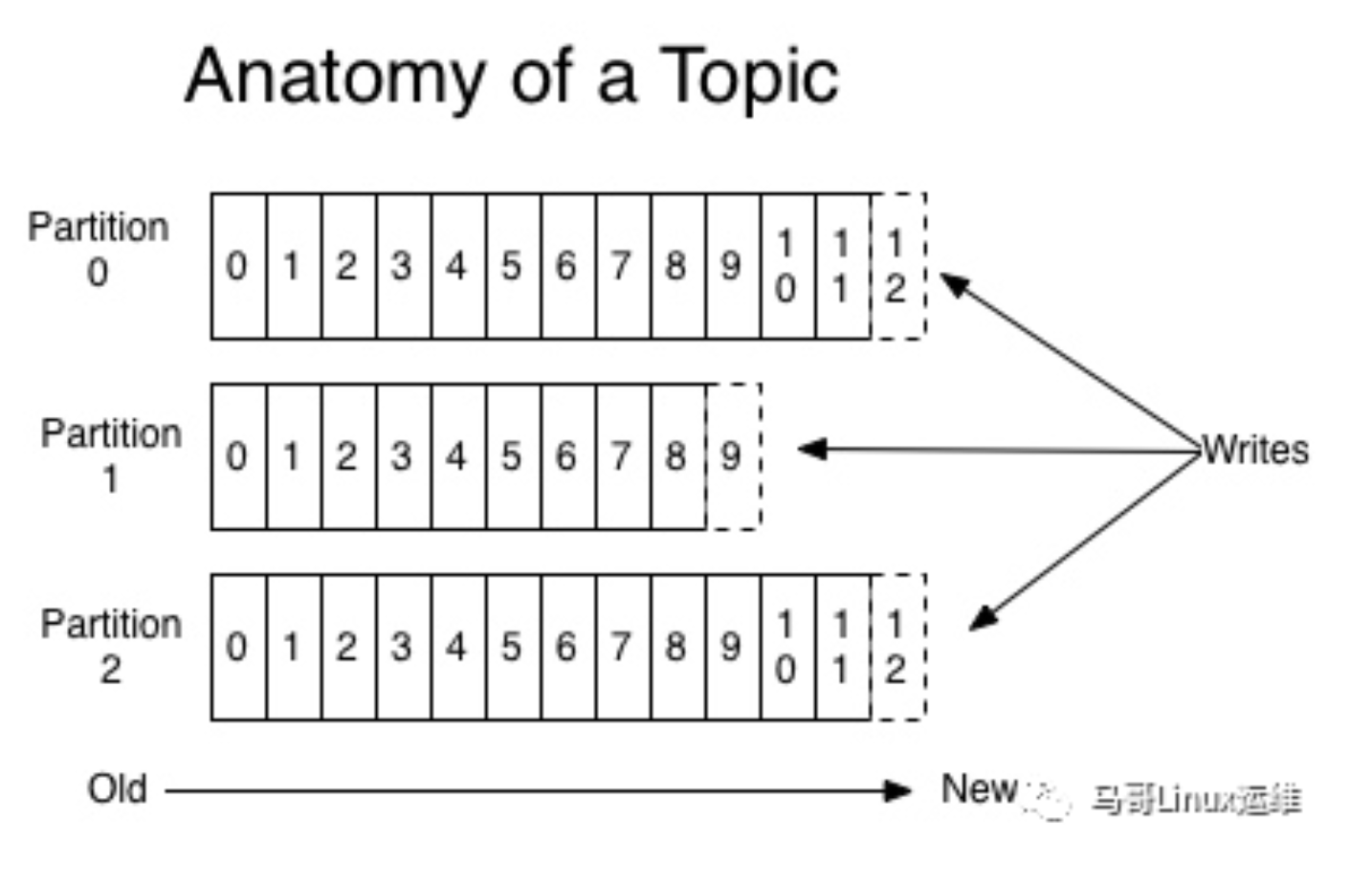
每个Partition分区都是一个有序的记录序列,如果有新的log会按顺序结构化添加到末尾,分区中的记录每个都按顺序的分配一个ID号,称之为偏移量,在整个Partition中具有唯一性。
Kafka集群发布过的消息记录会被持久化到硬盘中,无论消息是否被消费,发布记录都会被Kafka保留到硬盘中。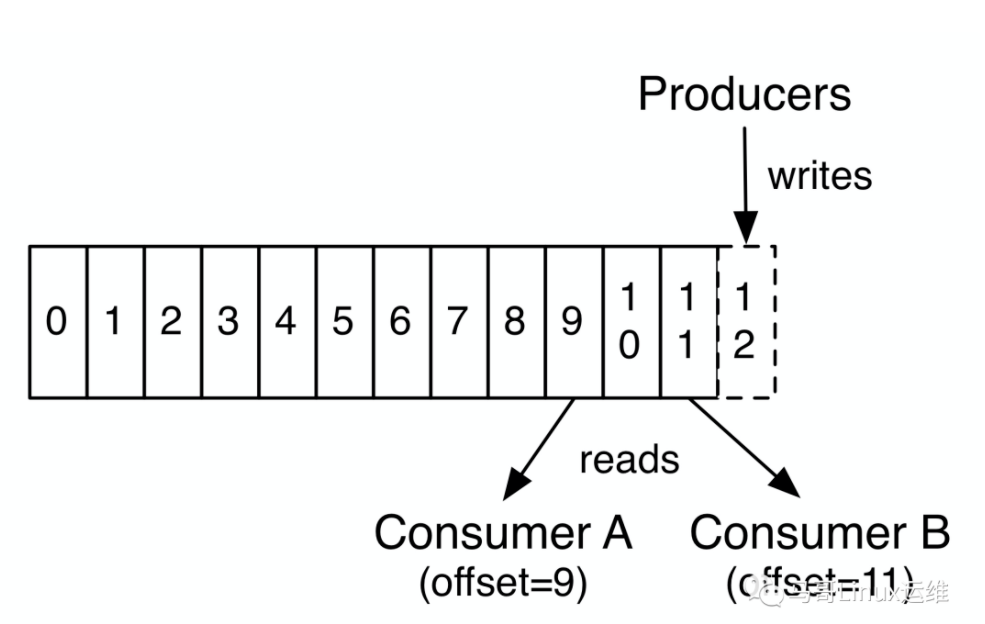
实际上,以消费者为单位地保留的唯一元数据是消费者在日志中的偏移或位置。这个偏移量由消费者控制的:消费者通常会在读取记录时线性地推进偏移量。
- 但事实上,由于消费者的位置是由消费者控制的,所以他可以按照自己喜欢的任何顺序进行消费记录
日志中分区有几个用途:
- 他们允许日志的大小超出适合单台服务器的大小,每个单独的分区必须适合托管它的服务器,但是一个主题可能有许多分区,因此它可以处理任意数量的数据
-
分布
日志Partition分区分布在Kafka集群中的服务器上,每台服务器都处理数据并请求共享分区。为了实现容错,每个Partition分区被复制到多个可配置的Kafka集群中的服务器上。
leader:领导者
- followers:追随者
每个Partition分区都有一个leader(领导者)服务器,是每个Partition分区。其中Partition分片的leader处理该Partition分区的所有读和写请求,而follower被动地复制leader所发生的的改变,如果该Partition分片的领导者发生了故障等,两个follower中的其中一台服务器将自动成为新的leader。每台服务器都充当一些分区的leader和一些分区的follower,因此集群内的负载非常平衡
地域复制
Kafka mirrormaker为集群提供地域复制支持,使用MirrorMaker,可以跨多个机房或云端来复制数据,可以在主动/被动方案中使用它进行备份或回复;在主动方案中,可以使数据更接近用户,或支持数据位置要求
生产者
