runoob:https://www.runoob.com/regexp/regexp-tutorial.html 奇乐编程:https://b23.tv/zx7H1h https://zh.javascript.info/regular-expressions 在线校验工具:https://regex101.com/
字符分为两种,普通字符和元字符,普通字符就是我们要匹配的文字,比如 test 匹配的就是test的文本内容;元字符就是有特殊含义的字符。也是正则里面的主要内容,比如 .d里面,. 代表的是任意字符;
可以使用下面的方式来学习,正则表达式的匹配,也可以通过在线网站匹配:https://regex101.com/,推荐用后者,因为更强大(尤其是在分组()部分)。
import rep = re.compile('cat.+') # 要匹配的(正则)字符串print(p.match('cat888')) # 被匹配的字符串# 没有匹配,结果为None;# 有匹配,span=(0, 3),表示匹配了三个字符; match='cat'表示匹配对象是cat;
元字符 pattern
. :匹配除换行符之外的任意单个字符。
import retext = '''ABC,TBCD,ABGM,'''p = re.compile(r'.B')# print(type(p)) # <class 're.Pattern'>for i in p.findall(text):print(i) # AB TB AB
re.compile(r’字符串’),前面加的r是为了避免和 \重复(禁止使用转义字符),效果类似于 原始字符串 f-string。
* :匹配前面的子表达式的任意次,包括0次(>=0)。
比如,你想要匹配每行’B’字后面的字符串内容,包括’B’本身。
import retext = '''ABC,TBCD,ABGM,'''p = re.compile(r'B.*') #B开头,加上任意单个字符的任意次(一直到本行结束)# print(type(p)) # <class 're.Pattern'>for i in p.findall(text):print(i)print('-------------')po = re.compile(r'BC*') # B开头,C字的任意次(包含0次)for i in po.findall(text):print(i) # BC BC B
+ :匹配前面的子表达式的任意次,不包括0次(>=1)。
import retext = '''ABC,TBCD,ABGM,'''po = re.compile(r'BC*') # 红字开头,C字的任意次(包含0次,模糊匹配)for i in po.findall(text):print(i) # BC BC Bprint('-------------')po = re.compile(r'BC+') # 红字开头,C字的任意次(不包含0次,完全匹配)for i in po.findall(text):print(i) # BC BC
要特别注意 和 + 之间的区别; 匹配 零次 或更多次,因此*重复的任何东西都可能根本不存在,而 + 至少需要一次。
ca*t 将匹配 ‘ct’ (0个 ‘a’ ),’cat’ (1个 ‘a’ ), ‘caaat’ (3个 ‘a’ ),等等。 ca+t 将匹配 ‘cat’ (1 个 ‘a’),’caaat’ (3 个 ‘a’),但不会匹配 ‘ct’。 ca-?t将匹配 cat,ca-t
? :匹配前面的子表达式零次或一次(0<=x<=1)
例如 do(es)? ”可以匹配“does”中的“do”和“does”。? 等价于{0,1}
{ } :匹配指定次数
有以下三种写法: {n} 前面紧挨的元素,匹配n次 x=n {n,} 前面紧挨的元素,至少匹配n次 x>=n {n,m} 前面紧挨的元素,至少匹配n次,至多匹配m次 n<=x<=m
比如说我们要提取一行数据里的手机号 \d{11},\d表示数字;如果是\d{3,5}则表示匹配出现三个到五个连续的数字字符;
import retext = '''Elian,181389984541,65Bobbie,18138984278,99Kirk,15089898236,89'''number = re.compile(r'\d{11}') # 匹配哪些元素print(number.findall(text)) # 从哪里匹配,结果是列表# ['18138998454', '18138984278', '15089898236']
