这是我见过把函数讲的最干脆的课(波波课堂):https://www.bilibili.com/video/BV1At411s7q1
函数是减少代码冗余和增加代码复用的有效手段,它是一段具有特定功能的代码块。函数是python这个程序里面,规定好的,是我们可以直接拿来用的,比如 print() 表示打印,input表示输入,len()表示获取列表长度,type()表示获取数据类型等等,他们后面都跟着一个括号,括号里面的东西叫参数,是如何处理数据的方法。
定义函数
语法是这样的:
def 函数名(参数1,参数2,参数3...):函数体return 语句
def的意思是定义(define),函数和参数都是自定义的,参数可以是一个,也可以是多个。下一行开始缩进是函数要实现的功能,也叫【函数体】。
调用函数(模块)
我们把两个py文件之间相互调用对方的函数称为模块;这里我们先自定义一个函数,之后引用它。
新建一个文件,名为 func.py,输入一下代码
def add(x, y):return x+y
再新建另外一个文件(必须在同一个目录下)来进行调用,有两种导入方式,对应两种使用方法,看例子: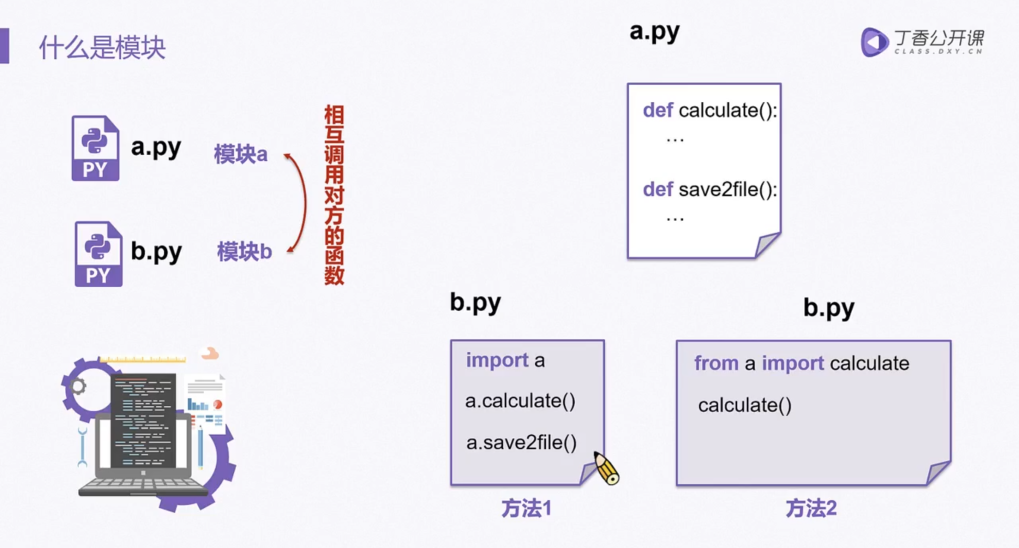
引用方式一(推荐):import …
import func as fc # 导入模块并重命名print(fc.add(2, 3)) # 结果5 使用模块func的add方法
引用方式二:from … import …
from func import add # 导入模块里的方法print(add(1, 2)) # 结果3 直接使用add方法from func import * # 使用星号表示,不指定固定的方法,使用方式和上面一样(容易重名不建议使用)。print(add(2, 2)) # 结果4
那么你可能会问,我们自定义的函数和系统自带的abs函数有什么区别呢?区别在于当你传参数错误的时候,自带的会告诉我们哪里错误,而你自定义的就不会正确的报错。当然也可以isinstance()来检查,想了解更多,可以看这篇文章:http://mrw.so/5yUpus
声明函数
在Python里,输入函数名和参数对应的值,并打印出来。函数可以同时返回多个值,但其实是一个tuple(元组)。
# 一个参数赋值调用def nihao(name):print(name+'早上好')nihao('富贵')# 两个参数赋值调用def nihao(name, grade):print(name+'的成绩是'+grade)nihao('三丰', '80')nihao('富贵', '98') # 需要都是字符串
弄清楚这个函数有多少个参数,如何给参数赋值,这个过程在函数里叫做参数的【传递(pass)】。
函数的定义和调用就这些,这些都只是小试牛刀,函数的作用远不止于此。它能将复杂的语句和功能统一封装进一个函数名里,调用者只需明白函数能实现什么,根据需要传递参数即可。
下面三个函数,第一种是调用外部变量;第二种是给参数打印出来后赋值;第三种是返回参数,最后打印时候赋值。
def shuoming(a):'''我是函数的说明,可以单行也可以多行'''print(a) # 打印shuoming(10) # 传参def abc(b):'我是横线,数字是几,就打印几个'b = b * '-'print(b) # 打印abc(5) # 传参并打印def abc(c):'里面返回,外面传参并打印'c += 20return c # 返回(不打印)print(abc(10)) # 传参并打印
小提示:def 下面注释的作用主要关于该函数的说明,当别人调用该函数时,会有提示,很有用。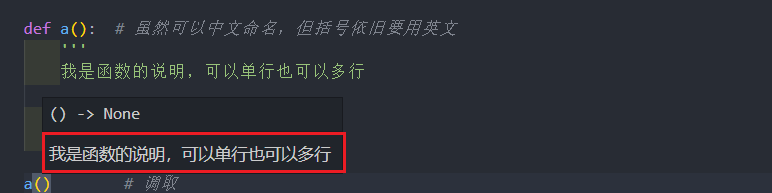
参数类型
主要的参数类型有:位置参数、默认参数、不定长参数,还有一个比较特殊,是可变关键词参数。
1.顺序(位置)参数
我们之前见过,就是上个例子的顺序传递。位置传递有两种写法,一种是写进函数括号里,一种是直接赋值,不用考虑顺序。
