CREATE TABLE single_table (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1),UNIQUE KEY idx_key2 (key2),KEY idx_key3 (key3),KEY idx_key_part(key_part1, key_part2, key_part3)) Engine=InnoDB CHARSET=utf8;
条件化简
移除不必要的括号
((a = 5 AND b = c) OR ((a > c) AND (c < 5)))看着就很烦,优化器会把那些用不到的括号给干掉,就是这样:(a = 5 and b = c) OR (a > c AND c < 5)
常量传递(constant_propagation)
a = 5 AND b > a就可以被转换为:a = 5 AND b > 5
等值传递(equality_propagation)
a = b and b = c and c = 5就可以被转换为:a = 5 and b = 5 and c = 5
移除没用的条件(trivial_condition_removal)
(a < 1 and b = b) OR (a = 6 OR 5 != 5)就可以被转换为:a < 1 OR a = 6
表达式计算
a = 5 + 1就可以被转换为:a = 6
HAVING子句和WHERE子句的合并
如果查询语句中没有出现诸如SUM、MAX等等的聚集函数以及GROUP BY子句,优化器就把HAVING子句和WHERE子句合并起来
常量表检测
设计MySQL的大叔觉得下边这两种查询运行的特别快:
- 查询的表中一条记录没有,或者只有一条记录。
- 使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表。
设计MySQL的大叔觉得这两种查询花费的时间特别少,少到可以忽略,所以也把通过这两种方式查询的表称之为常量表(英文名:constant tables)。
外连接消除
外连接和内连接的本质区别就是:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充;而内连接的驱动表的记录如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录会被舍弃
mysql> SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c |+------+------+------+------+2 rows in set (0.00 sec)mysql> SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2;+------+------+------+------+| m1 | n1 | m2 | n2 |+------+------+------+------+| 2 | b | 2 | b || 3 | c | 3 | c || 1 | a | NULL | NULL |+------+------+------+------+3 rows in set (0.00 sec)
我们把这种在外连接查询中,指定的WHERE子句中包含被驱动表中的列不为NULL值的条件称之为空值拒绝(英文名:reject-NULL)。在被驱动表的WHERE子句符合空值拒绝的条件后,外连接和内连接可以相互转换
子查询优化
子查询语法
按位置
- SELECT子句中 ```sql mysql> SELECT (SELECT m1 FROM t1 LIMIT 1); +——————————————-+ | (SELECT m1 FROM t1 LIMIT 1) | +——————————————-+ | 1 | +——————————————-+ 1 row in set (0.00 sec)
其中的(SELECT m1 FROM t1 LIMIT 1)就是我们唠叨的所谓的子查询。
- FROM子句中```sqlSELECT m, n FROM (SELECT m2 + 1 AS m, n2 AS n FROM t2 WHERE m2 > 2) AS t;+------+------+| m | n |+------+------+| 4 | c || 5 | d |+------+------+2 rows in set (0.00 sec)
SELECT * FROM t1 WHERE m1 = (SELECT MIN(m2) FROM t2);
- 行子查询
```sql
SELECT * FROM t1 WHERE (m1, n1) = (SELECT m2, n2 FROM t2 LIMIT 1);
