https://zhuanlan.zhihu.com/p/114921777
坑与注意事项
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面
数据库认识
5种类型数据库:
层次数据库,关系数据库,面向对象数据库,xml数据库,键值存储数据库。
mysql是关系数据库。即RDBMS。
数据库表结构,行称为记录,列称为字段。交汇处称为单元格。
sql语句分为三类:
- ddl:data definition language,数据定义语言。用于创建或删除数据库,数据表等对象。
- create:创建数据库和表等对象
- drop:删除库和表
- alter:修改库和表(列操作)
- dml:data manipulation language,数据操纵语言,查询或变更记录(行)。(重点)
- select:查询
- insert:插入
- update:更新
- delete:删除
- dcl:data control language,数据控制语言。确认或取消对数据的变更,设定对象的操作权限。
- commit:确认变更
- rollback:取消变更
- grant:赋予权限
- revoke:取消权限。
sql语句书写规范:
- 分号结尾
- 关键字不区分大小写,数据区分大小写;表名和字段根据操作系统不同,win不区分大小写,linux和mac区分。统一用小写。
- 常数写法固定:日期,字符串用引号,数值直接写
- 单词用半角或空行间隔
- 常见注意事项如下:
- MySQL 本身不区分大小写,但强烈要求关键字大写,表名、列名用小写;
- 创建表时,使用统一的、描述性强的字段命名规则保证字段名是独一无二且不是保留字的,不要使 用连续的下划线,不用下划线结尾;最好以字母开头;
- 关键字右对齐,且不同层级的用空格或缩进控制,使其区分开,见样例二;
- 列名少的时候写在一行里无伤大雅;多的时候以及涉及到 CASE WHEN 或者聚合计算的时候,建 议分行写;个人习惯是逗号在列名前面,方便之后删除某些列,放列名后亦可;
- 表别名和列别名尽量用有具体含义的词组,不要用 a b c,不然以后 review 的时候会非常痛苦;
- 运算符前后都加一个空格;
- 当用到多个表时,请在所有列名前写上引用的表别名,不要嫌麻烦;
- 每条命令用分号结尾;
- 养成随手写注释的习惯,注释方法: • 单行注释 # 注释文字 • 单行注释 – 注释文字 • 多行注释: / 注释文字 /
语句与语法
数据库层面
-- 创建数据库CREATE DATABASE < 数据库名称 > ;create database shop;-- 插入表数据CREATE TABLE < 表名 >( < 列名 1> < 数据类型 > < 该列所需约束 > ,< 列名 2> < 数据类型 > < 该列所需约束 > ,< 列名 3> < 数据类型 > < 该列所需约束 > ,< 列名 4> < 数据类型 > < 该列所需约束 > ,...< 该表的约束 1> , < 该表的约束 2> ,……);CREATE TABLE product(product_id CHAR(4) NOT NULL,product_name VARCHAR(100) NOT NULL,product_type VARCHAR(32) NOT NULL,sale_price INTEGER ,purchase_price INTEGER ,regist_date DATE ,PRIMARY KEY (product_id));-- 删除表:无法恢复,只能重新插入DROP TABLE < 表名 > ;DROP TABLE product;-- 添加列ALTER TABLE < 表名 > ADD COLUMN < 列的定义 >;ALTER TABLE product ADD COLUMN product_name_pinyin VARCHAR(100);-- 删除列,无法恢复ALTER TABLE < 表名 > DROP COLUMN < 列名 >;ALTER TABLE product DROP COLUMN product_name_pinyin;-- 清空表:比drop和delete快TRUNCATE TABLE TABLE_NAME;-- 更新记录UPDATE <表名>SET <列名> = <表达式> [, <列名2>=<表达式2>...];WHERE <条件>; -- 可选,非常重要。