再比如下面一段,我们要提取职位和薪资
import retext = '''数据分析:50K/月,巴拉巴拉产品经理:60.8K/每月,美团外卖'''p = re.compile(r'(.{2,8}):([\d.]+K/每{0,1}月)', re.M) # 每行文本逗号前的字符串,多行匹配for i in p.findall(text): # 从哪里匹配print(i)# ('数据分析', '50K/月')# ('产品经理', '60.8K/每月')
职位特征:任意字符的2-8位,并且以冒号结尾(注意区分标点的中英文) 薪资特征:数字和点的组合 + K/ + (每)月(每字可以通过{0,1}或者?来处理)
[ ] :包含多个字符串的任意一个或范围
什么意思呢?任意一个就是说 1[abc]2 匹配的是abc里的任意一个,结果可以是 1a2 1b2 1c2;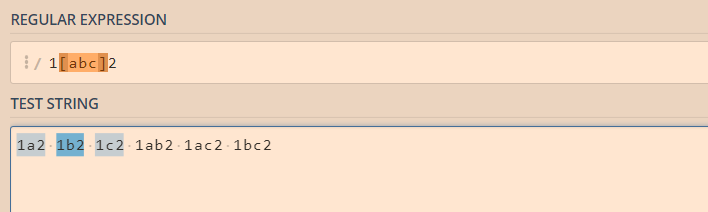
而范围指的是[A-Z] [a-z] [0-9] 这些带有区间范围的字符串。比如[0-9]表示所有数字
import retext = '''Elian,181389984541,65Bobbie,18138984278,99Kirk,19089898236,89'''name = re.compile(r'1[5-8]\d{9}') # 匹配哪些元素print(name.findall(text)) # 从哪里匹配,结果是列表# ['18138998454', '18138984278']
1表示第一个元素是1 [6-8]表示第二个元素是5,6,7,8,也可以写[5678],只是数字区间多的时候前者更方便,也可以用于字母a-c表示abc \d{9},表示重复9个数字
除了字母数字,[a-z] [A-Z] [0-9],括号里面还可以添加反斜杠 比如[\s,]表示任何空白字符,逗号;
注意:[.] 等价于 . ,点在方括号内就失去了魔法,和普通字符一样,比如 [ak.]匹配 a k . 里面的任意一个字符,这里的点就不是元字符的任意字符了。
import retext = '''Elian,1.81389984541,65Bobbie,18138984278,99Kirk,19089898236,89'''name = re.compile(r'1[.]') # 匹配开头是1后面是点的字符串print(name.findall(text)) # 从哪里匹配,结果是列表# ['1.']name = re.compile(r'1[.8]') # 匹配开头是1后面是点或8的字符串print(name.findall(text)) # 从哪里匹配,结果是列表# ['1.', '18']
如果在方括号内使用 ^ ,表示不包含方括号里面的字符集合。
import retext = '456fd5'p = re.compile(r'[^\d]') # 匹配非数字的字符串# for i in p.print(p.findall(text)) # 从哪里匹配,结果是列表# ['f', 'd']
( ) :组选择
由于匹配时候我们的正则表达式需要用一些字符来定位所取元素,所以结果也会带这些元素(符号),如果想把结果的这些字符去除,就需要用到分组,最终括号里的就是我们要提取的结果。
import retext = '''001,apple002,banner003,pear'''p = re.compile(r'(.+),', re.M) # 每行文本逗号前的字符串,多行匹配for i in p.findall(text): # 从哪里匹配print(i)# 001 002 003 结果又逗号,但是表达式里面不可以删除,因为删除就无法匹配到需要的内容
分组也可以使用嵌套,多组嵌套使用的方式建议是,先提取所有文字,然后在用括号分组取出,比如下面案例,我们可以先提取 ^.+,手机号码\d{11}$ ,然后使用括号来提取想要的内容。
import retext = '''小明,手机号码18137864612小李,手机号码13156894579小红,手机号码15056437563'''p = re.compile(r'^(.+),手机号码(\d{11}$)', re.M) # 提取内容,多行匹配for i in p.findall(text): # 从哪里匹配print(i)# ('小明', '18137864612')# ('小李', '13156894579')# ('小红', '15056437563')
我们也可以看到,多个嵌套后返回的结果就是元组,而非元素。如果不想要结果是元组,可以使用group方法来提取,案例如下:
import rep = re.compile(r'(\d+)-(\d+)-(\d+)') # 要匹配的(正则)字符串print(p.match('2022-05-06').group(2)) # 被匹配的字符串里,取出第二个组(括号)里的值 0和不填表示全取# 结果是 05 (字符串类型)# 不分组也可以取值,分组是为了让数据提取更灵活,想取谁都可以。
如果想全部取值,可以使用groups(),括号里面不需要填数字。
import rep = re.compile(r'(\d+)-(\d+)-(\d+)') # 要匹配的(正则)字符串print(p.match('2022-05-06').groups()) # 被匹配的字符串里,全部取值# 结果是 ('2022', '05', '06')# ---------------------------p = re.compile(r'(\d+)-(\d+)-(\d+)') # 要匹配的(正则)字符串year, month, day = p.match('2022-05-06').groups() #定义三个变量来装存他们print(year) # 结果是 2022
\ :对元字符进行转义(\d\s\w)
就是让元字符失效,比如说我们要匹配一个带有.的字符串,这时候你用点,程序就会把它当做是元字符的点(表示任意字符)这时候就需要用 反斜杠+点 来表示 点 ,用反斜杠+星 来表示星
import retext = '''Apple.greenbanner.yelloworange.orange'''po = re.compile(r'.*\.') #for i in po.findall(text):print(i) # Apple.banner.orange.
另外,官方也有一些已经定义的字符串
| 符号 | 说明 | 备注 |
|---|---|---|
| \d digit | 匹配任何十进制数字;这等价于类 [0-9]。 |
数字 |
| \D | 匹配任何非数字字符;这等价于类 [^0-9]。 |
|
| \w word | 匹配任何字母与数字字符;这相当于类 [a-zA-Z0-9_]。 |
数字字母下划线 |
| \W | 匹配任何非字母与数字字符;这相当于类 [^a-zA-Z0-9_]。 |
|
| \s space | 匹配任何空白字符(空格 tab 换行);这等价于类 [ \\t\\n\\r\\f\\v]。 |
空白 |
| \S | 匹配任何非空白字符;这相当于类 [^ \\t\\n\\r\\f\\v]。 |
\w有个问题,就是也包含中文字符,如果只需要字母,就需要加入标记flag,这里我们用到的标记是 re.ASCII
import retext = '''小明Tony小美'''name = re.compile(r'\w{2,4}') # 匹配连续出现2-4次的组合print(name.findall(text)) # 从哪里匹配,结果是列表['小明', 'Tony', '小美']name = re.compile(r'\w{2,4}', re.ASCII) # 只要符号条件的字母组合,也可以写作re.Aprint(name.findall(text)) # 从哪里匹配,结果是列表['Tony']
案例解析
import retext = '''小明,181389984541,65小鹏,18138984278,99小美,15089898236,89'''name = re.compile(r'\D{2,5},') # 匹配哪些元素print(name.findall(text)) # 从哪里匹配,结果是列表# ['\n小明,', '\n小鹏,', '\n小美,']
\D取值非数字的字符,长度是2-5之间(不要取1,因为标点符号也是非数字),为了保证取值的正确性,我们增加一个标点逗号作为结尾。
\b :字符边界
词边界 \b 是一种检查,就像 ^ 和 $ 一样。
当正则表达式引擎(实现搜索正则表达式的程序模块)遇到 \b 时,它会检查字符串中的位置是否是词(\w)边界。
不容易理解,按照我的理解就是 表达式的左右两侧字符 和 要匹配的字符串,两端不是单词字符(\w)。直接上图吧
alert( "Hello, Java!".match(/\bHello\b/) ); // Hello H的左边,o的右边不同类型alert( "Hello, Java!".match(/\bJava\b/) ); // Java 左右不同类型alert( "Hello, Java!".match(/\bHell\b/) ); // null (no match) l的右边是o,同类型,不匹配alert( "Hello, Java!".match(/\bJava!\b/) ); // null (no match) !的右边是空格,同类型,不匹配