列子查询
SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2);表子查询
SELECT * FROM t1 WHERE (m1, n1) IN (SELECT m2, n2 FROM t2);按与外层查询关系来区分子查询
不相关子查询
- 相关子查询
如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称之为相关子查询
SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2 WHERE n1 = n2);
子查询在布尔表达式中的使用
- 使用=、>、<、>=、<=、<>、!=、<=>作为布尔表达式的操作符
我们就把这些操作符称为comparison_operator吧,所以子查询组成的布尔表达式就长这样:
操作数 comparison_operator (子查询)
SELECT * FROM t1 WHERE m1 < (SELECT MIN(m2) FROM t2);
或者这样(行子查询):
SELECT * FROM t1 WHERE (m1, n1) = (SELECT m2, n2 FROM t2 LIMIT 1);
- [NOT] IN/ANY/SOME/ALL子查询
- IN或者NOT IN ```sql 操作数 [NOT] IN (子查询)
SELECT * FROM t1 WHERE (m1, n1) IN (SELECT m2, n2 FROM t2);
- ANY/SOME(ANY和SOME是同义词)
```sql
操作数 comparison_operator ANY/SOME(子查询)
SELECT * FROM t1 WHERE m1 > ANY(SELECT m2 FROM t2);
等价于
SELECT * FROM t1 WHERE m1 > (SELECT MIN(m2) FROM t2);
- ALL ```sql 操作数 comparison_operator ALL(子查询)
SELECT FROM t1 WHERE m1 > ALL(SELECT m2 FROM t2); 等价于 SELECT FROM t1 WHERE m1 > (SELECT MAX(m2) FROM t2);
- EXISTS子查询
有的时候我们仅仅需要判断子查询的结果集中是否有记录,而不在乎它的记录具体是个啥,可以使用把EXISTS或者NOT EXISTS放在子查询语句前边,就像这样:
```sql
[NOT] EXISTS (子查询)
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2);
子查询语法注意事项
- 子查询必须用小括号扩起来 ```sql mysql> SELECT SELECT m1 FROM t1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘SELECT m1 FROM t1’ at line 1
- 在SELECT子句中的子查询必须是标量子查询
```sql
mysql> SELECT (SELECT m1, n1 FROM t1);
ERROR 1241 (21000): Operand should contain 1 column(s)
- 在想要得到标量子查询或者行子查询,但又不能保证子查询的结果集只有一条记录时,应该使用LIMIT 1语句来限制记录数量。
- 对于[NOT] IN/ANY/SOME/ALL子查询来说,子查询中不允许有LIMIT 语句。 ```sql mysql> SELECT FROM t1 WHERE m1 IN (SELECT FROM t2 LIMIT 2);
ERROR 1235 (42000): This version of MySQL doesn’t yet support ‘LIMIT & IN/ALL/ANY/SOME subquery’
子查询中的这些语句也就是多余的
- ORDER BY子句
> SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2 ORDER BY m2);
- DISTINCT语句
> SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2 ORDER BY m2);
- 没有聚集函数以及HAVING子句的GROUP BY子句
> SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2 GROUP BY m2);
