学习方式
1.环境搭建
在终端登陆(不设置环境变量):/usr/local/mysql/bin/mysql -u root -p
password:17351735
在终端输入mysql,提示找不到命令,设置环境变量。
PATH=”$PATH”:/usr/local/mysql/bin
export PATH=$PATH:/usr/local/mysql/bin
source ~/.bash_profile
mysql -u root -p
之后输入密码:17351735,以后就可以通过 mysql -u root -p在终端登陆。
客户端登陆:
datatrip(付费)
dbeaver(免费)
2.认识数据库
数据库管理系统:Database Management System,DBMS
2.1DBMS类型
有本叫做《七周七数据库》的书,每周介绍1种数据库类型,总共介绍了5种类型,7个数据库。
2.1.1层次数据库(Hierarchical Database,HDB)
2.1.2关系数据库(Relational Database,RDB)
- Oracle Database:甲骨文公司的RDBMS
- SQL Server:微软公司的RDBMS
- DB2:IBM公司的RDBMS
- PostgreSQL:开源的RDBMS
- MySQL:开源的RDBMS
如上是5种具有代表性的RDBMS,其特点是由行和列组成的二维表来管理数据,这种类型的 DBMS 称为关系数据库管理系统(Relational Database Management System,RDBMS)。
2.1.3面向对象数据库(Object Oriented Database,OODB)
2.1.4XML数据库(XML Database,XMLDB)
2.1.5键值存储系统(Key-Value Store,KVS)
举例:MongoDB
这个笔记仅讲述关系数据库,即RDBMS,重点讲mysql。
RDBMS常见系统结构为c/s类型。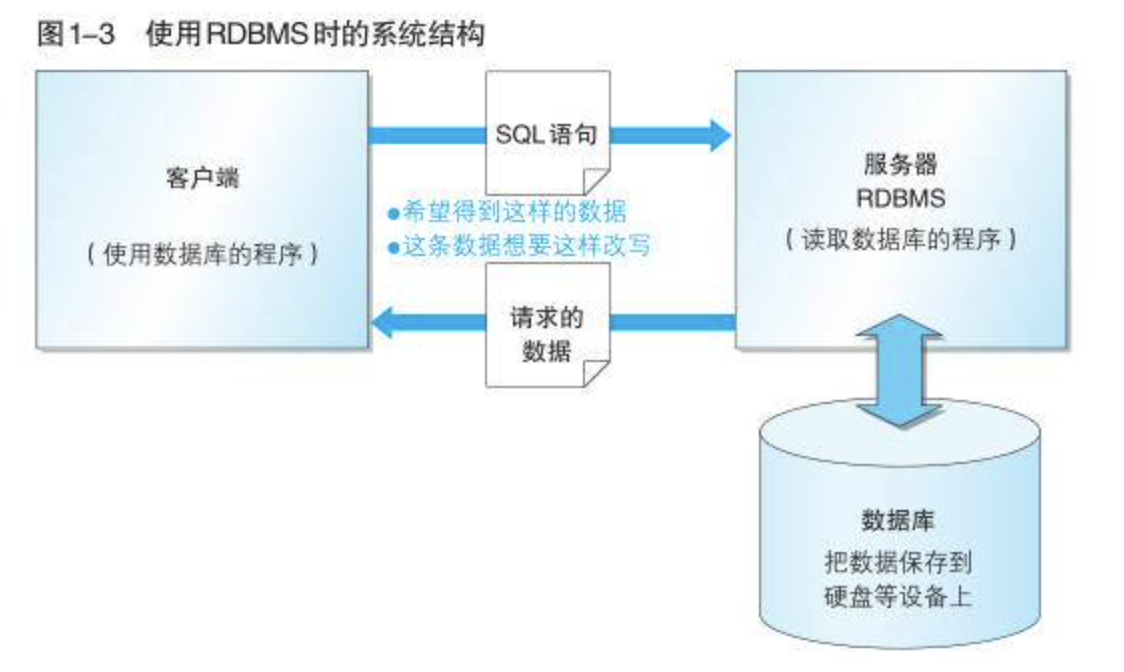
数据库按照记录的形式存储数据。
用excel做类比:
一条记录相当于excel里的一行。
一个列相当于一个字段。
行和列交汇的地方,称之为单元格。
表头,也就是列名。
2.2SQL语句的3大类
2.2.1DDL:数据定义语言
DDL(Data Definition Language,数据定义语言) 用来创建或者删除存储数据用的数据库以及数据库中的表等对象。DDL 包含以下几种指令。
- CREATE : 创建数据库和表等对象
- DROP : 删除数据库和表等对象
-
2.2.2DML:数据操纵语言
DML(Data Manipulation Language,数据操纵语言) 用来查询或者变更表中的记录。DML 包含以下几种指令。
SELECT :查询表中的数据
- INSERT :向表中插入新数据
- UPDATE :更新表中的数据
- DELETE :删除表中的数据
2.2.3DCL:数据控制语言
DCL(Data Control Language,数据控制语言) 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。DCL 包含以下几种指令。
- COMMIT : 确认对数据库中的数据进行的变更
- ROLLBACK : 取消对数据库中的数据进行的变更
- GRANT : 赋予用户操作权限
- REVOKE : 取消用户的操作权限
2.3SQL书写规范
- SQL语句要以分号( ; )结尾
- SQL 不区分关键字的大小写,但是插入到表中的数据是区分大小写的
- win 系统默认不区分表名及字段名的大小写
- linux / mac 默认严格区分表名及字段名的大小写 * 本教程已统一调整表名及字段名的为小写,以方便初学者学习使用。
- 常数的书写方式是固定的
‘abc’, 1234, ‘26 Jan 2010’, ‘10/01/26’, ‘2010-01-26’……
- 单词需要用半角空格或者换行来分隔
- 只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称
- 名称必须以半角英文字母开头
- 注释:—
SQL 语句的单词之间需使用半角空格或换行符来进行分隔,且不能使用全角空格作为单词的分隔符,否则会发生错误,出现无法预期的结果。
请大家认真查阅《附录1 - SQL 语法规范》,养成规范的书写习惯。
2.4操作与语句
创建数据库
CREATE DATABASE < 数据库名称 > ;CREATE DATABASE shop;
创建数据表
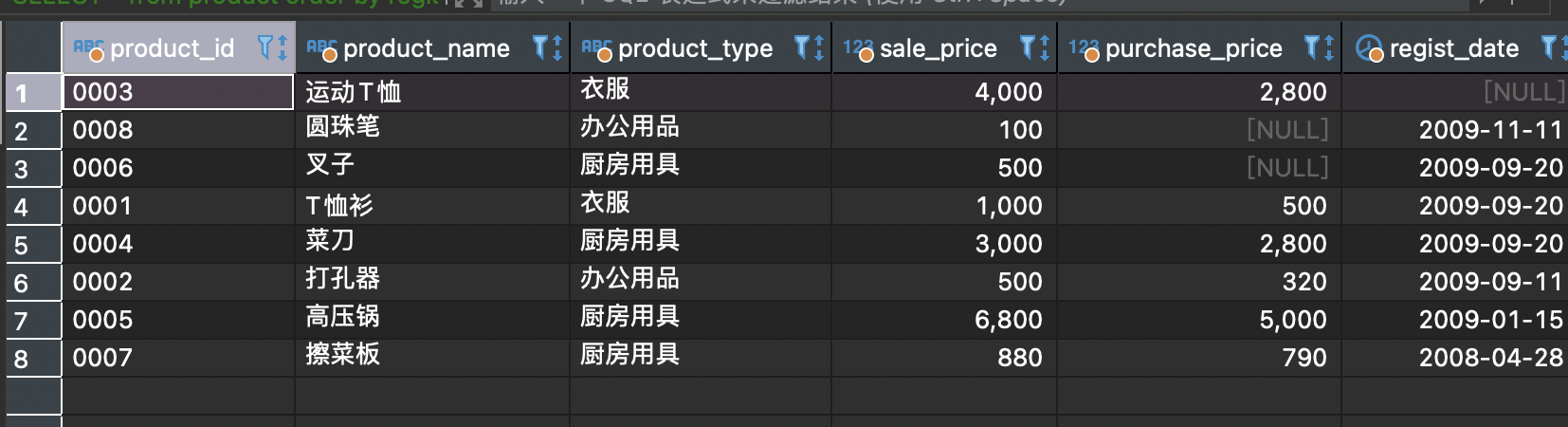
CREATE TABLE < 表名 >( < 列名 1> < 数据类型 > < 该列所需约束 > ,< 列名 2> < 数据类型 > < 该列所需约束 > ,< 列名 3> < 数据类型 > < 该列所需约束 > ,< 列名 4> < 数据类型 > < 该列所需约束 > ,...< 该表的约束 1> , < 该表的约束 2> ,……);----------------------------------------CREATE TABLE product(product_id CHAR(4) NOT NULL, -- 商品编号product_name VARCHAR(100) NOT NULL, -- 商品名称product_type VARCHAR(32) NOT NULL, -- 商品种类sale_price INTEGER , -- 销售单价purchase_price INTEGER , -- 进货单价regist_date DATE , -- 登记日期PRIMARY KEY (product_id));
四种最基本数据类型
- INTEGER 型
用来指定存储整数的列的数据类型(数字型),不能存储小数。
- CHAR 型
用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用。
- VARCHAR 型
用来存储可变长度字符串,定长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串不同,即使字符数未达到最大长度,也不会用半角空格补足。
- DATE 型
用来指定存储日期(年月日)的列的数据类型(日期型)。
约束
约束是除了数据类型之外,对列中存储的数据进行限制或者追加条件的功能。NOT NULL是非空约束,即该列必须输入数据。PRIMARY KEY是主键约束,代表该列是唯一值,可以通过该列取出特定的行的数据。DEFAULT DEFAULT 0 默认值
删除表
DROP TABLE < 表名 > ;DROP TABLE product;
更新表(alter:添加与删除列)
执行后无法恢复
-- 添加列ALTER TABLE < 表名 > ADD COLUMN < 列的定义 >;-- 添加一列可以存储100位的可变长字符串的 product_name_pinyin 列ALTER TABLE product ADD COLUMN product_name_pinyin VARCHAR(100);-- 删除列ALTER TABLE < 表名 > DROP COLUMN < 列名 >;ALTER TABLE product DROP COLUMN product_name_pinyin;-- 清空表内容TRUNCATE TABLE TABLE_NAME;
删除列的3种方法比较:
相比drop / delete,truncate用来清除数据时,速度最快。
更新数据(update)
UPDATE <表名>SET <列名> = <表达式> [, <列名2>=<表达式2>...];WHERE <条件>; -- 可选,非常重要。ORDER BY 子句; --可选LIMIT 子句; --可选---------------------------------------------- 修改所有的注册时间UPDATE productSET regist_date = '2009-10-10';-- 仅修改部分商品的单价UPDATE productSET sale_price = sale_price * 10WHERE product_type = '厨房用具';---------------------------------------------- 将商品编号为0008的数据(圆珠笔)的登记日期更新为NULLUPDATE productSET regist_date = NULLWHERE product_id = '0008';----------------------------------------------UPDATE 语句的 SET 子句支持同时将多个列作为更新对象。-- 基础写法,一条UPDATE语句只更新一列UPDATE productSET sale_price = sale_price * 10WHERE product_type = '厨房用具';UPDATE productSET purchase_price = purchase_price / 2WHERE product_type = '厨房用具';-- 合并后的写法UPDATE productSET sale_price = sale_price * 10,purchase_price = purchase_price / 2WHERE product_type = '厨房用具';
null值:可用于数据清空。但是,只有未设置 NOT NULL 约束和主键约束的列才可以清空为NULL
插入数据(insert)
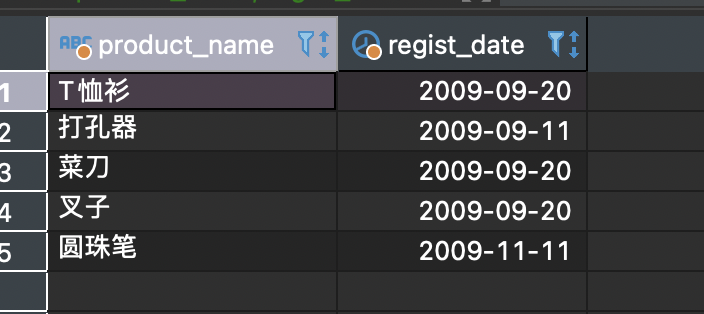
INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);--------------------------------------------CREATE TABLE productins(product_id CHAR(4) NOT NULL,product_name VARCHAR(100) NOT NULL,product_type VARCHAR(32) NOT NULL,sale_price INTEGER DEFAULT 0,purchase_price INTEGER ,regist_date DATE ,PRIMARY KEY (product_id));-- 包含列清单INSERT INTO productins (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');-- 省略列清单INSERT INTO productins VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');-- 通常的INSERTINSERT INTO productins VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');INSERT INTO productins VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);INSERT INTO productins VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');-- 多行INSERT ( DB2、SQL、SQL Server、 PostgreSQL 和 MySQL多行插入)INSERT INTO productins VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),('0003', '运动T恤', '衣服', 4000, 2800, NULL),('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');-- Oracle中的多行INSERTINSERT ALL INTO productins VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11')INTO productins VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL)INTO productins VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20')SELECT * FROM DUAL;-- DUAL是Oracle特有(安装时的必选项)的一种临时表A。因此“SELECT *FROM DUAL” 部分也只是临时性的,并没有实际意义。- DML :插入数据STARTTRANSACTION;INSERT INTO product VALUES('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');INSERT INTO product VALUES('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');INSERT INTO product VALUES('0003', '运动T恤', '衣服', 4000, 2800, NULL);INSERT INTO product VALUES('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');INSERT INTO product VALUES('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');INSERT INTO product VALUES('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');INSERT INTO product VALUES('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');INSERT INTO product VALUES('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');COMMIT;
2.5练习
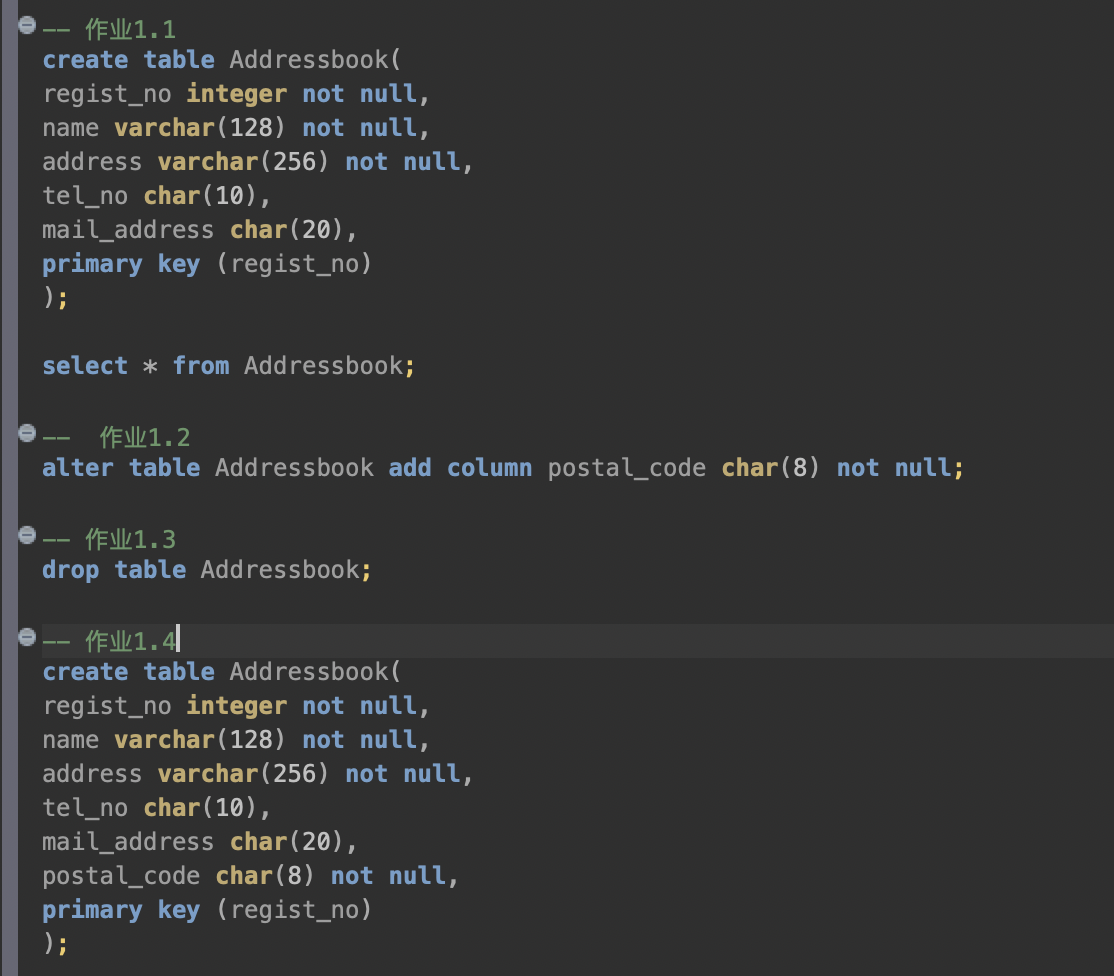
2.5.1
编写一条 CREATE TABLE 语句,用来创建一个包含表 1-A 中所列各项的表 Addressbook (地址簿),并为 regist_no (注册编号)列设置主键约束
表1-A 表 Addressbook (地址簿)中的列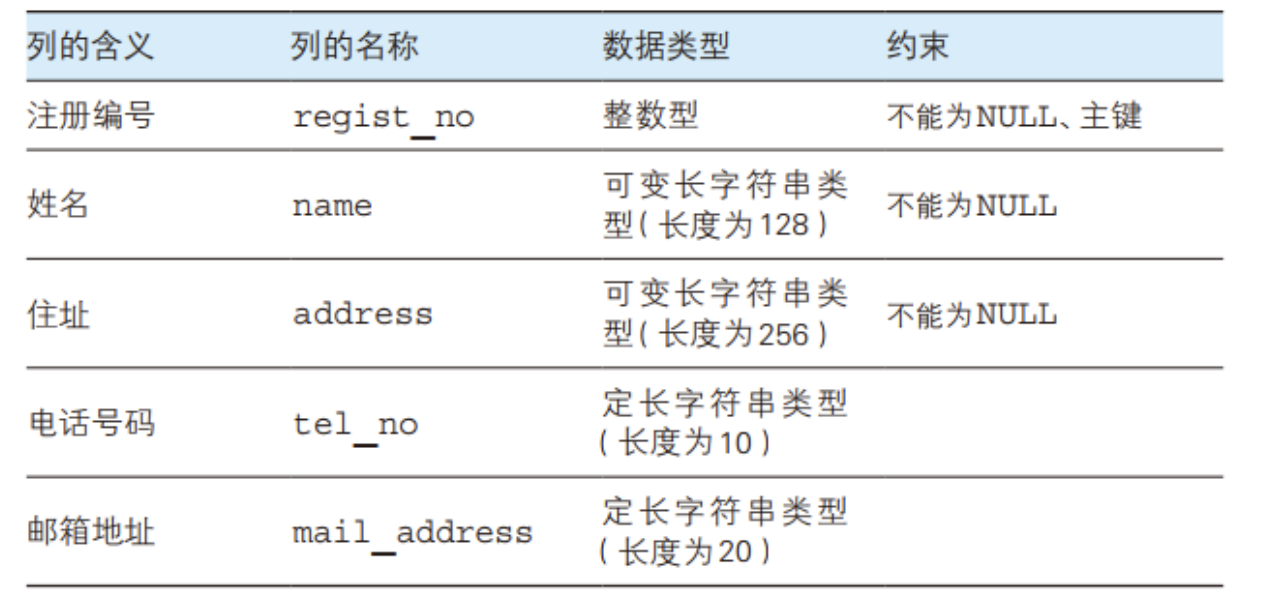
create table Addressbook(regist_no integer not null,name varchar(128) not null,address varchar(256) not null,tel_no char(10),mail_address char(20),primary key (regist_no));
2.5.2
假设在创建练习1.1中的 Addressbook 表时忘记添加如下一列 postal_code (邮政编码)了,请把此列添加到 Addressbook 表中。
列名 : postal_code
数据类型 :定长字符串类型(长度为 8)
约束 :不能为 NULL
alter table Addressbook add column postal_code char(8) not null;
2.5.3
编写 SQL 语句来删除 Addressbook 表。
drop table Addressbook;
2.5.4
编写 SQL 语句来恢复删除掉的 Addressbook 表。
create table Addressbook(regist_no integer not null,name varchar(128) not null,address varchar(256) not null,tel_no char(10),mail_address char(20),postal_code char(8) not null,primary key (regist_no));
3.基础查询与排序
3.1限定查询
- 星号(*)代表全部列的意思。
- SQL中可以随意使用换行符,不影响语句执行(但不可插入空行)。
- 设定汉语别名时需要使用双引号(”)括起来。
- 在SELECT语句中使用DISTINCT可以删除重复行。
- 注释是SQL语句中用来标识说明或者注意事项的部分。分为1行注释”— “和多行注释两种”/ /“。
- SELECT子句中可以使用常数或者表达式。
- 使用比较运算符时一定要注意不等号和等号的位置。
- 字符串类型的数据原则上按照字典顺序进行排序,不能与数字的大小顺序混淆。
希望选取NULL记录时,需要在条件表达式中使用IS NULL运算符。希望选取不是NULL的记录时,需要在条件表达式中使用IS NOT NULL运算符。 ```sql SELECT <列名>, FROM <表名>;
SELECT <列名>, …… FROM <表名> WHERE <条件表达式>;
— 用来选取product type列为衣服’的记录的SELECT语句 SELECT product_name, product_type FROM product WHERE product_type = ‘衣服’; — 也可以选取出不是查询条件的列(条件列与输出列不同) SELECT product_name FROM product WHERE product_type = ‘衣服’;
— 想要查询出全部列时,可以使用代表所有列的星号()。 SELECT FROM <表名>; — SQL语句可以使用AS关键字为列设定别名(用中文时需要双引号(“”))。 SELECT product_id As id, product_name As name, purchase_price AS “进货单价” FROM product; — 使用DISTINCT删除product_type列中重复的数据 SELECT DISTINCT product_type FROM product;
— SQL语句中也可以使用运算表达式 SELECT product_name, sale_price, sale_price 2 AS “sale_price x2” FROM product; — WHERE子句的条件表达式中也可以使用计算表达式 SELECT product_name, sale_price, purchase_price FROM product WHERE sale_price-purchase_price >= 500; / 对字符串使用不等号 首先创建chars并插入数据 选取出大于‘2’的SELECT语句*/ — DDL:创建表 CREATE TABLE chars (chr CHAR(3)NOT NULL, PRIMARY KEY(chr)); — 选取出大于’2’的数据的SELECT语句(‘2’为字符串) SELECT chr FROM chars WHERE chr > ‘2’; — 选取NULL的记录 SELECT product_name, purchase_price FROM product WHERE purchase_price IS NULL; — 选取不为NULL的记录 SELECT product_name, purchase_price FROM product WHERE purchase_price IS NOT NULL;
— 选取出销售单价大于等于1000日元的记录 SELECT product_name, product_type, sale_price FROM product WHERE sale_price >= 1000; — 向代码清单2-30的查询条件中添加NOT运算符 SELECT product_name, product_type, sale_price FROM product WHERE NOT sale_price >= 1000;