\b 既可以用于单词,也可以用于数字。例如,模式 \b\d\d\b 查找独立的两位数。
alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78 /g是 g是glabal全局的意思alert( "12,34,56".match(/\b\d\d\b/g) ); // 12,34,56
如果还没有理解,那就点这个链接再看看吧: https://zh.javascript.info/regexp-boundary
| : 或的关系
或运算符,用于匹配符号前或符号后的字符
.*?/.+? :贪婪模式与非贪婪模式
贪婪就是尽可能多的去匹配,.* 是贪婪的;如果不需要贪婪模式,需要在他们后面加上问号,表示非贪婪模式(尽可能少的匹配)。
import re# 贪婪模式 .*p = re.compile('cat.*') # 要匹配的(正则)字符串print(p.match('cattttttt')) # 被匹配的字符串# 匹配的结果是 cattttttt 尽可能多的匹配,程序会找到最长的那个符合要求的字符串# 非贪婪模式 .*?p = re.compile('cat.*?') # 要匹配的(正则)字符串print(p.match('cattttttt')) # 被匹配的字符串# 匹配的结果是 catt 匹配到一个就停止
^ :从开始位置匹配
import retext = '''001-apple-68002-banner-56003-pear-88'''# -- 单行 ---p = re.compile(r'^\d+') # 整个文本的开头是数字,默认单行匹配for i in p.findall(text): # 从哪里匹配print(i)# 001 # 如果上面的001换行了,第一行就是空,则结果为空# -- 多行 ---p = re.compile(r'^\d+', re.M) # 每行开头是数字,并且多行匹配for i in p.findall(text): # 从哪里匹配print(i)# 001 002 003
\d表示数字,这里用+而没用*,是因为星号包含0,也就是取值可以不为数字,相当于全选。
$ :从结尾位置匹配
比如我们需要找到结尾是jpg格式的图片连接,就可以写 jpg$
import retext = '''001-apple-68002-banner-56003-pear-88'''# -- 单行 ---p = re.compile(r'\d+$') # 整个文本的结束是数字,默认单行匹配for i in p.findall(text): # 从哪里匹配print(i)# 88# -- 多行 ---p = re.compile(r'\d+$', re.M) # 每行开头是数字,并且多行匹配for i in p.findall(text): # 从哪里匹配print(i)# 68 56 88
使用中的优先级
就好比加减乘除,他们的计算也有优先级。
| 优先级 | 字符 |
|---|---|
| 最高 | \ |
| 高 | ()、(?:)、(?=)、[] |
| 中 | *、+、?、{n}、{n,}、{n,m} |
| 低 | ^、$、中介字符 |
| 次最低 | 串接,即相邻字符连接在一起 |
| 最低 | | |
常用方法介绍
其中三个函数用于查找匹配match()、search()、findall(),一个函数sub()用于替换,一个函数split()用于切分字符串,还有一个函数compile()用于编译正则表达式。
match():匹配字符串的开头,如果开头匹配不上,则返回None; search():扫描整个字符串,匹配后立即返回,不在往后面匹配; findall():扫描整个字符串,以列表形式返回所有的匹配值; compile():将字符串编译成正则表达式对象,供 match() 、 search() 和findall()函数使用; sub():扫描整个字符串,用于替换字符串的某些值; split():扫描整个字符串,按照指定分隔符切分字符串;
修饰符 flag(I/A/M/S)
| 标记 | 含义 |
|---|---|
| re.I,IGNORECASE | 忽略大小写(常用) |
| re.A,ASCII | 只要字母 |