def nihao(a, b):print(a)print(b)nihao('jack', 'lucy') # 顺序赋值nihao(a='富贵', b='秋香') # 关键词赋值
2.关键词(默认值)参数
他是直接传递参数(赋值后打印出来),所以不需要再次调用。 一次赋值,终身受用。就是说如果后面没有传参,就显示默认值。
比如内置函数里 end=””,sep=”” 就是关键词参数
def test(d='jack', grade='87'):print(d+'的成绩是'+grade)test() # jack的成绩是87 - 不传参就用默认值test('lucy', '80') # lucy的成绩是80 - 传参就用传过来的值
注意:关键词参数必须放在最后,并且关键词参数后面的所有参数都必须有默认值;
3.不定长(可变)参数
他的格式是 一个星号+参数名(列表),字面意思理解就是一个参数赋予多个值。
# 传入多个参数(不固定长度)def nihao(*name):print(name)nihao('jack', 'lucy', 'james')# 使用元组传入参数,结果是一样的list = ('jack', 'lucy', 'tom')def nihao(*name):print(name)
输出的结果是元组 (‘jack’, ‘lucy’, ‘tom’) ,它的用法和列表用法类似,主要区别在于列表中的元素可以随时修改,但元组中的元素不可更改。(元组只有查,列表有增删改查)
不定长(可变)参数之前,只能用顺序参数;(1 2 赋值给 a b,关键词只能放最后,所以不能用关键词)
不定长(可变)参数之后,只能用关键词参数;(不用关键词, X Y 4 3 会全部赋值给 *args )。
具体原因参考这个
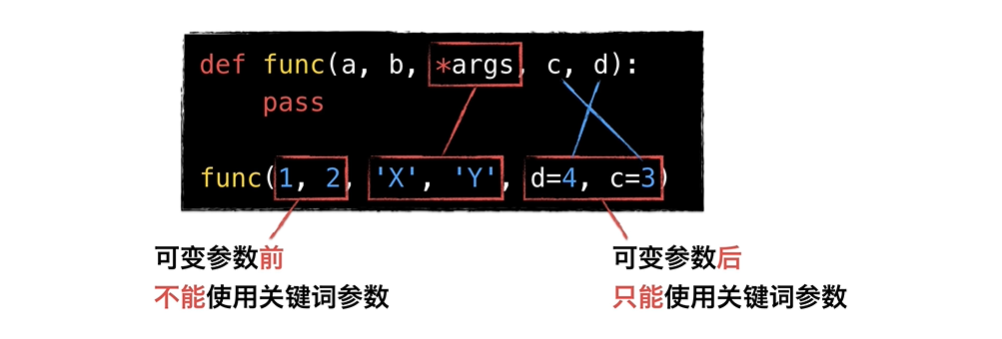
def nihao(a, b, *c):print(a) # jackprint(b) # lucyprint(c) # ('james', 'mason')nihao('jack', 'lucy', 'james', 'mason')
4.可变关键词参数
他的格式是 两个星号+参数名
def num(**key):print(key)num() # 结果 {}
上面代码结果运行之后是一个空字典,也就意味着我们传入的值必须是关键词参数。
def num(**key):print(key)num(a=1,b=2,c=3) # 结果是字典格式 {'a': 1, 'b': 2, 'c': 3}
然后我们遍历一下,打印出来。遍历字典中的键是keys ,值是values,键和值是items
def num(**key):for k, v in key.items():print(f'{k}:{v}')num(a=1, b=2, c=3)a:1b:2c:3
当和其他参数一起使用的时候,可变关键词参数必须最后。
def num(a, b, c, **key): # 如果c放在**key后面会报错print(f'{a}{b}{c}')for k, v in key.items():print(f'{k}:{v}')num(1, 2, x='hi', y='hello', c=3) # c可以使用关键词,也可以使用顺序赋值
如果加入不定长(可变)参数怎么办呢?
因为*key只能放最后,那么ABC只能放倒数第二;
又因为ABC之前的参数必须使用顺序赋值;ABC后的参数必须是用关键词赋值;
所以,下面的写法应该是:
123赋值给abc,456赋值给ABC,d使用关键词,xy的关键词参数赋值给*key
def num(a, b, c, *ABC, d, **key):print(f'{a}{b}{c}{d} - {ABC}')for k, v in key.items():print(f'{k}:{v}')num(1, 2, 3, 4, 5, 6, d=9, x='hi', y='hello')
不过这里的d的位置是方便举例,我们通常不这样写,习惯就是*key放最后,ABC倒数第二,之后其他的全部放前面并且顺序赋值,这样看起来更清晰,不容易出错。