<a name="d0uK8"></a>## 3.2运算符- 算术运算符:+,-,*,/- 比较运算符:=,<>,>=, >, <, <=- 逻辑运算符:- not,表示否定- and,取交集- or,取并集and优先级优于or,可以利用括号提升优先级<br />真值表和普通认为的一样。<br />sql语句除了真和假,还有一个不确定(unknown)值。属于三值逻辑。<br />真值表:<br />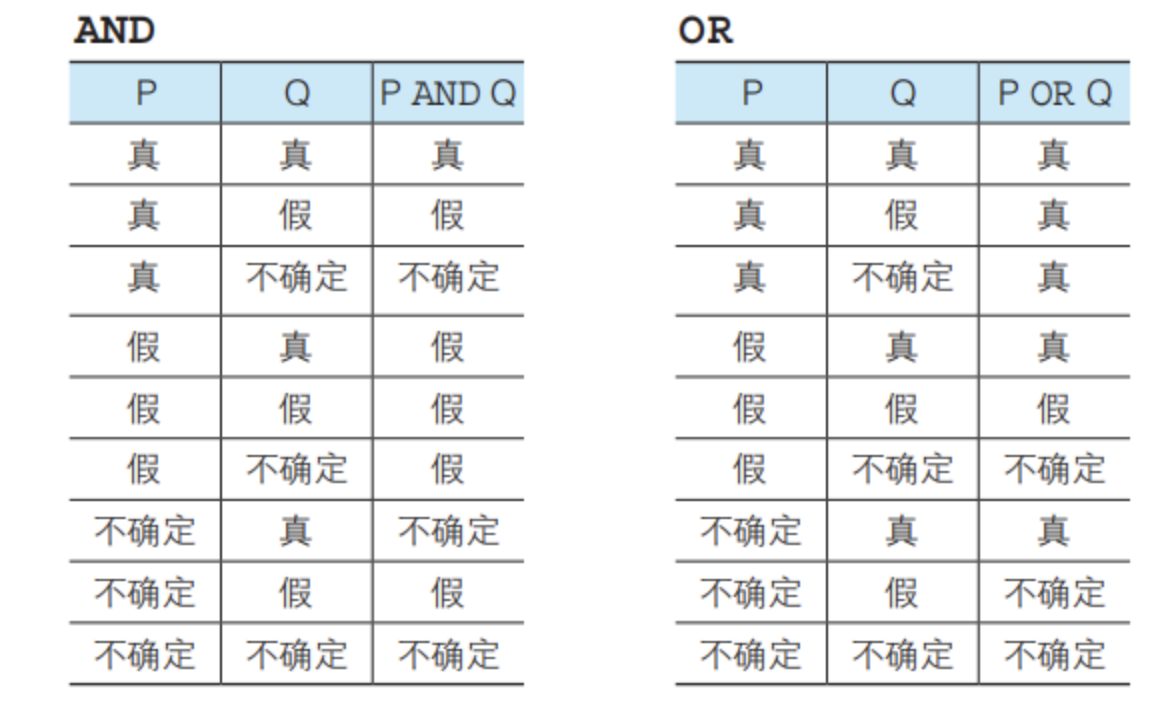<a name="fmMqP"></a>## 3.3练习题<a name="ZsPQL"></a>### 3.3.1编写一条SQL语句,从product(商品)表中选取出“登记日期(regist在2009年4月28日之后”的商品,查询结果要包含product name和regist_date两列。```sqlselect product_name, regist_date from product where regist_date > '2009-04-28';
3.3.2
请说出对product 表执行如下3条SELECT语句时的返回结果。
null要用is /is not,不如什么都查不到。
--1SELECT *FROM productWHERE purchase_price = NULL;
--2SELECT *FROM productWHERE purchase_price <> NULL;
--3SELECT *FROM productWHERE product_name > NULL;
3.3.3
从product表中取出“销售单价(saleprice)比进货单价(purchase price)高出500日元以上”的商品。请写出两条可以得到相同结果的SELECT语句。执行结果如下所示。
product_name | sale_price | purchase_price-------------+------------+------------T恤衫 | 1000 | 500运动T恤 | 4000 | 2800高压锅 | 6800 | 5000
select product_name, sale_price, purchase_price from product where sale_price-purchase_price >= 500;select product_name, sale_price, purchase_price from product where sale_price>=purchase_price + 500;
3.3.4
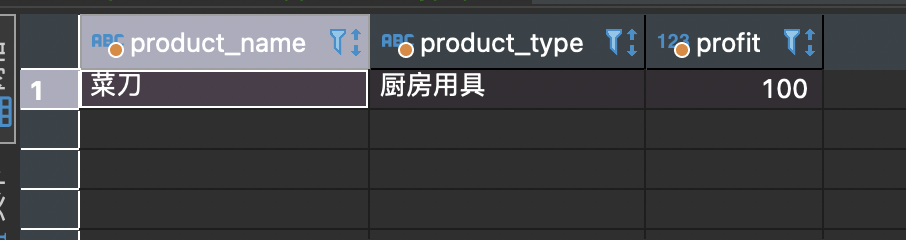
请写出一条SELECT语句,从product表中选取出满足“销售单价打九折之后利润高于100日元的办公用品和厨房用具”条件的记录。查询结果要包括product_name列、product_type列以及销售单价打九折之后的利润(别名设定为profit)。
提示:销售单价打九折,可以通过saleprice列的值乘以0.9获得,利润可以通过该值减去purchase_price列的值获得。
select product_name, product_type, purchase_price-sale_price*0.9 as profit from product where purchase_price-sale_price * 0.9 >= 100 and (product_type = '办公用品' or product_type ='厨房用具');
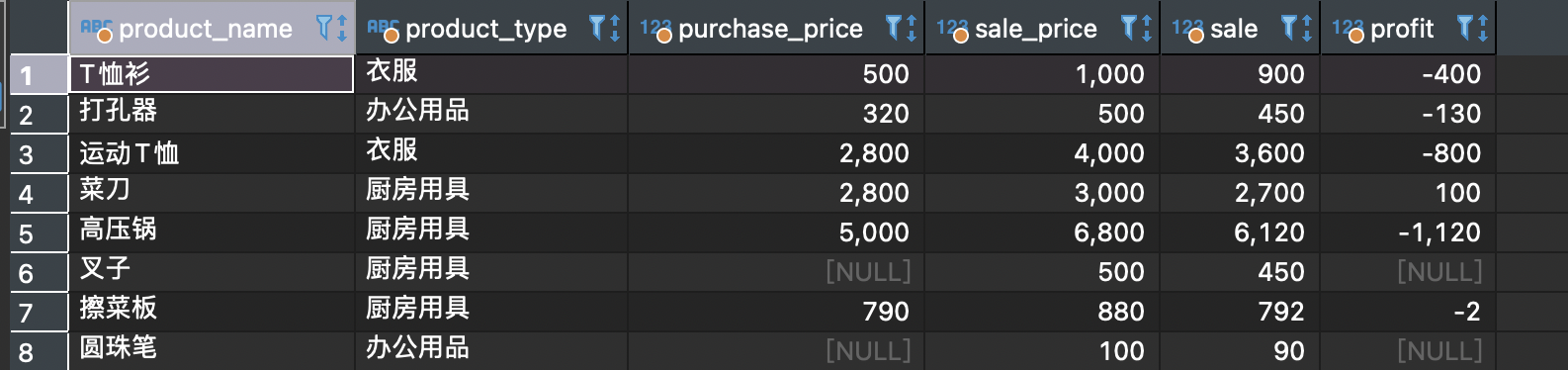
查看全部的:
elect product_name, product_type,purchase_price, sale_price, sale_price*0.9 as sale,purchase_price-sale_price*0.9 as profit from product;
3.4聚合查询
3.4.1使用聚合函数
聚合函数
- COUNT:计算表中的记录数(行数)
- SUM:计算表中数值列中数据的合计值
- AVG:计算表中数值列中数据的平均值
- MAX:求出表中任意列中数据的最大值
- MIN:求出表中任意列中数据的最小值
注意事项
- COUNT函数的结果根据参数的不同而不同。COUNT(*)会得到包含NULL的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数。
- 聚合函数会将NULL排除在外。但COUNT(*)例外,并不会排除NULL。
- MAX/MIN函数几乎适用于所有数据类型的列。SUM/AVG函数只适用于数值类型的列。
- 想要计算值的种类时,可以在COUNT函数的参数中使用DISTINCT。
- 在聚合函数的参数中使用DISTINCT,可以删除重复数据。 ```sql — 计算全部数据的行数(包含NULL) SELECT COUNT(*) FROM product; — 计算NULL以外数据的行数 SELECT COUNT(purchase_price) FROM product; — 计算销售单价和进货单价的合计值 SELECT SUM(sale_price), SUM(purchase_price) FROM product; — 计算销售单价和进货单价的平均值 SELECT AVG(sale_price), AVG(purchase_price) FROM product; — MAX和MIN也可用于非数值型数据 SELECT MAX(regist_date), MIN(regist_date) FROM product;
— 计算去除重复数据后的数据行数 SELECT COUNT(DISTINCT product_type) FROM product; — 是否使用DISTINCT时的动作差异(SUM函数) SELECT SUM(sale_price), SUM(DISTINCT sale_price) FROM product;
<a name="XZhjY"></a>## 3.5表分组- 在 GROUP BY 子句中指定的列称为**聚合键**或者**分组列**。- 聚合键包含null,会将null当作一组特殊数据处理。- GROUP BY的子句书写顺序有严格要求,不按要求会导致SQL无法正常执行,目前出现过的子句顺序为:1 SELECT → 2. FROM → 3. WHERE → 4. GROUP BY<br />其中前三项用于筛选数据,GROUP BY对筛选出的数据进行处理<a name="7BV84"></a>### 常见错误1. 在聚合函数的SELECT子句中写了聚合健以外的列使用COUNT等聚合函数时,**SELECT子句中如果出现列名,只能是GROUP BY子句中指定的列名**(也就是聚合键)。2. 在GROUP BY子句中使用列的别名SELECT子句中可以通过AS来指定别名,但**在GROUP BY中不能使用别名**。因为在DBMS中 ,SELECT子句在GROUP BY子句后执行。4. 在WHERE中使用聚合函数原因是**聚合函数的使用前提是结果集已经确定,而WHERE还处于确定结果集的过程中,所以相互矛盾会引发错误**。 如果想指定条件,可以在SELECT,HAVING(下面马上会讲)以及ORDER BY子句中使用聚合函数。```sqlSELECT <列名1>,<列名2>, <列名3>, ……FROM <表名>GROUP BY <列名1>, <列名2>, <列名3>, ……;-- 按照商品种类统计数据行数SELECT product_type, COUNT(*)FROM productGROUP BY product_type;-- 不含GROUP BYSELECT product_type, COUNT(*)FROM productSELECT purchase_price, COUNT(*)FROM productGROUP BY purchase_price;SELECT purchase_price, COUNT(*)FROM productWHERE product_type = '衣服'GROUP BY purchase_price;
用having给分组指定条件
这里WHERE不可行,因为,WHERE子句只能指定记录(行)的条件,而不能用来指定组的条件(例如,“数据行数为 2 行”或者“平均值为 500”等)。
可以在GROUP BY后使用HAVING子句。
HAVING的用法类似WHERE
HAVING子句用于对分组进行过滤,可以使用数字、聚合函数和GROUP BY中指定的列名(聚合键)。
-- 数字SELECT product_type, COUNT(*)FROM productGROUP BY product_typeHAVING COUNT(*) = 2;-- 错误形式(因为product_name不包含在GROUP BY聚合键中)SELECT product_type, COUNT(*)FROM productGROUP BY product_typeHAVING product_name = '圆珠笔';
3.6对查询结果进行排序
SQL中的执行结果是随机排列的,当需要按照特定顺序排序时,可已使用ORDER BY子句。
默认为升序排列,降序排列为DESC
在 ORDER BY 子句中却可以使用别名
为什么在GROUP BY中不可以而在ORDER BY中可以呢? 这是因为SQL在使用 HAVING 子句时 SELECT 语句的顺序为: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY。 其中SELECT的执行顺序在 GROUP BY 子句之后,ORDER BY 子句之前。也就是说,当在ORDER BY中使用别名时,已经知道了SELECT设置的别名存在,但是在GROUP BY中使用别名时还不知道别名的存在,所以不能在ORDER BY中可以使用别名,但是在GROUP BY中不能使用别名
