5.集合运算
在数据库中, 所有的表—以及查询结果—都可以视为集合。可进行集合运算。
集合运算符:
在标准 SQL 中, 分别对检索结果使用 UNION, INTERSECT, EXCEPT 来将检索结果进行并,交和差运算, 像UNION,INTERSECT, EXCEPT这种用来进行集合运算的运算符称为集合运算符.
交集,并集,差集,补集,对称差集。
5.1表的加法和减法
5.1.1并集(union/union all)
并集:去重汇总。关键字union,连接两个select语句。
可对同一张表或者两张不同的表操作。对同一张表,等同于where…or的使用。
如果结果合并但不去重,用union all 替换union
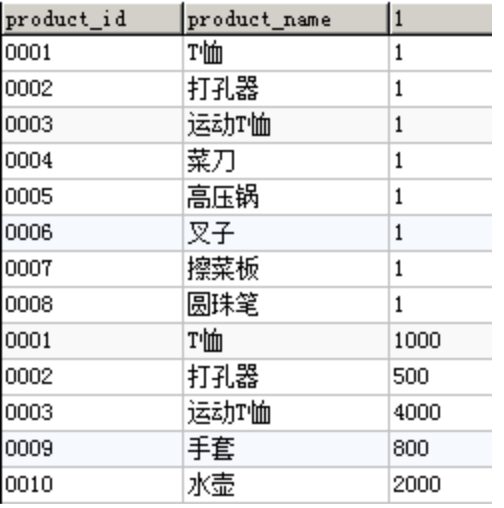
SELECT product_id, product_nameFROM ProductUNIONSELECT product_id, product_nameFROM Product2;-- 使用 OR 谓词SELECT *FROM ProductWHERE sale_price / purchase_price < 1.3OR sale_price / purchase_price IS NULL;-- 使用 UNIONSELECT *FROM ProductWHERE sale_price / purchase_price < 1.3UNIONSELECT *FROM ProductWHERE sale_price / purchase_price IS NULL;-- 保留重复行SELECT product_id, product_nameFROM ProductUNION ALLSELECT product_id, product_nameFROM Product2;-- 隐式类型转换:1既是第三列,也是product表该列的默认值。结果看下面的图。SELECT product_id, product_name, '1'FROM ProductUNIONSELECT product_id, product_name,sale_priceFROM Product2;
测试数据兼容性:
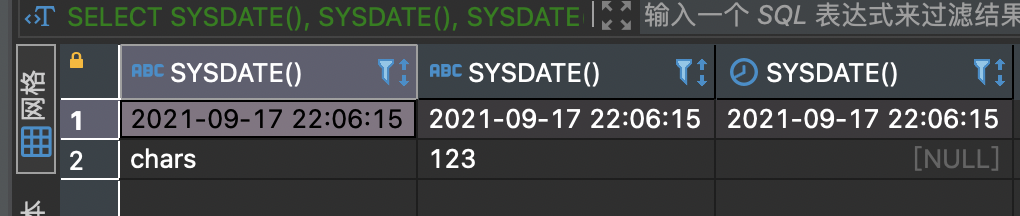
SYSDATE()函数可以返回当前日期时间, 是一个日期时间类型的数据
SELECT SYSDATE(), SYSDATE(), SYSDATE()UNIONSELECT 'chars', 123, null
5.1.2交集(表连结/and)
获得同时存在于两个表的数据。
不支持关键字INTERSECT,但可以用表连结的方式实现交集。
5.1.3差集(not in)
不支持except关键词。用not in 实现。
集合A-集合B,表示存在于A,但不存在于B的数据。即A扣除A和B的交集。
SELECT *FROM ProductWHERE product_id NOT IN (SELECT product_idFROM Product2)-- 使用 NOT IN 实现两个表的差集SELECT *FROM ProductWHERE product_id NOT IN (SELECT product_id FROM Product2)UNIONSELECT *FROM Product2WHERE product_id NOT IN (SELECT product_id FROM Product)
5.1.4对称差集
两个集合A,B的对称差是指那些仅属于A或仅属于B的元素构成的集合
两个集合的交可以看作是两个集合的并去掉两个集合的对称差。
-- 使用 NOT IN 实现两个表的差集SELECT *FROM ProductWHERE product_id NOT IN (SELECT product_id FROM Product2)UNIONSELECT *FROM Product2WHERE product_id NOT IN (SELECT product_id FROM Product)
5.2表的连结
连结(JOIN)就是使用某种关联条件(一般是使用相等判断谓词”=”), 将其他表中的列添加过来, 进行“添加列”的集合运算。
5.2.1内连结(INNER JOIN…on)
使用as表别名可以使语句简洁清晰
on类似于where,限定表连结条件,on里面的条件,最好用表.列的形式,这样易于查看。
-- 语法:FROM <tb_1> INNER JOIN <tb_2> ON <condition(s)>-- 例子:SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.product_type,P.sale_price,SP.quantityFROM ShopProduct AS SPINNER JOIN Product AS PON SP.product_id = P.product_id;-- 4种实现:-- 1SELECT *FROM (-- 第一步查询的结果SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.product_type,P.sale_price,SP.quantityFROM ShopProduct AS SPINNER JOIN Product AS PON SP.product_id = P.product_id) AS STEP1WHERE shop_name = '东京'AND product_type = '衣服' ;-- 2SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.product_type,P.sale_price,SP.quantityFROM ShopProduct AS SPINNER JOIN Product AS PON SP.product_id = P.product_idWHERE SP.shop_name = '东京'AND P.product_type = '衣服' ;-- 3SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.product_type,P.sale_price,SP.quantityFROM ShopProduct AS SPINNER JOIN Product AS PON (SP.product_id = P.product_idAND SP.shop_name = '东京'AND P.product_type = '衣服') ;-- 4SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.product_type,P.sale_price,SP.quantityFROM (-- 子查询 1:从 ShopProduct 表筛选出东京商店的信息SELECT *FROM ShopProductWHERE shop_name = '东京' ) AS SPINNER JOIN -- 子查询 2:从 Product 表筛选出衣服类商品的信息(SELECT *FROM ProductWHERE product_type = '衣服') AS PON SP.product_id = P.product_id;-- 结合group bySELECT SP.shop_id,SP.shop_name,MAX(P.sale_price) AS max_priceFROMshopproduct AS SPINNER JOINproduct AS PON SP.product_id = P.product_idGROUP BY SP.shop_id,SP.shop_name
执行顺序:
FROM 子句->WHERE 子句->SELECT 子句
自然连结
如果连结的两个表,存在公共列,则可以用NATURAL JOIN 替代inner join 且无需on。
这时第一列为公共列,之后的列为两个表的其他列。
SELECT * FROM shopproduct NATURAL JOIN Product;-- 等同于:SELECT SP.product_id,SP.shop_id,SP.shop_name,SP.quantity,P.product_name,P.product_type,P.sale_price,P.purchase_price,P.regist_dateFROM shopproduct AS SPINNER JOIN Product AS PON SP.product_id = P.product_id
内连结可用于实现交集,注意null值。null不能用等号比较,结果不会包括。
SELECT P1.*FROM Product AS P1INNER JOIN Product2 AS P2ON (P1.product_id = P2.product_idAND P1.product_name = P2.product_nameAND P1.product_type = P2.product_typeAND P1.sale_price = P2.sale_priceAND P1.regist_date = P2.regist_date)
5.2.2外连结(outer join)
内连结会丢弃两张表中不满足 ON 条件的行,和内连结相对的就是外连结。
外连结会根据外连结的种类有选择地保留无法匹配到的行.
按照保留的行位于哪张表,外连结有三种形式: 左连结, 右连结和全外连结.
左连结会保存左表中无法按照 ON 子句匹配到的行, 此时对应右表的行均为缺失值;
右连结则会保存右表中无法按照 ON 子句匹配到的行, 此时对应左表的行均为缺失值;
而全外连结则会同时保存两个表中无法按照 ON子句匹配到的行, 相应的另一张表中的行用缺失值填充.