ORDER BY 子句; --可选LIMIT 子句; --可选-- 修改所有的注册时间,set后可多写UPDATE productSET regist_date = '2009-10-10';-- 仅修改部分商品的单价UPDATE productSET sale_price = sale_price * 10WHERE product_type = '厨房用具';UPDATE productSET regist_date = NULLWHERE product_id = '0008';-- 合并后的写法UPDATE productSET sale_price = sale_price * 10,purchase_price = purchase_price / 2WHERE product_type = '厨房用具';-- 插入一行INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);-- 包含列清单INSERT INTO productins (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');-- 省略列清单INSERT INTO productins VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');-- 查询SELECT <列名>, ……FROM <表名>WHERE <条件表达式>;-- 聚合查询-- 计算全部数据的行数(包含NULL)SELECT COUNT(*)FROM product;-- 计算NULL以外数据的行数SELECT COUNT(purchase_price)FROM product;-- 计算销售单价和进货单价的合计值SELECT SUM(sale_price), SUM(purchase_price)FROM product;-- 计算销售单价和进货单价的平均值SELECT AVG(sale_price), AVG(purchase_price)FROM product;-- MAX和MIN也可用于非数值型数据SELECT MAX(regist_date), MIN(regist_date)FROM product;-- 计算去除重复数据后的数据行数SELECT COUNT(DISTINCT product_type)FROM product;-- 是否使用DISTINCT时的动作差异(SUM函数)SELECT SUM(sale_price), SUM(DISTINCT sale_price)FROM product;-- 表分组SELECT <列名1>,<列名2>, <列名3>, ……FROM <表名>GROUP BY <列名1>, <列名2>, <列名3>, ……;-- 按照商品种类统计数据行数SELECT product_type, COUNT(*)FROM productGROUP BY product_type;-- 不含GROUP BYSELECT product_type, COUNT(*)FROM product-- 分组与限定-- 数字SELECT product_type, COUNT(*)FROM productGROUP BY product_typeHAVING COUNT(*) = 2;-- 错误形式(因为product_name不包含在GROUP BY聚合键中)SELECT product_type, COUNT(*)FROM productGROUP BY product_typeHAVING product_name = '圆珠笔';-- 视图:保存select语句的结果CREATE VIEW <视图名称>(<列名1>,<列名2>,...) AS <SELECT语句>CREATE VIEW view_shop_product(product_type, sale_price, shop_name)ASSELECT product_type, sale_price, shop_nameFROM product,shop_productWHERE product.product_id = shop_product.product_id;-- 修改视图ALTER VIEW <视图名> AS <SELECT语句>ALTER VIEW productSumASSELECT product_type, sale_priceFROM ProductWHERE regist_date > '2009-09-11';DROP VIEW <视图名1> [ , <视图名2> …]DROP VIEW productSum;
数据类型
integer:整数
char:长字符串
varchar:可变长字符串
date:年月日
float
类型转换(todo)
约束
not null :非空
primary key:主键
default xx:默认值
查询
- select
- select :全部列,增加的自定义列放前面,后面可再加
- select distinct row_name:删除重复数据
- 可使用别名自定义列名
- where:限定行/记录的条件
- having:限定列的条件,用在group by后
分组group by:
- null会单独作为一组特殊数据
- 是对筛选后数据处理,写在select…from…where之后
- group by 中不能使用别名,因为执行顺序在select前
- 使用了group by后select 只能是聚合的列
- 计算分类的合计:group by xx with rollup
SELECT product_type,regist_date,SUM(sale_price) AS sum_priceFROM productGROUP BY product_type, regist_date WITH ROLLUP
