- 前沿
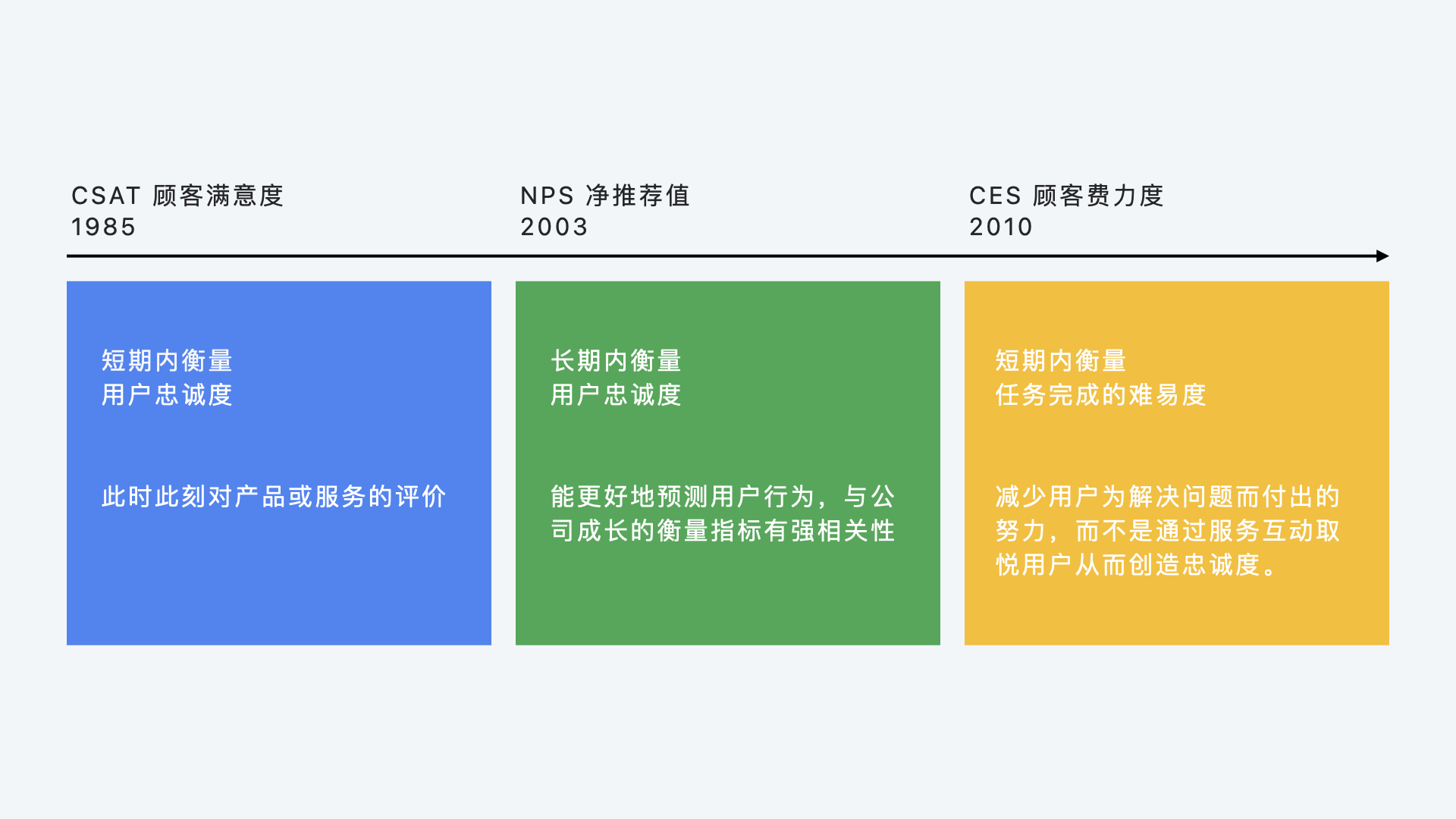
- 度量历史
- 度量标准
- 第一阶段
- 第二阶段
- 1992 PSSUQ 研究后系统可用性问卷 Post-Study System Usability Questionnaire
- ">
- 1993 ASQ 场景后问卷
- 1994 10 Usability Heuristics 尼克森十大可用性原则
- 1994 ACSI 顾客满意度
- 1995 CSUQ
- 1995 WAMMI 网站分析和测量问卷
- 199? SEQ 单项难易度问卷 Single Ease Question,SEQ
- 1998 ISO-9241-11 国际标准可用性测试
- 2001 USE 量表
- 2002 WQ 网络质量问卷
- 2002 反应卡片 Desirability Testing
- 2003 NPS 净推荐值
- 2007 WU 网络可用性问卷
- 2010 CES 用户费力度
- 2010 UMUX 用户体验可用性指标 The Usability Metric for User Experience
- 问卷的通用问题
- 第三阶段
- 度量特点
- 度量形式
- 寻找度量用户体验的核心指标
- 相关书籍📚
- 参考文章📚
- 整理文章参考
从专业角度,这一块是比较薄弱的环节。计划分为专业知识的了解(305)+典型案例的学习(304)+闭环(302)+拓展(304)= 预计需要好几周的时间来学习这个模块。慢慢来,没有人催我们 2022年的到来,关于用户体验度量需要实际在工作当中运用,所以时间也是比较的紧迫。
前沿
度量,英文名 Measure,是一种测量或评价特定现象或事物的方法,我们可以说某个东西较远较高较快,那是因为我们能够测量或量化它的某些属性,比如距离、高度或速度,这需要在一个恒定可靠的测量方法。不管是用卷尺还是直尺,10 厘米就是 10 厘米;不管是用秒表还是手机 App,10 秒就是 10 秒;不管是称铁还是称棉花,10 公斤就是 10 公斤。
度量存在于我们生活的许多领域,每一种行业、活动和文化都有自身的一系列度量。比如,汽车行业对汽车的马力、油耗和材料的成本等感兴趣,计算机行业则关心 CPU、GPU、RAM、ROM。
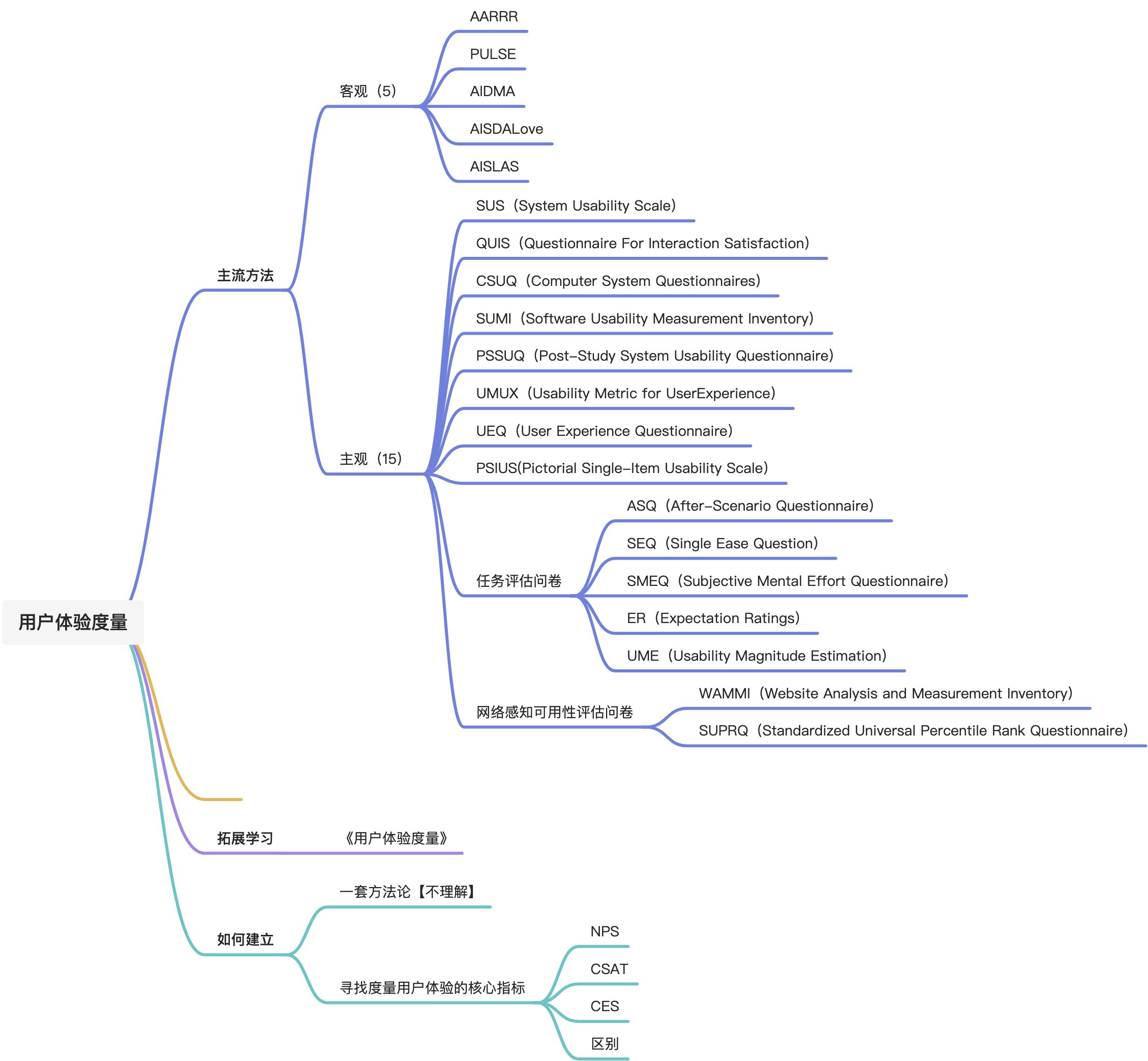
度量历史
- 第一阶段 1940-1990
- 第二阶段 1991-2010
- 第三阶段 2010-至今
度量标准
从 1940 至今,国内外较为人知的标准共有 30 个,其中第一阶段有 5 个,第二阶段有 16 个,第三阶段有 9 个。
第一阶段
- 1965 CSAT 顾客满意度 Customer Satisfaction
- 1986 SUS 系统可用性量表
- 1987 CUSI 用户满意度问卷
- 1987 QUIS 用户界面满意度问卷
- 1988 NASA-TLX NASA任务负荷问卷NASA
- 1989 TAM 技术接受度模型
1965 CSAT 顾客满意度 Customer Satisfaction
由 Parasuraman 和 Zeithaml 于 1965 年提出,CSAT 是市场营销中经常使用的术语,它是衡量一个公司提供的产品和服务是否满足或超过用户期望的指标。
满意度的适用性非常高,可以用于询问用户各种问题,可以看整体的产品体验满意度,也可以看具体的某个功能的满意度。满意度能够体现出用户对产品短期内的幸福感,但缺陷是无法体现用户对产品的长期态度。
CSAT 通常是七点量表,当然也有五点量表,只有一道题,向顾客提问「你对我们的产品满意吗?」,通过计算选择 6 分 和 7 分的用户所占比例得出分数。

1986 SUS 系统可用性量表 System Usability Scale
由 John Brooke 于 1986 年在 Digital Equipment Corporation 公司提出。尽管 John Brooke 将其描述为「快速而粗糙」的可用性问卷,但是丝毫不影响它的受欢迎程度,SUS 量表被认为是 80 年代经典的可用性问卷标准,也被认为是用户体验研究中最著名的问卷,自 1980 年代的命令行界面时代以来,SUS 一直存在,并且被大量的实验证明是有效和可靠的。全球大约43%的专业机构进行整体评估时,将SUS量表作为测试后问卷题目。SUS总共有10个问题,置信度为85%。
SUS 用于评估对整体系统的可用性,它是一份五点量表,有 10 道题目,评估维度有可用性和可学习性。
奇数项是正面描述题,偶数项是反面描述题。(正反两面有Kano模型)
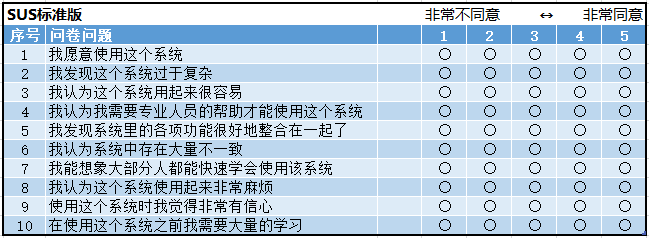
在使用SUS的过程中,可以对题目的词语进行替换,这些替换对最后的测量结果都没有影响。比如“system”可替换成网站、产品或者自己产品的名称等。
优势
SUS量表是通过大量实验为基础的量表设计,也是现在全球使用最多的整体性可行性评价量表。
- 正反语气间隔,使答案客观。SUS问卷中大家可以发现奇数问题是正面语气,偶数问题是负面语气,这样减少了被测试者的依从性,从而使结果更加客观。
- 问题可量化为百分数。正面问题转化分值为x-1,负面问题为5-x,所有题目得分后乘以5即得到分值。
- 步距为奇数。从非常不同意到非常同意,我们一般使用奇数,有很多量表也是这样规定的。因为用户可以选择一个中间状态而不像偶数那样,不具有这个中间状态。
- 快速收敛到正确结论。在对几种量表研究的同时,SUS是最快达到想要结论的量表。通常来讲,一个量表所测量出的结果与用户真实的意向具有一定的偏差,经研究SUS量表能够在不超过15个样本得到该系统的真实评价,所以该量表具有相当的灵敏性。
- SUS量表包含易学性与可用性。其中4和9是易学性,其余的表示可用性。这个两个方面代表了整体评价的2个主体方面。具体的题设数量设计,是通过大量的样本研究发现后得出的。
使用场景
- 同一个界面,完成不同的任务之间进行比较(因为有的任务可能会更难或不常使用,例如安装软件这个操作可能只需执行一次,而不像其他操作那样频繁使用;用户在完成不同类型和难度的任务之后,分别评多次SUS的分数,然后再进行对比,因为如果所有任务只评一个SUS分数的话,可能会因为某些任务较难而降低了评分);
- 同一个界面,先后不同版本之间进行比较(不过需要注意的是增加新功能或改版后,用户在初期可能会不适应,而导致SUS在短期内会下降,但长期会回升)
- 备用方案之间、竞品之间进行比较。
- 不同种类的界面之间进行比较(例如同一个产品有PC版、WAP版、Android版、iOS版、微信小程序)
分值解读
SUS分数反映的是总体的可用性,单独抽取某个题目的得分在产品之间作横向比较意义不大
针对SUS心理测试特征进行的最大研究中,Bangor等(2008)对收集到的2324份SUS问卷进行了因子分析,进而得出结论:SUS量表只有一个显著因子。Lewis和Sauro(2009)重新分析了Bangor等人的数据以及另一个来自于Lewis和Sauro(2009)的独立的SUS个案后发现,两个研究中数据的因子都聚合到两个因子中。Borsci等(2009)在同一年晚些时候使用了不同的测量模型和一批独立的数据,也得到同样的结论:SUS量表由2额因子构成:题项1、2、3、5、6、7、8、9构成因子一,题项4、10构成因子二。
Lewis和Sauro(2009)根据题目的内容将题项1、2、3、5、6、7、8、9构成的分量表命名为“可用性”,由题项4、10构成的分量表命名为“易学性”。Lewis和Sauro(2009)对数据进行分析,“可用性”子量表的可信度为0.91,“易学性”分量表的可行度为0.7。为使可用性和易学性分数能够与整体SUS量表分数兼容,范围也是0~100,需要对原始数据进行分化转化:可用性量表总分数乘以3.125,易学性量表总分数乘以12.5。
Borsci等(2015)发现SUS针对那些没有什么在线学习工具使用经验的人的分析结果呈线性结构,但对那些经验丰富的用户分析结果呈现二维性结构(可用性及易学性维度)。由于2009年以来发现了相互矛盾的实验情况,因此我们建议从业者在考虑使用可用性及可学性这两个维度的时候要格外小心,特别是当被测用户在使用产品过程中没有特别强烈的体验的时候。
如果某个界面的SUS分数为76,这表示什么?