| re.M,MULTILINE | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符(默认的点不包括) |
match(pattern,string,flag) 必须从字符串开头匹配
pattern:你写的正则表达式; string:待匹配的字符串; flag:修饰符;
match匹配的内容开头必须和正则表达式一一对应,并且只返回第一个结果(开头匹配不上输出None)。
import recontext = "2022-05-06 ok 2023-08-08"p = re.match(r'(\d+)-(\d+)-(\d+)', context) # 被匹配的第一个字符串取值 2022-05-06print(p.group()) # 匹配到的内容print(p.span()) # 匹配到的字符的开始和结束的索引位置 (0, 10)print(re.match('ok', context)) # 开始位置没有匹配成功,返回None
注:这个函数局限性太大,用的不是太多,因此大家知道这个事儿就行。match()函数主要是用于区分下面要讲的search()函数。
search(pattern, string,flag) 查找任意位置的匹配项(一个结果)
pattern:你写的正则表达式; string:待匹配的字符串; flag:修饰符;
与match匹配开头不同,search()函数是扫描整个字符串,只要能匹配上,就有结果。 但是注意匹配上之后就不再往后匹配了,只返回第一个结果。
import rep = re.compile(r'(\d+)-(\d+)-(\d+)') # 要匹配的(正则)字符串print(p.search('A2022-05-06').group()) # 被匹配的字符串里,全部取值# 结果是 ('2022', '05', '06')---- 换种写法(推荐下面的) ----context = "2022-05-06"p = re.search(r'(\d+)-(\d+)-(\d+)', context) # 要匹配的(正则)字符串print(p.group()) # 被匹配的字符串里,全部取值
match和search不同: 相同点:都是返回第一个匹配成功的结果; 不同点:match从开头匹配,search搜索整个字符串;
findall(pattern, string, flags) 查找任意位置的匹配项(所有结果)
pattern:你写的正则表达式; string:待匹配的字符串; flag:修饰符;
findall()函数,不管是我们做爬虫,还是我们做数据清洗,都属于高频函数;
finadll()函数会直接返回所有匹配对象,组成的列表(记住:返回的是列表);
不像search()函数与match()函数,findall不需要调用group()函数;
如果finadll()函数,没有匹配上,不会报错,而是返回一个空列表;
import recontext = "www.baidu.com, www.google.com"p1 = re.findall(r'g', context) # 被匹配的第一个字符串取值 2022-05-06print(p1) # 匹配到多个结果是列表 ['g', 'g']p2 = re.findall(r'ok', context) # 被匹配的第一个字符串取值 2022-05-06print(p2) # 匹配到无,结果为空列表 []
sub 替换(pattern,repl,string,count,flag)
pattern:你写的正则表达式; repl:替换成啥; string:待替换的字符串; count:表示最大替换次数,默认 0 表示替换所有的匹配; flag:修饰符;
sub里有四个参数,分别是 匹配规则(pattern),替换为什么(repl),要替换的字符串(string) ,替换的次数(count),还有一个修饰符。
import retext = 'today is 2020-03-05'# 直接替换print(re.sub('-', '', text)) # 'today is 20200305' # 没有设置全部匹配print(re.sub('-', '', text, 1)) # 'today is 202003-05' #匹配第一个# 通过函数替换# 'today is 03/05/2020'print(re.sub('(\d{4})-(\d{2})-(\d{2})', r'\2/\3/\1', text)) # \数字 代表匹配元素的次序# 'today is 03-05-2020'print(re.sub('(\d{4})-(\d{2})-(\d{2})', r'\2-\3-\1', text))