def num(a, b, c, d, *ABC, **key):print(f'{a}{b}{c}{d} - {ABC}')for k, v in key.items():print(f'{k}:{v}')num(1, 2, 3, 4, 5, 6, 9, x='hi', y='hello')
形参与实参

# 形式参数:def f(a):print(a)f(8) # a=8传递参数时会使用实际参数给形式参数赋值# 因为y被重新赋值,所以x和y不是用一个,即便f(x)传递了参数def f(y):y = 0 # 函数外的值不影响函数内的值,因为他们不是同一个yx = 6f(x)print(x) # 结果是6# 因为实参y没有重新赋值,所以x和y表示的是同一个列表。# 对于一些函数append,clear,remove等是会影响到函数外的列表和字典的x = [1,2,3]def f(y):y.append(6)f(x)print(x) # 结果是[1, 2, 3, 6]
返回 return()
当你输入参数给函数,函数就会返回一个值给你,这就是return的作用。
def a(name):return len(name)print(a('123'))
你有没有发现,其实我们这里还可以用print替代,那为什么要多出来一个方法呢?原因是大多数情况下,我们不需要打印结果,而是取出这个返回值先放着,后面调用。
我们来句子场景的例子看看,思路是这样的,先定义,返回的值存起来,然后一起打印时候赋值。
def guess(num):if num > 10:return 'yes'else:return 'no'print(guess(20)) # 因为用的是return,所以输出需要打印出来
return不仅可以返回数字x+y,也可以返回字符串,还可以返回字典,比如下面的例子。
def makeDB_dic(ip, uid, pwd):return{"server": ip,"uid": uid,"pwd": pwd}db = makeDB_dic("192.168.1.1", "5678", "qq123456") # 传参并赋值给变量dbprint(db) # 结果是字典 {'server': '192.168.1.1', 'uid': '5678', 'pwd': 'qq123456'}print(db['server']) # 打印字典里的值
元组解包
a, b, c = (1, 2, 3)
我们可以把后面的(1, 2, 3)理解为一个箱子,把这个箱子拆开并把元素依次赋值给abc
我们也可以使用可变参数,需要注意的是只能有一个 *c(可变参数)
a, b, *c = (1, 2, 3, 4, 5)print(a) # 1print(b) # 2print(c) # [3, 4, 5, 6]
虽然叫元组解包,但是不限于元组,任何可迭代对象都是可以元组解包的
# 列表a, b, *c = [1, 2, 3, 4, 5]print(a)print(b)print(c)# 字符串# 需要注意,这里打印出的123456不是数字,而是字符串类型a, b, *c = '123456'print(f'{a}', type(a)) # 1 <class 'str'>print(b) # 2print(c) # ['3', '4', '5', '6']# rangea, b, *c = range(6) # 注意是0-5print(f'{a}', type(a)) # 0 <class 'int'>print(f'{b}', type(b)) # 1 <class 'int'>print(f'{c}', type(c)) # [2, 3, 4, 5] <class 'list'># 字典(用键解包)a, *b = {'a': 1, 'b': 2, 'c': 3} # 默认值是键,建议加上.keys()增加代码可读性print(a) # aprint(b) # ['b', 'c']# 字典(用值解包)a, *b = {'a': 1, 'b': 2, 'c': 3}.values()print(a) # 1print(b) # [2, 3]# 字典(用键值对解包)a, *b = {'a': 1, 'b': 2, 'c': 3}.items()print(a) # ('a', 1)print(b) # [('b', 2), ('c', 3)]
请注意:字典是一种无序的容器,所以解包出来的元素有时候不一定按照我们给定的顺序依次解包。
