Ref: https://pdai.tech/md/java/thread/java-thread-x-juc-collection-ConcurrentHashMap.html
常见问题
- 为什么 HashTable 慢?
- 它的并发度是什么?
- 那么 ConcurrentHashMap 并发度是什么?
- ConcurrentHashMap 在 JDK1.7 和 JDK1.8 中实现有什么差别?JDK1.8 解決了 JDK1.7 中什么问题
- ConcurrentHashMap JDK1.7 实现的原理是什么?分段锁机制
- ConcurrentHashMap JDK1.8 实现的原理是什么?数组 + 链表 + 红黑树,CAS
- ConcurrentHashMap JDK1.7 中 Segment 数 (concurrencyLevel) 默认值是多少?为何一旦初始化就不可再扩容?
- ConcurrentHashMap JDK1.7 说说其 put 的机制?
- ConcurrentHashMap JDK1.7 是如何扩容的?rehash (注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry
- ConcurrentHashMap JDK1.8 是如何扩容的?tryPresize
- ConcurrentHashMap JDK1.8 链表转红黑树的时机是什么?临界值为什么是 8?
- ConcurrentHashMap JDK1.8 是如何进行数据迁移的?transfer
为什么 HashTable 慢
Hashtable 之所以效率低下主要是因为其实现使用了 synchronized 关键字对 put 等操作进行加锁,而 synchronized 关键字加锁是对整个对象进行加锁,也就是说在进行 put 等修改 Hash 表的操作时,锁住了整个 Hash 表,从而使得其表现的效率低下(get 也加锁)。ConcurrentHashMap - JDK 1.8
在 JDK1.7 之前,ConcurrentHashMap 是通过分段锁机制来实现的,所以其最大并发度受 Segment 的个数限制。因此,在 JDK1.8 中,ConcurrentHashMap 的实现原理摒弃了这种设计,而是选择了与 HashMap 类似的数组 + 链表 + 红黑树的方式实现,而加锁则采用 CAS 和 synchronized 实现。数据结构
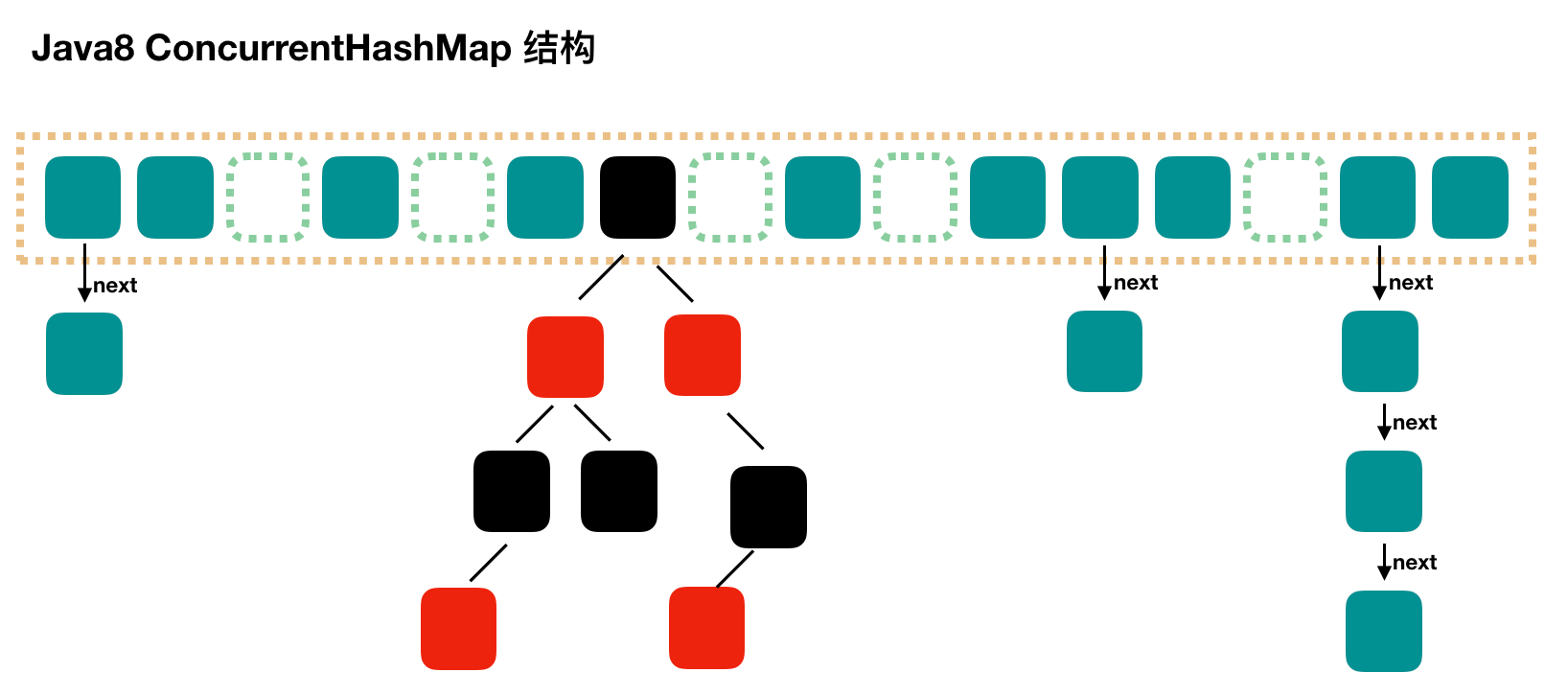