SELECT <列名1>, <列名2>, <列名3>, ……FROM <表名>ORDER BY <排序基准列1>, <排序基准列2>, ……-- 降序排列SELECT product_id, product_name, sale_price, purchase_priceFROM productORDER BY sale_price DESC;-- 多个排序键SELECT product_id, product_name, sale_price, purchase_priceFROM productORDER BY sale_price, product_id;-- 当用于排序的列名中含有NULL时,NULL会在开头或末尾进行汇总。SELECT product_id, product_name, sale_price, purchase_priceFROM productORDER BY purchase_price;
3.7练习题
3.7.1
请指出下述SELECT语句中所有的语法错误。
SELECT product_id, SUM(product_name)--本SELECT语句中存在错误。FROM productGROUP BY product_typeWHERE regist_date > '2009-09-01';
错误1:where要放在group by前
错误2:select里只能使用product_type或对其使用聚合函数。
错误3: sum函数使用了全角的括号。应为半角。
错误4: 注释的—后应有个空格。
改完后:
SELECT product_type,sum(product_type)-- 本SELECT语句中存在错误。FROM productWHERE regist_date > '2009-09-01'GROUP BY product_type ;
3.7.2
请编写一条SELECT语句,求出销售单价( sale_price 列)合计值大于进货单价( purchase_price 列)合计值1.5倍的商品种类。执行结果如下所示。
select product_type,sum(sale_price), sum(purchase_price)from productgroup by product_type having sum(sale_price) > 1.5*sum(purchase_price);

3.7.3
此前我们曾经使用SELECT语句选取出了product(商品)表中的全部记录。当时我们使用了ORDERBY子句来指定排列顺序,但现在已经无法记起当时如何指定的了。请根据下列执行结果,思考ORDERBY子句的内容。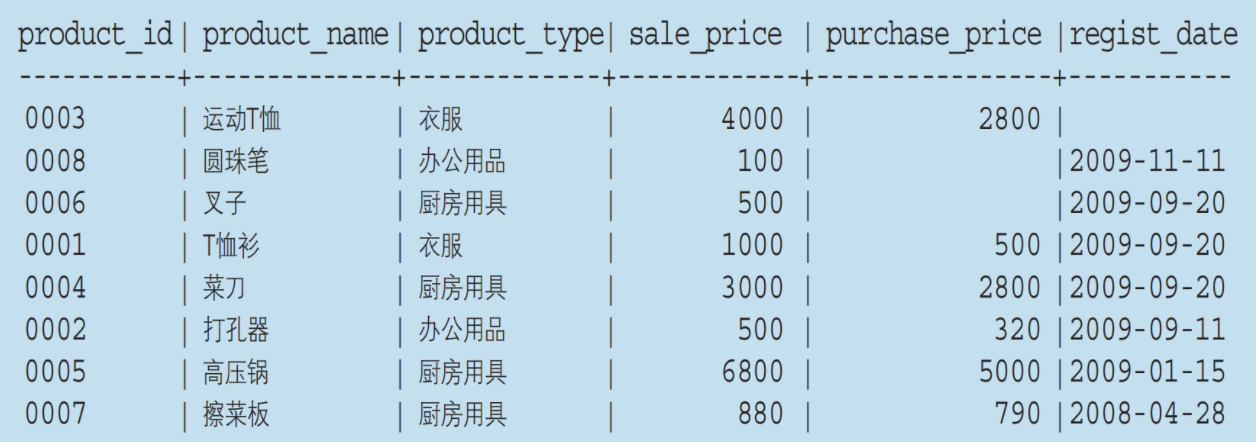
按照regist_date空值置顶,regist_date倒序,相同regist_date,按照sale_price升序。
注意缺了这句会导致时间乱序:regist_date desc
SELECT * from product order by regist_date is null desc,regist_date desc,sale_price asc;
在 MySQL 中,NULL 值被认为低于任何非 NULL 值,因此,当顺序是 ASC (升序)时,NULL 值首先出现,当顺序是 DESC (降序)时,NULL 值最后出现。我们将讨论以下两种情况,因为在这两种情况下,对 NULL 值进行排序可能并不简单。
参考资料:https://www.designcise.com/web/tutorial/how-to-order-null-values-first-or-last-in-mysql
4.复杂查询
4.1视图
视图与表的区别:是否保存实际数据。视图可理解为一个窗口,用来看到数据库表中真实数据。
比如一个select查询出来的结果就是视图。
视图基于真值表,也可以基于视图。但多重视图会降低sql性能。
一般dbms视图定义不能使用order by,因为视图和表一样,数据行没有顺序。
mysql视图定义可使用order by。
4.1.1视图创建
CREATE VIEW <视图名称>(<列名1>,<列名2>,…) AS
4.1.2视图更新
- 如果原表可以更新,那么 视图中的数据也可以更新。反之亦然,如果视图发生了改变,而原表没有进行相应更新的话,就无法保证数据的一致性了。
- 对于一个视图来说,如果包含以下结构的任意一种都是不可以被更新的:
- 聚合函数 SUM()、MIN()、MAX()、COUNT() 等。
- DISTINCT 关键字。
- GROUP BY 子句。
- HAVING 子句。
- UNION 或 UNION ALL 运算符。
- FROM 子句中包含多个表。
- 视图更新,原表也会被更新。但更新的只是视图里可以被看到的数据
4.1.3删除视图
DROP VIEW <视图名1> [ , <视图名2> …]
-- 创建视图CREATE VIEW <视图名称>(<列名1>,<列名2>,...) AS <SELECT语句>-- 基于单表视图CREATE VIEW productsum (product_type, cnt_product)ASSELECT product_type, COUNT(*)FROM productGROUP BY product_type ;-- 基于多表视图CREATE VIEW view_shop_product(product_type, sale_price, shop_name)ASSELECT product_type, sale_price, shop_nameFROM product,shop_productWHERE product.product_id = shop_product.product_id;-- 在上面的视图上查询SELECT sale_price, shop_nameFROM view_shop_productWHERE product_type = '衣服';-- 修改视图结构,视图名需要是数据库唯一。-- 也可以通过将当前视图删除然后重新创建的方式达到修改的效果。ALTER VIEW <视图名> AS <SELECT语句>ALTER VIEW productSumASSELECT product_type, sale_priceFROM ProductWHERE regist_date > '2009-09-11';-- 视图更新UPDATE productsumSET sale_price = '5000'WHERE product_type = '办公用品';-- 删除视图:需要权限DROP VIEW <视图名1> [ , <视图名2> …]DROP VIEW productSum;
4.2子查询
嵌套查询,select的from来自另一个select(子查询)的结果。
子查询是一次性的,不会存储的介质中。
但视图会保存下来。
多层嵌套,导致难以理解以及效率下降,尽量避免。
SELECT stu_nameFROM (SELECT stu_name, COUNT(*) AS stu_cntFROM students_infoGROUP BY stu_age) AS studentSum;
4.2.1标量子查询
只返回一个值的查询。
场景:
- 查询出销售单价高于平均销售单价的商品
- 查询出注册日期最晚的那个商品
标量子查询不仅仅局限于 WHERE 子句中,通常任何可以使用单一值的位置都可以使用。也就是说, 能够使用常数或者列名的地方,无论是 SELECT 子句、GROUP BY 子句、HAVING 子句,还是 ORDER BY 子句,几乎所有的地方都可以使用。
SELECT product_id, product_name, sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product);SELECT product_id,product_name,sale_price,(SELECT AVG(sale_price)FROM product) AS avg_priceFROM product;
4.2.2关联子查询
通过一些标志将内外两层的查询连接起来起到过滤数据的目的
SELECT product_type, product_name, sale_priceFROM product AS p1WHERE sale_price > (SELECT AVG(sale_price)FROM product AS p2WHERE p1.product_type = p2.product_typeGROUP BY product_type);--SELECT product_type, product_name, sale_priceFROM product AS p1WHERE sale_price > (SELECT AVG(sale_price)FROM product AS p2WHERE p1.product_type =p2.product_typeGROUP BY product_type);
4.3练习题
4.3.1
创建出满足下述三个条件的视图(视图名称为 ViewPractice5_1)。使用 product(商品)表作为参照表,假设表中包含初始状态的 8 行数据。
- 条件 1:销售单价大于等于 1000 日元。
- 条件 2:登记日期是 2009 年 9 月 20 日。
- 条件 3:包含商品名称、销售单价和登记日期三列。
对该视图执行 SELECT 语句的结果如下所示。
SELECT * FROM ViewPractice5_1;
执行结果
product_name | sale_price | regist_date--------------+------------+------------T恤衫 | 1000 | 2009-09-20菜刀 | 3000 | 2009-09-20
-- 作业3.1create view ViewPractice5_1(prodouct_name, sale_price, regist_date) asselect product_name, sale_price, regist_datefrom productwhere sale_price >= 1000 and regist_date = '2009-09-20';select * from ViewPractice5_1;

4.3.2
向习题一中创建的视图 ViewPractice5_1 中插入如下数据,会得到什么样的结果呢?