order by:对查询结果排序
- order by xx asc/desc
- 结果含有null,会放在开头或结尾
- 子句可以使用别名,因为执行顺序在select后
- 视图:可复用,被处理过的select语句的结果
- 虚拟表
- 可被更新,含有下列情况不可被更新:
- 聚合函数 SUM()、MIN()、MAX()、COUNT() 等。
- DISTINCT 关键字。
- GROUP BY 子句。
- HAVING 子句。
- UNION 或 UNION ALL 运算符。
- FROM 子句中包含多个表。
- 视图与原表的关系
- 原表数据更新,视图中相关数据也会被更新。反之亦然
- 视图是原表的一个窗口,用于看到部分原表数据或对原表进行处理。
- 子查询
- from子句是另一个select语句,
from ( xxxx) as xx - 一次性,保存下来就是视图
- 子句是标亮单一值(使用了聚合函数)也可以用在:where,group by,having,order by子句。
- 关联子查询:主查询与子查询通过标志连结(比如where条件),一般会给表设置别名。
- from子句是另一个select语句,
函数(常用30-50)
算数函数
- abs(数值):绝对值
- mod(被除数,除数):取余数
round(对象数值,保留小数的位数):四舍五入。保留小数的位数可为参数,注意可能出错。
字符串函数
concat(str1,str2, str3):拼接
- length(str):长度
- lower(str):转小写
- upper(str):转大写
- replace(src, str_before, str_after):替换
substring(对象字符串 FROM 截取的起始位置 FOR 截取的字符数 ):截取字符串。索引值起始为1
日期函数
current_date():当前年月日
- current_time():当前时间:时分秒
- current_timestamp():当前时间,年月日时分秒
extract(日期元素 FROM 日期):截取日期元素
cats(转化前值 as 想要转化的数据类型) 类型转换
- 数据类型:singed integer,date。。。
coalesce(data1, data2, data3…):将null值转化为其他值
count(),avg(),max(),min()
- count(*)包括null,其它情况聚合函数都会排除null,参数是具体列名
- max/min适用于几乎所有,sum/avg适用于数值类
- distinct排除重复值,可用于参数中
谓词
返回真值的函数
- 真值:true,false,unkonwn
- 谓词:
- like:字符串匹配
- like ‘dd%’:0+,匹配开头
- like ‘dd%dd’:匹配中间
- like ‘%dd’:匹配结尾
- 符号:%匹配0+个任意字符,_匹配1+各任意字符
- between:范围查询
- 范围查询,需要2个参数,包含两个临界值
- between 100 and 1000:[100, 1000]
- is null,is not null
- null不能用=判断,要用is null 或is not null
- in: 简写的or
- 简写的or,in(10,50, 100):是三者之一即可
- 有in 也有not in
- 不管是in 还是not in,结果都不包括null
- 支持子查询,in(select 子句):更灵活
- exists
- 可以用in/not in替代
- 判断是否存在满足某种条件的记录:返回true/false
- 参数通常是个子查询:exist(select 子句)
- 有exist也有not exist
- like:字符串匹配
case 表达式
分为简单表达式与搜索表达式。后者包含前者,可只学习后者。
依次判断when是否为真,是执行then后语句,都不满足,执行else后表达式。end不要省略。
else 不写则默认else null。
CASE WHEN <求值表达式> THEN <表达式>WHEN <求值表达式> THEN <表达式>WHEN <求值表达式> THEN <表达式>...ELSE <表达式>ENDSELECT product_name,CASE WHEN product_type = '衣服' THEN CONCAT('A : ',product_type)WHEN product_type = '办公用品' THEN CONCAT('B : ',product_type)WHEN product_type = '厨房用具' THEN CONCAT('C : ',product_type)ELSE NULLEND AS abc_product_typeFROM product;-- 实现行转列-- 对按照商品种类计算出的销售单价合计值进行行列转换SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes,SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen,SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_officeFROM