结构上和 Java8 的 HashMap 基本上一样,不过它要保证线程安全性,所以在源码上确实要复杂一些。并发度
Ref: https://blog.csdn.net/LO_YUN/article/details/106358362
通过 ConcurrentHashMap 的 put 方法,我们可以发现,加锁分为了两种:
1、没有发生 hash 冲突的时候,如果添加的元素的位置在数组中是空的话,那么就使用 CAS 的方式来加入元素,这里加锁的粒度是数组中的元素
2、如果出现了 hash 冲突,添加的元素的位置在数组中已经有了值,那么又存在三种情况
(1)key 相同,那么直接用新的元素覆盖旧的元素
(2)如果数组中的元素是链表的形式,那么将新的元素挂载在链表尾部
(3)如果数组中的元素是红黑树的形式,那么将新的元素加入到红黑树
第二种情况使用的是 synchronized 加锁,锁住的对象就是数组中的元素,加锁的粒度和第一种情况相同
得出结论,ConcurrentHashMap 的分段加锁机制,其实锁住的就是数组中的元素,当操作数组中不同的元素时,是不会产生竞争的
并发度对比
上面所说的都是 JDK1.8 的 ConcurrentHashMap 的实现,那么这个实现机制和 JDK1.7 中的 ConcurrentHashMap 又有什么不同呢?
在 JDK1.7 中,ConcurrentHashMap 使用的是 segment 锁,是继承自 ReentrantLock,一旦初始化完成,就不能再改变了,但是 segment 数组中的 HashEntry 数组是可以改变的
jdk1.8 中的 ConcurrentHashMap 中废弃了 segment 锁,直接使用了数组元素,数组中的每个元素都可以作为一个锁,在元素中没有值的情况下,可以直接通过 CAS 操作来设值,同时保证并发安全,如果元素里面已经存在值的话,那么就使用 synchronized 关键字对元素加锁,再进行之后的 hash 冲突处理。
随着数组扩容的话,这里面的元素增多,可加的锁也增多了,所以说 jdk1.8 的 ConcurrentHashMap 加锁粒度比 1.7 更细,jdk1.7 里加锁只能对 segment 来加锁,而且初始化了就不能改变。
综上所述,JDK1.8 中的 ConcurrentHashMap 加锁的粒度更细,并发性能更好。
ConcurrentHashMap - JDK 1.7
在 JDK1.5~1.7 版本,Java 使用了分段锁机制实现 ConcurrentHashMap.