AT&T Labs的Bangor,Kortum 和Miller在2009年发了一篇文章来解决这个问题。他们在SUS的结尾增加了1个问题(见下图),让用户使用Poor、Ok、Good等形容词来总体评价这个用户界面,其用意是想将SUS与这些形容词关连起来。
以下是每个形容词对应的SUS分数:按照这次的数据,被用户评为Good的那些界面,SUS的平均分为71.4。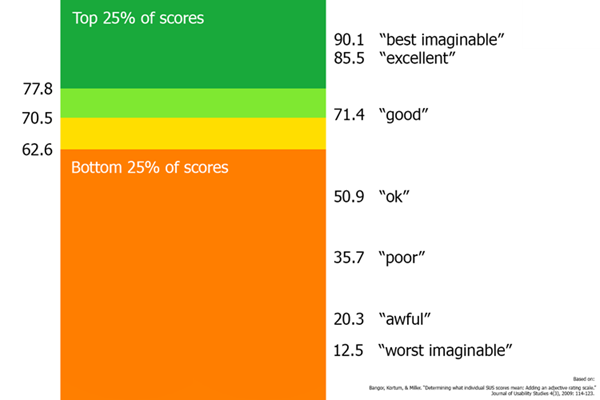
不过Bangor等人并没有明确说,是否有足够的证据来证明可以使用71.4或某个分数来判断一个产品是否合格。
除此之外,也可以将SUS分数换算成百分等级来解释,百分等级的意思是指测量的产品或系统相对于总数据库里其他产品或系统的可用性程度。比如SUS得分是73分,其百分等级大约为67,意味着比大约66%的产品可用性更好。
注意,这里的总数据库是Jeff Sauro(2011)通过446个研究,超过5000个用户的SUS反馈的数据库。如果从企业研究团队的角度来看,可以沉淀以往的研究,建立企业自己产品或系统的SUS数据库,从而获得自身的基准数据,当然,这个基准数据也有可能是内部团队制定。在这个分数库中,如果SUS得分为74,那么它比500多个界面中的70%都要高(见下图):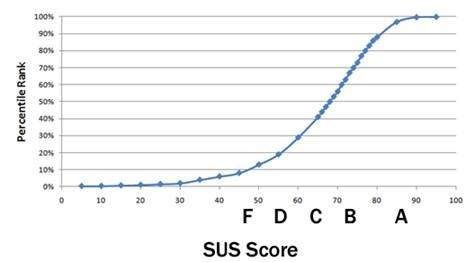
本质上,百分等级用于说明你的应用程序相对于总数据库里其他产品的可用性程度。在表格中找到最接近你SUS值的分数,然后查看对应评级和百分等级。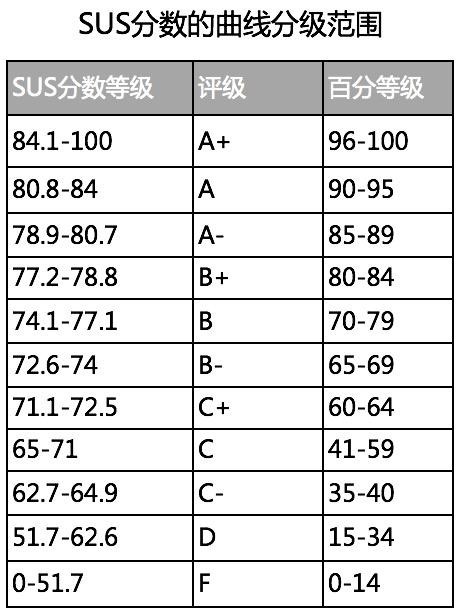
参考链接:
- SUS: A Quick and Dirty Usability Scale by John Brooke
- Measuring Usability with the System Usability Scale (SUS) by Jeff Sauro
- SUS: A Retrospective by John Brooke
- Determining What Individual SUS Scores Mean: Adding an Adjective Rating Scale by Kortum Bangor and Miller May
1987 CUSI 用户满意度问卷
1987 QUIS 用户界面满意度问卷 Questionnaire for User Interface Satisfaction
中文名用户界面满意度问卷,由人机交互实验室 Human-Computer Interface 于 1987 年在马里兰大学 University of Maryland 提出。
时至今日,QUIS 迭代了 7 个版本,最新的版本是九点量表,
简短版本有27 个评价项目,分为11个类别
- 总体反应
- 屏幕因素 Screen Factors。
- 术语和系统反馈 Terminology and System Feedback。
- 学习因素 Learning Factors。
- 系统能力 System Capabilities。
- 技术手册 Technical Manuals。
- 在线教程 Online Tutorials。
- 多媒体 Multimedia。
- 语音识别 Voice Recognition。
- 虚拟环境 Virtual Environments。
- 互联网访问 Internet Access。
- 软件安装 Software Installation。
图为简短版本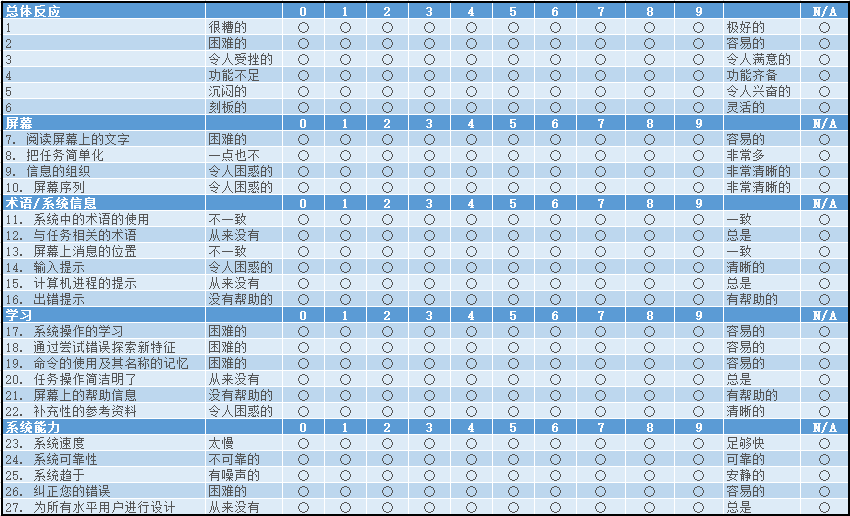
官方网站:http://lap.umd.edu/quis/
1988 NASA-TLX NASA任务负荷问卷NASA
1988 年,NASA 人类绩效小组的 Sandra G. Hart 和圣何塞州立大学的 Lowell E. Staveland 引入了任务负荷指数。自 1988 年以来,它的引用次数已超过 8,000 次,其传播范围已远远超出其最初在航空、焦点和英语方面的应用(Hart,2006 年)。
NASA-TLX 估计一个或多个用户感知的认知需求,这有助于衡量系统的可用性、有效性或舒适度。“自发产生的直接的、通常未用语言表达的印象”(Hart & Staveland, 1988)特别有趣,因为它们 要么难以客观地观察,要么不可能被客观地观察。研究人员根本无法通过观察获得他们想要的信息。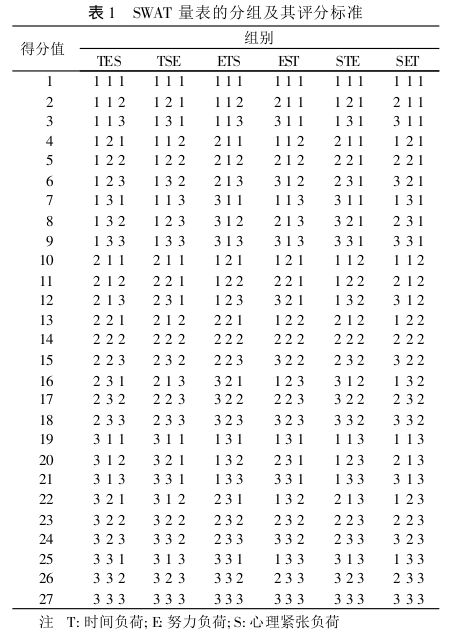
六个维度表
NASA-TLX 是一个多维尺度。这意味着,有六个子量表最终构成一个整体 NASA-TLX 分数(Hart & Staveland,1988):
- 心理——需要多少心理和知觉活动?任务是容易的还是苛刻的,简单的还是复杂的,严格的还是宽容的?
- 体力——需要多少体力活动?这项任务是容易的还是要求高的?慢还是快?松懈还是紧张?安逸还是辛苦?
- 时间 - 由于任务或任务元素发生的速度或节奏,您感受到了多少时间压力?步伐是缓慢而悠闲,还是快速而疯狂?
- 挫败感——你在任务中感到不安全、沮丧、烦躁、压力和恼火与安全、满足、满足、放松和自满相比有多大?
- 努力——你必须付出多大的努力(精神上和身体上)才能达到你的表现水平?
- 表现——你认为你在完成实验者(或你自己)设定的任务目标方面有多成功?您的满意程度如何?
值得注意的是,用户可以从多个角度解释“工作负载”这个词。最初,哈特假设这些观点的某种组合可能代表“大多数人”和“大多数场景”(Hart,2006)。为了考虑到这种预期的灵活性,Hart 采用了一种加权方案,以确保强调对每个用户最关键的尺寸。
对 NASA-TLX 的修改
已经有各种尝试修改 NASA-TLX。一些研究添加了子量表,而另一些则删除了它们。这是值得称赞的,但它确实“需要在使用新工具之前确定其有效性、敏感性和可靠性”(Hart,2006 年)。
最常见的适配称为 Raw TLX (RTLX),其中完全省略了加权过程。RTLX 之所以吸引人,原因显而易见:总体工作量估计就像结合每个子量表的分数一样简单。换句话说,除了简单的总和之外,不需要任何计算(Hart,2006)。
在各种研究将其与原始 TLX 进行比较之前,RTLX 的普及和使用一直受到批评。在对这 29 项研究的有趣总结中,Hart 写道,RTLX 被发现“要么更敏感 (Hendy, Hamilton, & Landry, 1993),要么不敏感 (Liu & Wickens, 1994),要么同样敏感 (Byers, Bittner , Hill, 1989),所以看来你可以选择”(Hart, 2006)。
好处
有效的:
NASA-TLX 及其子量表充分代表了不同任务中认知工作量的来源。Hart 和 Staveland 不仅在 1988 年的论文中验证了他们的测量方法,独立研究还发现 TLX 是衡量主观工作量的有效方法(Hart 和 Staveland,1988;Rubio 等人,2004;Xiao 等人,2005) .
适用于多个域:
NASA-TLX 适用于许多领域。最初,它旨在用于航空,但很快扩展到空中交通管制、民用和军用驾驶舱、机器人和无人驾驶车辆。后来,汽车、医疗保健和技术领域的研究使用了 TLX(Hart,2006)。
诊断-ish:
TLX 具有以前意想不到的优势,因为它具有一些诊断能力。虽然原始量表会产生一个总分,但子量表的存在有助于确定工作量的具体来源(Hart,2006)。此功能 对于希望 改进其设计的开发人员非常有帮助。
高度可访问性:
除了被翻译成至少 12 种语言之外,NASA-TLX 还可以在各种“媒介”中进行管理。纸和铅笔仍然很受欢迎,但 TLX 已集成到计算机软件包、iOS 应用程序和 Android 应用程序中。这些选项中的每一个都是完全免费的,这很重要。
缺点
记忆:
在任务期间要求用户完成量表可能会相当麻烦。不幸的是,等到任务完成可能会导致一系列问题。用户很容易忘记任务的各种细节。由于人类的记忆在许多情况下都被证明会恶化,因此从相关任务到 TLX 本身之间的时间并不理想。
任务绩效可能会影响评级:
用户对他或她自己的任务表现的看法会严重影响各种评级。如果他们认为自己完成了任务,工作量评级往往会被夸大。同样,如果用户察觉到任务失败,工作负载评级往往会降低。理想情况下,无论任务性能如何,用户都会对每个子量表进行相同的评价。
主观:
NASA-TLX 是对用户感知认知工作量的主观衡量,仅此而已。重要的是,它不是衡量使用系统所需的认知工作量的指标,无论它多么耸人听闻。使用 TLX 的从业者必须准确地记住他们正在测量的内容,也不应将感知到的工作负载评级视为其他任何东西。
文章链接:https://research-collective.com/nasa-tlx/
1989 TAM 技术接受度模型
技术接受模型(Technology Acceptance Model,TAM)是由美国学者戴维斯(Fred D. Davis, 1986)根据理性行为理论(Theory of Reasoned Action,简称TRA)在信息系统/计算机技术领域发展而来,用于解释和预测人们对信息技术的接受程度。
技术接受模型主张,人对信息科技的使用受其行为意图的影响,用来探讨外部因素对使用者的内部信念(beliefs)、态度(attitudes)及意向(intentions)的影响,两者进而影响信息系统使用的情况(Davis, 1989)。该理论认为,当用户面对一个新的技术时,感知有用性和感知易用性是两个主要的决定因素,如下图所示。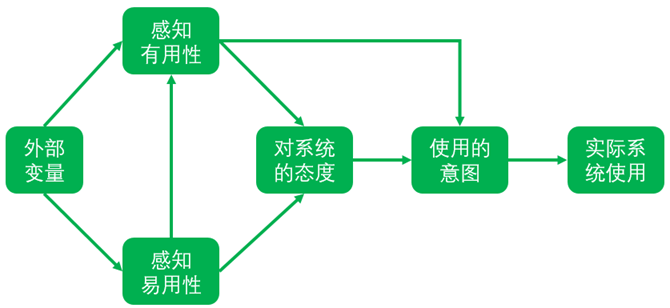
技术接受模型
- 感知易用性(Perceived ease-of-use,简称PEOU):指使用者认知到科技容易使用的程度,当系统越容易使用时,使用者对于自我效能与自我控制会更具信心,对系统所持态度也会更积极。
- 感知有用性(Perceived usefulness,简称PU):指使用者相信使用某系统会增加其工作绩效或所能省下努力的程度。使用者认知系统容易被使用时,会促进使用者以相同的努力完成更多的工作,因此认知有用同时受到认知易用与外部变量的影响。
- 用户的感知易用性越高,其使用态度倾向越积极。同时用户的感知易用性越高,其感知有用性也越大。