主函数 main()
用法有点像函数嵌套,先定义一个函数列表,然后调用,最后赋值。当然因为是自定义的函数,所以下面的main也可以换成任意的值,当然命名时候还是要规范。(不要学我哈~)
def a(name):return name + '的睿智、'def b(name):return name + '的段子.'def main(qipa_a,qipa_b):return '我超喜欢《奇葩说》里'+ a(qipa_a)+b(qipa_b)print(main('詹青云','小黑'))print(main('黄执中','傅首尔'))
main()函数内部分别调用了a()和b()函数,参数qipa_a和qipa_b传递给了a()和b()函数的参数name,得到返回值,并打印。看起来有点绕,我们将函数运行的步骤分解,就一目了然了。
需要多次调用函数时,可以再自定义一个主函数main(),调用非主函数的返回值。
我们看下面代码中,我们自定义了函数两个函数a和b,并分别返回了“的睿智”和“的段子”两个值,有没有发现这里面有重复的东西,之前我们也说了,如果发现你的代码有重复的结构,那大概率是写法不简洁,理解不深刻。
def a(name):return name + '的睿智、'def b(name):return name + '的段子.'print('我超喜欢《奇葩说》里'+a('詹青云') + b('小黑'))
话说回来,如果我们要一次性返回两个值或多个值(Python独有),该我们怎么做呢?先看代码:
def c(name1, name2):a = name1 + '的睿智、'b = name2 + '的段子'return a, bd = c('詹青云', '小黑')print('我超喜欢《奇葩说》里'+d[0]+d[1])
你或许已经完全懵逼了,c和d是什么啊,怎么又多了两个函数,别急,我们慢慢分解。
首先我们引入c是为了重新引入新的参数列表,重新命名name1和name2,然后返回结果a和b。接着我们给c元组赋值给变量d,最后打印赋值后的函数第一位就是d[0],第二位就是d[1]。
需要注意的是:没有return语句的函数会默认返回None(因为没有给返回值)。
def name1():a = 'i\'m,jack'print(name1()) # 没有return 返回是Nonedef name2():b = 'i\'m lucy'return bprint(name2()) # i'm lucy
另外还有个小瑕疵,需要注意,就是return语句在内部的时候,就会停止并返回结果,而不会继续运行。
# 遇到 lucy 就返回结果 后面不执行def name():return 'lucy'return 'jack'print(name())
变量作用域(局部变量/全局变量)
什么意思呢?就是当我们自定义一个函数的时候,这个函数能在哪个区域发生作用。函数外的叫全局变量,函数内的叫局部变量。
a = 'jack'def name1():b = 'lucy'return bdef name2():c = 'mason'print(c)print(a) # jack 全局变量print(name1()) # lucy 局部变量(return值就需要print)name2() # mason 局部变量
当然局部变量不可外用,全局变量随意用。比如下面的例子
# (内部)内部函数print调用(外部)变量aa = 108def name():print(a)name()# (内部)函数print调用(内部)变量adef name():a = 108print(a)name()# 会报错,(外部)函数print调用(内部)变量adef name():a = 108name()print(a)
如果非要把外部调用内部,可以通过global来把局部变量变成全局变量,比如:
