官方文档:https://openpyxl.readthedocs.io/en/stable/ 拓展资料:https://mp.weixin.qq.com/s/Q9EmcBB-r-2b2AW0Qx1Hcw
xlrd和xlwt两者的主要区别在于写入操作,其中xlwt针对Ecxec2007之前的版本,即.xls文件,其要求单个sheet不超过65535行,而openpyxl则主要针对Excel2007之后的版本(.xlsx),它对文件大小没有限制。另外还有区别就是二者在读写速度上的差异,xlrd/xlwt在读写方面的速度都要优于openpyxl,但因为xlwt无法生成xlsx是个硬伤,所以想要尽量提高效率又不影响结果时,可以考虑用xlrd读取,用openpyxl写入。
Excel文件三个对象: workbook: 工作簿,一个excel文件包含多个sheet。 sheet:工作表,一个workbook有多个,表名识别,如“sheet1”,“sheet2”等。 cell: 单元格,存储数据对象 row:行 column:列
openpyxl
简化版
import datetimefrom openpyxl import Workbookwb = Workbook() # 实例化之后后面才可以调用wb# 抓取活跃工作表!ws = wb.active# 修改工作表!ws.title = '2022' # 修改活跃工作表sheet名ws['A1'] = 42ws.append([1, 2, 3])ws['B5'] = datetime.datetime.now()# 保存工作表!wb.save('sample.xlsx') # 这个操作将覆盖已存在的文件,没有任何提示!
完整版
import datetimefrom openpyxl import Workbook, load_workbook, worksheetwb = Workbook() # 实例化# 1.新建工作表(二选一) ——————————————————————wb.create_sheet('2023') # 在后面插入一个新的工作表wb.create_sheet('2021', 0) # 在前面插入一个新的工作表ws = wb.active# 1.打开本地已存在的工作表(二选一) ——————————————————————# wb = load_workbook('openpyxl_note.xlsx') # py和Excel在一个文件夹下给文件名即可# wb = load_workbook('D:\\OneDrive\\Python\\Tomato\\openpyxl_note.xlsx') # 地址是双斜线\\# 2.打印工作表名称(可选) —————————————————————print(wb.sheetnames) # 打印出表单名结果是字典,结果是 ['2021', 'Sheet', '2023']for sheet in wb:print(sheet.title) # 遍历后打印出表单名,结果是列表形式展现(竖向)# 3.根据打印的列表定位(选择要操作的)工作表 ——————————————————————# 如果不定位工作表,会以激活(打开后显示的)的工作表写入ws = wb.active # 激活活跃工作表,打开文档后显示的ws['A5'] = 2099 # 赋值# 修改列表名ws0 = wb["Sheet"] # 找到Sheet列表ws0.title = '2022' # 修改Sheet列表名称# 插入当前时间ws1 = wb["2021"] # 通过列表名来定位ws1['A1'] = datetime.datetime.now() # 写入当前时间ws1.append([1, 2, 3, 4, 5, 6, 7, 8, 9])# 这种方式不能用了# ws2 = wb.get_sheet_by_name('2021') # 这种调用方式已过时,不能用了# ws2['A1'] = '1024'# 赋值ws3 = wb.worksheets[1] # 通过序号来定位ws3['B1'] = '我是第二个工作表' # 赋值# 在下方空白区域添加一行,数据从左到右依次填入ws4 = wb.worksheets[1] # 通过序号来定位ws4.append([1, 3, 5, 7])ws4.append([2, 4, 6, 8])ws4.append([0.2, 0.8, 0.3, 0.7])# 4.定位(选择要操作的)单元格 ——————————————————————print('【遍历,A列】')for cell in ws4["A"]:print(cell.value)print('【遍历,第一行】')for cell in ws4["1"]:print(cell.value)print('【遍历,多列】')for cell in ws4["A1:A3"]: # 使用切片获取,得到一个列表print(cell[0].value) # 打印单元格的值,这里打印的是元组,所以要先获取元组再取值(竖向)print('【遍历,多行】')for row in ws4['1:3']:for cell in row:print(cell.value) # 结果一行一行,一个一个展示# ______________________________________________print('【遍历,所有行】')for row in ws4.rows: # 循环获取ws4表下的行数据for cell in row: # 循环获取单元格数据print(cell.value, end=',') # 取值到空为止(横向),如果数据少于10行,默认取10行,按照表格里的位置打印出来print()print('【遍历,所有列】') # A1 A2 A3这样的顺序(返回的列都是元组,所以需要取两次)for column in ws4.columns: # 循环获取ws4表下的列数据for cell in column: # 循环获取单元格数据print(cell.value, end=',') # 取值到空为止(纵向),如果数据少于10行,默认取10行print()# ______________________________________________print('【指定行,从第3行到第5行】') # 返回的列都是元组,所以需要取两次for row in ws4.iter_rows(min_row=3, max_row=5):for cell in row:print(cell.value, end=',') # 按照表格里的位置打印出来print()print('【指定列,从第3列到第4列】')for column in ws4.iter_cols(min_col=3, max_col=4):for i in column:print(i.value, end=',') # 如果数据少于10行,默认取10行print()print('【指定列与列,从第3行到第5行,从第2列到第4列】')for row in ws4.iter_rows(min_row=3, max_row=5, min_col=2, max_col=4):for cell in row:print(cell.value, end=',') # 按照表格里的位置打印出来print()# 5.保存 ——————————————————————wb.save('openpyxl_note.xlsx') # 注意!!!这个操作将覆盖已存在的文件,没有任何提示!