TAM问卷内容
TAM的题项采用7个步距,从“很可能”到“不可能”,每个都是文字标签而非数字标签。示例:
具体题项为: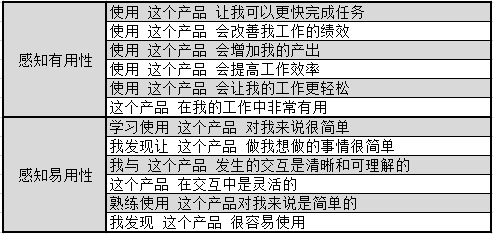
总结:这个调查问可能更加适合工具类的软件或应用。对于娱乐类的应用在评判有用性方面可能存在一定的不适用。
第二阶段
- 1992 PSSUQ 研究后系统可用性问卷 Post-Study System Usability Questionnaire
- 1993 ASQ 场景后问卷
- 1994 10 Usability Heuristics 尼克森十大可用性原则
- 1994 ACSI 顾客满意度
- 1995 CSUQ
- 1995 WAMMI 网站分析和测量问卷
- 199? SEQ 单项难易度问卷
- 1998 ISO-9241-11 国际标准可用性测试
- 2001 USE 量表
- 2002 WQ 网络质量问卷
- 2002 反应卡片 Desirability Testing
- 2003 NPS 净推荐值
- 2006
- 2007 WU 网络可用性问卷
- 2010 CES 用户费力度
- 2010 UMUX 用户体验可用性指标
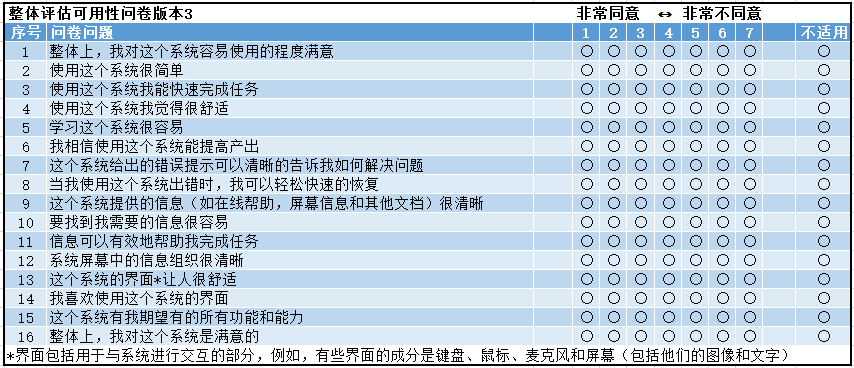
1992 PSSUQ 研究后系统可用性问卷 Post-Study System Usability Questionnaire
PSSUQ 起源于 IBM 1998 年名为「SUMS」的内部项目,时至今日,PSSUQ 迭代了 3 个版本,版本一有 18 道题目,版本二有 19 道题目,版本三有 16 道题目,由 James Lewis 于 1992 年在 IBM 公司提出。 问卷用于评估用户对计算机系统或应用程序锁感知的满意度。
PSSUQ 被认为是 SUS 的替代产品,用于评估用户对网站、软件、系统或产品的满意度、可用度,它是一份七点量表,有 16 道题目,一个整体,评估维度有 3 个:
- 整体
- 系统质量。
- 信息质量。
- 页面质量。

有4个分数
- 整体:题项1~16的反应平均值
- 系统质量:题项1~6的平均值
- 信息质量:题项7~12的平均值
- 界面质量:题项13~15的平均值
结果分数介于1~7分之间,分数低表示更高的满意度。如果从业人员需要,可以增加问题的题项目或在有限的程度中,可以对特定背景意义不大的题项进行删除。
在主持的可用性测试中,填写PSSUQ前给用户的说明如下:
您能通过本问卷告诉我们您使用系统的反馈。您的反馈可以帮助我们了解您对系统特别关心和满意的方面。为了尽可能好地完成这些题项,请您在回答的时候回想您在系统中执行的所有任务。请阅读每一个描述,表明您同意或不同意这些描述的程度。如果一个描述对您不适用,请圈“不适用”。请通过评论对您的答案进行精细描述。当您完成这个问卷后,我会跟你一起回购答案,以确定我了解您的所有反馈。谢谢!(Lewis,1995,p77)
版本3的信度为:
- 整体:94
- 系统质量:9
- 信息质量:91
- 界面质量:83
所有的信度都超过0.8,这表明问卷具有足够的信度作为标准化的可用性测量。
关于PSSUQ基准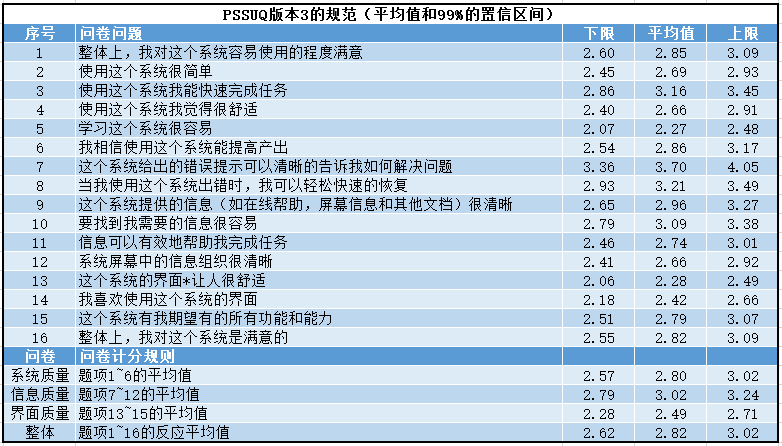
注:这些历史研究是基于PC系统得到的数据,用于手机端的度量需要再解释的时候特别注意,并在长期积累了手机端数据之后,对解释作适合于自己的修订。
题项评分最差的是第7项,对评分一直较差的第7项的建议:
- 如果这种情况发生在你的数据里,不要觉得奇怪。
- 一个产品很难提供有用的错误提示信息。
- 专注于提供有用的错误提示信息可能是值得我们付出努力的。
- 如果你发现,这个题项的平均值等于或低于信息质量的其他题项平均值,你有可能到了高于平均水平的错误消息。
1993 ASQ 场景后问卷
ASQ 的早期版本叫 PSQ,The Printer Scenario Questionnaire,场景后问卷,由 James Lewis 于 1993 年在 IBM 公司提出,用于评估打印机的易用性。
场景化问卷的开发与PSSUQ采用相同的形式,探测整体上完成任务的难易度、完成时间和支持信息的满意度。ASQ的项目采用从1(强烈同意)到7(强烈不同意)的7点计分。ASQ分数即是3个项目得分的平均分。
Lewis (1995)的研究指出ASQ分数与PSSUQ分数的之间存在r=0.8的强相关,与场景任务的成功率也存在r=-0.4的显著相关。
ASQ 是一份七点量表,共有 3 道题目,评估维度有 3 个:
- 任务难度。
- 完成效率。
- 帮助信息。


1994 10 Usability Heuristics 尼克森十大可用性原则
1994 ACSI 顾客满意度
1995 CSUQ
1995 WAMMI 网站分析和测量问卷
第一个意识到需要一个专门用来评估网站质量工具的是爱尔兰科克大学的人因研究小组(HFRG),他们与斯德哥尔摩的Nomos Management AB 合作,他们创建了网站分析和测量问卷(Website Analysis and Measurement Inventory,WAMMI)。
WAMMI包括20个项目,测量的因子与SUMI相同。WAMMI的总体信度在0.9-0.93之间,几个因子的测试信度为吸引力:0.64;可控性 0.69;效率:0.63;帮助性:0.7;易学性:0.74。相对于其它量表,这些分量表的信度有点儿偏低,因此WAMMI对于样本量有比较严格的规定:可用性测试不少于30人,学术应用不少于100人。
全部项目采用从1(强烈同意)到5(强烈不同意)的5点评分。在进行分数解释时,WAMMI推荐生成各个分量表的分数以及一个总分。其分数的标准化方式暂无公开发表,但标准化WAMMI分数的平均值为50,标准差为10
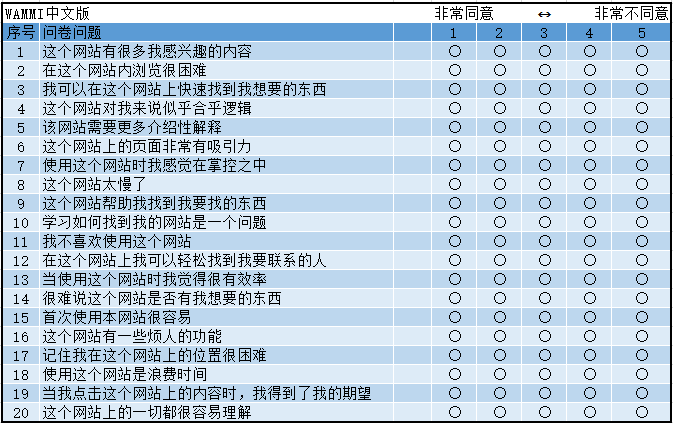
199? SEQ 单项难易度问卷 Single Ease Question,SEQ
只是要求评估完成任务的整体难易度,类似与ASQ第一项。SEQ的评分方式包括5点计分和7点计分,但根据目前的研究结果,7点评分拥有更高的信效度。
Sauro and Dumas (2009)发现SEQ分数与SUS得分呈现r=-0.56的的中等相关,与任务完成时间(r=-0.9)和任务出错率(r=-0.84)均存在显著相关性。同时,通过比较了SEQ、SMEQ和UME三个任务后评估问卷,他们也发现SEQ分数与SMEQ分数存在r=0.94的强相关,与UME分数存在r=0.95的强相关。
SEQ问卷内容:
1998 ISO-9241-11 国际标准可用性测试
2001 USE 量表
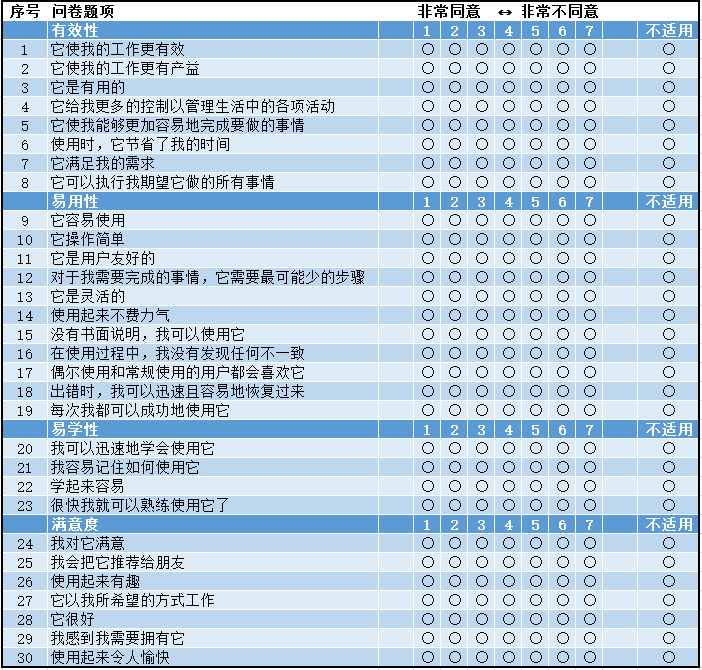
Arnie Lund(2001年)发表了USE量表。
测试4个部分,总共包括30个项目。
- 有效性(Usefulness)包括8个项目
- 易用性(Ease of Use)包括11个项目
- 易学性(Ease of Learning)包括4个项目
- 满意度(Satisfaction)包括7个项目。
量表的全部项目都是从1(不同意)到7(同意)的7点评分。其具体的统计方式和统计学参数尚未公开发表。但使用者可通过建立基线/竞品对比等方式来评测产品的可用性表现。
量表链接:http://garyperlman.com/quest/quest.cgi?form=USE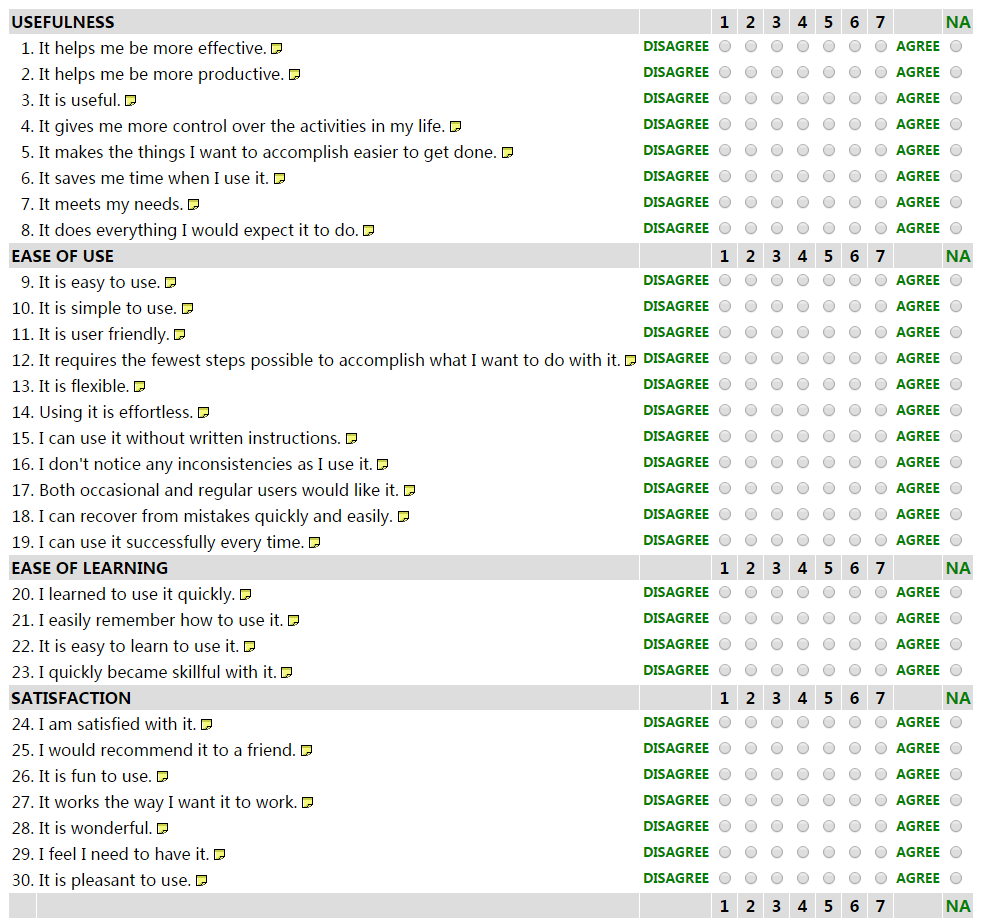
2002 WQ 网络质量问卷
2002 反应卡片 Desirability Testing
微软产品反应卡片Microsoft Reaction Card Method (Desirability Testing)是由微软公司的Joey Benedek和Trish Miner于2002年推出的一种测试“合意性”的方法。该方法主要用于检查设计或产品的情绪反应和合意性,通常应用在软件设计领域。
微软产品反应卡片Microsoft Reaction Card Method (Desirability Testing)是由微软公司的Joey Benedek和Trish Miner于2002年推出的一种测试“合意性”的方法。该方法主要用于检查设计或产品的情绪反应和合意性,通常应用在软件设计领域。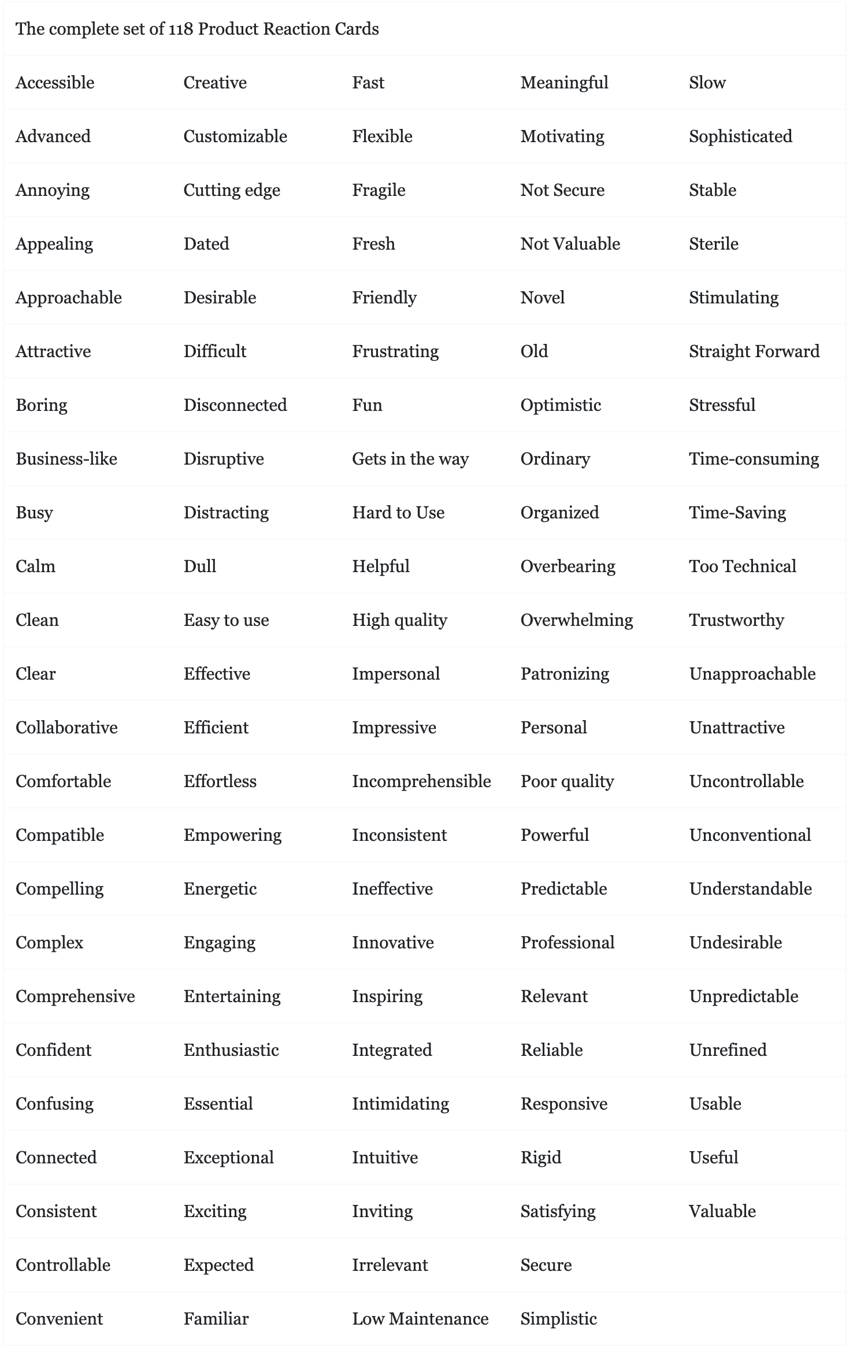
通过分析参与者的结果数据,研究者可以将特定的形容词和每个视觉设计方案结合起来,并且评估哪个方案与企业试图唤起的情感反应和品牌属性更加符合。研究者可以在一对一的情境中或者问卷调查中使用这个方法。一对一的方法的好处是研究者可以询问用户为什么选择特定的形容词,这个过程可能会发现一些额外的洞见。
在这里,合意性研究能够帮助解决两个问题:
- 告知设计团队,为什么不同的设计方向能够引发目标用户特定的反应(为了完善设计方向)
- 精确测量针对特定形容词(如,品牌特性)的视觉设计方向,从而帮助做出最后决策

通过分析参与者的结果数据,研究者可以将特定的形容词和每个视觉设计方案结合起来,并且评估哪个方案与企业试图唤起的情感反应和品牌属性更加符合。研究者可以在一对一的情境中或者问卷调查中使用这个方法。一对一的方法的好处是研究者可以询问用户为什么选择特定的形容词,这个过程可能会发现一些额外的洞见。
在这里,合意性研究能够帮助解决两个问题:
- 告知设计团队,为什么不同的设计方向能够引发目标用户特定的反应(为了完善设计方向)
- 精确测量针对特定形容词(如,品牌特性)的视觉设计方向,从而帮助做出最后决策
参考链接:
- Using the Microsoft Desirability Toolkit to Test Visual Appeal
- Desirability Studies: Measuring Aesthetic Response to Visual Designs
2003 NPS 净推荐值
2007 WU 网络可用性问卷
2010 CES 用户费力度
客户费力度这个概念在2010年在《哈佛商业评论》中被提出,按字面意思理解,“客户费力度”是让用户评价使用某产品/服务来解决问题的困难程度。第一版的“客户费力度”的问题是:为了得到你想要的服务,你费了多大劲儿?(How much effort did you personally have to put forth to handle your request?),用户需要在1分(very low effort)到5分(very high effort)之间做出选择。