def name():global a # global语句可以将局部变量声明为全局变量a = 108name()print(a)
包是什么

内置函数
1、set() 去重
当需要对一个列表进行去重操作的时候,set()函数就派上用场了。set([iterable]) 用于创建一个集合,集合里的元素是无序且不重复的。
obj = ['a','b','c','b','a']print(set(obj)) # 输出:{'b', 'c', 'a'}
集合对象创建后,还能使用并集、交集、差集功能。
A = set('hello')B = set('world')print(A.union(B)) # 并集,输出:{'e', 'd', 'w', 'h', 'r', 'l', 'o'}print(A.intersection(B)) # 交集(重复),输出:{'l', 'o'}print(A.difference(B)) # 差集,输出:{'e', 'h'}
2、eval() 计算
使用eval进行四则运算器,输入字符串公式,直接产生结果。
x = input('请输入计算公式:')print(eval(x))
eval(str_expression)作用是将字符串转换成表达式,并且执行。
a = eval('[1,2,3]')print(type(a))# 输出:<class 'list'>b = eval('max([2,4,5])')print(b)# 输出:5
3、sorted() 排序
主要用于对 列表、字典、元组里面的元素正/倒排序。
语法:sorted(Iterable, key=函数(排序规则), reverse=False) Iterable: 可迭代对象 key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数,根据函数运算的结果进行排序 reverse: 是否是倒叙. True: 倒叙, False: 正序
a = sorted([2, 4, 3, 1])print(a) # 输出:[1, 2, 3, 4]b = sorted([2, 4, 3, 1], reverse=True)print(b) # 输出:[4, 3, 2, 1]# 使用参数:key,根据自定义规则,按字符串长度来排序:chars = ['apple', 'watermelon', 'pear', 'banana']a = sorted(chars, key=lambda x: len(x)) # 结构:(列表,key=lambda x:排序规则)print(a)# 输出:['pear', 'apple', 'banana', 'watermelon']# 根据自定义规则,对元组构成的列表进行排序:tuple_list = [('A', 1, 5), ('B', 3, 2), ('C', 2, 6)]# key=lambda x: x[1]中可以任意选定x中可选的位置进行排序a = sorted(tuple_list, key=lambda x: x[1]) # 结构:(列表,key=lambda x:排序规则)print(a)# 输出:[('A', 1, 5), ('C', 2, 6), ('B', 3, 2)]
4、reversed() 反转
如果需要对序列的元素进行反转操作,reversed()函数能帮到你。reversed() 接受一个序列,将序列里的元素反转,并最终返回迭代器。
a = reversed('abcde')print(list(a))# 输出:['e', 'd', 'c', 'b', 'a']b = reversed([2,3,4,5])print(list(b))# 输出:[5, 4, 3, 2]
5、map() 大小写
做文本处理的时候,假如要对序列里的每个单词进行大写转化操作。