内容去重
从Excel表中可以看到有两条重复记录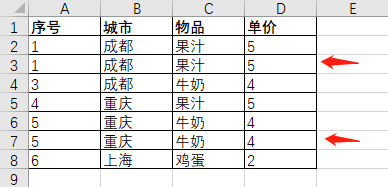
import pandas as pdfrom openpyxl import Workbook, load_workbook, worksheet # 表格处理wb = Workbook() # 实例化# 读取Excel中Sheet1中的数据data = pd.DataFrame(pd.read_excel('D:\\OneDrive\\Python\\Tomato\\delete_cols.xlsx', 'Sheet1'))# 查看读取数据内容# print(data) # 可以不打印出来,打印出来是写代码时候要看数据准确性,下面同理# 查看是否有重复行,Ture表示有重复(删除的数据),False为没有(也是最终保留的数据)re_row = data.duplicated()# print(re_row)# 查看去除重复行的数据,存储要去除的数据(上面为Ture的数据)no_re_row = data.drop_duplicates()# print(no_re_row)# 查看基于[物品]列去除重复行的数据wp = data.drop_duplicates(['物品'])print(wp) # 打印去重后表格的内容# 将去除重复行后的数据输出到excel表中no_re_row.to_excel('D:\\OneDrive\\Python\\Tomato\\delete_cols.xlsx', 'Sheet1')# 因为去重时候多加了一列序号,我们把它删除并保存 _______________wb = load_workbook('D:\\OneDrive\\Python\\Tomato\\Tomato.xlsx') # 打开表格worksheet = wb.worksheets[0] # 找到第一个工作表worksheet.delete_cols(1) # 删除表格的第一列,这里的值是从1开始而不是0,行是rows,列是colswb.save('D:\\OneDrive\\Python\\Tomato\\Tomato.xlsx') # 保存后样式会重置
输出结果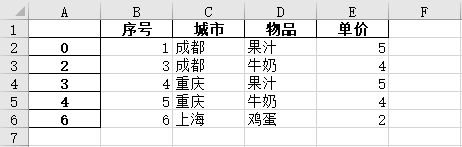
表格 - 样式修改
官方文档:https://openpyxl.readthedocs.io/en/stable/styles.html
一共有六种属性:
- font(字体类):字号、字体颜色、下划线等
- fill(填充类):颜色等
- border(边框类):设置单元格边框
- alignment(位置类):对齐方式
- number_format(格式类):数据格式
- protection(保护类):写保护
font(字体类)
# 单格 字体 修改 ______________________________________from openpyxl.styles import Font # 导入包font = Font(u'宋体',size = 11,bold=True,italic=True,strike=True,color='000000') #定义样式ws['A1'].font = font # 应用样式# 指定列 修改 ______________________________________font = Font(color="b74022", bold=True)for x in ws['A':'B']: # 遍历A列到B列所有数据,注意列是字母(字符串),所以带引号# 也可以是 ['A1':'D5'],这样遍历的就是区间范围,而不是单独的行和列for cell in x:cell.font = font# 指定行 修改 ______________________________________font = Font(color="217346", bold=True)for y in ws[1:2]: # 遍历第1行到第2行的所有数据for cell in y:cell.font = font
size=11, 字体 color=’FF0000’ 色值不需要带# color=colors.WHITE, 字体颜色必须大写 bold=True, 加粗 italic=True, 斜体 strike=True,删除线 vertAlign=None, 垂直对齐 underline=’none’, #下划线
fill(填充类)
# 单格 背景 修改 ______________________________________from openpyxl.styles import PatternFill # 导入包fill = PatternFill("solid", "b7472a")ws['B1'].fill = fill # 应用样式#多行多列的用法和font一样,只是把font改为fill
注意,官方文档中写明,fill_type若没有特别指定类型,则后续的参数都无效
border(边框类)
from openpyxl.styles import Border,Side # 注意隔离是导入两个包border = Border(left=Side(border_style='thin',color='000000'), #定义四个方向的边框样式right=Side(border_style='thin',color='000000'),top=Side(border_style='thin',color='000000'),bottom=Side(border_style='thin',color='000000'))ws['C1'].border = border #应用样式
alignment(位置类)