CES的理念是只有真正帮助用户轻松地解决问题的产品或服务,才会获得高满意度和忠诚度。最好在用户刚刚做完操作时询问,否则用户可能忘记自己完成操作的实际体验。下图是现在比较通用的2.0版本:
- 提出的问题是:企业让我的问题处理过程变得简单。
- 客户的选项包括:强烈不同意,不同意,有点不同意,中立,有点同意,同意,强烈同意

度量:计算所有用户的答案的总和,得到的总分低说明企业降低了用户满足需求的难度,而总分很高则说明用户在与企业互动的时候花费了太多力气。
- 优势: CES的优势之一是只关注“用户费力程度”这个要素的解决办法。计算CES分数的唯一目的是消除或减少用户服务中的障碍。 CES已被证实是评估用户忠诚度的最佳指标。
- 劣势: CES可以指出用户服务中的障碍,但它并不会深究为什么用户会遇到问题,或这些障碍会是什么。
2010 UMUX 用户体验可用性指标 The Usability Metric for User Experience
由 Kraig Finstad 于 2010 年论文 The Usability Metric for User Experience 中首次提出,其前身是 SUS 问卷,目的是为了在不影响问卷可信度的情况下,尽可能的减少问卷的题目,也是为了更符合 ISO 的评估维度。 净推荐值最早是由贝恩咨询企业客户忠诚度业务的创始人佛瑞德·赖克霍徳(Fred Reichheld)在2003提出,它通过测量用户的推荐意愿,从而了解用户的忠诚度。NPS并非一个单独的量表,它的问题项目来源于SUPR-Q。
UMUX 是一份七点量表,共有 4 道题,对应 3 个评估维度。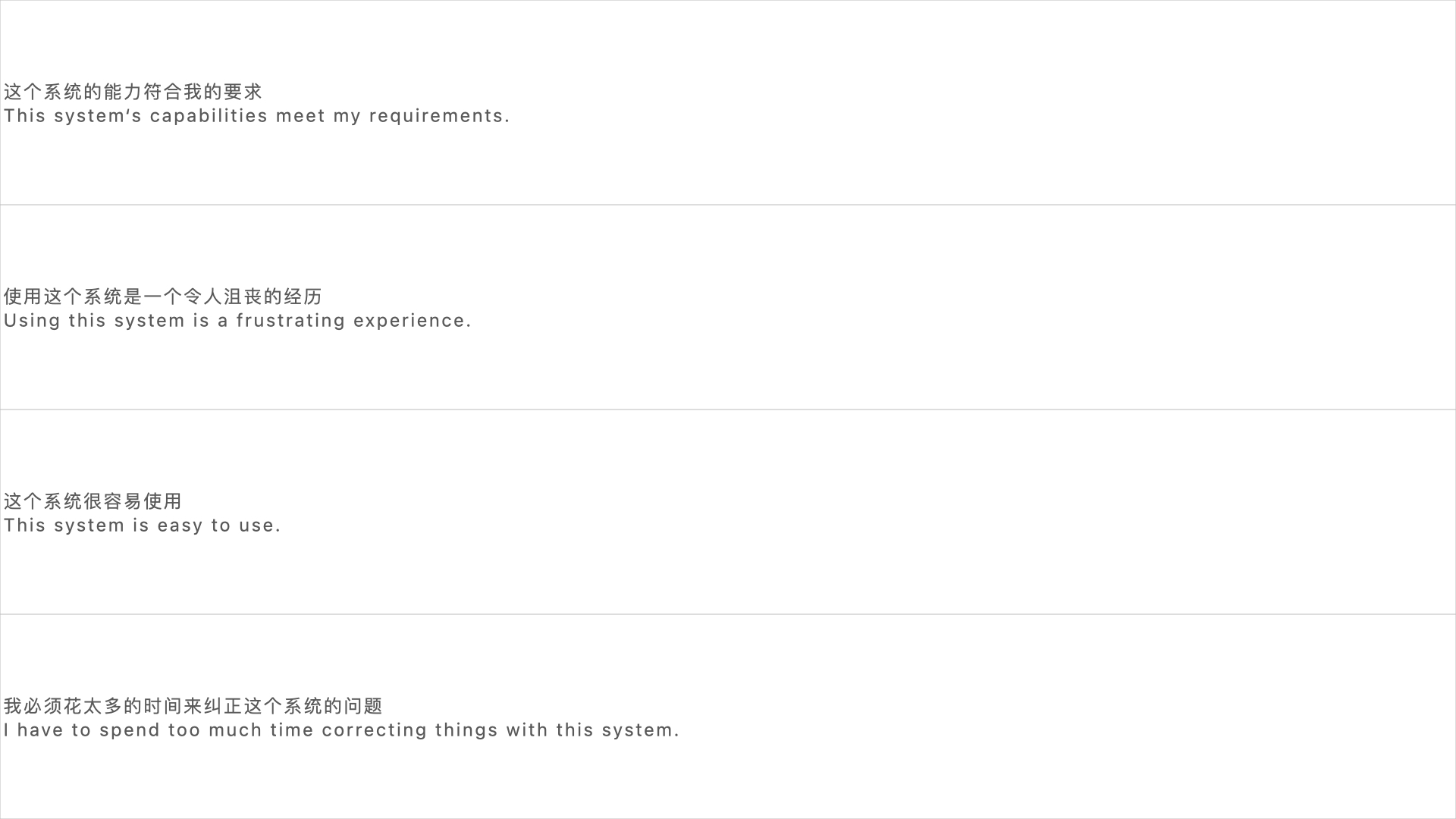
- 推荐者Promoters(得分在9~10之间):是具有狂热忠诚度的人,他们会继续购买并引荐给其他人
- 被动者Passives(得分在7~8之间):总体满意但并不狂热,将会考虑其他竞争对手的产品
贬损者Detractors(得分在 0~6之间):使用并不满意或者对你的企业没有忠诚度
推荐者所占比例减去贬损者所占比例就是最终的NPS值。NPS询问的是意愿而不是情感,对用户来说更容易回答,且相比于CSAT,它对用户行为的预测力更高。
- 优势: NPS仅需要用户回答一个简单的问题,比较容易完成,因此用户会更愿意参与评分。
- 劣势: NPS面临最主要的批判是只有一个问题,那就意味着只能测量一个维度,因此它仅提供了一个狭窄的用户满意度视角。 而且,这个问题也不能证明推荐者会真的向他们生活中的朋友推荐企业的产品或服务,因此这个分数并不一定与客户在现实生活中的推荐行为相关。
问卷的通用问题
- 是用户自行填写的数据,数据可能不可靠。
- 衡量的是用户的主观感受,而不是客观表现。虽然满意度和客观性能指标,例如任务完成率、任务时间或错误,之间有一定的相关性,但满意度指标通常在与性能指标相结合时能说明更清晰的问题。
- 每个用户可能对分数的定义各不相同,例如 7 分中的 5 分的含义是什么。
- 低样本量的情况下,例如 5 个用户,不太可能提供有统计学意义的结果,最终得出的结论也具有高度误导性。
第三阶段
由于问卷的缺陷,在第三阶段的度量标准中,不约而同地都加入了客观指标,来衡量用户体验。
- 200? PULSE 产品体验评估指标
- 2010 HEART + GSM
- 2010 UMUX 用户体验的可用性指标
- 2015 SUPR-Q 标准化的用户体验百分等级问卷 Standardized Universal Percentile Rank Questionnaire
- 2015 SUPR-Qm APP用户体验量表
- 2015 五度模型
- 2017 TECH
- 2019 PTECH
- 2019UES 度量系统
- 2020 两章一分
- 2021 EDS 度量模型
- 2021 QMD 度量模型
200? PULSE 产品体验评估指标
传统 Web 产品体验评估指标,由 Google 提出,提出的时间未知,搜索了很久都没有找到,PULSE 的每一个字母代表一种指标
- Page Views 页面浏览量:产品指标,衡量页面被用户访问的次数,以及逐级页面的点击转化情况。
- Uptime 运行时间:技术指标,衡量网站持续稳定的运行时间。
- Latency 延迟:技术指标,衡量用户打开页面的速度。
- Seven-day active users 七日用户活跃:产品指标,反映网站的实际运营情况,用于估计产品的用户规模。
- Earnings 收益:商业指标,例如电商业务关注 GMV,音视频业务关注 VIP 用户数。
PULSE 是基于商业和技术来评估产品的,是跟踪产品的整体表现,无法直接通过指标观测用户体验是怎么样的。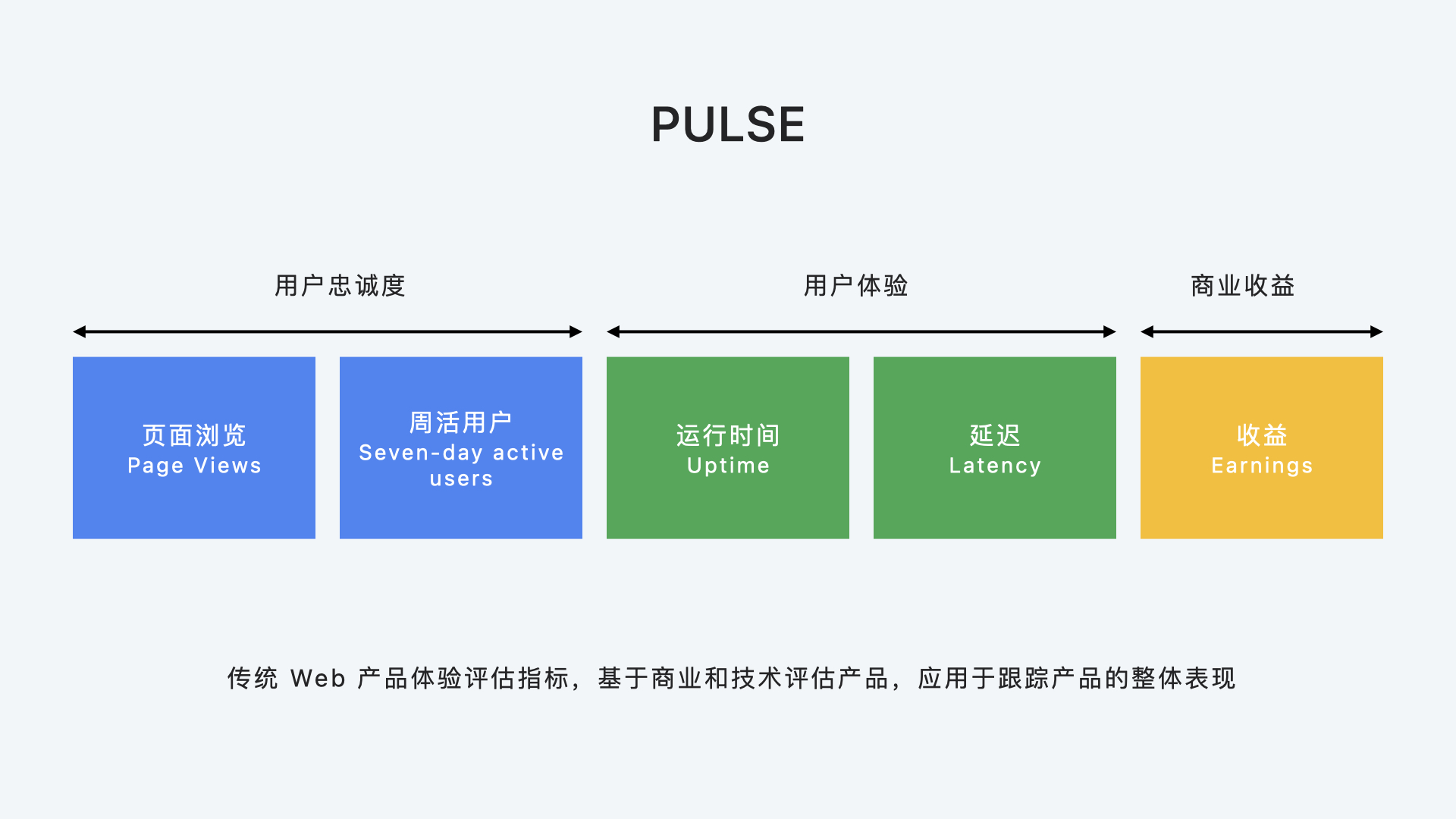
2010 HEART
HEART,是在 PULSE 的缺陷上,加以改进形成的以用户为中心的体验度量模型,由 Kerry Rodden、Hilary Hutchinson 和 Xin Fu 在 Google 于 2010 年在 CHI 论文中首次提出。
HEART 的每一个字母代表一种用户体验测量标准:
- Happiness 愉悦感。
- Engagement 参与度。
- Adoption 接受度。
- Retention 留存率。
- Task Success 任务完成率。
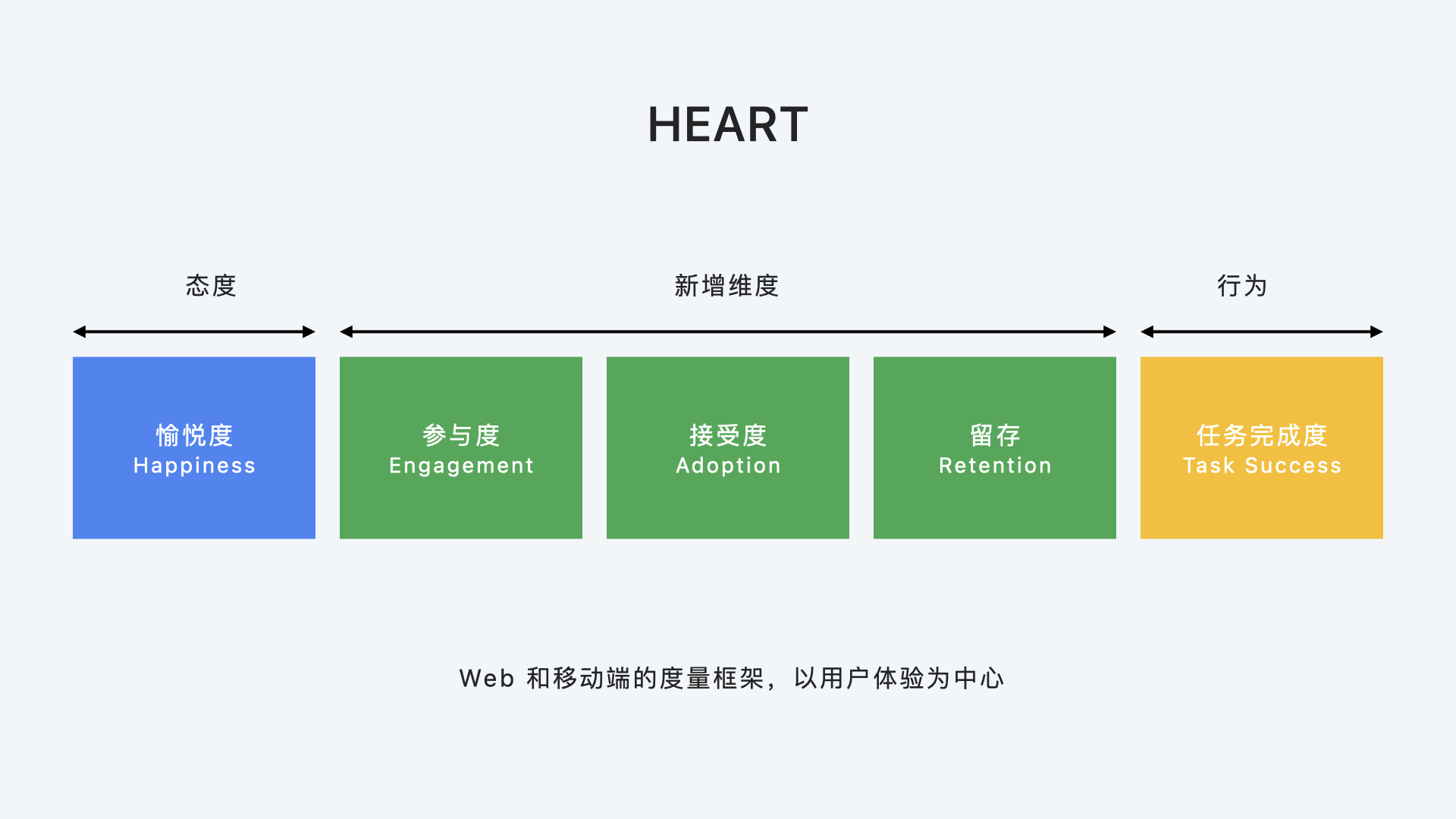
HEART 并没有具体的度量指标,不同的产品可定义不同的指标,例如:
- 愉悦感能结合用户的满意度来度量。
- 参与度、接受度、留存率能结合用户的行为数据来度量。
- 任务完成度能结合任务完成的效果和效率来度量。
HEART 并不适合在一个指标设定中用到所有维度,但可以参考该模型来决定是否包括或排除某个维度。比如用户是要将使用你的产品作为工作的一部分,在这种环境下参与度就没有什么意义了,可以考虑选择愉悦感或者任务完成度。
愉悦感
愉悦感是设计用户体验中的主观感受问题,像满意度、视觉感受、向别人推荐的意愿、易用性感知。可以通过设计问卷,长时间监控相同的指标来比较修改后带来的变化。
例如,Google 曾经有个性化首页的服务,团队利用产品内置的检测手段,跟踪了一周内一系列的指标来研究改版和新功能的影响。在一次大改版之后,起初用户满意度指标是大幅下降的,但是随着时间推移,这个指标逐渐恢复,这表明大幅下降只是因为刚改版时的不适应。渐渐习惯这次改变之后,用户实际上是很喜欢的,有了这一信息,团队就可以更有信心地坚持这次改版的设计。
参与度 Engagement
参与度是用户在一个产品中的参与深度,在这个维度上,通常用来作为一段时期内访问的频度、强度或互动深度的总和。比如单用户每周的访问次数,或者用户每天上传的照片数,这比总量要好,因为总量的增长可能是由更多的用户的产生,而不是更多的使用产生的。
例如,Gmail 团队更想研究用户的参与度,而非 PULSE 指标体系中的七天活跃用户数,只是上周使用该产品用户的简单计数之和。我们有理由去相信,深度用户会经常检查他们的邮箱,因为他们已经形成习惯。我们选择的指标是一周内访问五天或者更多的百分比,这一指标同样也可以用来预测用户长期的留存度。
接受度和留存率 Adoption & Retention
接受度和留存率指标通过特定时期内大量用户的统计,例如最近 7 天日活数,提供强大的洞察,来定位新用户和老用户的差异问题。接受度监控特定时期内有多少新用户开始使用产品,例如最近 7 天内新创建的账号。
留存率则监控特定时期内有多少用户在下载后一个时期内仍然存在,例如某周的 7 天日活数在 3 个月后仍然在 7 天日活用户中。
「使用」和「周期」需要因地制宜,有时候「使用」就意味着访问网站,有时候则是到达了某个特定的页面或者完成某种互动,例如创建账户。留存率和参与度相似,它可以被定义不同周期长度,有的产品也许只需要观察周数据,有的则需要月数据或者季度数据。
例如,在 2008 年证券市场暴跌的那段时间,谷歌金融在浏览量和七日活动用户指标上都有一次井喷,但无法确定数据的剧增是来自关心金融危机的新用户或是恐慌性不停查看他们的投资信息的老用户。
在不知道是谁增加了这些访问量之前,决定是否要改版网站以及如何进行修改十分困难,谷歌金融利用接受度和留存率这两个指标来区分用户群体,同时还关注了新用户继续使用该服务的百分比,这类信息被利用于解读事件驱动的数据波动,以及发现潜在的机会。
任务完成率 Task Success
任务完成率维度包括一些传统的用户体验行为指标,比如效率,完成任务的时间、效果,任务完成的百分比以及错误率。
例如,谷歌地图曾经有过两种不同的搜索框,一种是用户可以分开输入「目的」和「地点」的双重搜索框,另一种是单个搜索框处理所有的类别。有人觉得单个搜索框就可以胜任一切,同时又保持了效率,在之后的 A/B 测试中,团队测试了仅提供单个搜索框的版本。他们比较了两个不同版本的错误率,发觉用户在单个搜索框版本中能够更加有效地达成他们的搜索目的。最终,这个结果让团队非常有把握地在所有地图上移除了双搜索框功能。
2010 GSM
GSM 模型是和 HEART 一并提出的概念,是为了将 HEART 度量标准应用于实践。
No matter how user-centered a metric is, it is unlikely to be useful in practice unless it explicitly relates to a goal, and can be used to track progress towards that goal. We developed a simple process that steps teams through articulating the goals of a product or feature, then identifying signals that indicate success, and finally building specific metrics to track on a dashboard.