re.sub的一个变形方法是re.subn,区别是返回一个包含2个元素的元组,其中第一个元素为替换结果,第二个为替换次数。
import retext = 'today is 2020-03-05'print(re.sub('-', '', text)) # today is 20200305text = 'today is 2020-03-05'print(re.subn('-', '', text)) # ('today is 20200305', 2) # 结果是元组(结果,次数)
高级一点,可以使用替换函数。如果案例没看不明白,可以点击 查看解释。
import renames = '''https://www.bilibili.com/video/av66001/?p=1https://www.bilibili.com/video/av46002/?p=125https://www.bilibili.com/video/av90003/?p=33'''# 替换函数,参数是 Match对象def subFunc(match):# Match对象 的 group(0) 返回的是整个匹配上的字符串src = match.group(0) # 原始值# Match对象 的 group(1) 返回的是第一个group分组的内容(也就是括号里的值)number = int(match.group(1)) + 6 # 替换规则 取出第一个括号里包括的值转化为整数类型并加6dest = f'/av{number}/' # 再合并回字符串print(f'{src} 替换为 {dest}')# 返回值就是最终替换的字符串return dest# 正则表达式,定义函数(替换的是返回值dest),文件位置newStr = re.sub(r'/av(\d+?)/', subFunc, names)print(newStr)
里面的group(1)可以理解为第一个括号里的值;如果正则表达式是 /av(\d+?)/.p=(\d+),那么 (\d+?)就是第一个括号里的值,即group(1),(\d+)就是group(2) ,以此类推。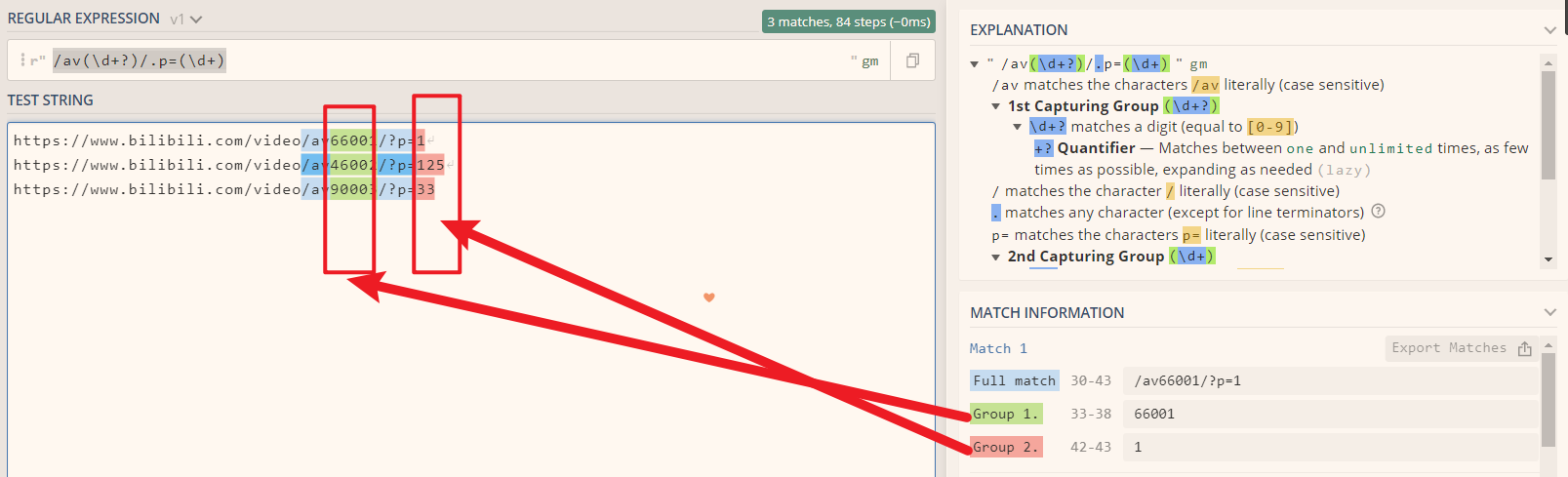
这里的group(0)其实是不需要的,因为我们需要看到数据处理的过程,所以加了第17行和第22行,实际工作中不需要写。
split 分割(pattern,string,maxsplit,flag)
pattern:你写的正则表达式; string:待分割的字符串; maxsplit:最大分割次数,默认为 0,表示不限制分割次数; flag:修饰符;
有时候分隔符不固定,可以试用split进行分割,多个分隔符试放在中括号里。
import retext = '1,2,3-4'# 这里如果不指定“最大分割次数”,则是不限次数切分print(re.split(',', text))# ['1', '2', '3-4']# 如果指定最大分割次数maxsplit=1,那么就只以第一个分隔符,进行切分print(re.split(',', text, 1))# ['1', '2,3-4']# 多个分隔符,用中括号,比如下面使用冒号、横杠进行分割print(re.split('[,-]', text))# ['1', '2', '3', '4']
常用的正则表达式写法:
邮箱
包含大小写字母,下划线,阿拉伯数字,点号,中划线
pattern = re.compile(r"[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(?:\.[a-zA-Z0-9_-]+)")strs = '我的私人邮箱是zhuwjwh@outlook.com,公司邮箱是123456@qq.org,麻烦登记一下?'result = pattern.findall(strs)print(result)
身份证号
地区:[1-9]\d{5}
年的前两位:(18|19|([23]\d)) 1800-2399
年的后两位:\d{2}
月份:((0[1-9])|(10|11|12))
天数:(([0-2][1-9])|10|20|30|31) 闰年不能禁止29+
三位顺序码:\d{3}
两位顺序码:\d{2}
校验码:[0-9Xx]