from openpyxl.styles import Alignment # 导入包align = Alignment(horizontal='left',vertical='center',wrap_text=True) # 定义样式ws['D1'].alignment = align # 应用样式
horizontal 水平对齐,可以左对齐left,还有居中center和右对齐right,分散对齐distributed,跨列居中centerContinuous,两端对齐justify,填充fill,常规general
vertical 垂直对齐,可以居中center,还可以靠上top,靠下bottom,两端对齐justify,分散对齐distributed
wrap_text 自动换行,这是个布尔类型的参数,这个参数还可以写作wrapText
indent=0 缩进。
number_format(格式类)
数据格式属性number_format的值是字符串类型,不为对象,直接赋值即可。
openpyxl内置了一些数据格式查看 openpyxl.styles.numbers,也支持excel自定义格式,以下两种方式效果相同:
# 使用openpyxl内置的格式from openpyxl.styles import numbersws.cell['D2'].number_format = numbers.FORMAT_GENERALws.cell(row=2, column=4).number_format = numbers.FORMAT_DATE_XLSX15# 直接使用字符串修改D2ws.cell['D2'].number_format = 'General'ws.cell(row=2, column=4).number_format = 'd-mmm-yy'
protection(保护类)
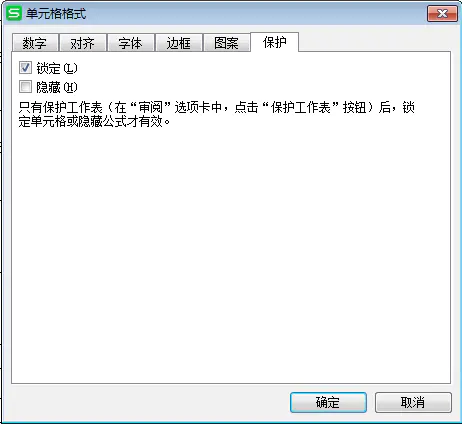
from openpyxl.styles import Protection # 导入包protection = Protection(locked=True,hidden = True)
上面的代码,相当于开启了下图的选项。
拆分合并
merge_cells()工作表方法,可以将一个矩形区域中的单元格合并为一个单 元格。在交互式环境中输入以下代码:
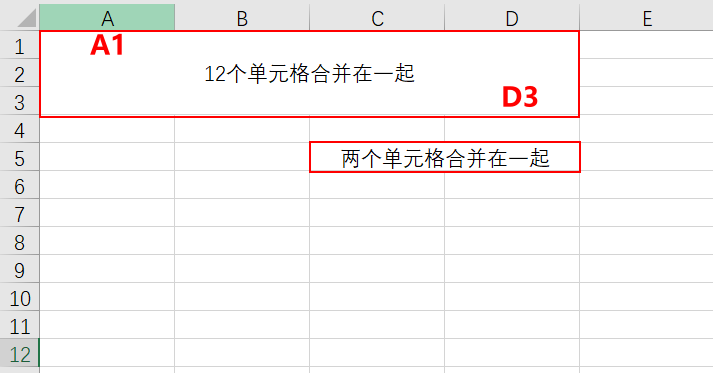
import openpyxlwb = openpyxl.Workbook()sheet = wb.activesheet.merge_cells('A1:D3')sheet['A1'] = '12个单元格合并在一起'sheet.merge_cells('C5:D5')sheet['C5'] = '两个单元格合并在一起'wb.save('merged.xlsx')
要拆分单元格,就调用 unmerge_cells()工作表方法。在交互式环境中输入以下 代码:
import openpyxlwb = openpyxl.load_workbook('merged.xlsx')sheet = wb.get_active_sheet()sheet.unmerge_cells('A1:D3') #拆分为独立单元格sheet.unmerge_cells('C5:D5') #拆分为独立单元格wb.save('merged.xlsx')
冻结窗口
对于太大而不能一屏显示的电子表格,“冻结”顶部的几行或最左边的几列,是 很有帮助的。例如,冻结的列或行表头,就算用户滚动电子表格,也是始终可见的。 这称为“冻结窗格”。

注意看:冻结的都是设置的单元格向上和向左移动一格的区域。
A2左边没有列,上面有一行,所以冻结第一行; C2左边有列A和列B,上面有一行,所以冻结列A、列B和行1
>>> import openpyxl>>> wb = openpyxl.load_workbook('produceSales.xlsx')>>> sheet = wb.active>>> sheet.freeze_panes = 'A2'>>> wb.save('freezeExample.xlsx')
表格 - 设置宽高;
设置单行和一列的长和宽:
from openpyxl import load_workbookwb = load_workbook('test.xlsx') #加载文档ws = wb[wb.sheetnames[0]] #选择第一个工作表并定义为ws,后面就直接引用ws,就说明是这个工作表# 调整A列的宽ws.column_dimensions['A'].width = 20.0# 调整第1行的高ws.row_dimensions[1].height = 40wb.save('test.xlsx')
设置所有行和全部列的长和宽
from openpyxl import load_workbookfrom openpyxl.utils import get_column_letterwb = load_workbook('test.xlsx')print(wb.sheetnames)ws = wb[wb.sheetnames[0]]width = 2.0height = width * (2.2862 / 0.3612)print("row:", ws.max_row, "column:", ws.max_column)for i in range(1, ws.max_row+1):ws.row_dimensions[i].height = heightfor i in range(1, ws.max_column+1):ws.column_dimensions[get_column_letter(i)].width = widthwb.save('test.xlsx')
修改某一列的时间格式

若有收获,就点个赞吧
0 人点赞
