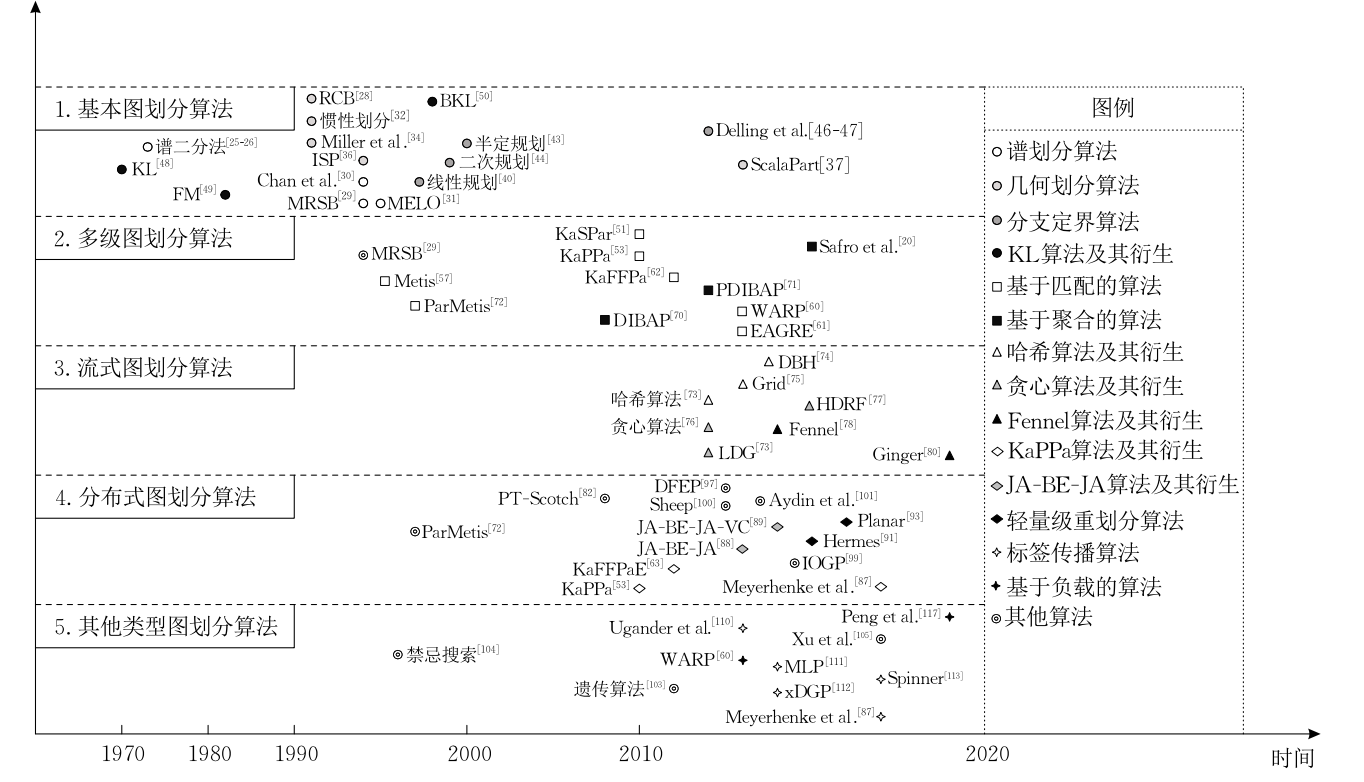
发展历史
早期算法主要在单机环境下运行,随着图数据规模的增大,多级图划分算法逐渐兴起,其将原始图粗糙化为较小图进行划分,再将结果投射回原始图.之后随着大规模知识图谱的出现,多级算法也不能处理现有的大图,人们开始思考如何将现有算法置于分布式环境下运行,于是有了分布式图划分算法.并且将动态图作为划分的输入图,以适应现实中不断更新的数据.近几年提出的流式图划分算法将顶点或边转化成流输入,是另一种划分大规模图的思路.