INSERT INTO ViewPractice5_1 VALUES (' 刀子 ', 300, '2009-11-02');
执行报错,提示:Field of view ‘shop.viewpractice5_1’ underlying table doesn’t have a default value.
显式的:INSERTINTOViewPractice5_1(prodouct_name, sale_price, regist_date) VALUES (‘ 刀子 ‘, 300, ‘2009-11-02’);
依然如此。
product表的列定义: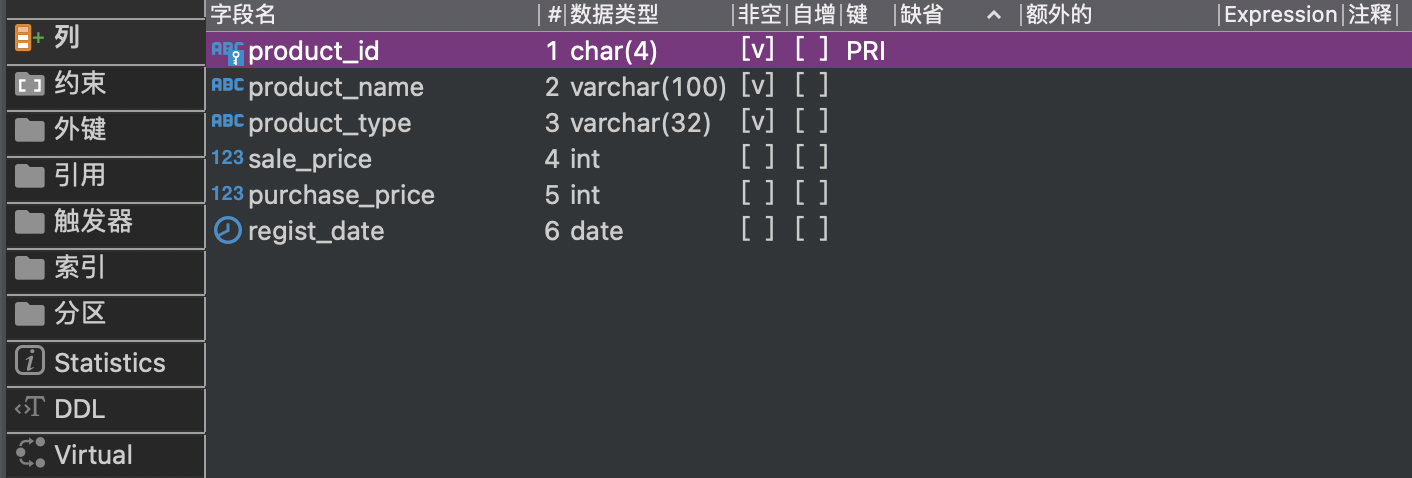
如果在product表设置视图对应字段拥有默认值,
查询资料,向视图插入数据,首先要有插入资格,其次拥有以下条件之一:
- 该字段允许空值。
- 该字段设有默认值。
- 该字段是标识字段,可根据标识种子和标识增量自动填充数据。
- 该字段的数据类型为timestamp或uniqueidentifier。
4.3.3
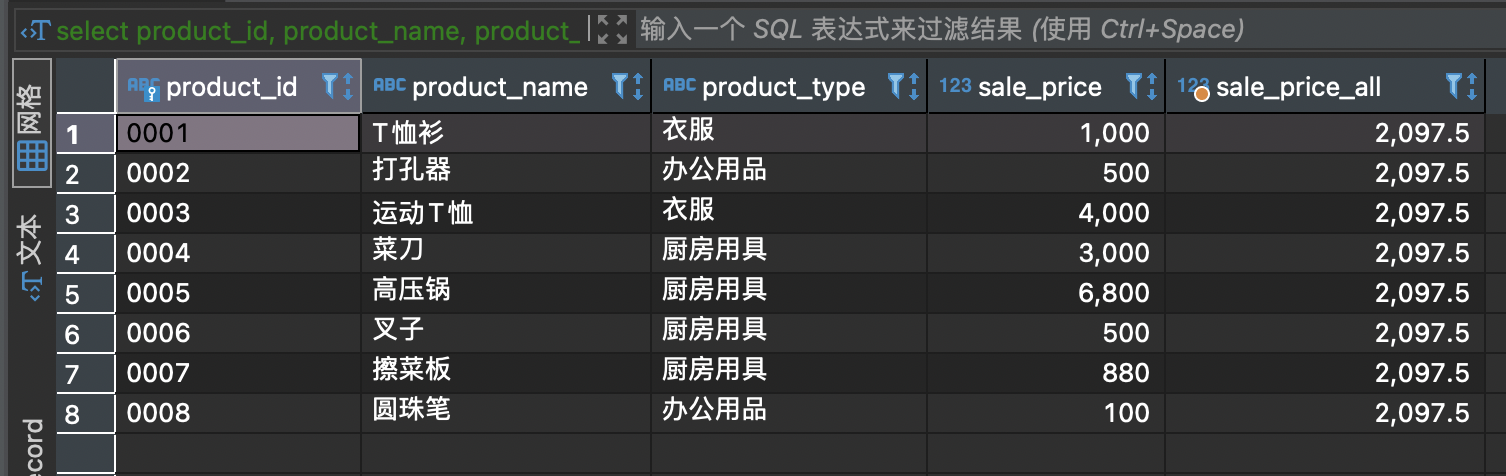
请根据如下结果编写 SELECT 语句,其中 sale_price_all 列为全部商品的平均销售单价。
product_id | product_name | product_type | sale_price | sale_price_all------------+-------------+--------------+------------+---------------------0001 | T恤衫 | 衣服 | 1000 | 2097.50000000000000000002 | 打孔器 | 办公用品 | 500 | 2097.50000000000000000003 | 运动T恤 | 衣服 | 4000 | 2097.50000000000000000004 | 菜刀 | 厨房用具 | 3000 | 2097.50000000000000000005 | 高压锅 | 厨房用具 | 6800 | 2097.50000000000000000006 | 叉子 | 厨房用具 | 500 | 2097.50000000000000000007 | 擦菜板 | 厨房用具 | 880 | 2097.50000000000000000008 | 圆珠笔 | 办公用品 | 100 | 2097.5000000000000000
-- 注意子查询里的括号select product_id, product_name, product_type, sale_price,(select AVG(sale_price) from product) as sale_price_allfrom product;
4.3.4
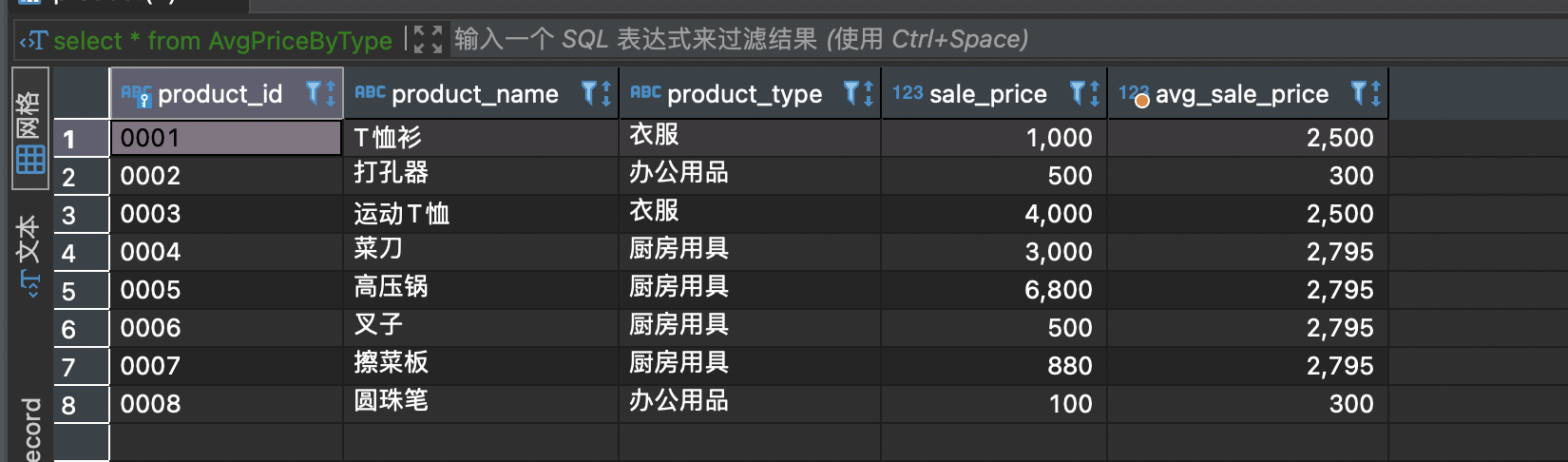
请根据习题一中的条件编写一条 SQL 语句,创建一幅包含如下数据的视图(名称为AvgPriceByType)。
product_id | product_name | product_type | sale_price | avg_sale_price------------+-------------+--------------+------------+---------------------0001 | T恤衫 | 衣服 | 1000 |2500.00000000000000000002 | 打孔器 | 办公用品 | 500 | 300.00000000000000000003 | 运动T恤 | 衣服 | 4000 |2500.00000000000000000004 | 菜刀 | 厨房用具 | 3000 |2795.00000000000000000005 | 高压锅 | 厨房用具 | 6800 |2795.00000000000000000006 | 叉子 | 厨房用具 | 500 |2795.00000000000000000007 | 擦菜板 | 厨房用具 | 880 |2795.00000000000000000008 | 圆珠笔 | 办公用品 | 100 | 300.0000000000000000
提示:其中的关键是 avg_sale_price 列。与习题三不同,这里需要计算出的 是各商品种类的平均销售单价。这与使用关联子查询所得到的结果相同。 也就是说,该列可以使用关联子查询进行创建。问题就是应该在什么地方使用这个关联子查询。
解答:先完成查询句,再套上创建视图的语法。
关于各商品种类的平均销售单价,参考前面的例子。
关键在于对子查询两个表的别名的定义。最外层是表p1,内层是表p2。
CREATE view AvgPriceByType (product_id, product_name, product_type, sale_price,avg_sale_price)asselect product_id, product_name, product_type, sale_price,(SELECT AVG(sale_price)FROM product AS p2WHERE p1.product_type =p2.product_type) as avg_sale_pricefrom product as p1;select * from AvgPriceByType;
4.4函数
函数总个数超过200个,不需要完全记住,常用函数有 30~50 个,其他不常用的函数使用时查阅文档即可。
4.4.1算术函数 (用来进行数值计算的函数)
+,-,*,/
-- DDL :创建表USE shop;DROP TABLE IF EXISTS samplemath;CREATE TABLE samplemath(m float(10,3),n INT,p INT);-- DML :插入数据START TRANSACTION; -- 开始事务INSERT INTO samplemath(m, n, p) VALUES (500, 0, NULL);INSERT INTO samplemath(m, n, p) VALUES (-180, 0, NULL);INSERT INTO samplemath(m, n, p) VALUES (NULL, NULL, NULL);INSERT INTO samplemath(m, n, p) VALUES (NULL, 7, 3);INSERT INTO samplemath(m, n, p) VALUES (NULL, 5, 2);INSERT INTO samplemath(m, n, p) VALUES (NULL, 4, NULL);INSERT INTO samplemath(m, n, p) VALUES (8, NULL, 3);INSERT INTO samplemath(m, n, p) VALUES (2.27, 1, NULL);INSERT INTO samplemath(m, n, p) VALUES (5.555,2, NULL);INSERT INTO samplemath(m, n, p) VALUES (NULL, 1, NULL);INSERT INTO samplemath(m, n, p) VALUES (8.76, NULL, NULL);COMMIT; -- 提交事务-- 查询表内容SELECT * FROM samplemath;+----------+------+------+| m | n | p |+----------+------+------+| 500.000 | 0 | NULL || -180.000 | 0 | NULL || NULL | NULL | NULL || NULL | 7 | 3 || NULL | 5 | 2 || NULL | 4 | NULL || 8.000 | NULL | 3 || 2.270 | 1 | NULL || 5.555 | 2 | NULL || NULL | 1 | NULL || 8.760 | NULL | NULL |+----------+------+------+11 rows in set (0.00 sec)
4.4.1.1ABS — 绝对值
语法:ABS( 数值 )
ABS 函数用于计算一个数字的绝对值,表示一个数到原点的距离。
当 ABS 函数的参数为NULL时,返回值也是NULL。
4.4.1.2MOD — 求余数
语法:MOD( 被除数,除数 )
MOD 是计算除法余数(求余)的函数,是 modulo 的缩写。小数没有余数的概念,只能对整数列求余数。
注意:主流的 DBMS 都支持 MOD 函数,只有SQL Server 不支持该函数,其使用%符号来计算余数。
4.4.1.3ROUND — 四舍五入
语法:ROUND( 对象数值,保留小数的位数 )
ROUND 函数用来进行四舍五入操作。
注意:当参数 保留小数的位数 为变量时,可能会遇到错误,请谨慎使用变量。
SELECT m,ABS(m)ASabs_col ,n, p,MOD(n, p) AS mod_col,ROUND(m,1)ASround_colSFROM samplemath;+----------+---------+------+------+---------+-----------+| m | abs_col | n | p | mod_col | round_col |+----------+---------+------+------+---------+-----------+| 500.000 | 500.000 | 0 | NULL | NULL | 500.0 || -180.000 | 180.000 | 0 | NULL | NULL | -180.0 || NULL | NULL | NULL | NULL | NULL | NULL || NULL | NULL | 7 | 3 | 1 | NULL || NULL | NULL | 5 | 2 | 1 | NULL || NULL | NULL | 4 | NULL | NULL | NULL || 8.000 | 8.000 | NULL | 3 | NULL | 8.0 || 2.270 | 2.270 | 1 | NULL | NULL | 2.3 || 5.555 | 5.555 | 2 | NULL | NULL | 5.6 || NULL | NULL | 1 | NULL | NULL | NULL || 8.760 | 8.760 | NULL | NULL | NULL | 8.8 |+----------+---------+------+------+---------+-----------+11 rows in set (0.08 sec)
4.4.2字符串函数 (用来进行字符串操作的函数)
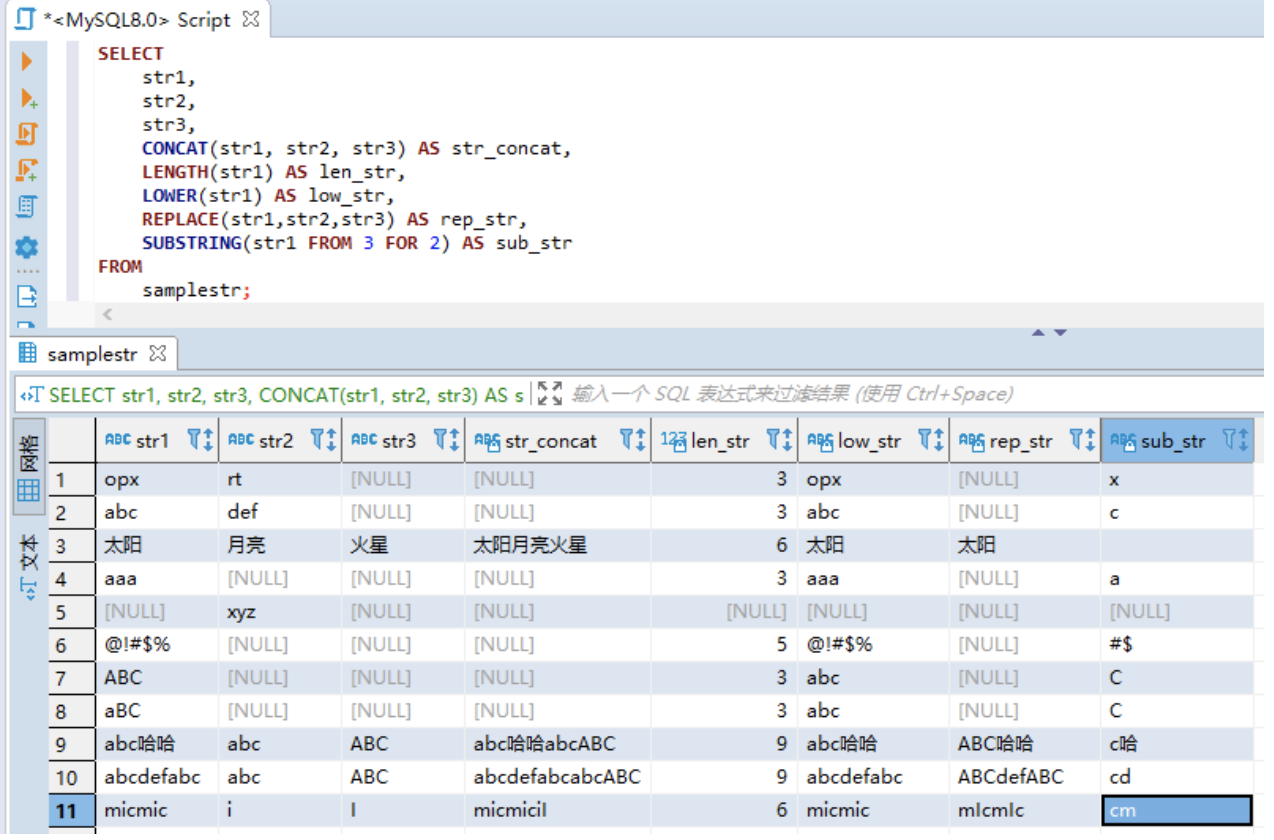
4.4.2.1CONCAT — 拼接
语法:CONCAT(str1, str2, str3)
MySQL中使用 CONCAT 函数进行拼接。
4.4.2.2LENGTH — 字符串长度
4.4.2.3LOWER — 小写转换
LOWER 函数只能针对英文字母使用,它会将参数中的字符串全都转换为小写。该函数不适用于英文字母以外的场合,不影响原本就是小写的字符。
类似的, UPPER 函数用于大写转换。
4.4.2.4REPLACE — 字符串的替换
语法:REPLACE( 对象字符串,替换前的字符串,替换后的字符串 )
4.4.2.5SUBSTRING — 字符串的截取
语法:SUBSTRING (对象字符串 FROM 截取的起始位置 FOR 截取的字符数)
