访问方法(access method)的概念
(all) 使用全表扫描进行查询这种执行方式很好理解,就是把表的每一行记录都扫一遍嘛,把符合搜索条件的记录加入到结果集就完了。不管是啥查询都可以使用这种方式执行,当然,这种也是最笨的执行方式。
使用索引进行查询因为直接使用全表扫描的方式执行查询要遍历好多记录,所以代价可能太大了。如果查询语句中的搜索条件可以使用到某个索引,那直接使用索引来执行查询可能会加快查询执行的时间。使用索引来执行查询的方式五花八门,又可以细分为许多种类:
- 针对主键或唯一二级索引的等值查询 const
- 针对普通二级索引的等值查询 ref
- 针对普通二级索引的等值查询和该列的值为NULL ref_or_null
- 针对索引列的范围查询 range
- 直接扫描整个索引 index
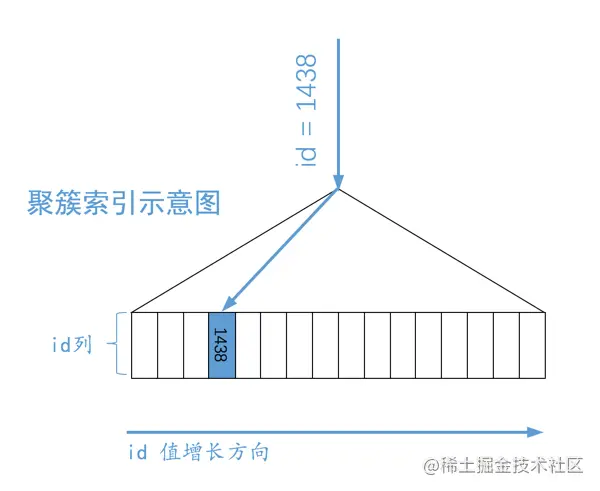
const
针对主键或唯一二级索引的等值查询
SELECT * FROM single_table WHERE id = 3841;
SELECT * FROM single_table WHERE key2 = 3841;
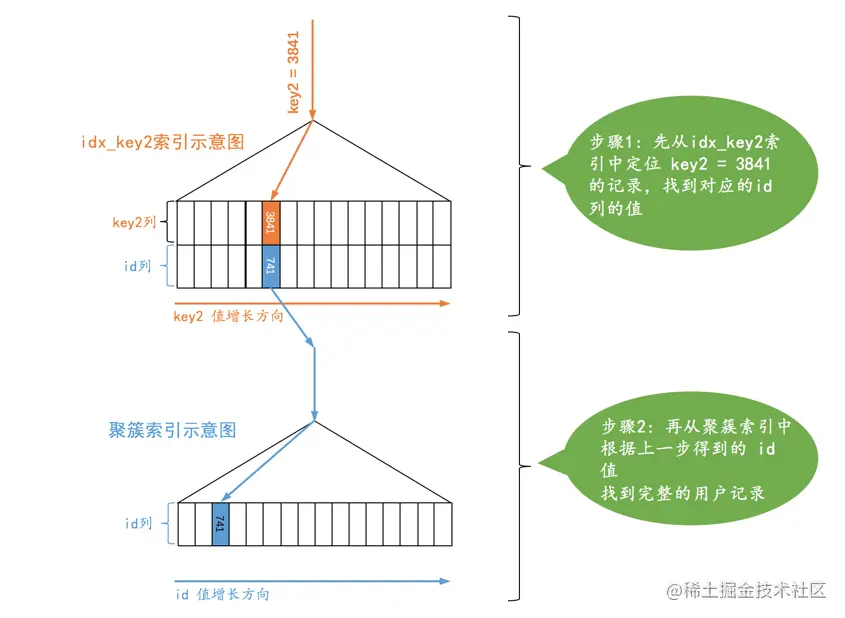
对于唯一二级索引来说,查询该列为NULL值的情况比较特殊,比如这样:
SELECT * FROM single_table WHERE key2 is NULL;
ref
针对普通二级索引的等值查询
SELECT * FROM single_table WHERE key1 = 'abc';
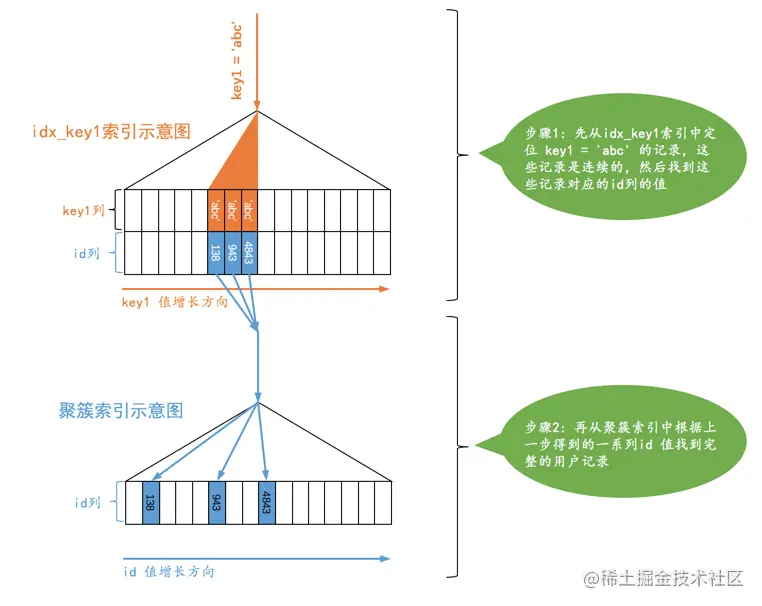
ref_or_null
二级索引列的值等于某个常数的记录,还想把该列的值为NULL
SELECT * FROM single_table WHERE key1 = 'abc' OR key1 IS NULL;
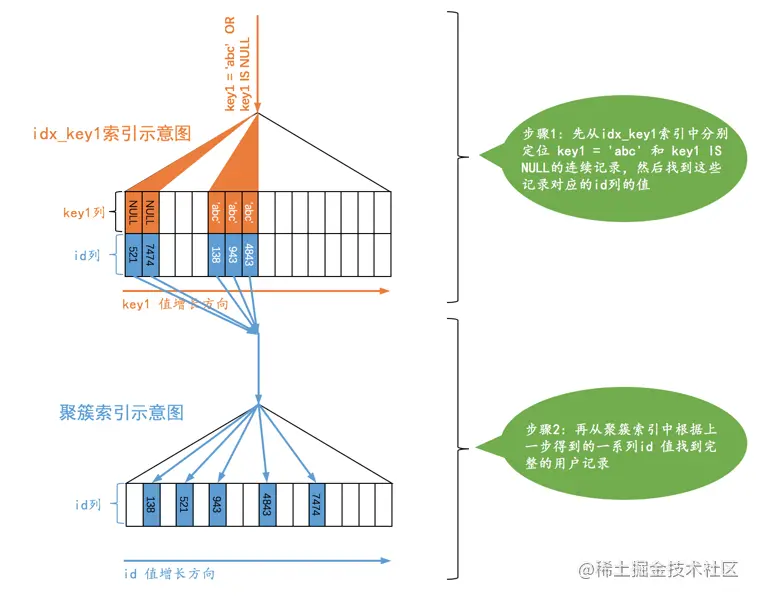
range
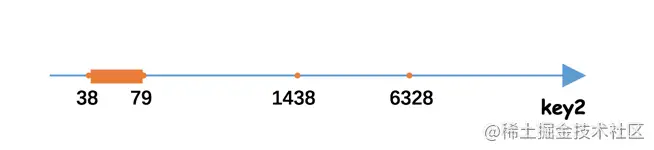
- 针对索引列的范围查询