无论一个指标如何以用户为中心,除非它与目标明确相关,并可用于跟踪该目标的进展,否则它在实践中不太可能有用。我们开发了一个简单的过程,通过阐明产品或功能的目标,然后确定表明成功的信号,最后在仪表盘上建立具体的指标来跟踪。
———Kerry Rodden, Hilary Hutchinson, and Xin Fu
- Goal 目标:用户需要完成什么任务?设计的目的是什么?是吸引新用户更重要,还是鼓励现有用户更多的参与?
- Signal 信号:想想目标的成功或失败如何体现在用户的行为或态度上,什么样的行为会表明目标已经实现?哪些数据会与成功失败相关?如何收集这些行为和数据?
- Metric 指标:如何将这些信号转化成具体的衡量标准?能否和其他的项目或产品进行比较?

HEART + GSM 就是一套完整的产品体验评估模型,能推导出每一个度量维度相关的目标、信号和指标,以及拿到这些衡量指标的评估方法。因此,模型的落地应用和目标的拆解密不可分。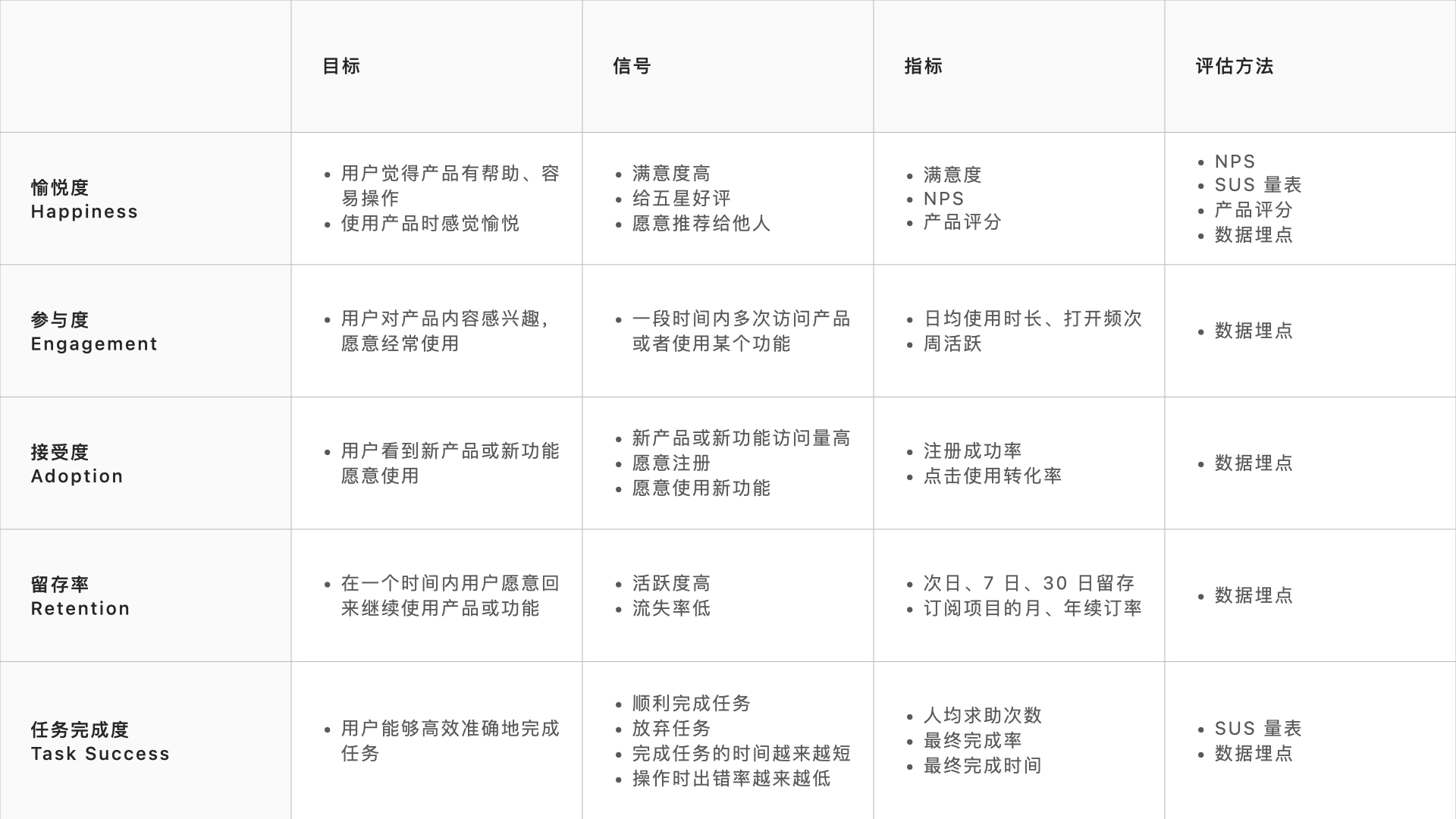
2010 UMUX 用户体验的可用性指标
UMUX 是一种简短的定性评估,旨在衡量系统的一般可用性。 UMUX 问卷由 Kraig Finstad 和他的同事于 2010 年在英特尔开发,旨在为 10 项 SUS 问卷提供更短的替代方案。此外,它旨在解决国际标准化组织或 ISO 提出的可用性的新定义。SUS 评估感知的可用性和可学习性,而UMUX 通过评估有效性、效率和满意度来瞄准可用性。
UMUX是一套相对较新的标准化可用性问卷调查表。UMUX的主要目标是使用较少的题项来满足ISO定义的可用性(有用、高效、令人满意)调研。题项少并不代表不好,在某些情况下,较短的问卷可能更有用。
UMUX的强大之处在于其感知可用性度量与SUS的测量结果基本一致(与SUS标准版相关系数0.9)。
UMUX的可靠性α系数为0.94。
UMUX-LITE
如果觉得上面的题项还是太多,可以使用更为精简版的UMUX-LITE,UMUX-LITE主要测量的内容为“有用性”(项目1)和“易用性”(项目1)。具体问卷内容为:
UMUX-LITE的可靠性α系数为0.82,与SUS标准版的相关系数为0.73
总结,虽然UMUX比较相比较简短,但是SUS更多的已经被验证。所以如果期望数据更准确,推荐使用SUS。
2015 SUPR-Q 标准化的用户体验百分等级问卷 Standardized Universal Percentile Rank Questionnaire
是一个等级量表,根据官方的信息,SUPR-Q总共包括10个项目,分别测量网站的可用性(Usability),可信度/信任(Trust & Credibility),外观(Appearance)和忠诚度(Loyalty)。
- The website is easy to use. (usability)
- It is easy to navigate within the website. (usability)
- The information on the website is credible (trust for non-commerce)
- The information on the website is trustworthy (trust for non-commerce)
- I feel comfortable purchasing from the website. (trust for commerce sites)