使用 SUBSTRING 函数 可以截取出字符串中的一部分字符串。截取的起始位置从字符串最左侧开始计算,索引值起始为1。
4.4.2.6SUBSTRING_INDEX — 字符串按索引截取
语法:SUBSTRING_INDEX (原始字符串, 分隔符,n)
该函数用来获取原始字符串按照分隔符分割后,第 n 个分隔符之前(或之后)的子字符串,支持正向和反向索引,索引起始值分别为 1 和 -1。
-- DDL :创建表USE shop;DROP TABLE IF EXISTS samplestr;CREATE TABLE samplestr(str1 VARCHAR (40),str2 VARCHAR (40),str3 VARCHAR (40));-- DML:插入数据START TRANSACTION;INSERT INTO samplestr (str1, str2, str3) VALUES ('opx', 'rt', NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('abc', 'def', NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('太阳', '月亮', '火星');INSERT INTO samplestr (str1, str2, str3) VALUES ('aaa', NULL, NULL);INSERT INTO samplestr (str1, str2, str3) VALUES (NULL, 'xyz', NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('@!#$%', NULL, NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('ABC', NULL, NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('aBC', NULL, NULL);INSERT INTO samplestr (str1, str2, str3) VALUES ('abc哈哈', 'abc', 'ABC');INSERT INTO samplestr (str1, str2, str3) VALUES ('abcdefabc', 'abc', 'ABC');INSERT INTO samplestr (str1, str2, str3) VALUES ('micmic', 'i', 'I');COMMIT;-- 确认表中的内容SELECT * FROM samplestr;+-----------+------+------+| str1 | str2 | str3 |+-----------+------+------+| opx | rt | NULL || abc | def | NULL || 太阳 | 月亮 | 火星 || aaa | NULL | NULL || NULL | xyz | NULL || @!#$% | NULL | NULL || ABC | NULL | NULL || aBC | NULL | NULL || abc哈哈 | abc | ABC || abcdefabc | abc | ABC || micmic | i | I |+-----------+------+------+11 rows in set (0.00 sec)--获取第一个元素SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);+------------------------------------------+| SUBSTRING_INDEX('www.mysql.com', '.', 2) |+------------------------------------------+| www.mysql |+------------------------------------------+1 row in set (0.00 sec)SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);+-------------------------------------------+| SUBSTRING_INDEX('www.mysql.com', '.', -2) |+-------------------------------------------+| mysql.com |+-------------------------------------------+1 row in set (0.00 sec)-- 获取第2个元素/第n个元素可以采用二次拆分的写法SELECT SUBSTRING_INDEX('www.mysql.com', '.', 1);+------------------------------------------+| SUBSTRING_INDEX('www.mysql.com', '.', 1) |+------------------------------------------+| www |+------------------------------------------+1 row in set (0.00 sec)SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('www.mysql.com', '.', 2), '.', -1);+--------------------------------------------------------------------+| SUBSTRING_INDEX(SUBSTRING_INDEX('www.mysql.com', '.', 2), '.', -1) |+--------------------------------------------------------------------+| mysql |+--------------------------------------------------------------------+1 row in set (0.00 sec)
4.4.3日期函数 (用来进行日期操作的函数)
不同DBMS的日期函数语法各有不同,下面介绍一些被标准 SQL 承认的可以应用于绝大多数 DBMS 的函数。
特定DBMS的日期函数查阅文档即可。
4.4.3.1CURRENT_DATE — 获取当前日期
4.4.3.2CURRENT_TIME — 当前时间
4.4.3.3CURRENT_TIMESTAMP — 当前日期和时间
4.4.3.4EXTRACT — 截取日期元素
语法:EXTRACT(日期元素 FROM 日期)
使用 EXTRACT 函数可以截取出日期数据中的一部分,例如“年”
“月”,或者“小时”“秒”等。该函数的返回值并不是日期类型而是数值类型
SELECT CURRENT_DATE;+--------------+| CURRENT_DATE |+--------------+| 2020-08-08 |+--------------+1 row in set (0.00 sec)SELECT CURRENT_TIME;+--------------+| CURRENT_TIME |+--------------+| 17:26:09 |+--------------+1 row in set (0.00 sec)SELECT CURRENT_TIMESTAMP;+---------------------+| CURRENT_TIMESTAMP |+---------------------+| 2020-08-08 17:27:07 |+---------------------+1 row in set (0.00 sec)SELECT CURRENT_TIMESTAMP as now,EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS MINute,EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;+---------------------+------+-------+------+------+--------+--------+| now | year | month | day | hour | MINute | second |+---------------------+------+-------+------+------+--------+--------+| 2020-08-08 17:34:38 | 2020 | 8 | 8 | 17 | 34 | 38 |+---------------------+------+-------+------+------+--------+--------+1 row in set (0.00 sec)
4.4.4转换函数 (用来转换数据类型和值的函数)
一是数据类型的转换,简称为类型转换,在英语中称为cast;
另一层意思是值的转换。
4.4.4.1CAST — 类型转换
4.4.4.2COALESCE — 将NULL转换为其他值
语法:COALESCE(数据1,数据2,数据3……)
COALESCE 是 SQL 特有的函数。该函数会返回可变参数 A 中左侧开始第 1个不是NULL的值。
参数个数是可变的,因此可以根据需要无限增加。
在 SQL 语句中将 NULL 转换为其他值时就会用到转换函数。
-- 将字符串类型转换为数值类型SELECT CAST('0001' AS SIGNED INTEGER) AS int_col;+---------+| int_col |+---------+| 1 |+---------+1 row in set (0.00 sec)-- 将字符串类型转换为日期类型SELECT CAST('2009-12-14' AS DATE) AS date_col;+------------+| date_col |+------------+| 2009-12-14 |+------------+1 row in set (0.00 sec)SELECT COALESCE(NULL, 11) AS col_1,COALESCE(NULL, 'hello world', NULL) AS col_2,COALESCE(NULL, NULL, '2020-11-01') AS col_3;+-------+-------------+------------+| col_1 | col_2 | col_3 |+-------+-------------+------------+| 11 | hello world | 2020-11-01 |+-------+-------------+------------+1 row in set (0.00 sec)
4.4.5聚合函数 (用来进行数据聚合的函数)
4.5谓词
谓词就是返回值为真值的函数。包括TRUE / FALSE / UNKNOWN。
谓词主要有以下几个:
4.5.1LIKE,字符串部分一致性查询
对字符串的一部分进行一致性查询时使用。
_下划线匹配任意 1 个字符%是代表“零个或多个任意字符串”的特殊符号
根据%放的位置,分为前方一致,中间一致和后方一致3种类型。