左/右连结
左右连结只是交换两表位置,可只学习一种。
三种外连结的对应语法分别为:
-- 左连结FROM <tb_1> LEFT OUTER JOIN <tb_2> ON <condition(s)>-- 右连结FROM <tb_1> RIGHT OUTER JOIN <tb_2> ON <condition(s)>-- 全外连结FROM <tb_1> FULL OUTER JOIN <tb_2> ON <condition(s)>-- 例子:SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.sale_priceFROM Product AS PLEFT OUTER JOIN ShopProduct AS SPON SP.product_id = P.product_id;-- quantity< 50,但可能存在缺失值SELECT P.product_id,P.product_name,P.sale_price,SP.shop_id,SP.shop_name,SP.quantityFROM Product AS PLEFT OUTER JOIN ShopProduct AS SPON SP.product_id = P.product_idWHERE quantity< 50-- 在WHERE过滤条件中增加 **`OR quantity IS NULL`** 的条件, 便可以得到预期的结果。-- 然而在真实的查询环境中,-- 由于数据量大且数据质量并非设想的那样"干净", 我们并不能容易地意识到缺失值等问题数据的存在-- 利用from>where>select的执行顺序-- 把WHERE子句挪到外连结之前进行: 先写个子查询,-- 用来从ShopProduct表中筛选quantity<50的商品, 然后再把这个子查询和主表连结起来.-- 保留所有的左表prodouct以及右表符合条件的数据SELECT P.product_id,P.product_name,P.sale_price,SP.shop_id,SP.shop_name,SP.quantityFROM Product AS PLEFT OUTER JOIN -- 先筛选quantity<50的商品(SELECT *FROM ShopProductWHERE quantity < 50 ) AS SPON SP.product_id = P.product_id
全外连结(结合左右连结)
mysql不支持,但可以对左连结和右连结的结果进行 UNION 来实现全外连结。
交叉连结(CROSS JOIN 笛卡尔积)
交叉连结是对两张表中的全部记录进行交叉组合,因此结果中的记录数通常是两张表中行数的乘积.本例中,因为 ShopProduct 表存在 13 条记录,Product 表存在 8 条记录,所以结果中就包含了 13 × 8 = 104 条记录.
交叉连结没有应用到实际业务之中的原因有两个.一是其结果没有实用价值,二是由于其结果行数太多,需要花费大量的运算时间和高性能设备的支持.
内连结是交叉连结的一部分,“内”也可以理解为“包含在交叉连结结果中的部分”.相反,外连结的“外”可以理解为“交叉连结结果之外的部分”.
-- 1.使用关键字 CROSS JOIN 显式地进行交叉连结SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.sale_priceFROM ShopProduct AS SPCROSS JOIN Product AS P;--2.使用逗号分隔两个表,并省略 ON 子句SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.sale_priceFROM ShopProduct AS SP , Product AS P;
5.2.3多表连结
通常连结只涉及 2 张表,但有时也会出现必须同时连结 3 张以上的表的情况, 原则上连结表的数量并没有限制.
-- 建表CREATE TABLE InventoryProduct( inventory_id CHAR(4) NOT NULL,product_id CHAR(4) NOT NULL,inventory_quantity INTEGER NOT NULL,PRIMARY KEY (inventory_id, product_id));--- DML:插入数据START TRANSACTION;INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0001', 0);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0002', 120);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0003', 200);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0004', 3);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0005', 0);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0006', 99);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0007', 999);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P001', '0008', 200);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0001', 10);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0002', 25);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0003', 34);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0004', 19);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0005', 99);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0006', 0);INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0007', 