- 不允许在一条语句中增删改某个表的记录时同时还对该表进行子查询
```sql
mysql> DELETE FROM t1 WHERE m1 < (SELECT MAX(m1) FROM t1);
ERROR 1093 (HY000): You can't specify target table 't1' for update in FROM clause
子查询在MySQL中是怎么执行的
标量子查询、行子查询的执行方式
- 不相关标量子查询或者行子查询 ```sql
SELECT * FROM s1 WHERE key1 = (SELECT common_field FROM s2 WHERE key3 = ‘a’ LIMIT 1);
它的执行方式就是这样的:
- 先单独执行(SELECT common_field FROM s2 WHERE key3 = 'a' LIMIT 1)这个子查询。
- 然后在将上一步子查询得到的结果当作外层查询的参数再执行外层查询SELECT * FROM s1 WHERE key1 = ...。
- 相关标量子查询或者行子查询
```sql
SELECT * FROM s1 WHERE
key1 = (SELECT common_field FROM s2 WHERE s1.key3 = s2.key3 LIMIT 1);
它的执行方式就是这样的:
- 先从外层查询中获取一条记录,本例中也就是先从s1表中获取一条记录。
- 然后从上一步骤中获取的那条记录中找出子查询中涉及到的值,本例中就是从s1表中获取的那条记录中找出s1.key3列的值,然后执行子查询。
- 最后根据子查询的查询结果来检测外层查询WHERE子句的条件是否成立,如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。
- 再次执行第一步,获取第二条外层查询中的记录,依次类推~
IN子查询优化
物化表的提出
不直接将不相关子查询的结果集当作外层查询的参数,而是将该结果集写入一个临时表里。写入临时表的过程是这样的SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
- 该临时表的列就是子查询结果集中的列。
- 写入临时表的记录会被去重。
- 一般情况下子查询结果集不会大的离谱,所以会为它建立基于内存的使用Memory存储引擎的临时表,而且会为该表建立哈希索引。
如果子查询的结果集非常大,超过了系统变量tmp_table_size或者max_heap_table_size,临时表会转而使用基于磁盘的存储引擎来保存结果集中的记录,索引类型也对应转变为B+树索引。
把这个将子查询结果集中的记录保存到临时表的过程称之为物化(英文名:Materialize)。为了方便起见,我们就把那个存储子查询结果集的临时表称之为物化表。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行IN语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
物化表转连接
SELECT * FROM s1
WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
当我们把子查询进行物化之后,假设子查询物化表的名称为materialized_table,该物化表存储的子查询结果集的列为m_val
- 从表s1的角度来看待
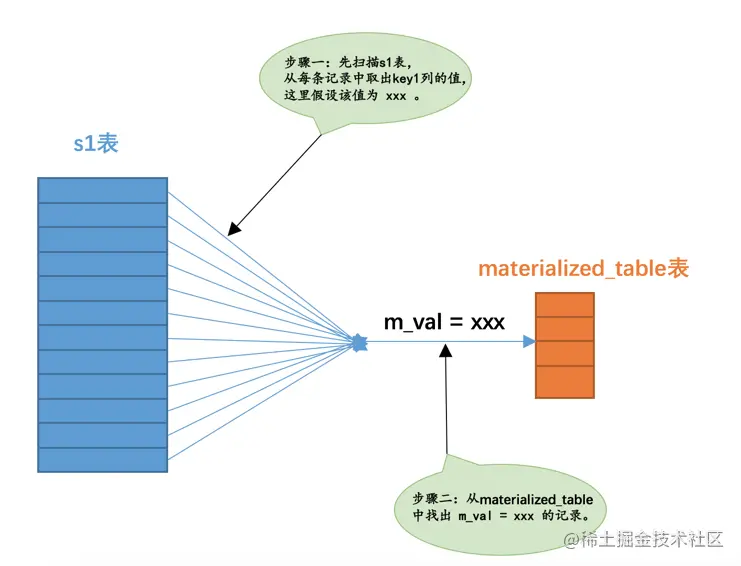
- 从子查询物化表的角度来看待

将子查询转换为semi-join
SELECT * FROM s1
WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');
SELECT s1.* FROM s1 INNER JOIN s2
ON s1.key1 = s2.common_field
WHERE s2.key3 = 'a';
只不过我们不能保证对于s1表的某条记录来说,在s2表(准确的说是执行完WHERE s2.key3 = ‘a’之后的结果集)中有多少条记录满足s1.key1 = s2.common_field这个条件,不过我们可以分三种情况讨论:
- 情况一:对于s1表的某条记录来说,s2表中没有任何记录满足s1.key1 = s2.common_field这个条件,那么该记录自然也不会加入到最后的结果集。
- 情况二:对于s1表的某条记录来说,s2表中有且只有1条记录满足s1.key1 = s2.common_field这个条件,那么该记录会被加入最终的结果集。