- I feel confident conducting business on the website. (trust for commerce sites)
- I will likely visit this website in the future (loyalty)
- I find the website to be attractive. (appearance)
- The website has a clean and simple presentation. (appearance)
- How likely are you to recommend this website to a friend or colleague? (loyalty)
《用户体验度量》这本书上给出的题项是8个其中7个项目是5分制,第8个项目(NPS)是11分值。具体如下: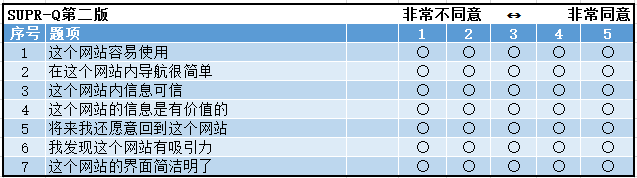

计算分值时,将前七个问题的答案加上第八个项目于的一半分数加起来即可。
SUPR-Q的总体信度为0.86。SUPR-Q分量表的可信度为:
可用性(项目1,2):88
信任度(项目3,4):85
忠诚度(项目5,8):64
外观(项目6,7):78[
](https://fuzzymath.com/blog/suprq-design-metric/)
2015 SUPR-Qm APP用户体验量表
SUPR-Qm由SUPR-Q的作者Jeff Sauro创建,主要目的是面向一定APP做用户调研。SUPR-Qm来源于最23个其他相关文献中的题目和4个开放性的问题
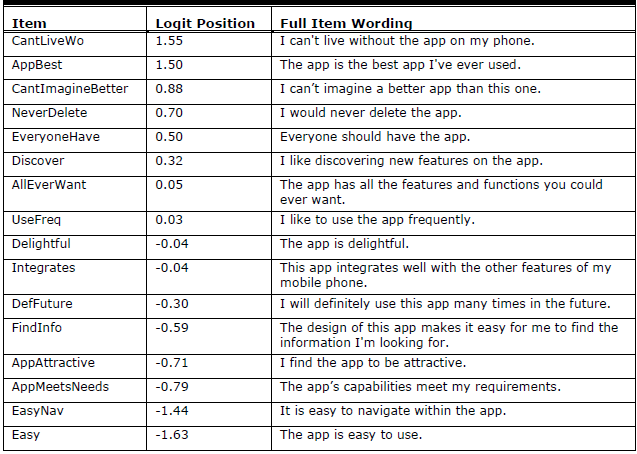
23个相关题目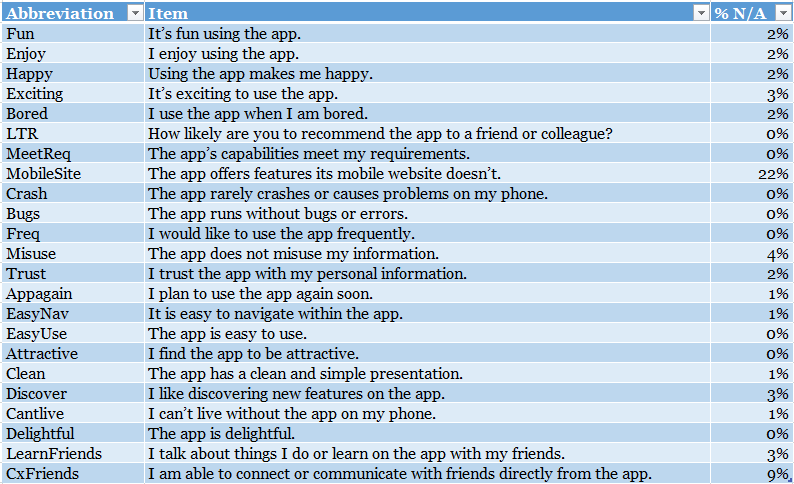
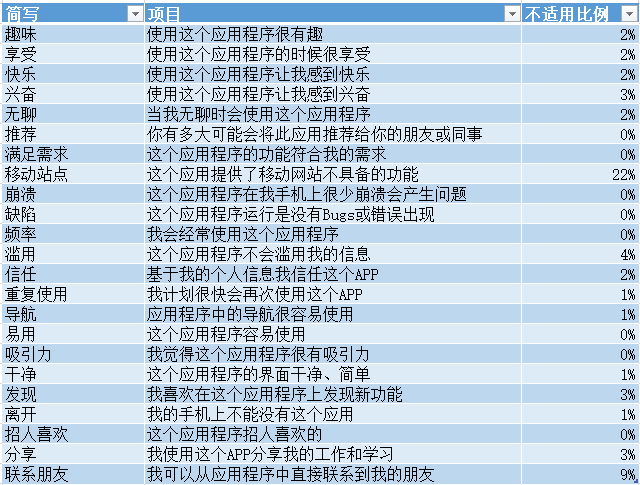
4个开放性问题

具体设计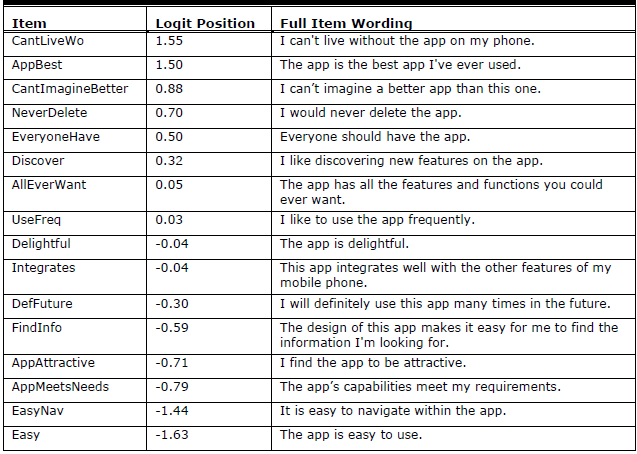
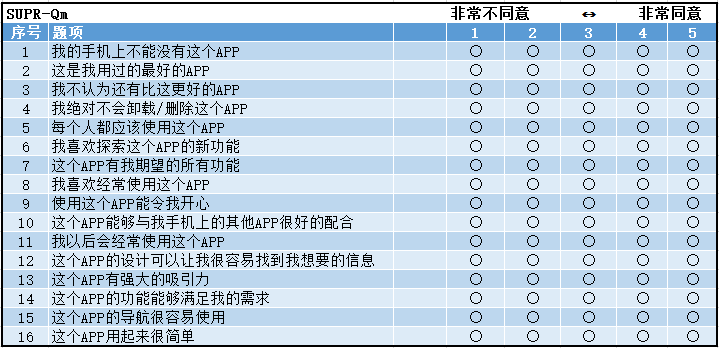
上图中的Logit Position为获得此项高分的难易程度,数值越高代表越难。
SUPR-Qm的内部一致性信度达到0.94,与其它体验量表的得分有着显著的相关性:与LTR(推荐度)的相关性为0.74、与SUPR-Q相关性为0.71、与UMUX-Lite的相关性为0.74。同样的,SUPR-Qm的分数与Apple Store和Google Store的用户评分之间有0.38的相关性。
SUPR-Qm的适用场景
- 在可用性测试中或者网络投放的回忆性测试中评估APP的整体性用户体验,作为之后产品提升或改变的基线对比
- 在可用性的前后分别进行施测,以便于进行对比分析产品的优化成果
- SUPR-Qm可以和其它具有领域特殊性的问题混合在一起使用,以便于测量某些特殊产品(如游戏)的用户体验
另外,在验证SUPR-Qm信效度时,Sauro评估了国外比较常用的一部分APP,有需要的也可以用这些去做对比,如下: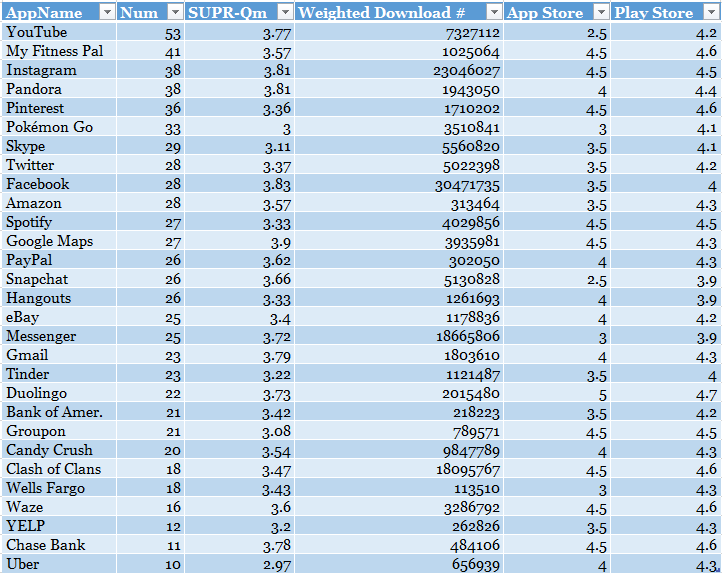
2015 五度模型
五度模型,由 1688 UED 的戴均于 2015 年发布
2017 TECH
由蚂蚁金服于 2017 年发布,基于 HEART 模型并根据业务特性做出了优化