0 );INSERT INTO InventoryProduct (inventory_id, product_id, inventory_quantity)VALUES ('P002', '0008', 18);COMMIT;-- 根据上表及 ShopProduct 表和 Product 表, 使用内连接找出每个商店都有那些商品, 每种商品的库存总量分别是多少.SELECT SP.shop_id,SP.shop_name,SP.product_id,P.product_name,P.sale_price,IP.inventory_quantityFROM ShopProduct AS SPINNER JOIN Product AS PON SP.product_id = P.product_idINNER JOIN InventoryProduct AS IPON SP.product_id = IP.product_idWHERE IP.inventory_id = 'P001';-- 外连结SELECT P.product_id,P.product_name,P.sale_price,SP.shop_id,SP.shop_name,IP.inventory_quantityFROM Product AS PLEFT OUTER JOIN ShopProduct AS SPON SP.product_id = P.product_idLEFT OUTER JOIN InventoryProduct AS IPON SP.product_id = IP.product_id
5.3练习题
先找到书本里的数据,
下载链接: https://pan.baidu.com/s/1FOsWKC8Jd-dbSRKFap588Q
提取码: gxzt
创建product2
DROP TABLE IF EXISTS `product2`;CREATE TABLE `product2` (`product_id` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`product_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`product_type` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`sale_price` int DEFAULT NULL,`purchase_price` int DEFAULT NULL,`regist_date` date DEFAULT NULL,PRIMARY KEY (`product_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;/*Data for the table `product2` */insert into `product2`(`product_id`,`product_name`,`product_type`,`sale_price`,`purchase_price`,`regist_date`) values ('0001','T恤','衣服',1000,500,'2009-09-20'),('0002','打孔器','办公用品',500,320,'2009-09-11'),('0003','运动T恤','衣服',4000,2800,NULL),('0009','手套','衣服',800,500,NULL),('0010','水壶','厨房用具',2000,1700,'2009-09-20');
5.3.1
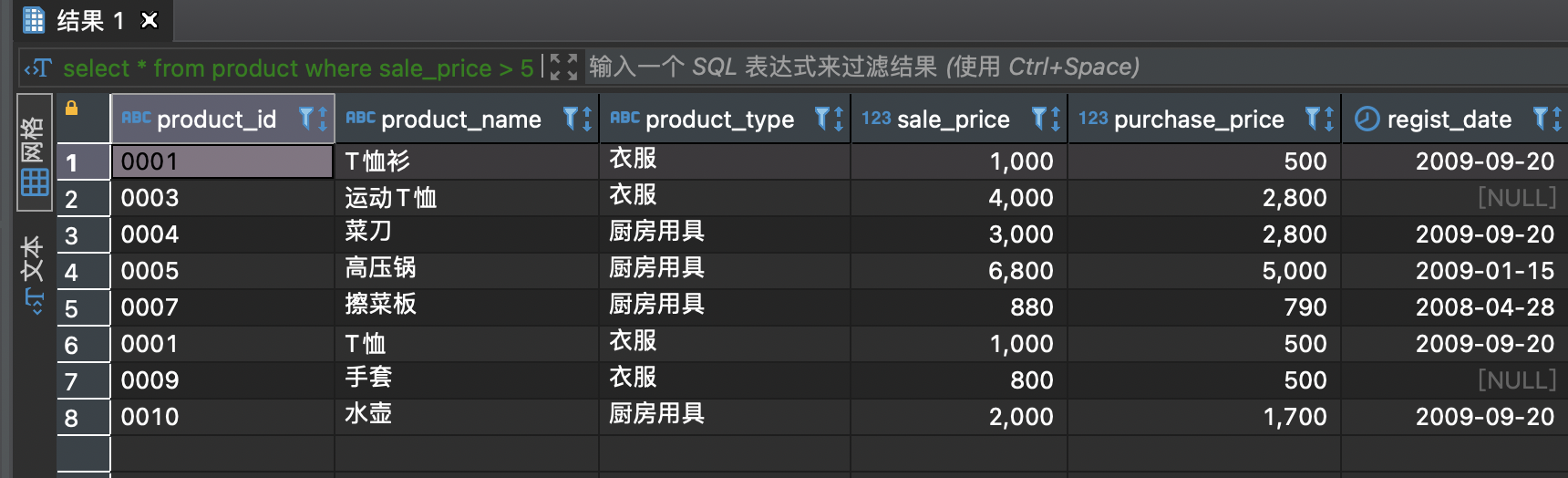
找出 product 和 product2 中售价高于 500 的商品的基本信息。
select * from product where sale_price > 500unionselect * from product2 where sale_price > 500;
5.3.2
借助对称差的实现方式, 求product和product2的交集。
一种比较方便的做法:在product中获取id也在product2的
select * from product where product_id IN (select product_id from product2);

5.3.3
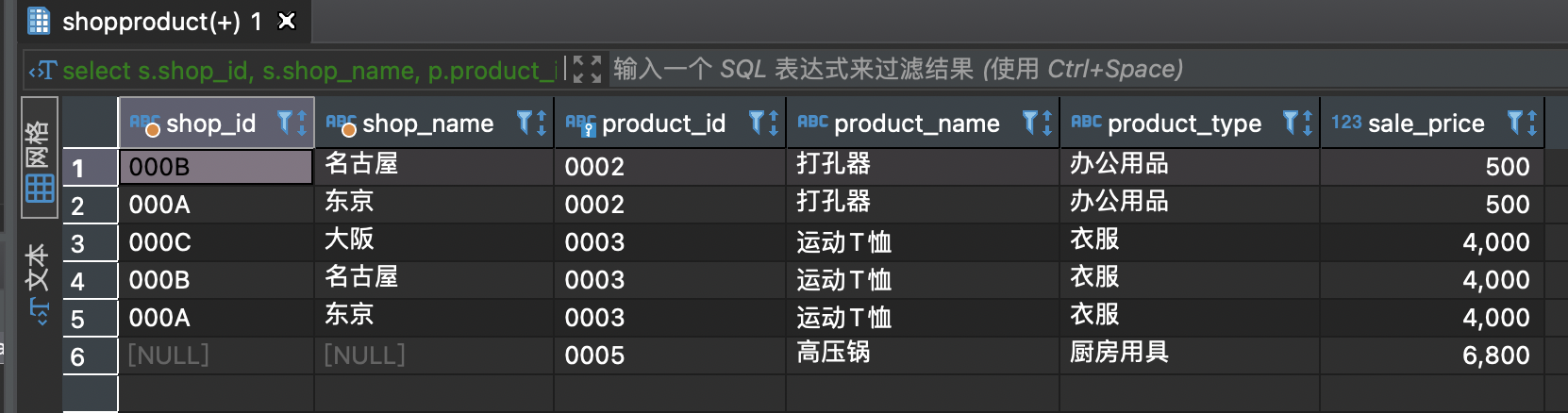
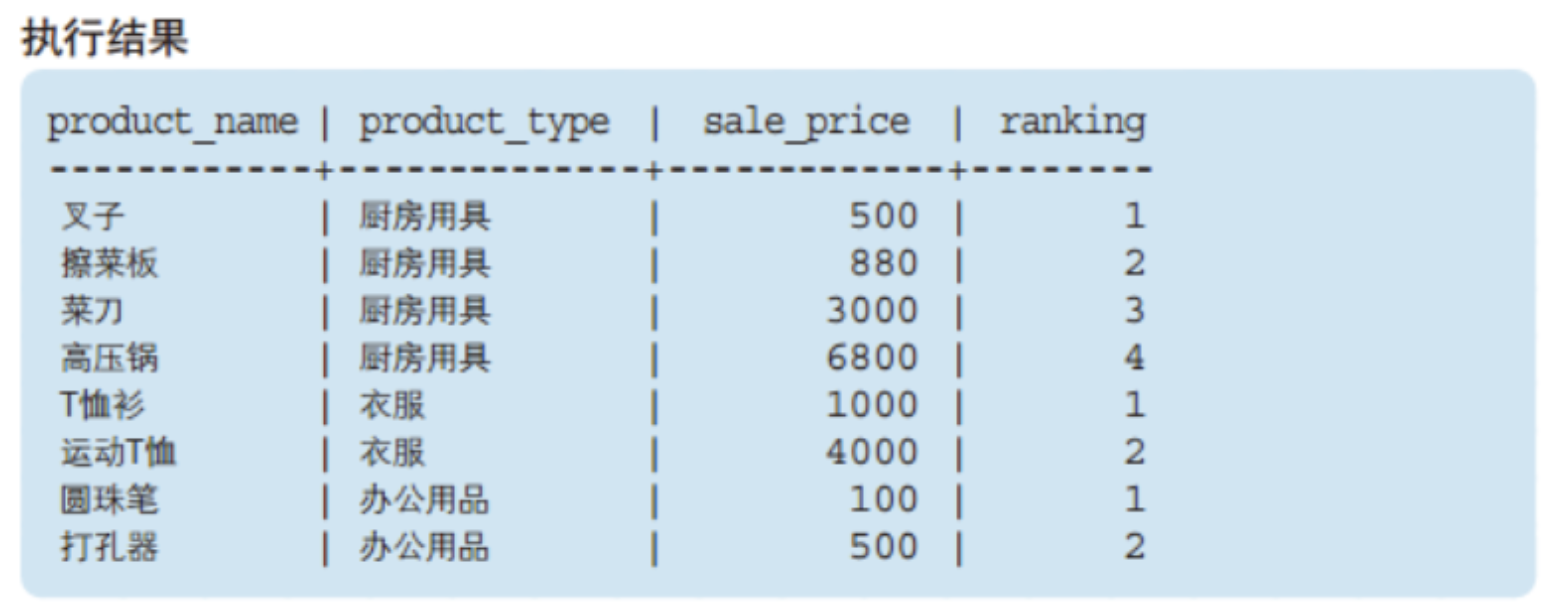
每类商品中售价最高的商品都在哪些商店有售 ?
1.需要导入其他表shopproduct
DROP TABLE IF EXISTS `shopproduct`;CREATE TABLE `shopproduct` (`shop_id` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`shop_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`product_id` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`quantity` int NOT NULL,PRIMARY KEY (`shop_id`,`product_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;/*Data for the table `shopproduct` */insert into `shopproduct`(`shop_id`,`shop_name`,`product_id`,`quantity`) values ('000A','东京','0001',30),('000A','东京','0002',50),('000A','东京','0003',15),('000B','名古屋','0002',30),('000B','名古屋','0003',120),('000B','名古屋','0004',20),('000B','名古屋','0006',10),('000B','名古屋','0007',40),('000C','大阪','0003',20),('000C','大阪','0004',50),('000C','大阪','0006',90),('000C','大阪','0007',70),('000D','福冈','0001',100);
2.