chars = ['apple', 'watermelon', 'pear', 'banana']# upper大写 lower小写 title首字母大写a = map(lambda x: x.title(), chars) # 结构:(lambda x:函数,列表)print(list(a))# 输出:['Apple', 'Watermelon', 'Pear', 'Banana']
map()会根据提供的函数,对指定的序列做映射,最终返回迭代器。也就是说map()函数会把序列里的每一个元素用指定的方法加工一遍,最终返回给你加工好的序列。
nums = [1,2,3,4]a = map(lambda x:x*x,nums) # 结构:(lambda x:函数,列表)print(list(a))# 输出:[1, 4, 9, 16]
6、reduce() 累积
前面说到对列表里的每个数字作平方处理,用map()函数。
那我想将列表里的每个元素相乘(或相加),该怎么做呢?
from functools import reducenums = [1, 2, 3, 4]a = reduce(lambda x, y: x*y, nums) # 结构:(lambda x,y:函数,列表)b = reduce(lambda x, y: x+y, nums) # 结构:(lambda x,y:函数,列表)print(a) # 输出:24print(b) # 输出:10
reduce()会对参数序列中元素进行累积。第一、第二个元素先进行函数操作,生成的结果再和第三个元素进行函数操作,以此类推,最终生成所有元素累积运算的结果。
reduce和加号除了可以计算,还可以对字符串进行拼接
from functools import reducechars = ['a', 'p', 'p', 'l', 'e']a = reduce(lambda x, y: x+y, chars) # 结构:(lambda x,y:函数,列表)print(a) # 输出:apple
你可能已经注意到,reduce()函数在python3里已经不再是内置函数,而是迁移到了functools模块中。
7、filter() 过滤
一些数字组成的列表,要把其中偶数去掉,该怎么做呢?
nums = [1, 2, 3, 4, 5, 6]a = filter(lambda x: x % 2 != 0, nums) # 结构:(lambda x:函数,列表)print(list(a)) # 输出:[1,3,5]
filter()函数轻松完成了任务,它用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象。filter()函数和map()、reduce()函数类似,都是将序列里的每个元素映射到函数,最终返回结果。
我们再试试,如何从许多单词里挑出包含字母w的单词。
chars = chars = ['apple', 'watermelon', 'pear', 'banana']a = filter(lambda x: 'w' in x, chars) # 结构:(lambda x:函数,列表)print(list(a)) # 输出:['watermelon']
8、enumerate() 枚举
这样一个场景,同时打印出序列(列表)里每一个元素和它对应的顺序号,我们用enumerate()函数做做看。
chars = ['apple', 'watermelon', 'pear', 'banana']for i, j in enumerate(chars): # 因为chars是列表(x,y),所以我们使用两个变量来接收print(i, j)'''输出:0 apple1 watermelon2 pear3 banana'''
enumerate翻译过来是枚举、列举的意思,所以说 enumerate() 函数用于对序列里的元素进行顺序标注,返回(元素、索引)组成的迭代器。
再举个例子说明,对字符串进行标注,返回每个字母和其索引。
a = enumerate('abcd')print(list(a)) # 输出 [(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')]

若有收获,就点个赞吧
0 人点赞