-- DDL :创建表CREATE TABLE samplelike( strcol VARCHAR(6) NOT NULL,PRIMARY KEY (strcol)samplelike);-- DML :插入数据START TRANSACTION; -- 开始事务INSERT INTO samplelike (strcol) VALUES ('abcddd');INSERT INTO samplelike (strcol) VALUES ('dddabc');INSERT INTO samplelike (strcol) VALUES ('abdddc');INSERT INTO samplelike (strcol) VALUES ('abcdd');INSERT INTO samplelike (strcol) VALUES ('ddabc');INSERT INTO samplelike (strcol) VALUES ('abddc');COMMIT; -- 提交事务SELECT * FROM samplelike;+--------+| strcol |+--------+| abcdd || abcddd || abddc || abdddc || ddabc || dddabc |+--------+6 rows in set (0.00 sec)-- 前方一致:选取出“dddabc”SELECT * FROM samplelikeWHERE strcol LIKE 'ddd%';+--------+| strcol |+--------+| dddabc |+--------+1 row in set (0.00 sec)-- 中间一致:选取出“abcddd”“dddabc”“abdddc”SELECT *FROM samplelikeWHERE strcol LIKE '%ddd%';+--------+| strcol |+--------+| abcddd || abdddc || dddabc |+--------+3 rows in set (0.00 sec)-- 后方一致:选取出“abcddd“SELECT *FROM samplelikeWHERE strcol LIKE '%ddd';+--------+| strcol |+--------+| abcddd |+--------+1 row in set (0.00 sec)--_下划线匹配任意 1 个字符SELECT *FROM samplelikeWHERE strcol LIKE 'abc__';+--------+| strcol |+--------+| abcdd |+--------+1 row in set (0.00 sec)
4.5.2BETWEEN,用于范围查询
范围查询,需要3个参数。闭区间。
不包括临界值,则使用< 和 >
-- 选取销售单价为100~ 1000元的商品SELECT product_name, sale_priceFROM productWHERE sale_price BETWEEN 100 AND 1000;+--------------+------------+| product_name | sale_price |+--------------+------------+| T恤 | 1000 || 打孔器 | 500 || 叉子 | 500 || 擦菜板 | 880 || 圆珠笔 | 100 |+--------------+------------+5 rows in set (0.00 sec)-- SELECT product_name, sale_priceFROM productWHERE sale_price > 100AND sale_price < 1000;+--------------+------------+| product_name | sale_price |+--------------+------------+| 打孔器 | 500 || 叉子 | 500 || 擦菜板 | 880 |+--------------+------------+3 rows in set (0.00 sec)
4.5.3IS NULL、IS NOT NULL, 判断是否为null
不能使用=来获得是null的值。
SELECT product_name, purchase_priceFROM productWHERE purchase_price IS NULL;+--------------+----------------+| product_name | purchase_price |+--------------+----------------+| 叉子 | NULL || 圆珠笔 | NULL |+--------------+----------------+2 rows in set (0.00 sec)SELECT product_name, purchase_priceFROM productWHERE purchase_price IS NOT NULL;+--------------+----------------+| product_name | purchase_price |+--------------+----------------+| T恤 | 500 || 打孔器 | 320 || 运动T恤 | 2800 || 菜刀 | 2800 || 高压锅 | 5000 || 擦菜板 | 790 |+--------------+----------------+6 rows in set (0.00 sec)
4.5.4IN:or的简便用法
也有not in,但不能选出null。
SELECT product_name, purchase_priceFROM productWHERE purchase_price IN (320, 500, 5000);+--------------+----------------+| product_name | purchase_price |+--------------+----------------+| T恤 | 500 || 打孔器 | 320 || 高压锅 | 5000 |+--------------+----------------+3 rows in set (0.00 sec)SELECT product_name, purchase_priceFROM productWHERE purchase_price NOT IN (320, 500, 5000);+--------------+----------------+| product_name | purchase_price |+--------------+----------------+| 运动T恤 | 2800 || 菜刀 | 2800 || 擦菜板 | 790 |+--------------+----------------+3 rows in set (0.00 sec)
作为子查询的参数
-- DDL :创建表DROP TABLE IF EXISTS shopproduct;CREATE TABLE shopproduct( shop_id CHAR(4) NOT NULL,shop_name VARCHAR(200) NOT NULL,product_id CHAR(4) NOT NULL,quantity INTEGER NOT NULL,PRIMARY KEY (shop_id, product_id) -- 指定主键);-- DML :插入数据START TRANSACTION; -- 开始事务INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0001', 30);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0002', 50);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0003', 15);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0002', 30);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0003', 120);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0004', 20);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0006', 10);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0007', 40);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0003', 20);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0004', 50);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0006', 90);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0007', 70);INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000D', '福冈', '0001', 100);COMMIT; -- 提交事务SELECT * FROM shopproduct;+---------+-----------+------------+----------+| shop_id | shop_name | product_id | quantity |+---------+-----------+------------+----------+| 000A | 东京 | 0001 | 30 || 000A | 东京 | 0002 | 50 || 000A | 东京 | 0003 | 15 || 000B | 名古屋 | 0002 | 30 || 000B | 名古屋 | 0003 | 120 || 000B | 名古屋 | 0004 | 20 || 000B | 名古屋 | 0006 | 10 || 000B | 名古屋 | 0007 | 40 || 000C | 大阪 | 0003 | 20 || 000C | 大阪 | 0004 | 50 || 000C | 大阪 | 0006 | 90 || 000C | 大阪 | 0007 | 70 || 000D | 福冈 | 0001 | 100 |+---------+-----------+------------+----------+13 rows in set (0.00 sec)-- 取出大阪在售商品的销售单价-- step1:取出大阪门店的在售商品 `product_id`SELECT product_idFROM shopproductWHERE shop_id = '000C';+------------+| product_id |+------------+| 0003 || 0004 || 0006 || 0007 |+------------+4 rows in set (0.00 sec)-- step2:取出大阪门店在售商品的销售单价 `sale_price`SELECT product_name, sale_priceFROM productWHERE product_id IN (SELECT product_idFROM shopproductWHERE shop_id = '000C');+--------------+------------+| product_name | sale_price |+--------------+------------+| 运动T恤 | 4000 || 菜刀 | 3000 || 叉子 | 500 || 擦菜板 | 880 |+--------------+------------+4 rows in set (0.00 sec)-- 子查询展开后的结果SELECT product_name, sale_priceFROM productWHERE product_id IN ('0003', '0004', '0006', '0007');+--------------+------------+| product_name | sale_price |+--------------+------------+| 运动T恤 | 4000 || 菜刀 | 3000 || 叉子 | 500 || 擦菜板 | 880 |+--------------+------------+4 rows in set (0.00 sec)-- not in-- NOT IN 使用子查询作为参数,取出未在大阪门店销售的商品的销售单价SELECT product_name, sale_priceFROM productWHERE product_id NOT IN (SELECT product_idFROM shopproductWHERE shop_id = '000A');+--------------+------------+| product_name | sale_price |+--------------+------------+| 菜刀 | 3000 || 高压锅 | 6800 || 叉子 | 500 || 擦菜板 | 880 || 圆珠笔 | 100 |+--------------+------------+5 rows in set (0.00 sec)
4.5.5EXISTS:判断是否存在满足条件的记录
谓词的作用就是 “判断是否存在满足某种条件的记录”。
如果存在这样的记录就返回真(TRUE),如果不存在就返回假(FALSE)。
EXIST,基本上也都可以使用 IN(或者 NOT IN)来代替
EXIST(存在)谓词的主语是“记录”。
只有1个参数,右侧,通常是一个子查询。
SELECT product_name, sale_priceFROM product AS pWHERE EXISTS (SELECT 1 -- 这里可以书写适当的常数FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id);+--------------+------------+| product_name | sale_price |+--------------+------------+| 运动T恤 | 4000 || 菜刀 | 3000 || 叉子 | 500 || 擦菜板 | 880 |+--------------+------------+4 rows in set (0.00 sec)
用not exist替换not in
SELECT product_name, sale_priceFROM product AS pWHERE NOT EXISTS (SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000A'AND sp.product_id = p.product_id);+--------------+------------+| product_name | sale_price |+--------------+------------+| 菜刀 | 3000 || 高压锅 | 6800 || 叉子 | 500 || 擦菜板 | 880 || 圆珠笔 | 100 |+--------------+------------+5 rows in set (0.00 sec)
4.6case表达式
条件分支。
语法分为简单CASE表达式和搜索CASE表达式两种。
搜索CASE表达式包含简单CASE表达式的全部功能。
依次判断 when 表达式是否为真值,是则执行 THEN 后的语句,如果所有的 when 表达式均为假,则执行 ELSE 后的语句。
无论多么庞大的 CASE 表达式,最后也只会返回一个值。
else可以省略,会认为是else null,但end不能省略。
行转列:
- 当待转换列为数字时,可以使用
SUM AVG MAX MIN等聚合函数; - 当待转换列为文本时,可以使用
MAX MIN等聚合函数 ```sql CASE WHEN <求值表达式> THEN <表达式> WHEN <求值表达式> THEN <表达式> WHEN <求值表达式> THEN <表达式> . . . ELSE <表达式> END
— 应用场景1:根据不同分支得到不同列值 SELECT product_name, CASE WHEN product_type = ‘衣服’ THEN CONCAT(‘A : ‘,product_type) WHEN product_type = ‘办公用品’ THEN CONCAT(‘B : ‘,product_type) WHEN product_type = ‘厨房用具’ THEN CONCAT(‘C : ‘,product_type) ELSE NULL END AS abc_product_type FROM product; +———————+—————————+ | product_name | abc_product_type | +———————+—————————+ | T恤 | A : 衣服 | | 打孔器 | B : 办公用品 | | 运动T恤 | A : 衣服 | | 菜刀 | C : 厨房用具 | | 高压锅 | C : 厨房用具 | | 叉子 | C : 厨房用具 | | 擦菜板 | C : 厨房用具 | | 圆珠笔 | B : 办公用品 | +———————+—————————+ 8 rows in set (0.00 sec)
— 应用场景2:实现列方向上的聚合
SELECT product_type,
SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type;
+———————+—————-+
| product_type | sum_price |
+———————+—————-+
| 衣服 | 5000 |
| 办公用品 | 600 |
| 厨房用具 | 11180 |
+———————+—————-+
3 rows in set (0.00 sec)
— 在列的方向上展示不同种类额聚合值 sum_price_clothes | sum_price_kitchen | sum_price_office —————————+—————————-+————————- 5000 | 11180 | 600
— 对按照商品种类计算出的销售单价合计值进行行列转换 SELECT SUM(CASE WHEN product_type = ‘衣服’ THEN sale_price ELSE 0 END) AS sum_price_clothes, SUM(CASE WHEN product_type = ‘厨房用具’ THEN sale_price ELSE 0 END) AS sum_price_kitchen, SUM(CASE WHEN product_type = ‘办公用品’ THEN sale_price ELSE 0 END) AS sum_price_office FROM product; +—————————-+—————————-+—————————+ | sum_price_clothes | sum_price_kitchen | sum_price_office | +—————————-+—————————-+—————————+ | 5000 | 11180 | 600 | +—————————-+—————————-+—————————+ 1 row in set (0.00 sec)
— CASE WHEN 实现数字列 score 行转列 SELECT name, SUM(CASE WHEN subject = ‘语文’ THEN score ELSE null END) as chinese, SUM(CASE WHEN subject = ‘数学’ THEN score ELSE null END) as math, SUM(CASE WHEN subject = ‘外语’ THEN score ELSE null END) as english FROM score GROUP BY name; +———+————-+———+————-+ | name | chinese | math | english | +———+————-+———+————-+ | 张三 | 93 | 88 | 91 | | 李四 | 87 | 90 | 77 | +———+————-+———+————-+ 2 rows in set (0.00 sec)
— CASE WHEN 实现文本列 subject 行转列 SELECT name, MAX(CASE WHEN subject = ‘语文’ THEN subject ELSE null END) as chinese, MAX(CASE WHEN subject = ‘数学’ THEN subject ELSE null END) as math, MIN(CASE WHEN subject = ‘外语’ THEN subject ELSE null END) as english FROM score GROUP BY name; +———+————-+———+————-+ | name | chinese | math | english | +———+————-+———+————-+ | 张三 | 语文 | 数学 | 外语 | | 李四 | 语文 | 数学 | 外语 | +———+————-+———+————-+ 2 rows in set (0.00 sec
<a name="zk1QV"></a>## 4.7练习题<a name="EDwxt"></a>### 4.7.1运算或者函数中含有 NULL 时,结果全都会变为NULL ?(判断题)<a name="W8KNu"></a>### 4.7.2对本章中使用的 product(商品)表执行如下 2 条 SELECT 语句,能够得到什么样的结果呢?```sql-- 1SELECT product_name, purchase_priceFROM productWHERE purchase_price NOT IN (500, 2800, 5000);-- 2SELECT product_name, purchase_priceFROM productWHERE purchase_price NOT IN (500, 2800, 5000, NULL);
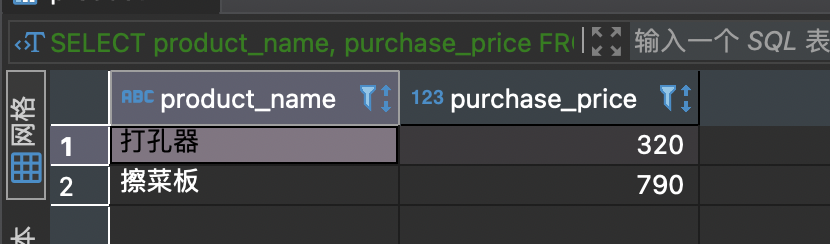
4.7.3
按照销售单价( sale_price)对练习 3.6 中的 product(商品)表中的商品进行如下分类。
- 低档商品:销售单价在1000日元以下(T恤衫、办公用品、叉子、擦菜板、 圆珠笔)
- 中档商品:销售单价在1001日元以上3000日元以下(菜刀)
- 高档商品:销售单价在3001日元以上(运动T恤、高压锅)
请编写出统计上述商品种类中所包含的商品数量的 SELECT 语句,结果如下所示。
执行结果
low_price | mid_price | high_price----------+-----------+------------5 | 1 | 2

若有收获,就点个赞吧
0 人点赞