- 情况三:对于s1表的某条记录来说,s2表中至少有2条记录满足s1.key1 = s2.common_field这个条件,那么该记录会被多次加入最终的结果集。
对于s1表的某条记录来说,由于我们只关心s2表中是否存在记录满足s1.key1 = s2.common_field这个条件,而不关心具体有多少条记录与之匹配,又因为有情况三的存在,我们上边所说的IN子查询和两表连接之间并不完全等价。但是将子查询转换为连接又真的可以充分发挥优化器的作用,所以设计MySQL的大叔在这里提出了一个新概念 —- 半连接(英文名:semi-join)。将s1表和s2表进行半连接的意思就是:对于s1表的某条记录来说,我们只关心在s2表中是否存在与之匹配的记录,而不关心具体有多少条记录与之匹配,最终的结果集中只保留s1表的记录
实现方法:
- Table pullout (子查询中的表上拉)
当子查询的查询列表处只有主键或者唯一索引列时,可以直接把子查询中的表上拉到外层查询的FROM子句中,并把子查询中的搜索条件合并到外层查询的搜索条件中
SELECT * FROM s1
WHERE key2 IN (SELECT key2 FROM s2 WHERE key3 = 'a');
SELECT s1.* FROM s1 INNER JOIN s2
ON s1.key2 = s2.key2
WHERE s2.key3 = 'a';
为啥当子查询的查询列表处只有主键或者唯一索引列时,就可以直接将子查询转换为连接查询呢?哎呀,主键或者唯一索引列中的数据本身就是不重复的嘛!所以对于同一条s1表中的记录,你不可能找到两条以上的符合s1.key2 = s2.key2的记录呀~
DuplicateWeedout execution strategy (重复值消除)
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');转换为半连接查询后,s1表中的某条记录可能在s2表中有多条匹配的记录,所以该条记录可能多次被添加到最后的结果集中,为了消除重复,我们可以建立一个临时表,比方说这个临时表长这样:
CREATE TABLE tmp ( id PRIMARY KEY );
这样在执行连接查询的过程中,每当某条s1表中的记录要加入结果集时,就首先把这条记录的id值加入到这个临时表里,如果添加成功,说明之前这条s1表中的记录并没有加入最终的结果集,现在把该记录添加到最终的结果集;如果添加失败,说明之前这条s1表中的记录已经加入过最终的结果集,这里直接把它丢弃就好了,这种使用临时表消除semi-join结果集中的重复值的方式称之为DuplicateWeedout。LooseScan execution strategy (松散扫描)
SELECT * FROM s1 WHERE key3 IN (SELECT key1 FROM s2 WHERE key1 > 'a' AND key1 < 'b');在子查询中,对于s2表的访问可以使用到key1列的索引,而恰好子查询的查询列表处就是key1列,这样在将该查询转换为半连接查询后,如果将s2作为驱动表执行查询的话,那么执行过程就是这样:
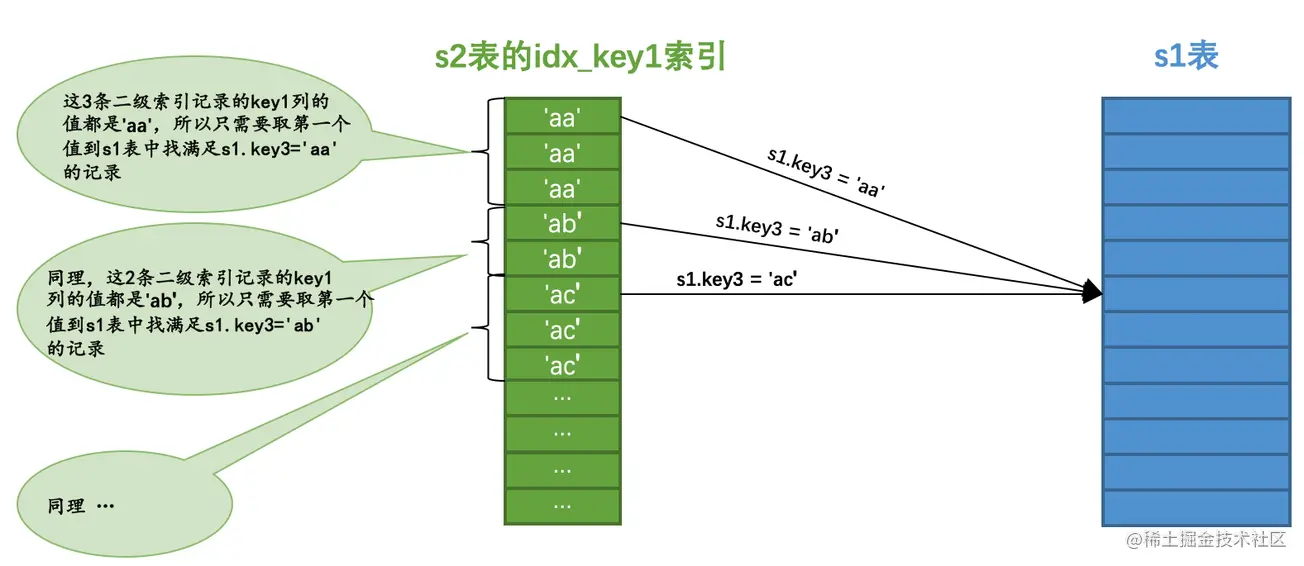
Semi-join Materialization execution strategy
我们之前介绍的先把外层查询的IN子句中的不相关子查询进行物化,然后再进行外层查询的表和物化表的连接本质上也算是一种semi-join,只不过由于物化表中没有重复的记录,所以可以直接将子查询转为连接查询。
- FirstMatch execution strategy (首次匹配)
FirstMatch是一种最原始的半连接执行方式,跟我们年少时认为的相关子查询的执行方式是一样一样的,就是说先取一条外层查询的中的记录,然后到子查询的表中寻找符合匹配条件的记录,如果能找到一条,则将该外层查询的记录放入最终的结果集并且停止查找更多匹配的记录,如果找不到则把该外层查询的记录丢弃掉;然后再开始取下一条外层查询中的记录,重复上边这个过程。
对于某些使用IN语句的相关子查询,
比方这个查询:
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE s1.key3 = s2.key3);
它也可以很方便的转为半连接,转换后的语句类似这样:
SELECT s1.* FROM s1 SEMI JOIN s2 ON s1.key1 = s2.common_field AND s1.key3 = s2.key3;