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
index
遍历二级索引记录的执行SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
注意事项
重温 二级索引 + 回表
一般情况下只能利用单个二级索引执行查询SELECT * FROM single_table WHERE key1 = 'abc' AND key2 > 1000;
明确range访问方法使用的范围区间
其实对于B+树索引来说,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以写成<>)或者LIKE操作符连接起来,就可以产生一个所谓的区间。
我们在为某个索引确定范围区间的时候只需要把用不到相关索引的搜索条件替换为TRUE就好了
之所以把用不到索引的搜索条件替换为TRUE,是因为我们不打算使用这些条件进行在该索引上进行过滤,所以不管索引的记录满不满足这些条件,我们都把它们选取出来,待到之后回表的时候再使用它们过滤。
例如:
SELECT * FROM single_table WHERE(key1 > 'xyz' AND key2 = 748 ) OR(key1 < 'abc' AND key1 > 'lmn') OR(key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc')) ;
假设我们使用idx_key1执行查询
//简化(key1 > 'xyz' AND TRUE ) OR(key1 < 'abc' AND key1 > 'lmn') OR(TRUE AND key1 > 'zzz' AND (TRUE OR TRUE))//化简一下上边的搜索条件就是下边这样:(key1 > 'xyz') OR(key1 < 'abc' AND key1 > 'lmn') OR(key1 > 'zzz')//替换掉永远为TRUE或FALSE的条件(key1 > 'xyz') OR (key1 > 'zzz')//最后得到(key1 > 'zzz'
索引合并
Intersection合并
Intersection翻译过来的意思是交集