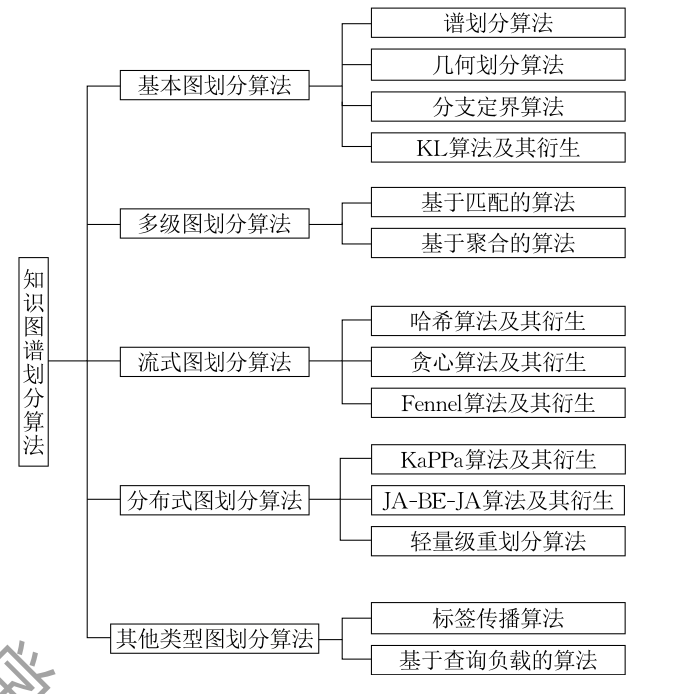
知识图谱划分算法框架
知识图谱划分算法时间轴
概念知识
知识图谱实际上是图数据模型的继承和发展。
知识图谱 G=(V,E)某种扩展形式,V为顶点集合表实体,E为边集合表实体间的联系。在一般图模型的顶点和边上附加上更多的属性信息,用于描述现世界中事物的广泛联系。
知识图谱 主要有以下4种类型,分别是RDF图、属性图、异构信息网络和有向标签图。
RDF:万维网联盟制定的一种表网络信息的标准,通过资源,属性和值来描述特定信息,三元组(s,p,o)s,p,o表示语义数据中的主语,谓语和宾语
算法介绍
K-L(Kernighan-Lin)算法
K-L(Kernighan-Lin)算法是一种将已知网络划分为已知大小的两个社区的二分方法,它是一种贪婪算法。它的主要思想是为网络划分定义了一个函数增益Q,Q表示的是社区内部的边数与社区之间的边数之差,根据这个方法找出使增益函数Q的值成为最大值的划分社区的方法。具体策略是,将社区结构中的结点移动到其他的社区结构中或者交换不同社区结构中的结点。从初始解开始搜索,直到从当前的解出发找不到更优的候选解,然后停止。
K-L算法的缺陷是必须先指定了两个子图的大小,不然不会得到正确的结果,实际应用意义不大。
谱二分算法
当网络中存在两个社区结构时,就能够根据非零特征值所对应的特征向量中的元素值进行结点划分。把所有正元素对应的那些结点划分为同一个社区结构,而所有负元素对应的结点划分为另外一个社区结构。
谱二分算法利用的是Laplace矩阵的特征值和特征向量的性质来做社区划分。Laplace矩阵的第二小特征值λ2的值越小,划分的效果就越好。所以谱二分法使用Laplace矩阵的第二小特征值来划分社区。
谱平分法的缺陷是,一次只能划分2个社区,如果需要划分多个,需要执行多次。如果只需要划分两个社区,谱平分法的效率比较高,但是要划分多个社区的时候,铺平分法的效率就不高了,它的优点也不能得到充分的体现,而且准确度也可能会降低。
<br /> <br /> <br />

若有收获,就点个赞吧
0 人点赞