商品: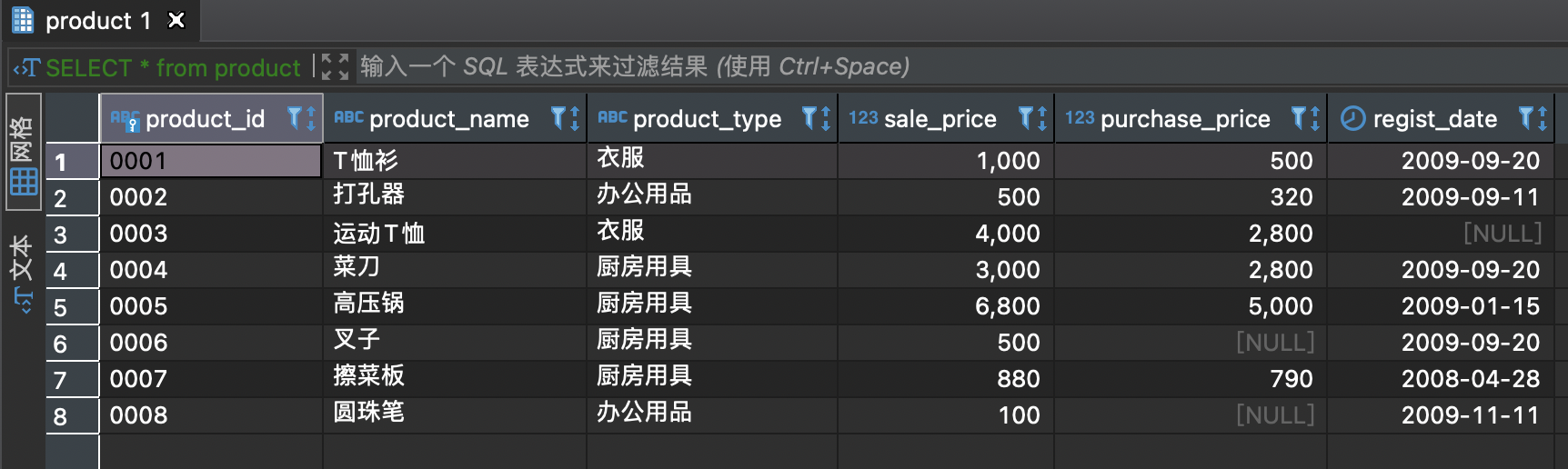
商店: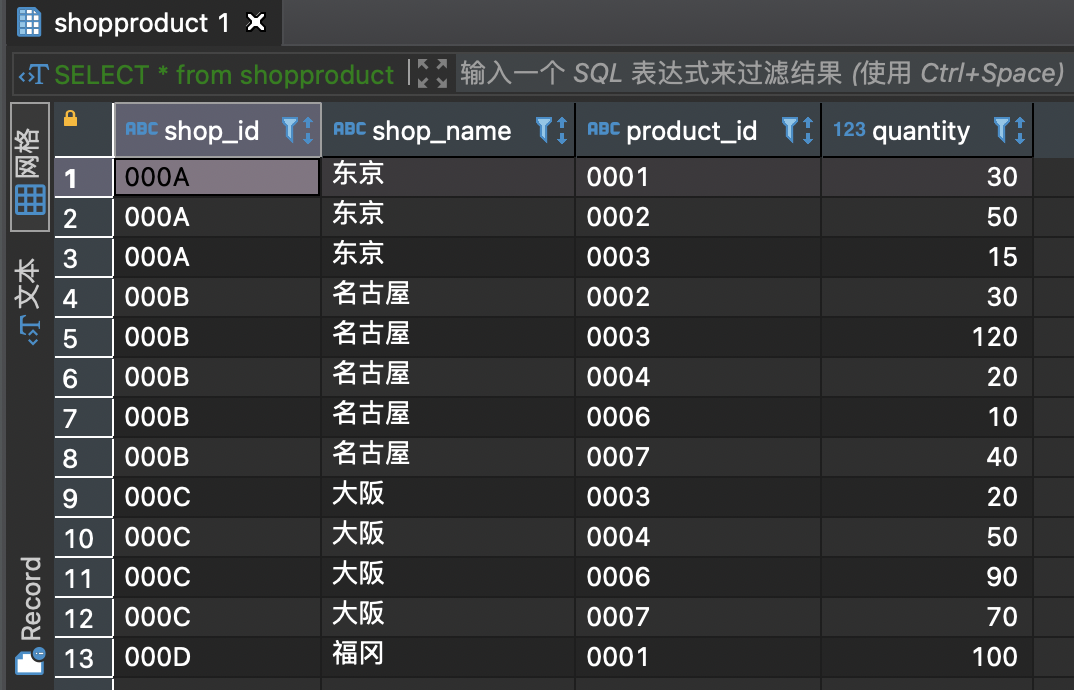
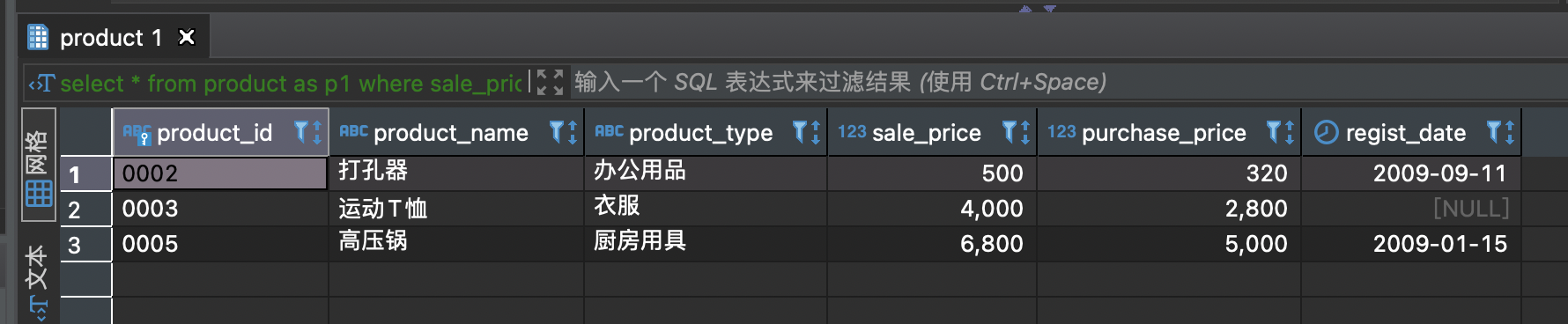
-- 先找到各类商品最高售价的商品select * from product as p1 where sale_price = (SELECT MAX(sale_price) from product as p2where p1.product_type=p2.product_type);
select s.shop_id, s.shop_name, p.product_id, p.product_name, p.product_type, p.sale_pricefrom shopproduct as sinner join product as pon s.product_id = p.product_idwhere p.sale_price in (SELECT max(sale_price) from product as p2 where p.product_type = p2.product_type);
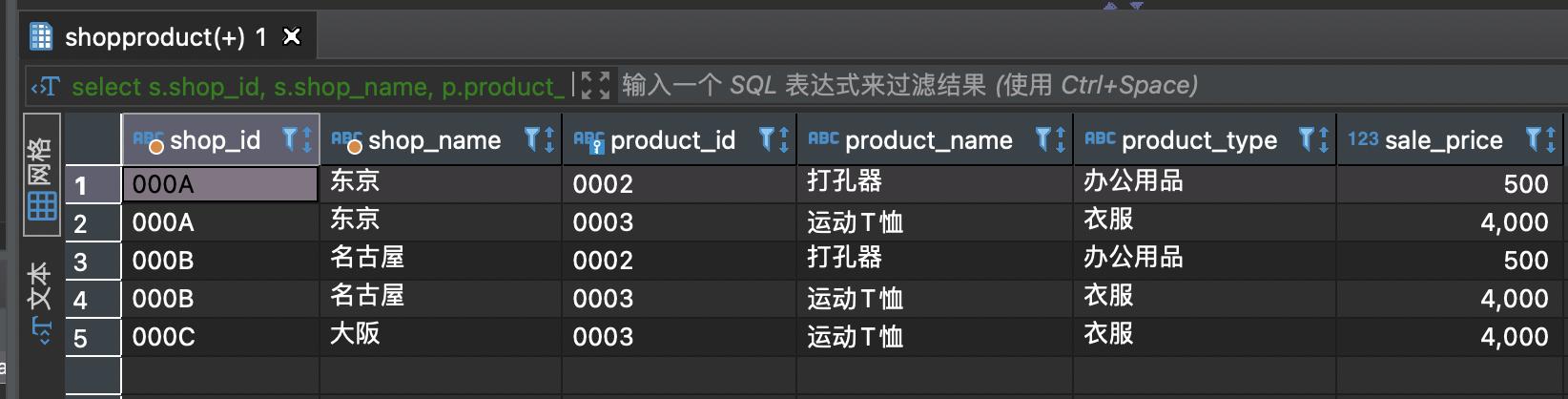
注意高压锅0005不在商品售卖.