SELECT * FROM single_table WHERE key1 = 'a' AND key3 = 'b';
假设这个查询使用Intersection合并的方式执行的话,那这个过程就是这样的:
- 从idx_key1二级索引对应的B+树中取出key1 = ‘a’的相关记录。
- 从idx_key3二级索引对应的B+树中取出key3 = ‘b’的相关记录。
- 二级索引的记录都是由索引列 + 主键构成的,所以我们可以计算出这两个结果集中id值的交集。
- 按照上一步生成的id值列表进行回表操作,也就是从聚簇索引中把指定id值的完整用户记录取出来,返回给用户。
MySQL在某些特定的情况下才可能会使用到Intersection索引合并:
情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的
-
Union合并
```sql SELECT * FROM single_table WHERE key1 = ‘a’ OR key3 = ‘b’;
MySQL在某些特定的情况下才可能会使用到Union索引合并:- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。- 情况二:主键列可以是范围匹配- 情况三:使用Intersection索引合并的搜索条件<a name="TKEkO"></a>### Sort-Union合并```sqlSELECT * FROM single_table WHERE key1 < 'a' OR key3 > 'z'
这是因为根据key1 < ‘a’从idx_key1索引中获取的二级索引记录的主键值不是排好序的,根据key3 > ‘z’从idx_key3索引中获取的二级索引记录的主键值也不是排好序的,但是key1 < ‘a’和key3 > ‘z’这两个条件又特别让我们动心,所以我们可以这样:
- 先根据key1 < ‘a’条件从idx_key1二级索引中获取记录,并按照记录的主键值进行排序
- 再根据key3 > ‘z’条件从idx_key3二级索引中获取记录,并按照记录的主键值进行排序
- 因为上述的两个二级索引主键值都是排好序的,剩下的操作和Union索引合并方式就一样了。
