什么是scrapy 框架?<br />Scrapy是一个为了爬取网站数据, 提取结构性数据而编写的应用框架, 非常出名, 非常强悍, 所谓的框架就是一个已经被集成各种功能 ( 高性能异步下载, 分布式, 解析, 持久化等 )的具有很强通用性的项目模版 。对于框架的学习, 重点是要学习其框架的特性 , 各个功能的用法即可。
安装
linux系统
pip install scrapy
windows系统
# 1pip install whell# 2下载 twisted (scrapy依耐这个模块)https://www.lfd.uci.edu/~gohlke/pythonlibs/#teisted进入下载目录: 复制你下载的文件的名! 如果安装报错 找不到文件, 就使用conda来换切换环境即可pip install Twisted-20.3.0-cp39-cp39-win_amd64.whl# 3pip install pywin32# 4pip install scrapy
安装 whell
pip install whell
安装 twisted
下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#teisted
根据你电脑的python 是3.几的, 就选择 对应的版本, 比如我现在的电脑安装的python是 3.9.7的
那么我就选择 cp39
- Twisted‑20.3.0‑cp39‑cp39‑win_amd64.whl

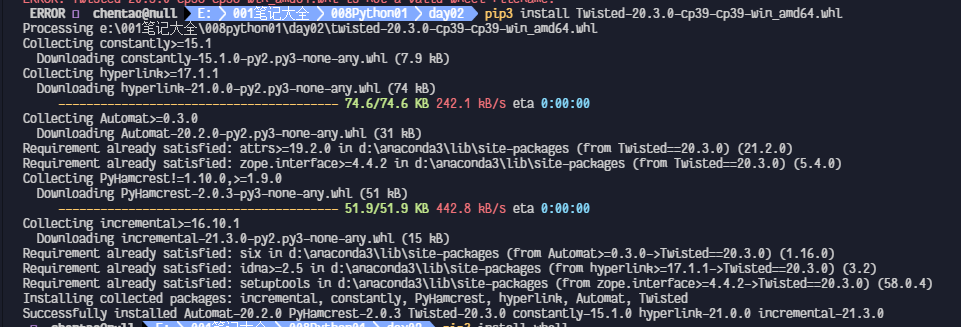
pip install Twisted-20.3.0-cp39-cp39-win_amd64.whl
如果安装报错 找不到文件, 就使用conda来换切换环境即可
安装pywin32
pip install pywin32
安装 Scrapy
pip install scrapy

检测是否安装成功
Scrapy # 按回车, 不报错就表示安装好了

基础使用
工程目录结构
创建项目,scrapy startproject FirstPro # FirstPro 是 项目名称
scrapy startproject FirstPro# cd 到工程目录当中 FirstPro
创建爬虫文件 scrapy genspider
- 爬虫名称: first
- 起始URL: www.xxx.com
scrapy genspider first www.xxx.com

爬虫文件结构
默认会生成这样的一个模版
# first.py 文件import scrapyclass FirstSpider(scrapy.Spider):name = 'first'allowed_domains = ['www.xxx.com']start_urls = ['http://www.xxx.com/']def parse(self, response):pass
- name: #爬虫文件名, 爬虫文件对应的唯一标识
- allowed_domains # 域名限定 , 一般不使用注释掉
- start_urls : # (重点)起始的URL列表 , 列表中存放的URL会被自动的进行get请求发送
start_urls = ‘[https://www.sougou.com/‘,”https://www.baidu.com”] 如果这里有2个域名, 程序会自动发送请求, 无需我手动书写请求
- parse(): 专门用来解析数据, 调用的次数, 取决于start_urls 列表的元素
- response: 请求对应响应的对象
执行工程 scrapy crawl
scrapy crawl first
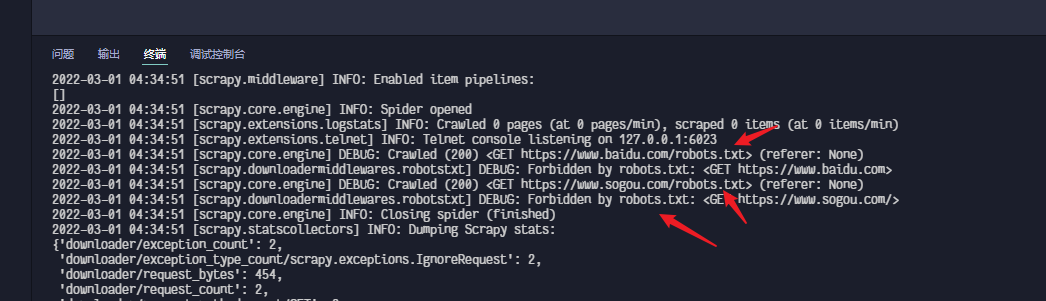
robots.txt反爬虫协议
robots.txt是一种反爬虫协议, 在协议中规定了那些身份的爬虫无法爬取的资源有那些!
我们可以选择遵守协议, 也可以不遵守协议, 可在 爬虫配置文件中修改settings.py**ROBOTSTXT_OBEY=True 改为Flase**