用左连结可以明确看出,product写在前面:
select s.shop_id, s.shop_name, p.product_id, p.product_name, p.product_type, p.sale_pricefrom product as pleft outer join shopproduct as son s.product_id = p.product_idwhere p.sale_price in (SELECT max(sale_price) from product as p2 where p.product_type = p2.product_type);
5.3.4
分别使用内连结和关联子查询每一类商品中售价最高的商品。
-- 子查询select * from product as p1 where sale_price = (SELECT MAX(sale_price) from product as p2where p1.product_type=p2.product_type);-- 内连结:自身与(最高价分组)内连结,条件在于自身售价与最高价相同SELECT p.product_id, p.product_name, p.product_type, p.sale_price, p.regist_date, p2.max_pricefrom product as pinner join(-- 这里注意要select product_type,为了后面on的类型比较select product_type, max(sale_price) as max_price from product group by product_type) as p2on p.product_type = p2.product_typewhere p.sale_price = p2.max_price;
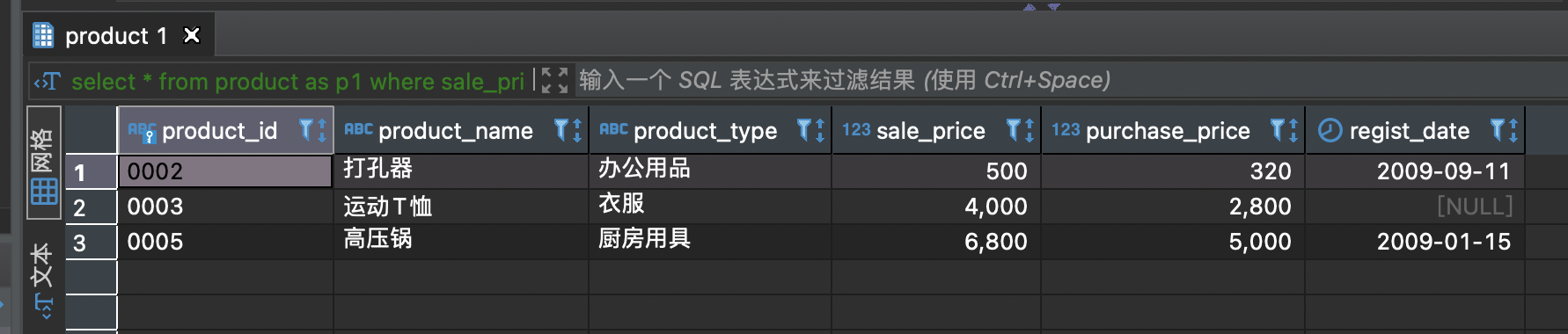

5.3.5
用关联子查询实现:在 product 表中,取出 product_id, produc_name, slae_price, 并按照商品的售价从低到高进行排序、对售价进行累计求和。
解答:先生成一个按照售价高低排序的视图,且生成当前行序号。
之后在视图的基础上用子查询实现累计求和。
注意:
视图的每列内容与as 后select是一一对应的,没对应要删除重新生成。
自定义的列名不能是关键词,比如row.