索引合并注意事项
联合索引替代Intersection索引合并
连接简介
连接的本质
连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户(笛卡尔积)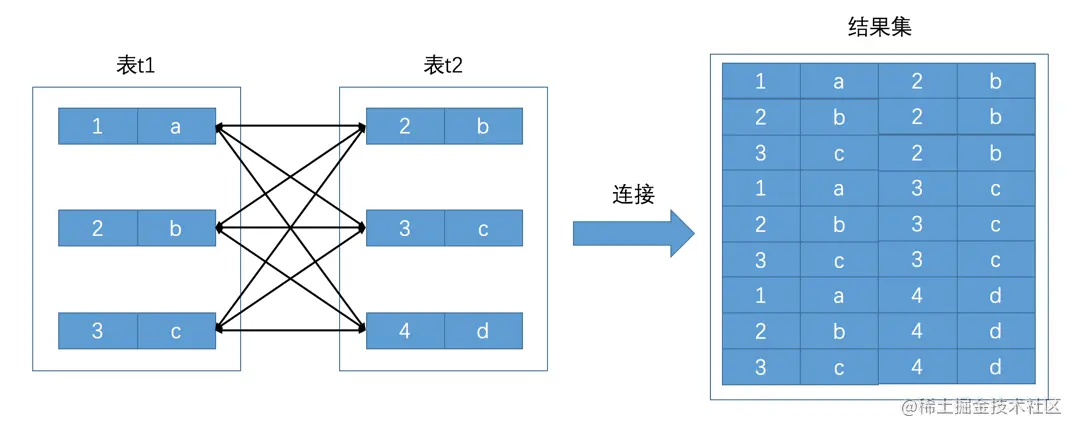
连接过程简介
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
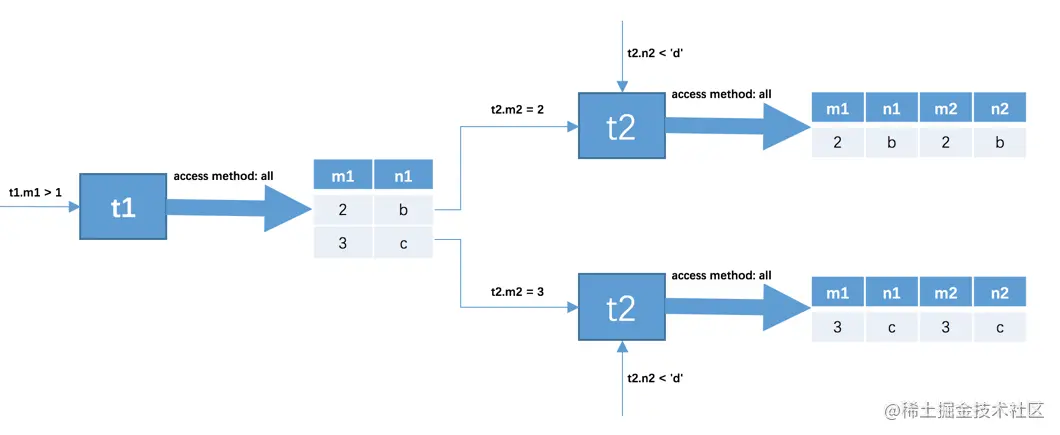
内连接和外连接
内连接和外连接的概念:
- 对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
- 对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
过滤条件
- WHERE子句中的过滤条件
WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
- ON子句中的过滤条件
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。
需要注意的是,这个ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把ON子句放到内连接中,MySQL会把它和WHERE子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到WHERE子句中,把涉及两表的过滤条件都放到ON子句中,我们也一般把放到ON子句中的过滤条件也称之为连接条件。
连接的原理
嵌套循环连接(Nested-Loop Join)
驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join)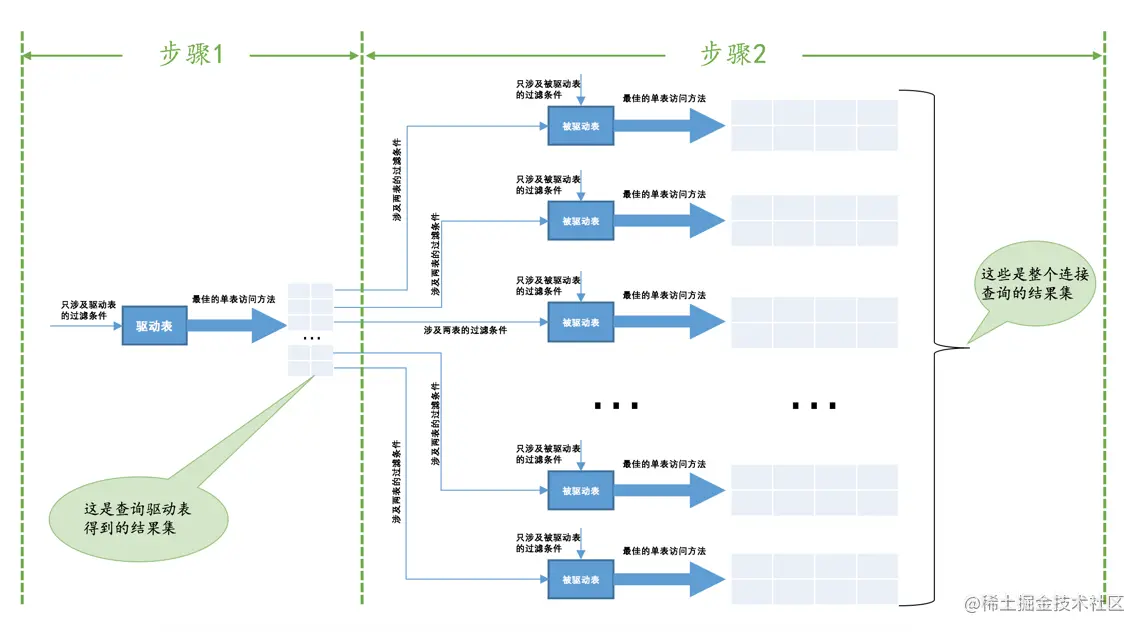
基于块的嵌套循环连接(Block Nested-Loop Join)
join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价

若有收获,就点个赞吧
0 人点赞