product;+-------------------+-------------------+------------------+| sum_price_clothes | sum_price_kitchen | sum_price_office |+-------------------+-------------------+------------------+| 5000 | 11180 | 600 |+-------------------+-------------------+------------------+1 row in set (0.00 sec)-- CASE WHEN 实现数字列 score 行转列SELECT name,SUM(CASE WHEN subject = '语文' THEN score ELSE null END) as chinese,SUM(CASE WHEN subject = '数学' THEN score ELSE null END) as math,SUM(CASE WHEN subject = '外语' THEN score ELSE null END) as englishFROM scoreGROUP BY name;+------+---------+------+---------+| name | chinese | math | english |+------+---------+------+---------+| 张三 | 93 | 88 | 91 || 李四 | 87 | 90 | 77 |+------+---------+------+---------+-- CASE WHEN 实现文本列 subject 行转列SELECT name,MAX(CASE WHEN subject = '语文' THEN subject ELSE null END) as chinese,MAX(CASE WHEN subject = '数学' THEN subject ELSE null END) as math,MIN(CASE WHEN subject = '外语' THEN subject ELSE null END) as englishFROM scoreGROUP BY name;+------+---------+------+---------+| name | chinese | math | english |+------+---------+------+---------+| 张三 | 语文 | 数学 | 外语 || 李四 | 语文 | 数学 | 外语 |+------+---------+------+---------+
关键词的书写顺序和执行顺序
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY。
语法顺序:
select [distinct]
from
join on
where
group by
having
union
order by
执行顺序:
from
join on
where
group by
having
select
distinct
union
order by
运算符
算数:+, -, *, /(取小数)
比较:=, <>, >=, <=, >, <
逻辑:not 否定, WHERE NOT sale_price >= 1000; and, or
and优先于or,可以用括号提高优先级。
由于存在null(不确定值),因此真值表为三值逻辑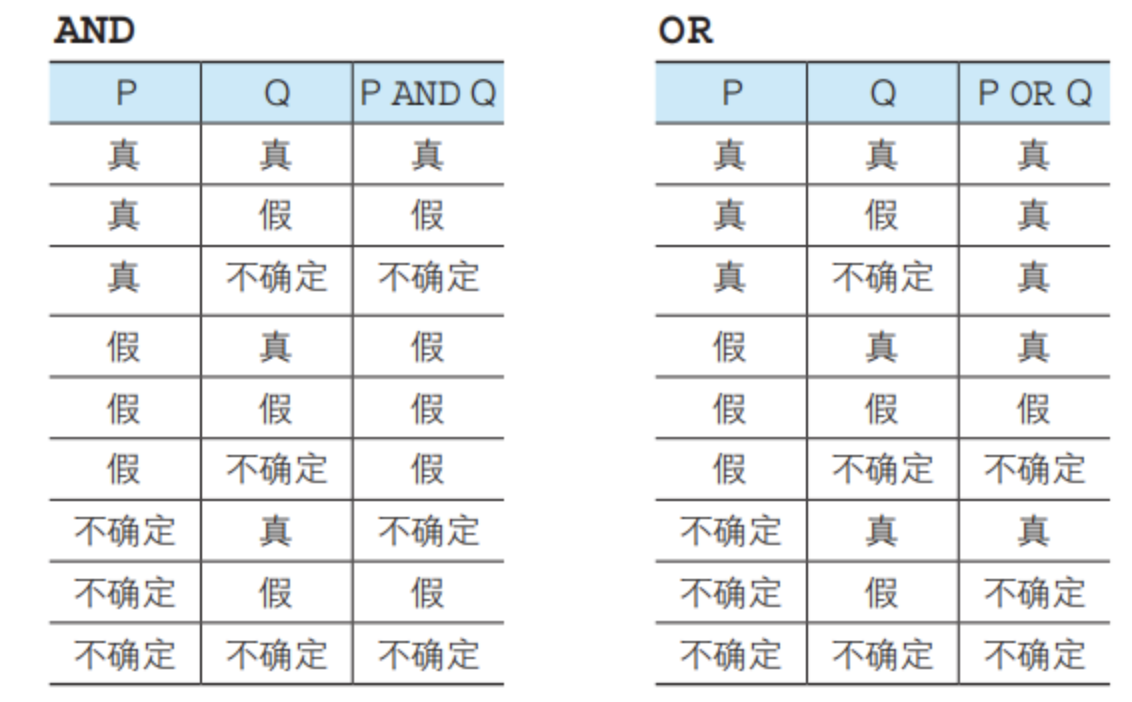
注意:
4种结果为null的情况:
ture and null = null
false or null = null
null and null = null
null or null = null
2种与null操作有结果的情况:
ture or null = true/1
false and null = false/0
与null的比较:结果都为null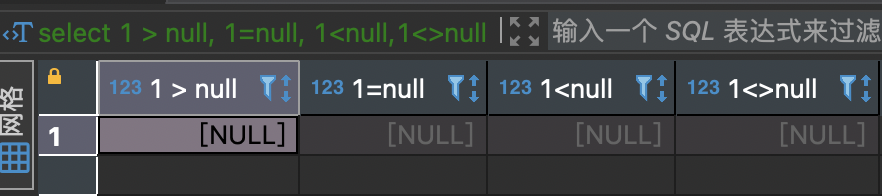
集合运算
并集:union,行合并,可以用or替代
合并会去重,如果要保留重复行,用union all 替代union
SELECT product_id,product_name,product_type,sale_price,purchase_priceFROM PRODUCTWHERE sale_price<800UNIONSELECT product_id,product_name,product_type,sale_price,purchase_priceFROM PRODUCTWHERE sale_price>1.5*purchase_price;
差集/交集:not in
对称差:并集-交集:
-- 使用 NOT IN 实现两个表的差集SELECT *FROM ProductWHERE product_id NOT IN (SELECT product_id FROM Product2)UNIONSELECT *FROM Product2WHERE product_id NOT IN (SELECT product_id FROM Product)
连结:增加列,xx join
- 多表信息获取,将结果显示在一个表
- 连结一般会对两个表取别名,在on里用别名.列名的形式引用,同时在select里也可以用到别名。
- 连结后的内容,根据select的顺序。
- on是连结的条件。
- 后面还可以增加where子句,进一步对连结后结果进行筛选。
- 关于on和where,可以分开,也可以现在各自的子句里where筛选后再连结。
- 亦可增加group by分组,在on之后。
- 子连结可用子查询实现。
- inner join换成natural join,则会根据两个表都包含的列名进行连结。
- 可使用连结实现交集:在on里限定条件
- 内连结:保留共同的,左/右连结:调换表顺序,实际一致。一定会输出主表全部。全外连结,输出两表所有。不能被关联的用null补足。
```sql
— 内连结
FROM
INNER JOIN ON
FROMLEFT OUTER JOIN ON
FROMRIGHT OUTER JOIN ON FULL OUTER JOIN ON
SELECT SP.shop_id ,SP.shop_name ,SP.product_id ,P.product_name ,P.product_type ,P.sale_price ,SP.quantity FROM ShopProduct AS SP INNER JOIN Product AS P ON SP.product_id = P.product_id;
SELECT SP.shop_id ,SP.shop_name ,MAX(P.sale_price) AS max_price FROMshopproduct AS SP INNER JOINproduct AS P ON SP.product_id = P.product_id GROUP BY SP.shop_id,SP.shop_name
<a name="opJ5h"></a>## 窗口函数有选择地对部分数据进行汇总,计算和排序。- partition by:用于分组,语义类似group by,可省略- order by:排序- 窗口函数- 聚合函数:逐行累计- sum()- max()- min()- 累计还可以限制累计行的范围:- rows n preceding:之前的n行+自身行- rows between n1 preceding and n2 following:之前n1行+自身行+之后n2行- rows n following:自身行+之后n行- 专用排序- rank():相同位次,跳过之后位次。1,1,1,4- dense_rank():相同位次并列不跳过。1,1,1,2- row_number():唯一连续位次。1,2,3,4```sql<窗口函数> OVER ([PARTITION BY <列名>]ORDER BY <排序用列名>)SELECT product_name,product_type,sale_price,RANK() OVER (PARTITION BY product_typeORDER BY sale_price) AS rankingFROM productSELECT product_name,product_type,sale_price,RANK() OVER (ORDER BY sale_price) AS ranking,DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking,ROW_NUMBER() OVER (ORDER BY sale_price) AS row_numFROM productSELECT product_id,product_name,sale_price,SUM(sale_price) OVER (ORDER BY product_id) AS current_sum,AVG(sale_price) OVER (ORDER BY product_id) AS current_avgFROM product;SELECT product_id,product_name,sale_price,AVG(sale_price) OVER (ORDER BY product_idROWS 2 PRECEDING) AS moving_avg,AVG(sale_price) OVER (ORDER BY product_idROWS BETWEEN 1 PRECEDINGAND 1 FOLLOWING) AS moving_avgFROM product
关键字
as:列和表的别名,用于自定义查询显示的列名或者多表查询时,为了方便给表起别名。
if exist
数据库,excel,python处理的比较

若有收获,就点个赞吧
0 人点赞
