数据和链表时间复杂度比较:
| 操作类型 | 数组 | 链表 |
|---|---|---|
| 头添加 |  |
 |
| 尾添加 |  |
 |
| 随机访问(查找) |  |
 |
| 插入 |  |
 |
| 删除 |  |
 |
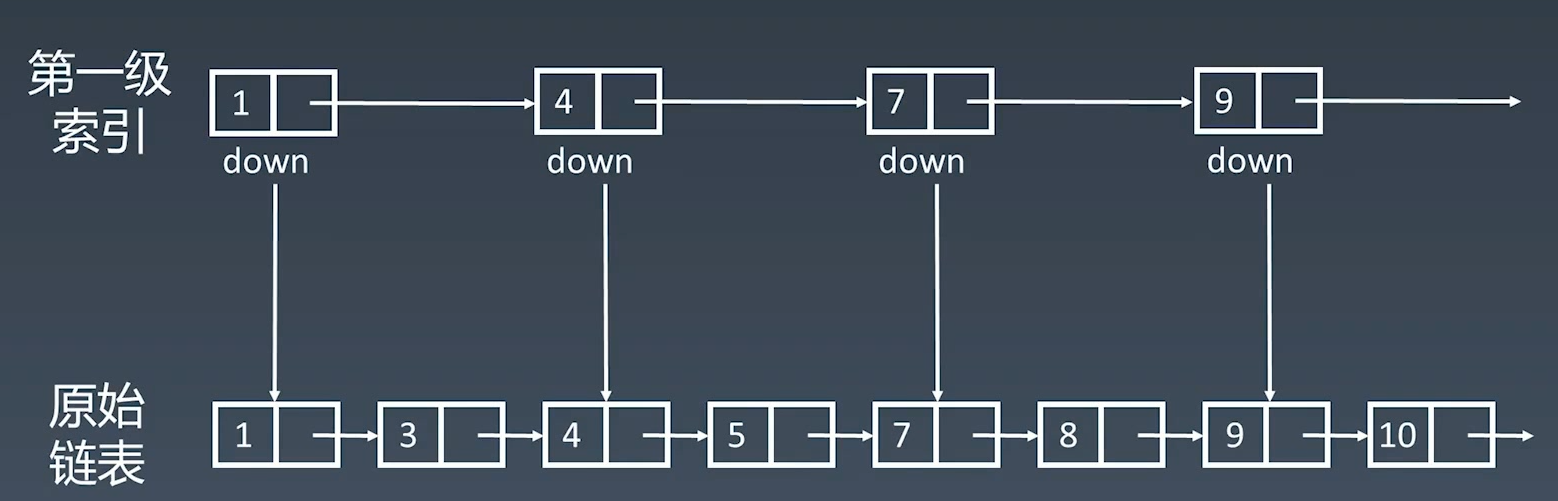
跳表
跳表是补足链表的缺陷而设计出来的。链表的缺陷是查找(lookup)的时间复杂度为  ,究其原因它是一个简单的一维线性结构:
,究其原因它是一个简单的一维线性结构:
优化中心思想:
- 升维
- 空间换时间