然后就可以使用我们上边介绍过的DuplicateWeedout、LooseScan、FirstMatch等半连接执行策略来执行查询,当然,如果子查询的查询列表处只有主键或者唯一二级索引列,还可以直接使用table pullout的策略来执行查询,但是需要大家注意的是,由于相关子查询并不是一个独立的查询,所以不能转换为物化表来执行查询
semi-join的适用条件
用文字总结一下,只有符合下边这些条件的子查询才可以被转换为semi-join:
- 该子查询必须是和IN语句组成的布尔表达式,并且在外层查询的WHERE或者ON子句中出现。
- 外层查询也可以有其他的搜索条件,只不过和IN子查询的搜索条件必须使用AND连接起来。
- 该子查询必须是一个单一的查询,不能是由若干查询由UNION连接起来的形式。
该子查询不能包含GROUP BY或者HAVING语句或者聚集函数。
不适用于semi-join的情况
外层查询的WHERE条件中有其他搜索条件与IN子查询组成的布尔表达式使用OR连接起来
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a') OR key2 > 100;使用NOT IN而不是IN的情况
SELECT * FROM s1 WHERE key1 NOT IN (SELECT common_field FROM s2 WHERE key3 = 'a')在SELECT子句中的IN子查询的情况
SELECT key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a') FROM s1 ;子查询中包含GROUP BY、HAVING或者聚集函数的情况
SELECT * FROM s1 WHERE key2 IN (SELECT COUNT(*) FROM s2 GROUP BY key1);子查询中包含UNION的情况
SELECT * FROM s1 WHERE key1 IN ( SELECT common_field FROM s2 WHERE key3 = 'a' UNION SELECT common_field FROM s2 WHERE key3 = 'b' );优化不能转为semi-join查询的子查询
对于不相关子查询来说,可以尝试把它们物化之后再参与查询
不管子查询是相关的还是不相关的,都可以把IN子查询尝试转为EXISTS子查询
小结一下
如果IN子查询符合转换为semi-join的条件,查询优化器会优先把该子查询转换为semi-join,然后再考虑下边5种执行半连接的策略中哪个成本最低:选择成本最低的那种执行策略来执行子查询。
- Table pullout
- DuplicateWeedout
- LooseScan
- Materialization
- FirstMatch
- 如果IN子查询不符合转换为semi-join的条件,那么查询优化器会从下边两种策略中找出一种成本更低的方式执行子查询:
- 先将子查询物化之后再执行查询
- 执行IN to EXISTS转换。
ANY/ALL子查询优化
| 原始表达式 | 转换为 | | —- | —- | | < ANY (SELECT inner_expr …) | < (SELECT MAX(inner_expr) …) | | > ANY (SELECT inner_expr …) | > (SELECT MIN(inner_expr) …) | | < ALL (SELECT inner_expr …) | < (SELECT MIN(inner_expr) …) | | > ALL (SELECT inner_expr …) | > (SELECT MAX(inner_expr) …) |
[NOT] EXISTS子查询的执行
对于派生表的优化
SELECT * FROM (
SELECT id AS d_id, key3 AS d_key3 FROM s2 WHERE key1 = 'a'
) AS derived_s1 WHERE d_key3 = 'a';
对于含有派生表的查询,MySQL提供了两种执行策略:
- 最容易想到的就是把派生表物化。
使用了一种称为延迟物化的策略,也就是在查询中真正使用到派生表时才回去尝试物化派生表,而不是还没开始执行查询呢就把派生表物化掉
- 将派生表和外层的表合并,也就是将查询重写为没有派生表的形式
当派生表中有这些语句就不可以和外层查询合并:
- 聚集函数,比如MAX()、MIN()、SUM()啥的
- DISTINCT
- GROUP BY
- HAVING
- LIMIT
- UNION 或者 UNION ALL
- 派生表对应的子查询的SELECT子句中含有另一个子查询
所以MySQL在执行带有派生表的时候,优先尝试把派生表和外层查询合并掉,如果不行的话,再把派生表物化掉执行查询

若有收获,就点个赞吧
0 人点赞