settings.py配置文件详解
- USER_AGENT : 表示全局浏览器UA
- ROBOTSTXT_OBEY : 表示是否遵循反爬虫协议
- LOG_LEVEL=”ERROR” : 表示我只想看报错的日记
- CONCURRENT_REQUESTS =32 :表示手动修改线程数量
- ITEM_PIPELINES :表示开启管道,里面有对应要开启管道的名称
响应数据解析
import scrapyclass FirstSpider(scrapy.Spider):name = 'first'# allowed_domains = ['www.xxx.com']start_urls = ['https://duanzixing.com/page/2/', 'https://duanzixing.com/page/3/']def parse(self, response):# print(response)article_list = response.xpath('/html/body/section/div/div/article')for article in article_list:# 如果selector 调用extract则表述, 将该对象data 属性值取出,返回字符串#title = article.xpath('./header/h2/a/@title')[0].extract()# 如果使用列表调用extract()则表示, extract会将列表中每一个列表元素进行extract操作, 返回列表#title = article.xpath('./header/h2/a/@title').extract()# 数组类型: 取多个内容title = article.xpath('./header/h2/a/@title').extract()# 字符串类型: 只取一个content = article.xpath('./p[2]/text()').extract_first()print(title,content)break;-----------------------------------------家里的猫没看住跑出去了-段子网-最新段子-搞笑段子-微段子-段子网-段子手-段子大全家里的猫没看住跑出去了,了无音讯。两个月后带着孩子回家了。我问它:“带着孩子回来什么意思?”它就只用那亮晶晶的眼睛看着我,我瞬间读懂了它的意思,认祖归宗,让我负责。记得高一的时候暗恋班上一个女生几个月之后-段子网-最新段子-搞笑段子-微段子-段子网-段子手-段子大全记得高一的时候暗恋班上一个女生几个月之后,决定向她表白,但女生以学习为由拒绝了。但我不灰心,知道她喜欢吃甜点,于是我每天都去蛋糕店买点心给她吃,风雨无阻,不管我生病还是有事,从未间断过。终于有一天,她胖到了180斤。...

注意Scrapy是异步多线程
Scrapy是一个异步框架多线程, 异步效果就是由 Twisted实现的
持久化存储
基于终端指令的持久化存储
- 只可以将parse的返回值进行本次文件的持久化存储
- 执行指令:scrapy crawl spiderName -o filePath
scrapy crawl spiderName -o filePath
基于管道持久化存储(重点)
pipelines.py文件里有个方法process_item()
它就是来处理持久化存储的
- 在爬虫文件中进行数据解析
将解析的数据存储封装到item类型的对象中
在`item.py`文件中 接收
将item类型的对象提交管道
直接书写`yield`
yield item #将item对象提交给管道
- 管道接收item然后基于process_item方法进行持久化存储操作
在配置文件中开启管道
ITEM_PIPELINES = {'duanziPro.pipelines.DuanziproPipeline':300,}<br />后面的300数值表示优先级!且数值越小优先级越高

若有收获,就点个赞吧
0 人点赞