- NPS 对 C 端产品是一个很有效的指标,对于企业级中后台来说,往往由于企业产品的封闭内环、用户基数等众多原因,可能还是满意度来的更加有效。
- 不强调留存率:企业级产品用户往往没有太多的可选余地,因此留存率未必适合用来衡量用户对于产品的喜好。
- 参与度和接受度指标合并:对于企业级中后台系统,用户使用的目标性更强,TA 就是来完成某个任务或完成工作的,因此活跃度基本和产品能否满足用户的需求强相关。
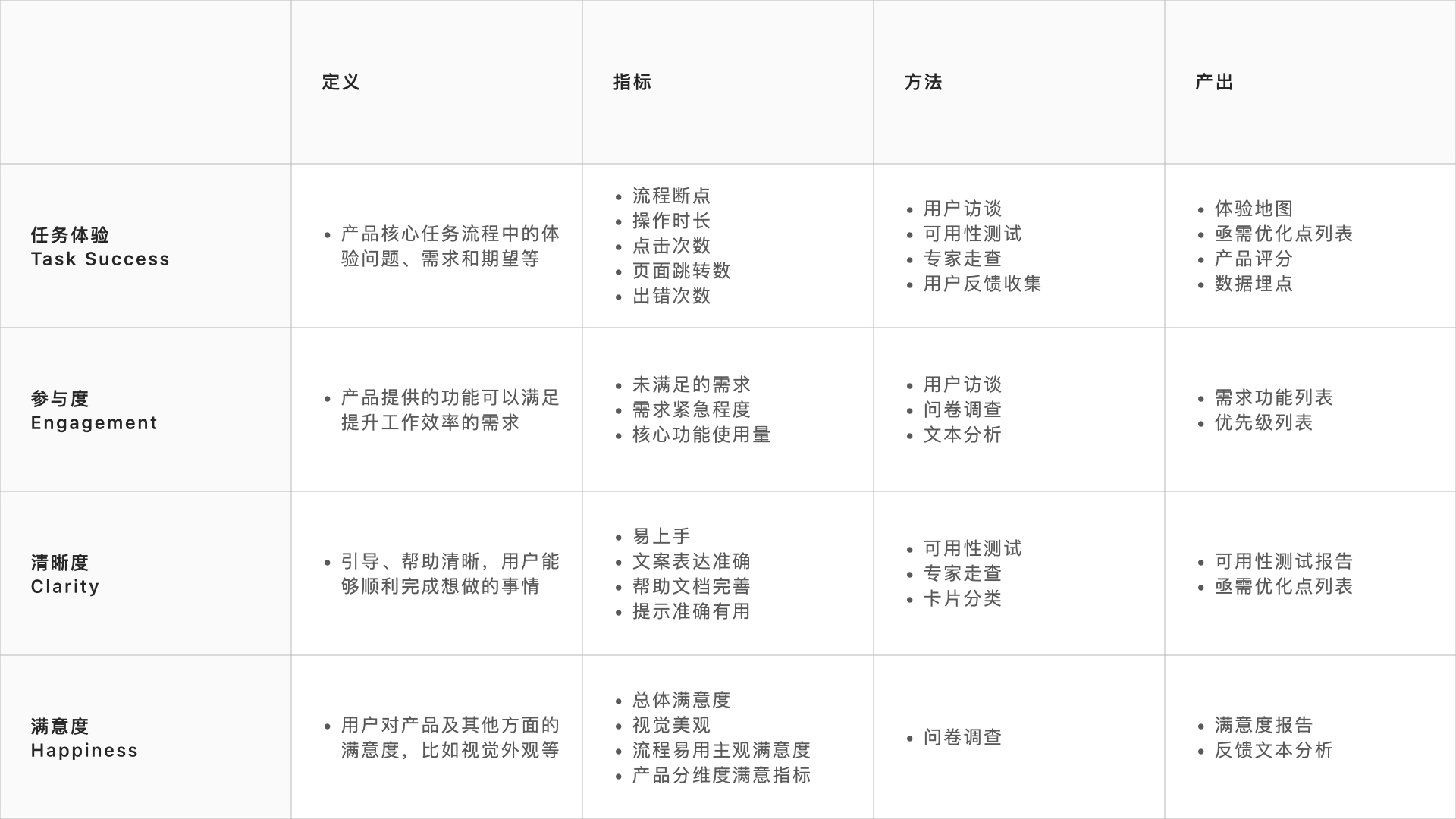
2019 PTECH
基于 TECH 并加入了性能体验 Performance 维度,能直接计算产品的体验分,由蚂蚁金服于 2019 年 SEE CONF 科技大会发布。
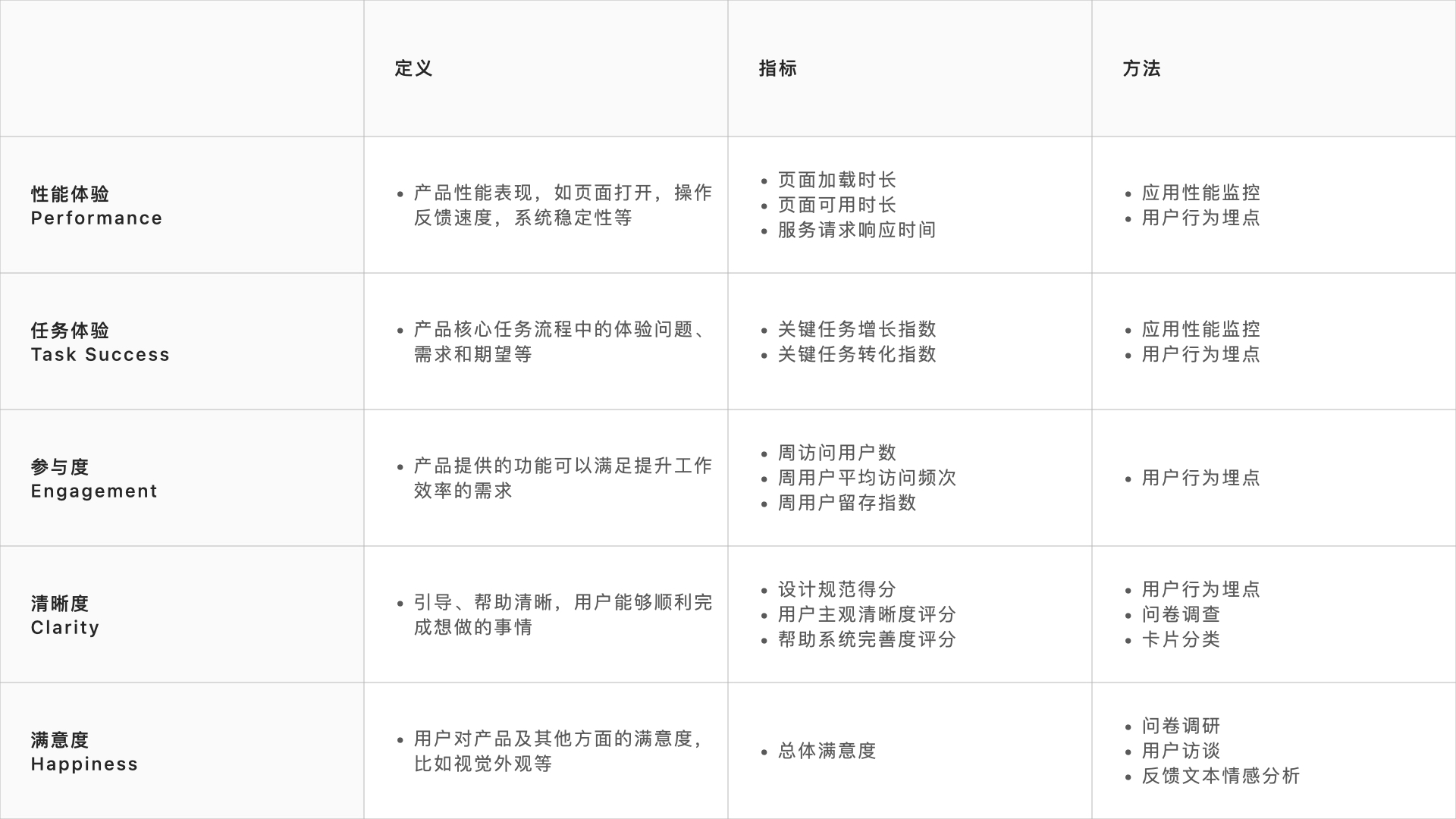
2019 UES 度量系统 User Experience System
由阿里巴巴旗下的阿里云设计中心于 2019 年提出。
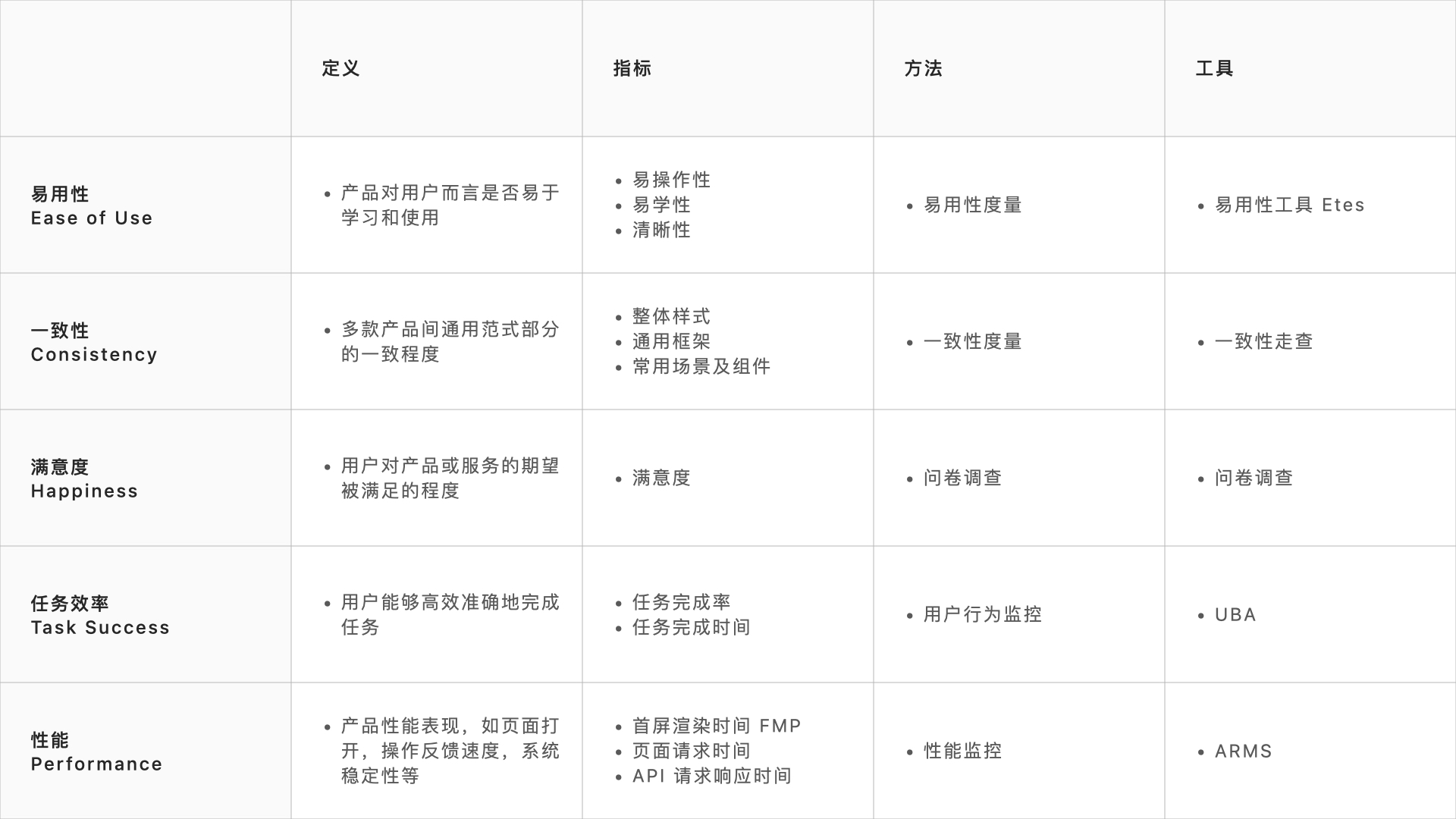
2020 两章一分
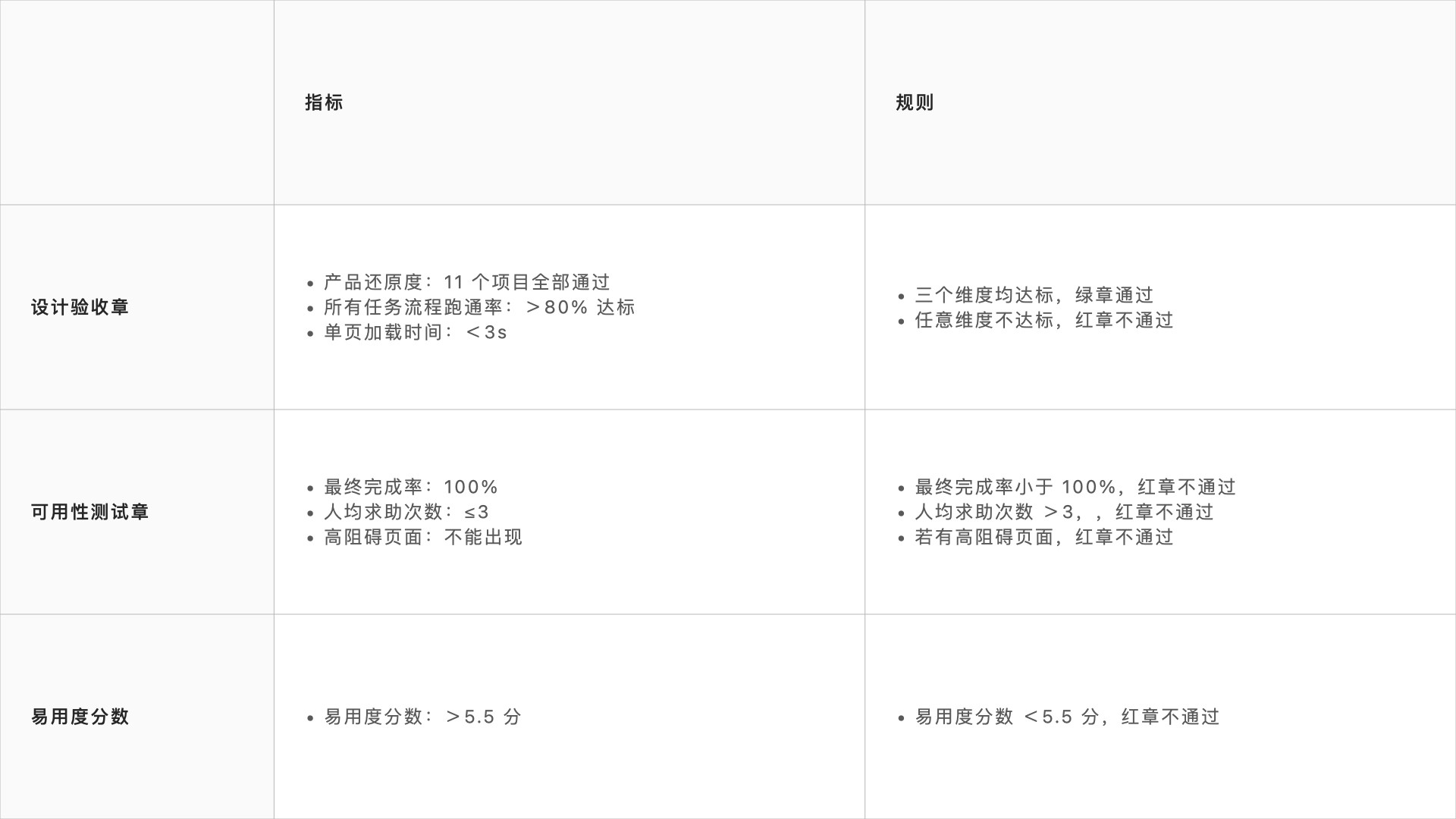
由于 PTECH 模型操作门槛较高、对埋点数据有不少要求,难以推广到各条业务线,于是去繁从简,提高通用性,蚂蚁金服于 2020 年发布了两章一分。
2021 EDS 度量模型
DES 由优酷设计团队于 2021 年提出的,模型分两种,一种是通用模型,为各业务、产品都会涉及到的设计通用维度,更专注于设计本身的维度度量。任何功能类型都可以从基础体验和完成度角度考察设计是否吸引、清晰、易读、高效。将满意度和费力度合并在一个类别中,作为用户主观态度维度。
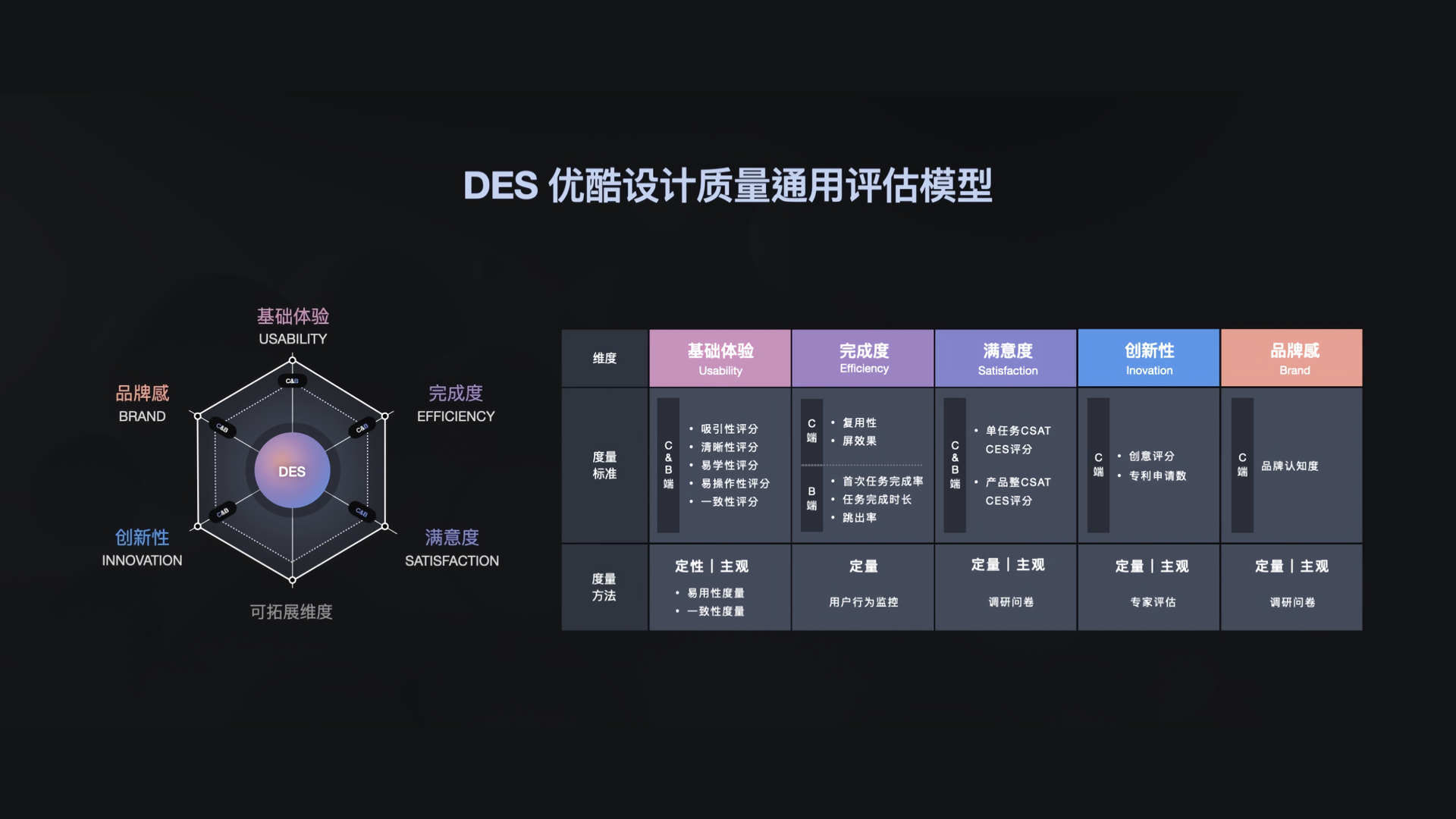
另一种是针对各业务的设计团队制定具备指向性的模型,例如 B 端平台、长视频消费端、短视频消费端来构建模型。
2021 QMD 度量模型
度量特点
相同点
根据用户心智模型(OADI模型),不管是C还是B端,体验流程基本一致
不同点
不同的产品形态,导致C端和B端侧重点不一样,度量方式存在差异
C端产品业务及用户数据丰富,用户体验易于量化,而B端缺少相关业务和用户数据,用户体验难以量化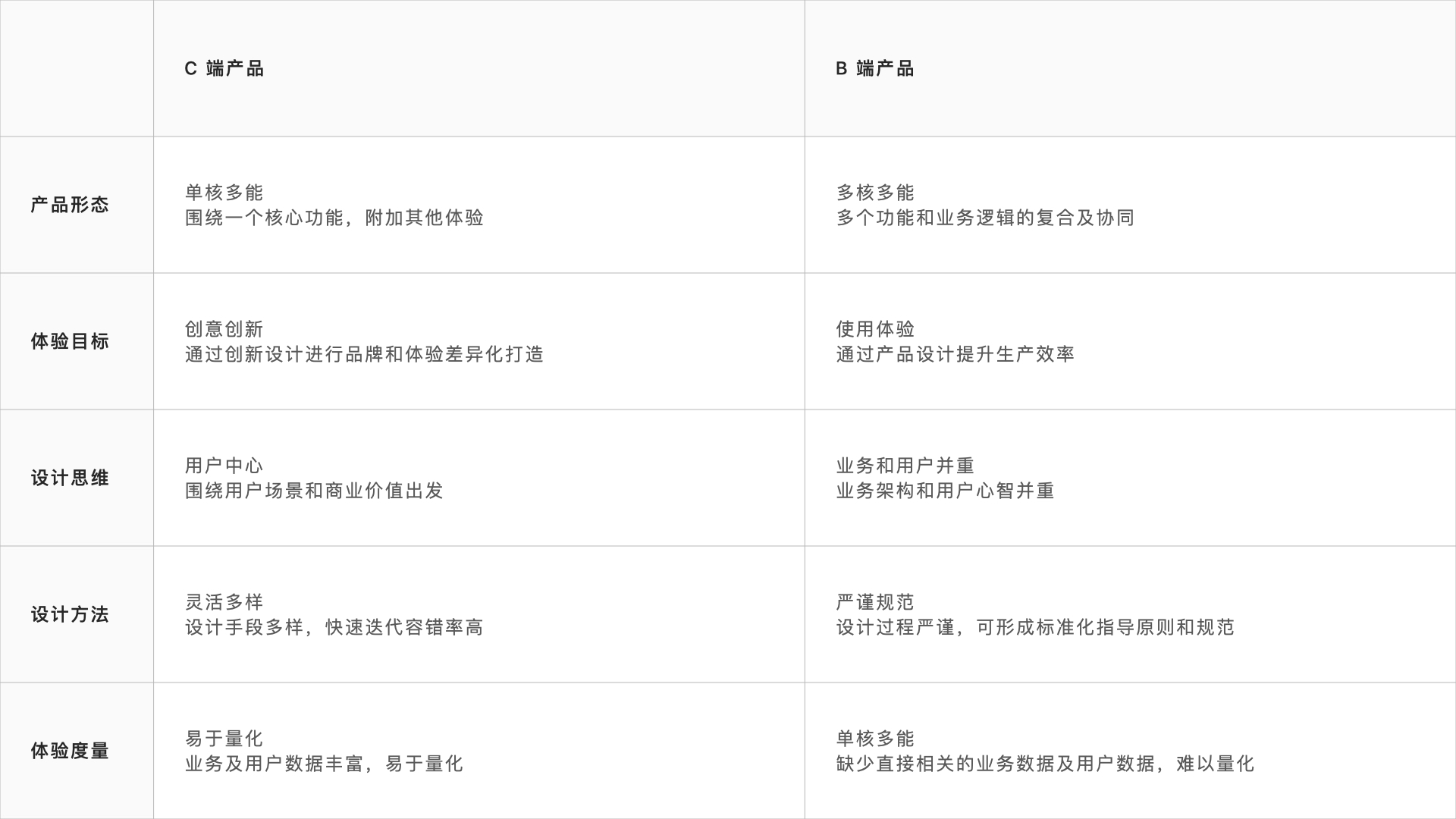
即使是同类B端,也细分领域:通用型产品,商家产品,中后台产品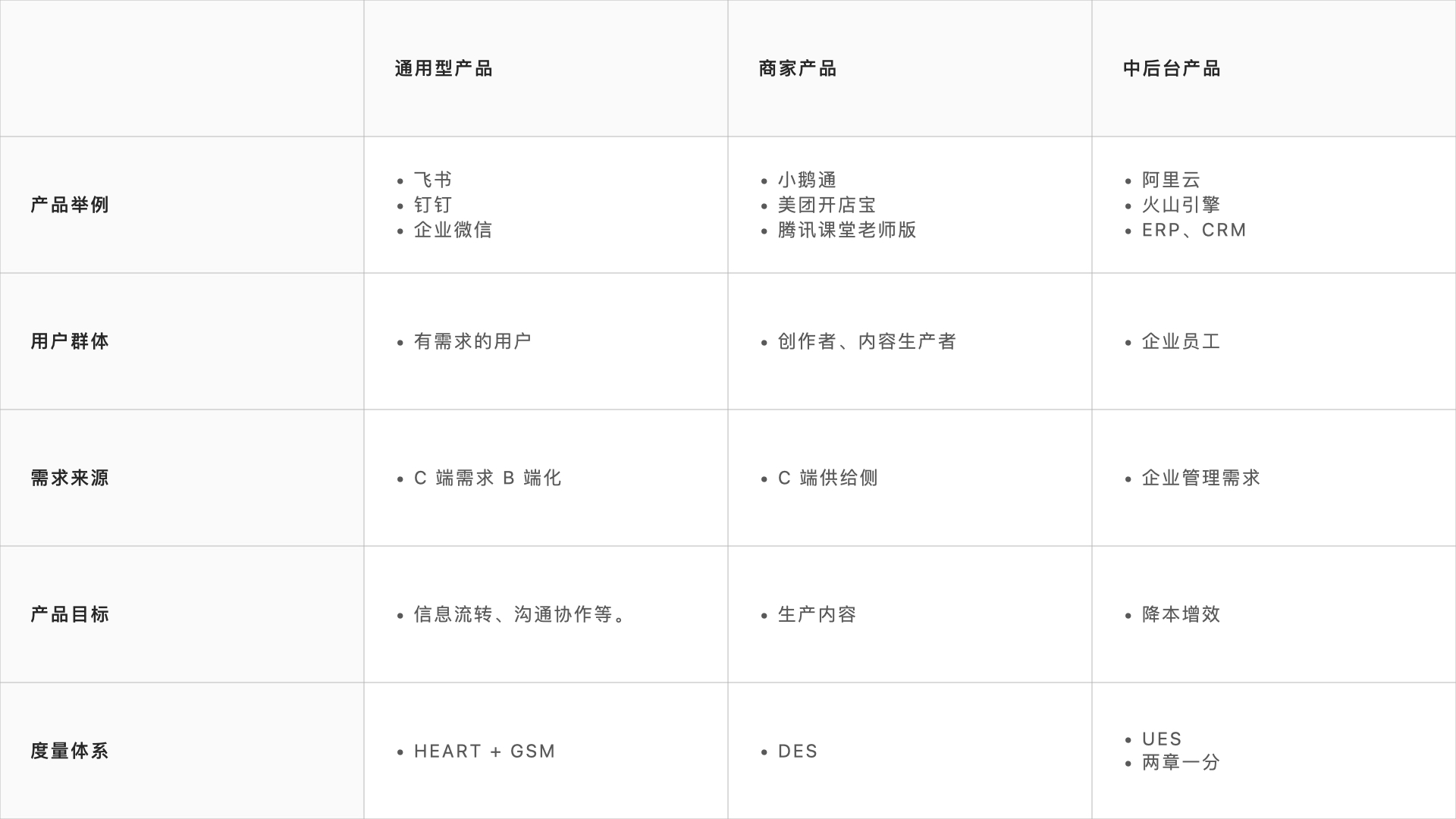
B端度量特点
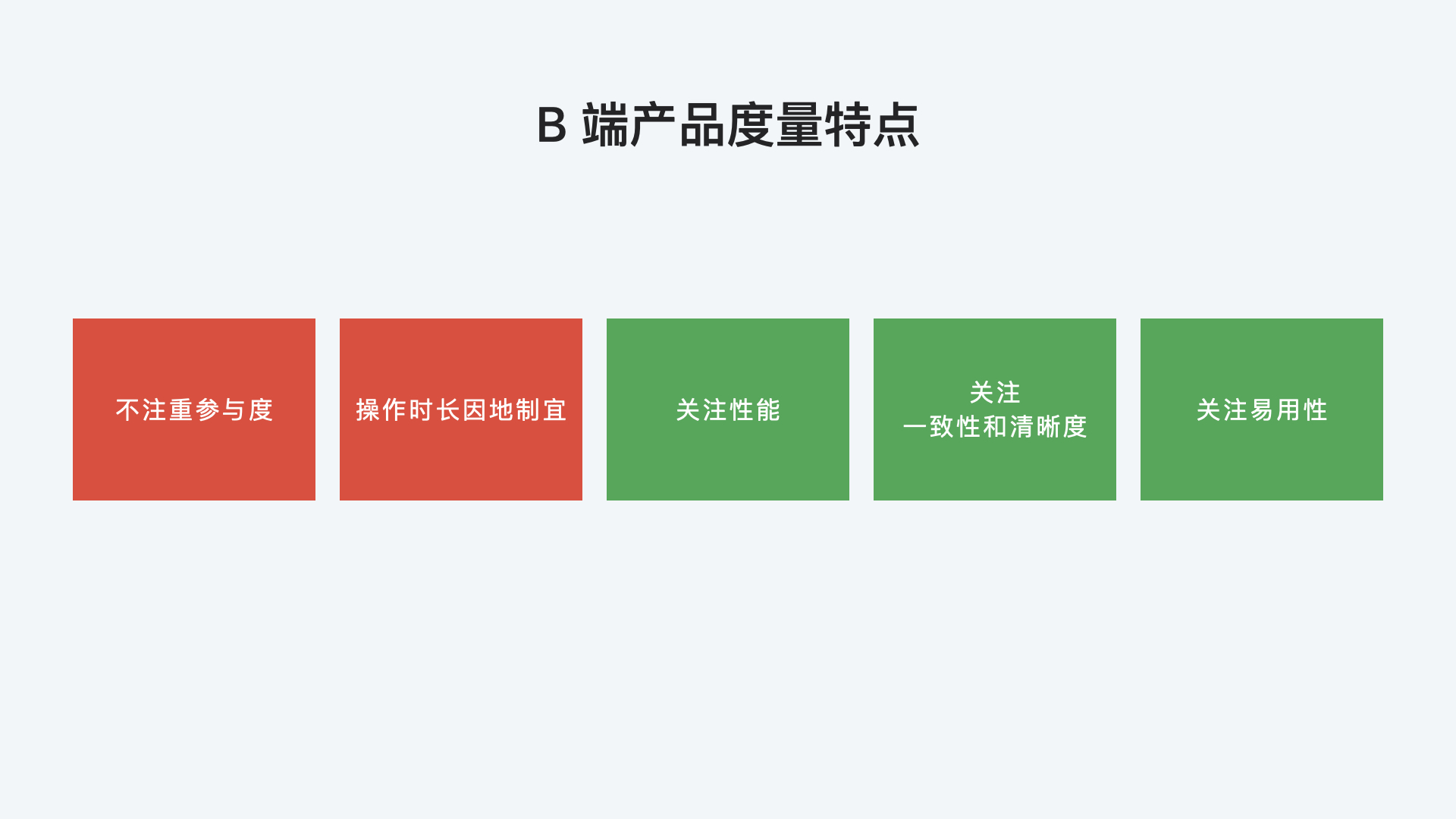
- 不注重参与度
第一是因为强制性使用,衡量它没有意义,例如 IM 的参与度肯定是 100%;第二是因为没有需求,例如采购可能会经常用到「合同管理」功能,研发可能很少用到。 - 操作时长因地制宜,无法通用化
企业中后台产品类型多、使用场景复杂程度各自不同,操作时长难以作为通用的衡量标准,例如用语雀创建企业空间只需要 5 分钟,用云凤蝶搭建一个后台页面可能需要 60 分钟,用 sofa stack 创建并发布一个应用可能需要 2-3 个小时。 - 关注性能
因为其本身的特殊性,B 端注重生产力和工作效率,生产力的前提是系统性能的可靠性、健壮性,需要降低响应时间和提高系统吞吐量。 - 关注一致性、清晰度
B 端产品的后台多种多样,降低学习成本的最好方式就是使用一致的文案、布局、设计系统。 - 关注易用性
易用性的目的同样服务于生产力,符合用户的习惯与需求。度量形式
标准化问卷
什么是标准化问卷?