-- 搞一个视图drop view view_product_sum;create view view_product_sum(line, product_id, product_name, sale_price)asselect ROW_NUMBER() over(order by sale_price asc) as line, product_id, product_name, sale_pricefrom product;select * from view_product_sum;select v.line, v.product_id, v.product_name, v.sale_price,(select sum(sale_price) from view_product_sum as v2 where v2.line <= v.line) as sum_pricefrom view_product_sum as v;
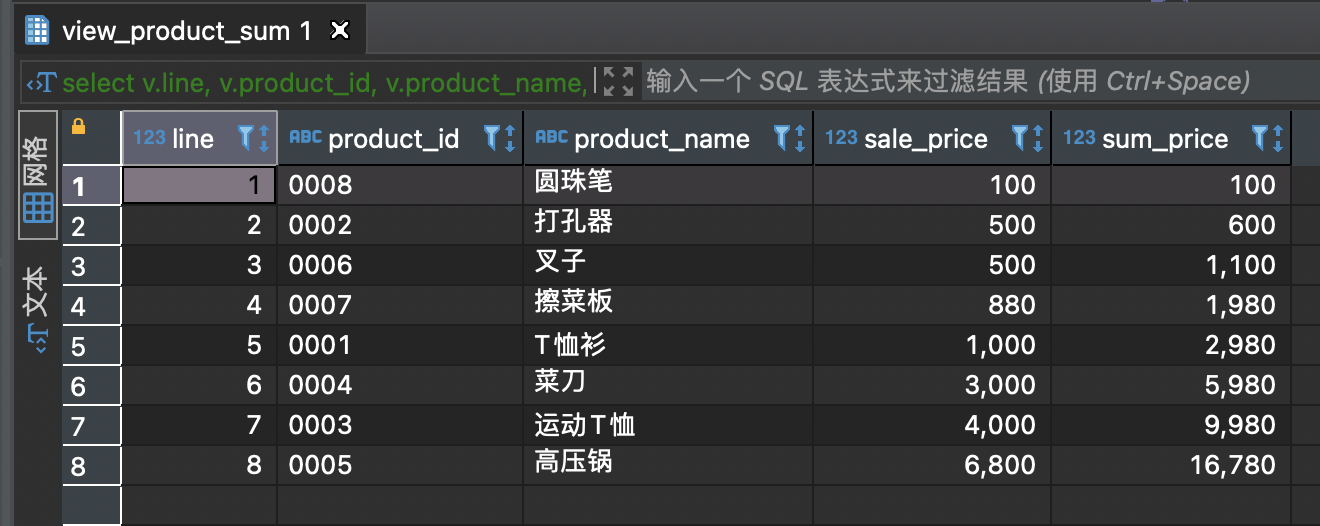
6.高级处理
6.1窗口函数
窗口函数也称为OLAP函数。
OLAP 是OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理。
常规的SELECT语句都是对整张表进行查询,而窗口函数可以让我们有选择的去某一部分数据进行汇总、计算和排序。
- 原则上,窗口函数只能在SELECT子句中使用。
- 窗口函数OVER 中的ORDER BY 子句并不会影响最终结果的排序。其只是用来决定窗口函数按何种顺序计算。
group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。
语法:
PARTITON BY是用来分组,即选择要看哪个窗口,类似于GROUP BY 子句的分组功能,但是PARTITION BY 子句并不具备GROUP BY 子句的汇总功能,并不会改变原始表中记录的行数。
ORDER BY是用来排序,即决定窗口内,是按那种规则(字段)来排序的。
-- []中的内容可以省略<窗口函数> OVER ([PARTITION BY <列名>]ORDER BY <排序用列名>)
SELECT product_name,product_type,sale_price,RANK() OVER (PARTITION BY product_typeORDER BY sale_price) AS rankingFROM product
6.2窗口函数种类
大致来说,窗口函数可以分为两类。
一是 将SUM、MAX、MIN等聚合函数用在窗口函数中
二是 RANK、DENSE_RANK等排序用的专用窗口函数
6.2.1聚合函数在窗口函数的应用
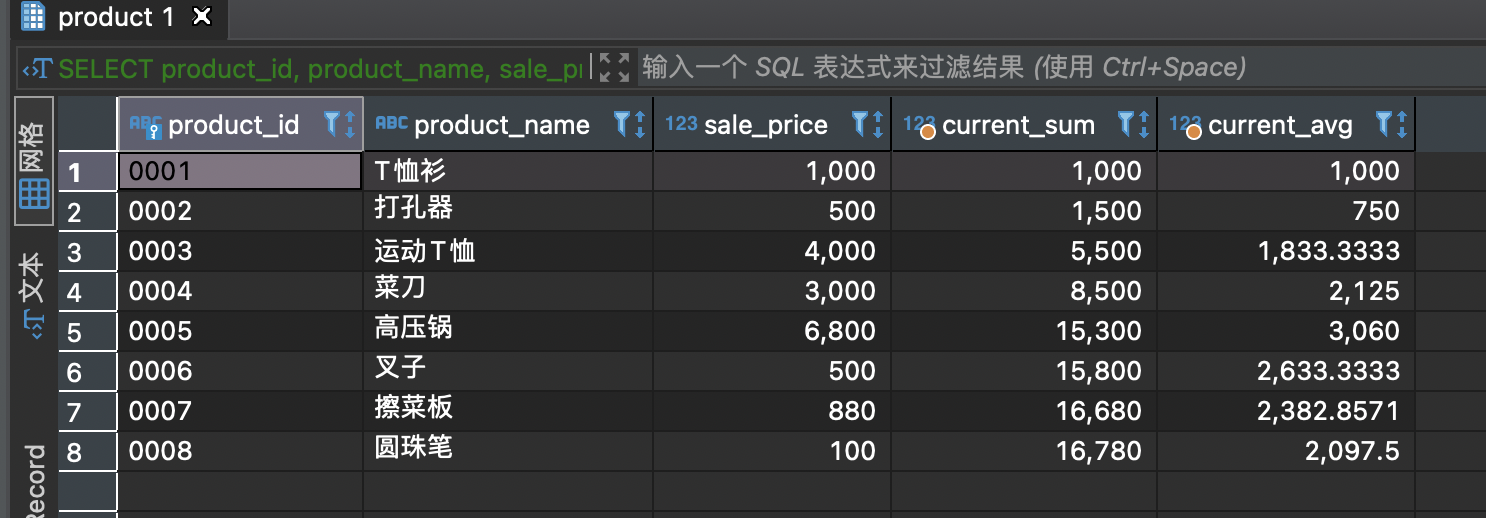
聚合函数在窗口函数使用时,计算的是累积到当前行的所有的数据的聚合。