生产者将数据发布到他们选择的Topic,生产者负责选择分配给Topic中的哪个分区的记录。这可以通过循环方式来完成,只是为了负载均衡,或者可以根据一些语义分区函数来完成
消费者
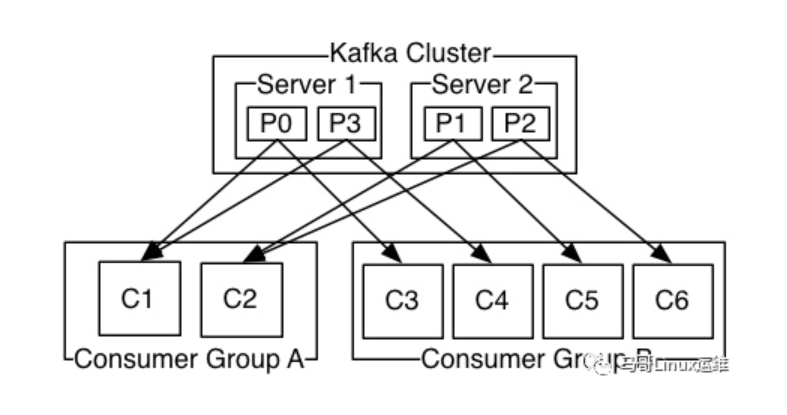
Consumer通过Consumers Group name标记自己,并且发布到Topic的每个记录被传递到每个订阅Consumers Group中的一个Consumers实例,Consumers实例可以在单独的进程中,也可以在不同的机器,如果所有Consumers实例具有相同的Consumers Group,则记录将有效地在Consumers上进行负载均衡。
如果所有Consumers实例在不同的Consumers Group中,则每个记录都将广播到所有Consumers进程中。
Kafka仅提供分区内记录的总顺序,而不是Topic中不同分区之间的记录。对于大多数应用程序而言,按分区排序和按键分许数据的能力已经足够,但是如果你需要记录总顺序,则可以使用只有一个分区的Topic来实现,尽管这意味着每个消费者组只有一个消费者进程。
Consmuer Group
我们开始处有讲到消息系统分类:P-T-P模式和发布/订阅模式,也有说到我们的Kafka采用的就是发布订阅模式,即一个消息产生者产生消息到Topic中,所有的消费者都可以消费到该条消息,采用异步模型;而P-T-P则是一个消息生产者生产的消息发不到Queue中,只能被一个消息消费者所消费,采用同步模型 其实发布订阅模式也可以实现P-T-P的模式,即将多个消费者加入一个消费者组中,例如有三个消费者组,每个组中有3个消息消费者实例,也就是共有9个消费者实例,如果当Topic中有消息要接收的时候,三个消费者组都会去接收消息,但是每个人都接收一条消息,然后消费者组再将这条消息发送给本组内的一个消费者实例,而不是所有消费者实例,到最后也就是只有三个消费者实例得到了这条消息,当然我们也可以将这些消费者只加入一个消费者组,这样就只有一个消费者能够获得到消息了。
Guarantees
在高级别的Kafka中提供了以下保证:

若有收获,就点个赞吧
0 人点赞