问卷是一种用于获取被测者信息的表格,问卷的题目可以是开放式的问题,但更典型的是选择题或打分题。标准化问卷是被设计为可重复使用的问卷,通常有一组特定的问题使用特定的格式按照特定的顺序呈现,基于用户答案产生的度量值具有一定的规则(对于用户的回答,也有特定的计算方法和规则。)。作为标准化问卷设计的一部分,设计者通常需要报告问卷测量的信度、效度和灵敏度,换言之,问卷需要经过心理测量的条件审查(并不是每一份被重复使用的问卷就能称为标准化问卷)。
对标准化问卷的质量测试:信度,效度和灵敏度
信度:测量一致性。它衡量的指标是:对同一对象测量得到的结果是否一致。一般信度的评估包括重复测量信度和分半信度,最常见的方法α系数法。信度范围在 0 到 1 之间,对于问卷的信度,并没有固定的要求,不同内容的问卷对信度的要求不一样,但是,那些有着重要影响的问卷,例如 IQ 测试等,我们对其信度要求高,一般达到9 以上,而一些其他的问卷,信度要求7 以上就能够接受。
- α信度系数是目前最常用的信度系数,其公式为:
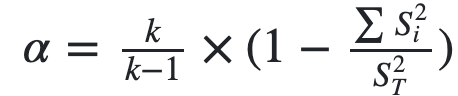 ,其中,K为量表中题项的总数,
,其中,K为量表中题项的总数, 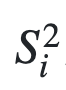 为第i题得分的题内方差, #S_T^2#为全部题项总得分的方差。从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。这种方法适用于态度、意见式问卷(量表)的信度分析。总量表的信度系数最好在8以上,7-0.8之间可以接受;分量表的信度系数最好在0.7以上,0.6-0.7还可以接受。α系数如果在0.6以下就要考虑重新编问卷。
为第i题得分的题内方差, #S_T^2#为全部题项总得分的方差。从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。这种方法适用于态度、意见式问卷(量表)的信度分析。总量表的信度系数最好在8以上,7-0.8之间可以接受;分量表的信度系数最好在0.7以上,0.6-0.7还可以接受。α系数如果在0.6以下就要考虑重新编问卷。
效度:测量有效性。确定有效性有不同的方式。确定有效性有几种不同的方法:
- 内容效度是一种通过考察条目出处的理性而非经验的评估。通常,如果条目是由领域专家创建,或是引用于目标领域或相关领域已有调查问卷的文献中,则我们可以预设该内容是有效的。
- 效标关联效度是指测量结果与某种预设或并发测量这边的相关性,通常使用皮尔逊相关系数来评估。这些相关性并不需要很大就能证明有效性。
- 结构效度是指为问卷所选的条目与调查问卷锁设计的评估基础结构之间的一致性程度。问卷调查人员使用统计程序(主要是因子分析)来发现或确定相关项目的集群。当项目以合理(或按预期的)的方式聚集在一起时,这不仅体现了构建效度,也是形成合理分量表的基础。测量之间在结构上存在高度的相关性可以被认为时聚合效度的证据,反之,在结构上没有达到预期一致性可以被认为时分歧效度的证据。
灵敏度:间接指标时产品比较时达到统计显著性所需的最小样本量,问卷越灵敏,所需的样本量最小。
标准化问卷的特点
- 客观性:允许可用性测试的从业者独立的验证其他从业者的报告。
- 复用性:可以轻松复用别人的研究,甚至是自身的研究。例如,可用性测试的研究一再表明,标准化可用性问卷比费标准化可用性问卷更可靠。
- 量化:标准化测量使得从业者的报告结果有更细微的细节,而不仅只有个人判断。标准化也运行从业者使用高效的数学和统计学方法来理解他们的结果。
- 经济:开发标准化测试需要大量的工作。但是,一旦开发出来,他就能重复使用,非常经济。
- 沟通:当标准化测试可用时,从业者能更加方便的进行有效沟通。
- 科学的普适性:科学结果的普适性是科学工作的核心。标准化对评估结果的普适性必不可少。
常见的标准化可用性问卷
产品或系统的可用性测试后,都想把结果更好地传递给相关方。除了定性的研究结果之外,还有定量的可用性问卷,这些可用性问卷是标准化的,不仅可以科学地量化用户体验,也方便相关方之间有效沟通。常见的标准化可用性问卷有:
- 整体评估问卷
- 任务评估问卷
- 网站感知可用性评估问卷
| 整体评估问卷 | 任务评估问卷 | 网站感知可用性评估问卷 | 用户心理负荷的测量 | 其他有趣的问卷 |
|---|---|---|---|---|
| 用于完成一系列任务场景后,对产品或系统整体的感知可用性测量。 | 每完成一个场景任务,让用户对该任务进行感知可用性测量。 | 大部分标准化可用性问卷最初在20世纪80年代中期到后期被开发,在网络开始流行时,出现了更有针对性的评估网站感知可用性的问卷。 | 用户在使用产品时的心理负荷水平也直接影响着用户的主观满意度。 | CSUQ(电脑系统可用性问卷) |
| QUIS(用户交互满意度问卷) | ASQ(场景后问卷) | WAMMI(网站分析和测量问卷) | SWAT(主观性工作负荷评估技术Subjective Workload Assessment Technology) | CSUQ(电脑系统可用性问卷) |
| SUMI(软件可用性测试问卷) | SEQ(单项难易度问卷 | SUPR-Q(标准化的用户体验百分等级问卷) | NASA-TLX(NASA任务负荷指数National Aeronautics and Space Administration-Task Load Index) | USE(有用性、满意度、易用性) |
| PSSUQ(整体评估可用性问卷) | SMEQ(主观脑力负荷问题) | SUPR_Qm(APP用户体验量表) |
|
| HQ(享受性质量) |
| SUS(系统可用性量表) | ER(期望评分) |
|
| EMO(情绪指标结果) |
| UMUX(用户体验的可用性指标) | UMEX(可用性等级评估) |
|
| ACSI(美国顾客满意度指数) |
| UMUX-LITE(用户体验的可用性指标-简化版) |
|
|
| NPS(净推荐值) |
|
|
|
|
| NPS(净推荐值) |
|
|
|
|
| TAM(技术接受模型) |
寻找度量用户体验的核心指标
NPS,CSAT,CES之间的区别
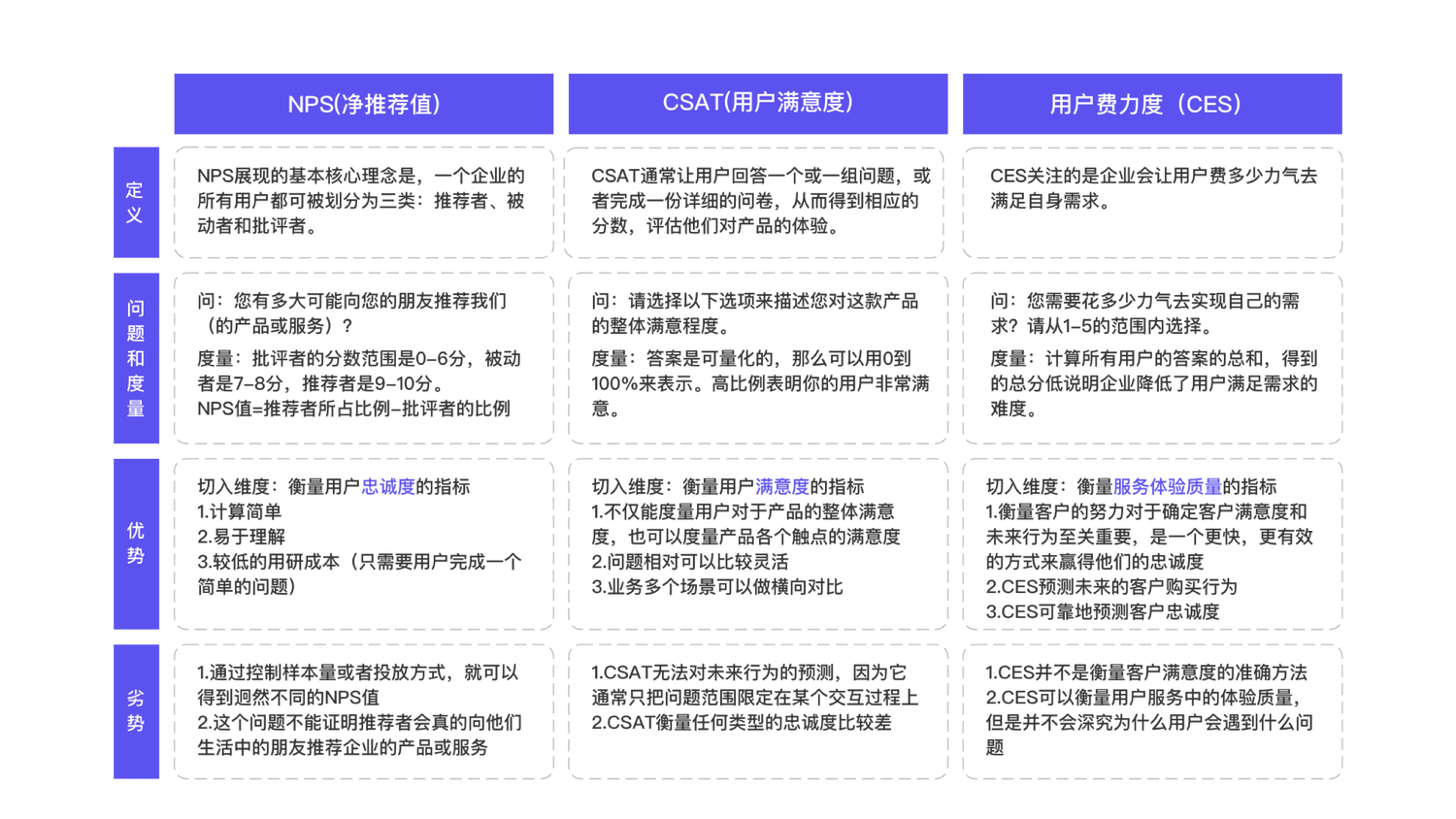
CES 是基于 CSAT 无法客观体现用户忠诚度的研究所提出的,根据 Oracle 的一项研究,82% 的人把他们的购买经历描述为「花费太多的努力」,CES 是想办法减少用户为了解决问题而付出的努力。
从 CES→CSAT→NPS,是一个用户预期的渐进变化,CES 更关注的是基础体验,也就是简单好用。
客户满意度(CSAT)
这应该是最经典的衡量指标了,随着市场竞争的愈加激烈,各行各业对客户满意度都愈加重视,在我们在生活中的方方面面都可以看到关于客户满意度方面的调研。
CSAT要求用户评价对特定事件/体验的满意度,大都使用的是五点量表,包括五个选择:非常满意、满意、一般、不满意、非常不满意。
通过计算选择4分和5分的用户所占比例得出最终的CSAT值。CSAT的好处是简单且扩展性强,例如在客户打开的某个登录页面或是在拨打一次客户电话之后,我们都可以设定一个CSAT题项进行测量。但在这个过程中,一定要注意问题设计的便利性、复杂程度等,通常不要超过3分钟,并且最好能够通过送积分或者抽奖的方式对参与的客户表示感谢。
在分析结果时必须要考虑到“深层原因”。设想一下,如果一个客户对产品或者服务的这个环节满意或不满意,大概会是哪些因素造成的?这些因素之间的关系或权重分别是什么?以此可以得到我们需要关心的具体细节。
当然,CSAT这个衡量指标也存在以下几个问题:
首先,人们很容易在中等范围内回答问题,如果无法引导客户真正参与评分,样本结果很可能无法给企业带来真实的反馈,这些反馈对进一步提升完全没有作用。
其次,即使在客户满意度很高的情况下,你依然有可能遭遇到客户拒绝续签。这是因为满意度并不直接与客户忠诚度相关联。试想,虽然你的客户得到了很好的客户服务,但是他们可能仍旧会因为需要联系客服这一事实感到不开心。
客户费力度(CES)
回想你最后一次和客服部门打交道的情景,假设在一次在线购物后,你发现购买的产品存在缺陷,你需要先给企业打电话,紧接着要把存在缺陷的产品给他们寄回去。对于大多企业,客服部门都有完善的售后处理流程与客服话术,以提升客户满意度,然而即使你对这一客服经历很满意,你却很有可能不会再与这家公司打交道,因为每当回想起他们的产品时你总是会禁不住回想起上一次那一段不顺畅的售后经历。
与其费尽心思为客户提供“满意”的客服经历,我们不如想想其他办法,让问题的解决能够简单快速。许多公司都已经意识到:“简单快速”意味着减少客户流失,企业必须能够让客户“不费力/无须努力”、“简单快速”地与他们打交道。
客户费力度这个概念在2010年在《哈佛商业评论》中被提出,按字面意思理解,“客户费粒度”是让用户评价使用某产品/服务来解决问题的困难程度。第一版的“客户费力度”的问题是:为了得到你想要的服务,你费了多大劲儿?评分从“1(非常低)”到“5(非常高)”,最好在用户刚刚做完操作时询问,否则用户可能忘记自己完成操作的实际体验,下图是现在比较通用的2.0版本:
提出的问题是:企业让我的问题处理过程变得简单。
客户的选项包括:强烈不同意,不同意,有点不同意,中立,有点同意,同意,强烈同意
根据Oracle的一项研究,82%的人把他们的购买经历描述为“花费太多的努力”,CES背后的理论就是,应该想办法减少客户为了解决问题而付出的努力。CES可以帮助你找出可优化的方向,更容易理解在哪里进行改善,较低的费力度也与客户续签直接相关,从而增加客户的生命周期价值。
一般情况下,首先利用“客户满意度”来衡量客户对产品或服务的体验反馈,当这套标准的价值到达临界点时,就应该尝试CES客户费力度,作为满意度的扩充,更充分的评估客户体验情况。
最后,对于客户体验的评估是一个长期的、变化的、复杂的过程,使用哪些指标本身并不能直接代表评估手段的先进与否,更重要的是我们衡量的指标是否可以涵盖客户体验的所有环节。
更重要的是,得出结果后一定要继续洞察,对各项指标的结果的原因进行深入探讨和挖掘,找到提升的方法。比如客户费力度这个指标,通常这时客户已经碰到了问题,如不会使用产品或者使用中出现了错误等等,我们需要往前追溯,找到是否有某个环节中可以帮助在该问题上减少客户费力度。
相关书籍📚
| 用户体验度量 | 看名称就知道可能比较全面? |
|---|---|
参考文章📚
| 用户体验度量 | 看名称就知道可能比较全面? |
|---|---|
| NPS净推荐值(带案例) | |
整理文章参考
| 关于NPS | |
|---|---|
| 关于NPS,CSAT,NPS区别 | |
| 体验度量理论 2021 | 本文章大致思路框架基本来源于此,按照历史脉络梳理 |
| 用户调研之标准化可用性问卷 | 针对于问卷调研时,该采取的思路(较为全面) |
| UMUX |

若有收获,就点个赞吧
0 人点赞