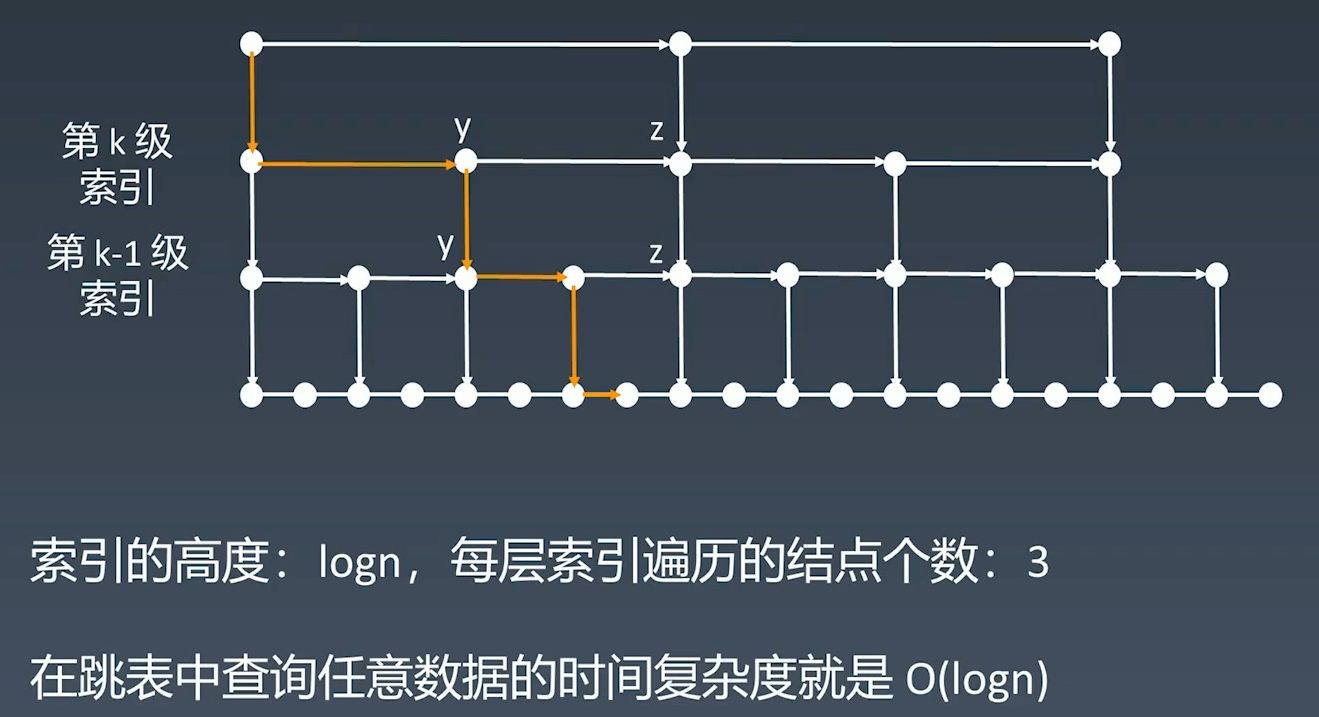
跳表的时间复杂度
原始链表存在  个元素,第一级索引结点个数是
个元素,第一级索引结点个数是  ,第二级索引结点个数是
,第二级索引结点个数是  ,第 k 级索引节点个数是
,第 k 级索引节点个数是  。假设索引有
。假设索引有  级,最高级的索引有
级,最高级的索引有  个结点。求得
个结点。求得 

工程应用
LRU缓存算法
从本质上来说,缓存之所以有效是因为程序和数据的局部性原理(locality)。
理想的 LRU 算法应该可以在  的时间内读取一条数据或更新一条数据。基于 HashMap 不能实现,因为它没有排序功能,所以在确定最少使用的 item 时需要遍历所有元素。
的时间内读取一条数据或更新一条数据。基于 HashMap 不能实现,因为它没有排序功能,所以在确定最少使用的 item 时需要遍历所有元素。
我们需要一种既能按访问时间排序,又能在常数时间内随机访问的数据结构。这可以通过 HashMap + 双向链表来实现。HashMap 保存在  时间内确定 item,双向链表则按照访问时间顺序对所有 item 进行排序。
时间内确定 item,双向链表则按照访问时间顺序对所有 item 进行排序。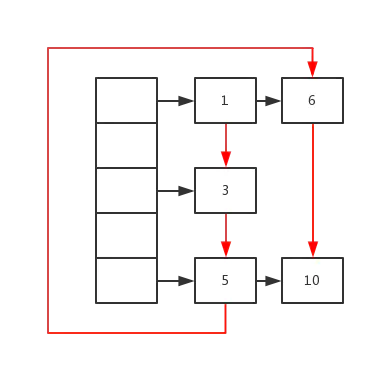
如果单纯比较性能,跳跃表和红黑树可以说相差不大,但是加上并发的环境就不一样了,如果要更新数据,跳跃表需要更新的部分就比较少,锁的东西也就比较少,所以不同线程争锁的代价就相对少了,而红黑树有个平衡的过程,牵涉到大量的节点,争锁的代价也就相对较高了。性能也就不如前者了。

若有收获,就点个赞吧
0 人点赞