pattern = re.compile(r"[1-9]\d{5}(?:18|19|(?:[23]\d))\d{2}(?:(?:0[1-9])|(?:10|11|12))(?:(?:[0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]")strs = '小明的身份证号码是342623198910235163,手机号是13987692110'result = pattern.findall(strs)print(result)
国内手机号码
手机号都为11位,且以1开头,第二位一般为3、5、6、7、8、9 ,剩下八位任意数字。例如:13987692110
pattern = re.compile(r"1[356789]\d{9}")strs = '小明的手机号是13987692110,你明天打给他'result = pattern.findall(strs)print(result)
国内固定电话
区号3~4位,号码7~8位。例如:0511-1234567、021-87654321
pattern = re.compile(r"\d{3}-\d{8}|\d{4}-\d{7}")strs = '0511-1234567是小明家的电话,他的办公室电话是021-87654321'result = pattern.findall(strs)print(result)
域名
包含http:\或https:\
pattern = re.compile(r"(?:(?:http:\/\/)|(?:https:\/\/))?(?:[\w](?:[\w\-]{0,61}[\w])?\.)+[a-zA-Z]{2,6}(?:\/)")strs = 'Python官网的网址是https://www.python.org/'result = pattern.findall(strs)print(result)
IP地址
包含http:\或https:\
pattern = re.compile(r"((?:(?:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d))")strs = '''192.168.8.840.0.0.1256.1.1.1192.256.256.256192.255.255.255aa.bb.cc.dd'''result = pattern.findall(strs)print(result)
日期
常见日期格式:yyyyMMdd、yyyy-MM-dd、yyyy/MM/dd、yyyy.MM.dd
pattern = re.compile(r"\d{4}(?:-|\/|.)\d{1,2}(?:-|\/|.)\d{1,2}")strs = '今天是2020/12/20,去年的今天是2019.12.20,明年的今天是2021-12-20'result = pattern.findall(strs)print(result)
国内邮政编码
我国的邮政编码采用四级六位数编码结构 前两位数字表示省(直辖市、自治区) 第三位数字表示邮区;第四位数字表示县(市) 最后两位数字表示投递局(所)
pattern = re.compile(r"[1-9]\d{5}(?!\d)")strs = '上海静安区邮编是200040'result = pattern.findall(strs)print(result)
弱密码
以字母开头,长度在6~18之间,只能包含字母、数字和下划线
pattern = re.compile(r"[a-zA-Z]\w{5,17}")strs = '密码:q123456_abc'result = pattern.findall(strs)print(result)
强密码
以字母开头,必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间
pattern = re.compile(r"[a-zA-Z](?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}")strs = '强密码:q123456ABc,弱密码:q123456abc'result = pattern.findall(strs)print(result)
中文字符
所有中文字符
pattern = re.compile(r"[\u4e00-\u9fa5]")strs = 'apple:苹果'result = pattern.findall(strs)print(result)
还有一些高级概念,比如捕获,断言,平衡组,递归,感兴趣的可以来这里看看:https://deerchao.cn/tutorials/regex/regex.htm

若有收获,就点个赞吧
0 人点赞