SELECT product_id,product_name,sale_price,SUM(sale_price) OVER (ORDER BY product_id) AS current_sum,AVG(sale_price) OVER (ORDER BY product_id) AS current_avgFROM product;
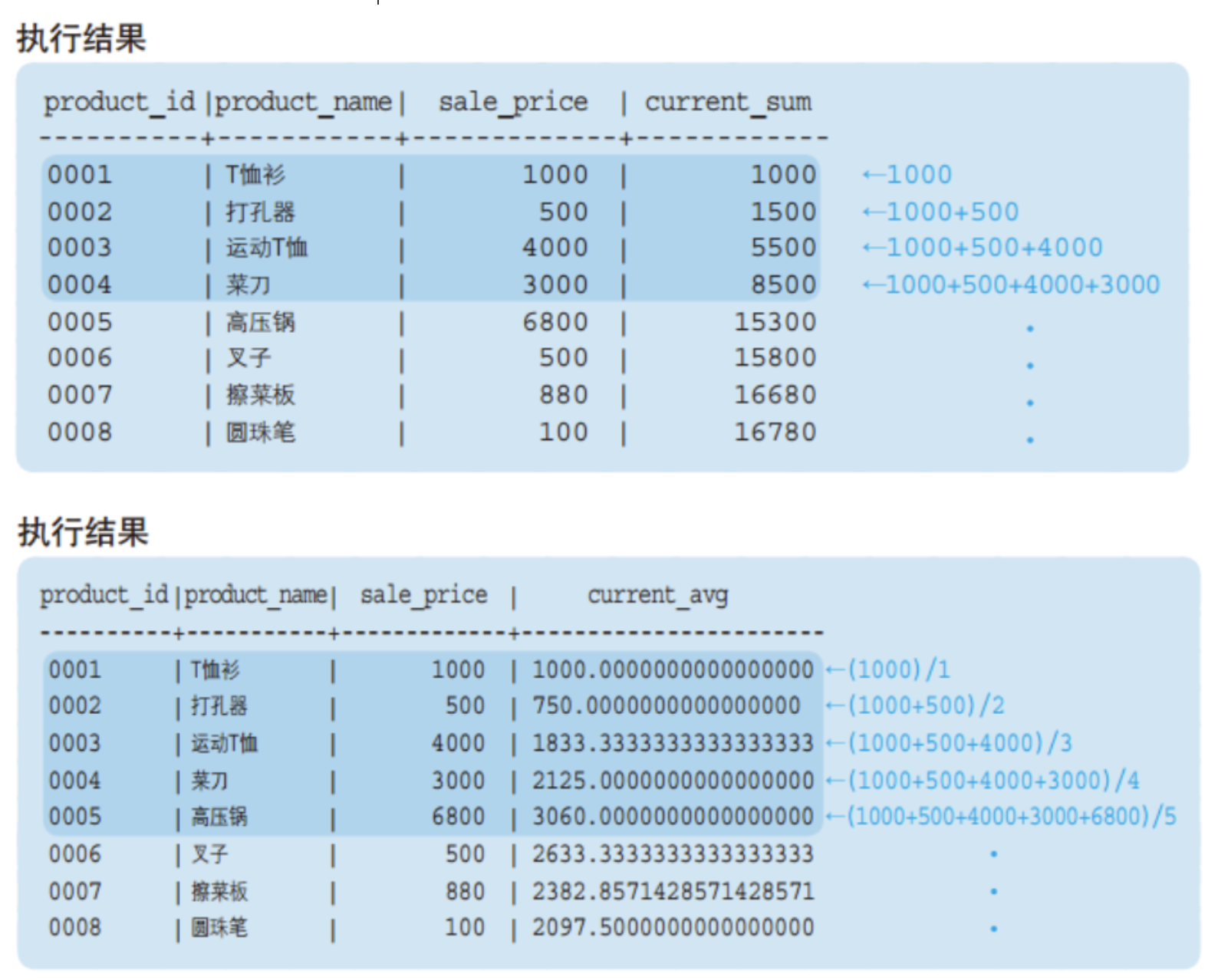 可以看到current_sum是逐行递增,current_avg对应当前行平均。
可以看到current_sum是逐行递增,current_avg对应当前行平均。
6.2.2排序专用窗口函数
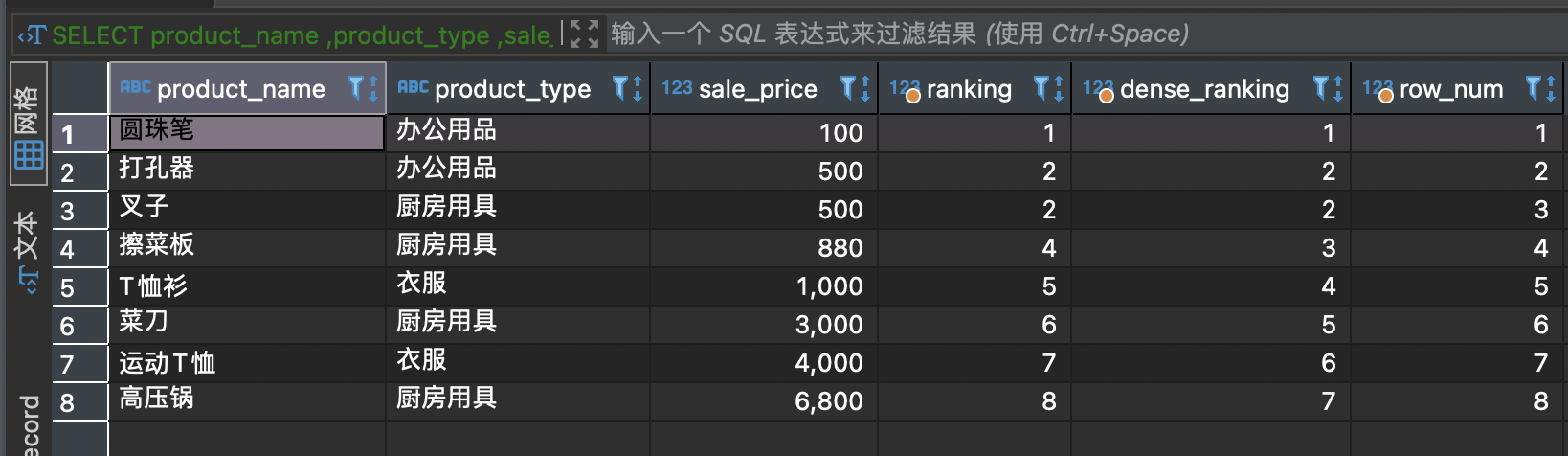
RANK()
计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
DENSE_RANK()
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
ROW_NUMBER()
赋予唯一的连续位次。
例)有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位
SELECT product_name,product_type,sale_price,RANK() OVER (ORDER BY sale_price) AS ranking,DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking,ROW_NUMBER() OVER (ORDER BY sale_price) AS row_numFROM product
6.3窗口函数应用
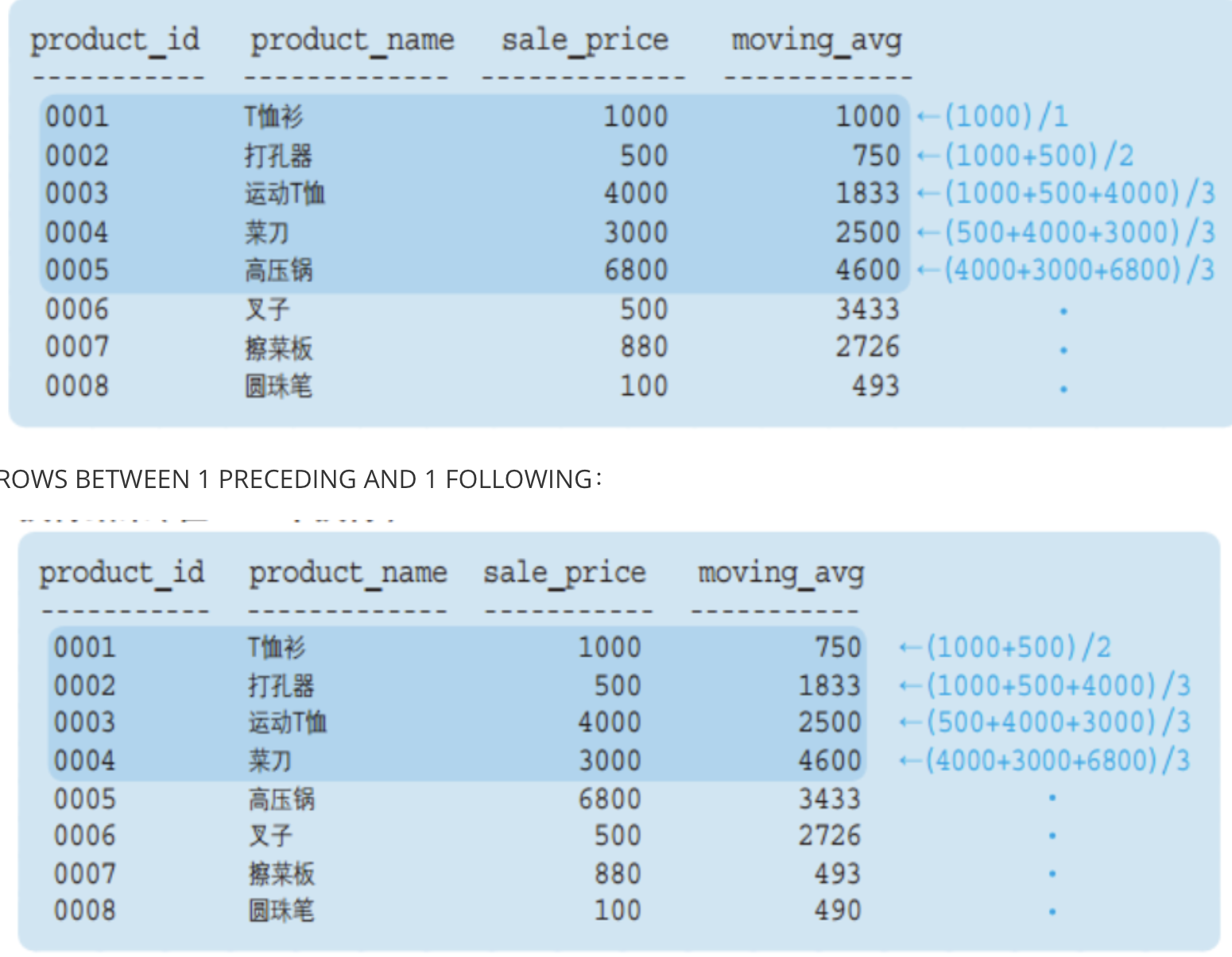
使用聚合函数时,可以指定更加详细的汇总范围。
- PRECEDING(“之前”), 将框架指定为 “截止到之前 n 行”,加上自身行
- FOLLOWING(“之后”), 将框架指定为 “截止到之后 n 行”,加上自身行
- BETWEEN 1 PRECEDING AND 1 FOLLOWING,将框架指定为 “之前1行” + “之后1行” + “自身”
```sql
<窗口函数> OVER (ORDER BY <排序用列名>
ROWS n PRECEDING )
<窗口函数> OVER (ORDER BY <排序用列名> ROWS BETWEEN n PRECEDING AND n FOLLOWING)
```sqlSELECT product_id,product_name,sale_price,AVG(sale_price) OVER (ORDER BY product_idROWS 2 PRECEDING) AS moving_avg1,AVG(sale_price) OVER (ORDER BY product_idROWS BETWEEN 1 PRECEDINGAND 1 FOLLOWING) AS moving_avg2FROM product
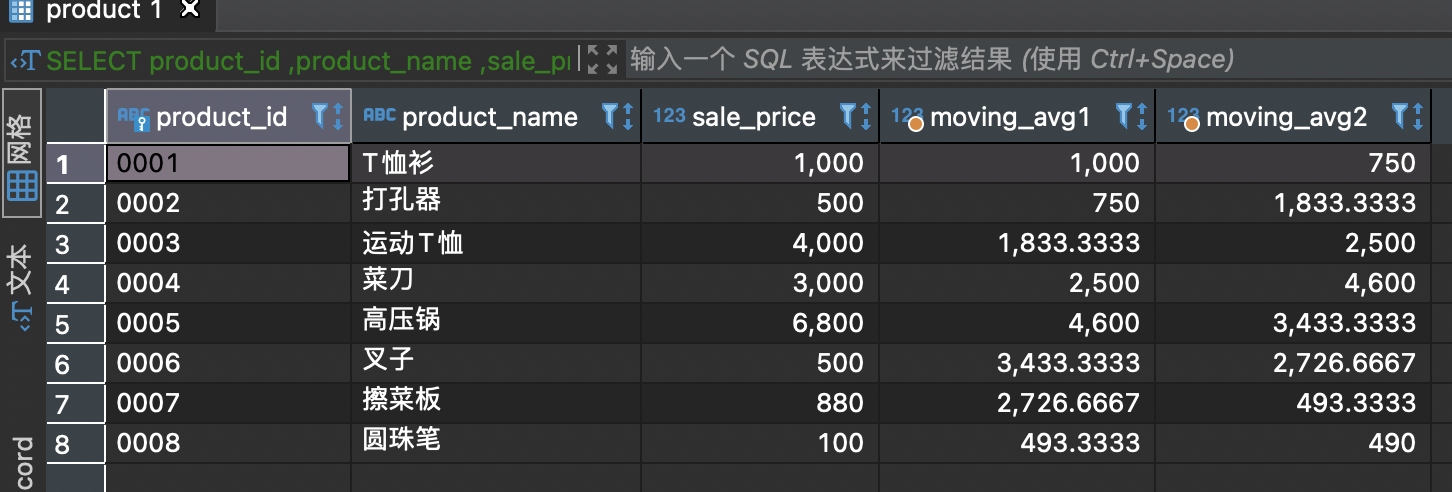
6.4grouping运算符:
常规的GROUP BY 只能得到每个分类的小计,有时候还需要计算分类的合计,可以用 ROLLUP关键字。
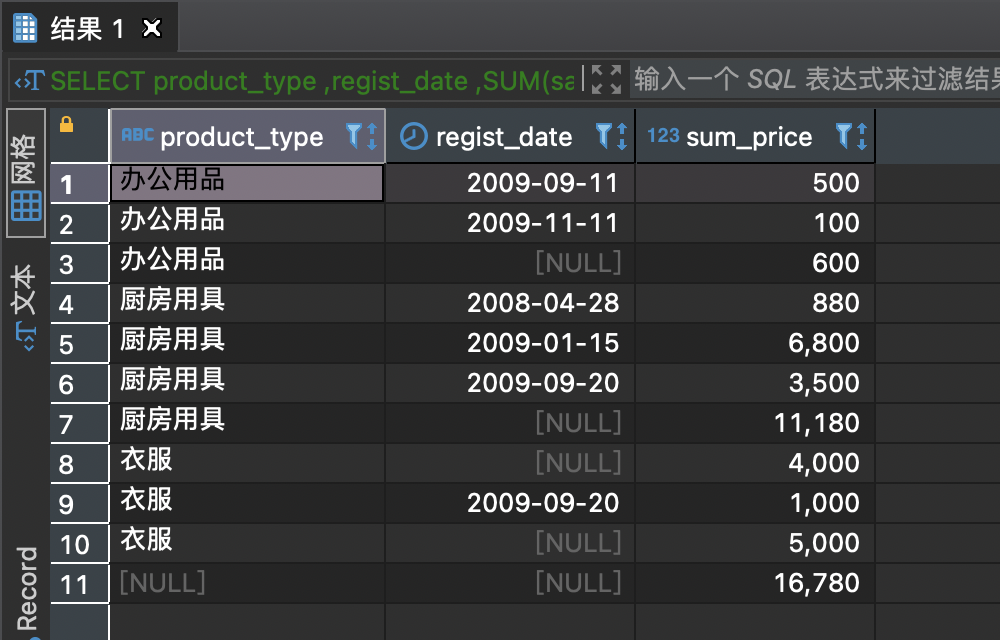
SELECT product_type,regist_date,SUM(sale_price) AS sum_priceFROM productGROUP BY product_type, regist_date WITH ROLLUP
注意每个类别多出一个regist_date为nul的行,该行为对该类别里售价的汇总。
同时,衣服类别里存在regist_date为nul的数据,是源数据,不是汇总。注意区别。
6.3练习题
6.3.1
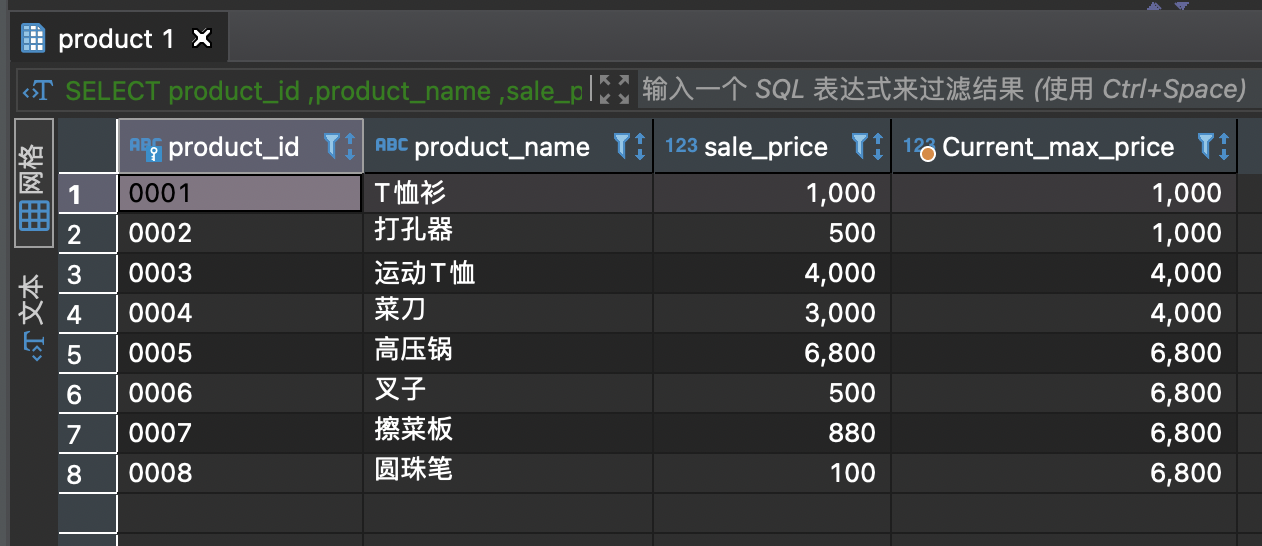
请说出针对本章中使用的 product(商品)表执行如下 SELECT 语句所能得到的结果。
SELECT product_id,product_name,sale_price,MAX(sale_price) OVER (ORDER BY product_id) AS Current_max_priceFROM product
6.3.2
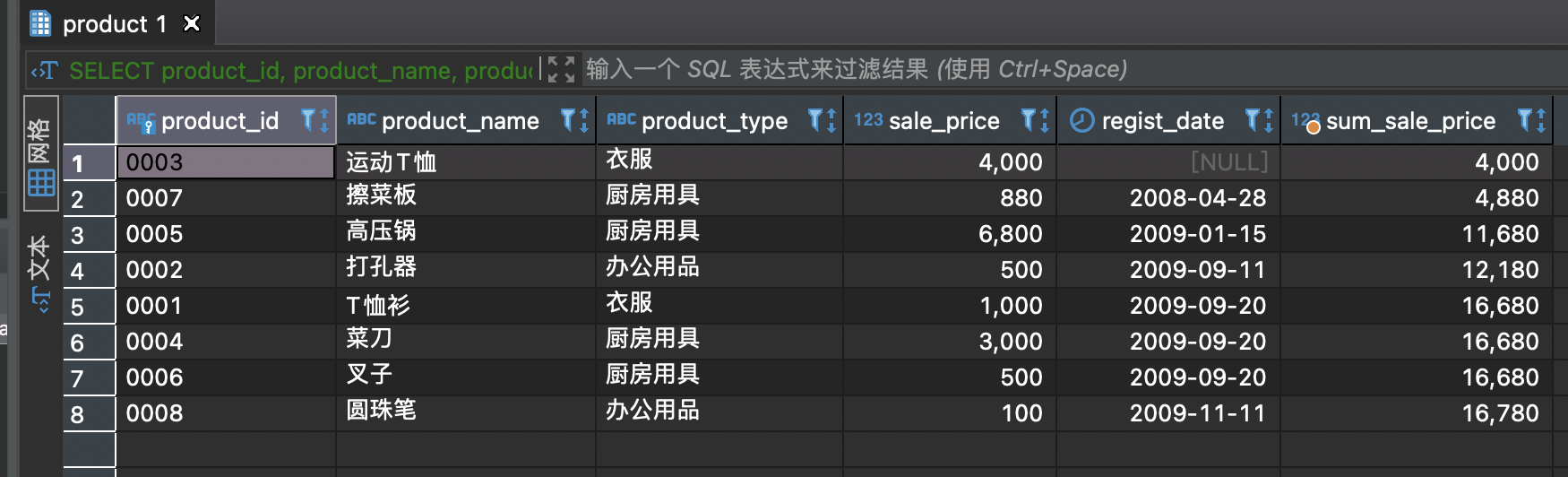
继续使用product表,计算出按照登记日期(regist_date)升序进行排列的各日期的销售单价(sale_price)的总额。排序是需要将登记日期为NULL 的“运动 T 恤”记录排在第 1 位(也就是将其看作比其他日期都早)。
SELECT product_id, product_name, product_type, sale_price, regist_date,sum(sale_price) over (order by regist_date asc) as sum_sale_pricefrom product;
6.3.3
思考题
① 窗口函数不指定PARTITION BY的效果是什么?
② 为什么说窗口函数只能在SELECT子句中使用?实际上,在ORDER BY 子句使用系统并不会报错。
解答:
①: 不分组,仅根据order by里的指定参数进行排序
②:用于order by,是为了什么?不会增加复杂度吗?有用于order by的例子吗?

若有收获,就点个赞吧
0 人点赞