简而言之,ConcurrentHashMap 在对象中保存了一个 Segment 数组,即将整个 Hash 表划分为多个分段;而每个 Segment 元素,即每个分段则类似于一个 Hashtable;这样,在执行 put 操作时首先根据 hash 算法定位到元素属于哪个 Segment,然后对该 Segment 加锁即可。因此,ConcurrentHashMap 在多线程并发编程中可实现多线程 put 操作。接下来分析 JDK1.7 版本中 ConcurrentHashMap 的实现原理。
数据结构
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表” 部分 “或” 一段 “的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了 “槽” 来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。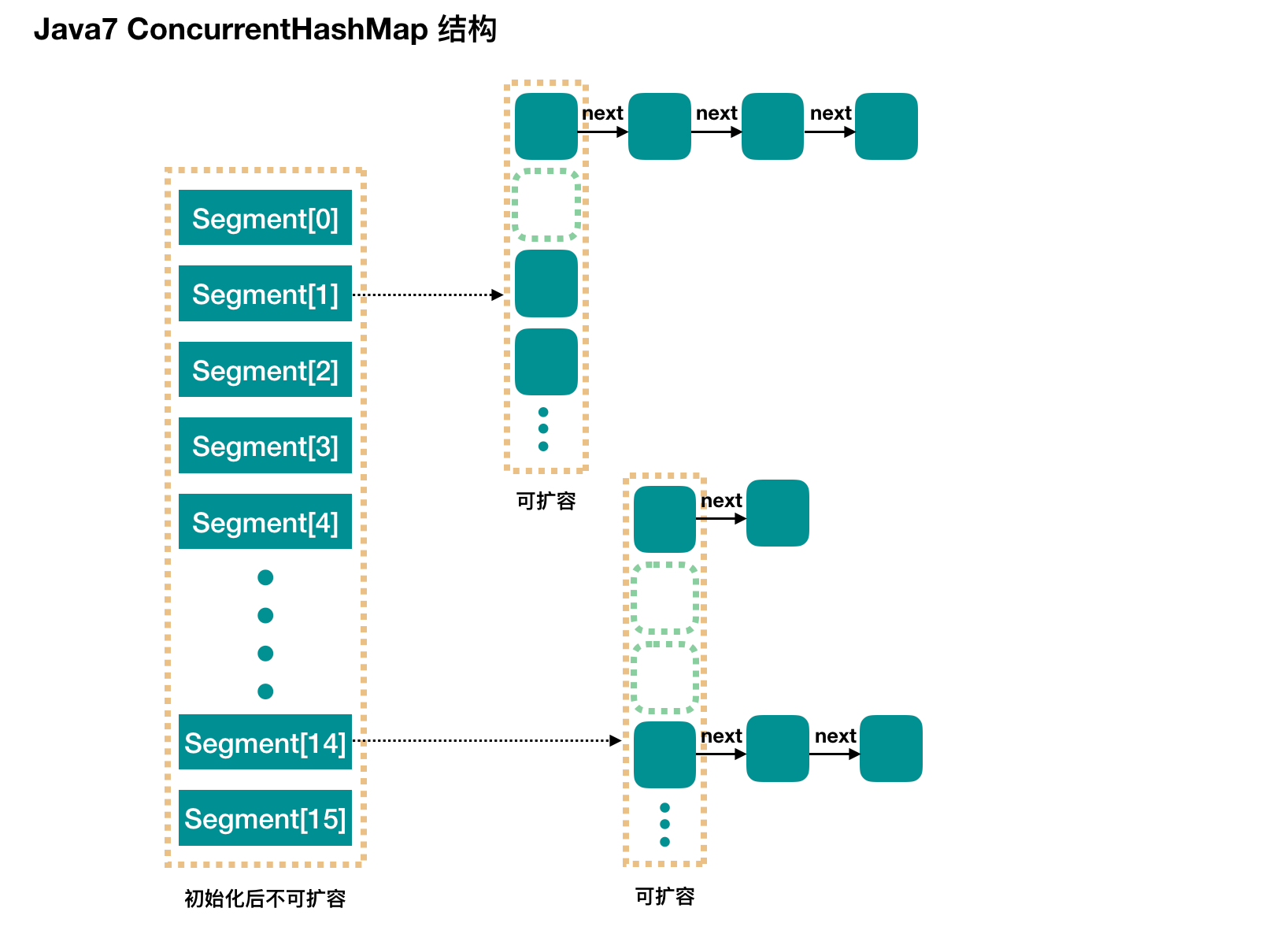
concurrencyLevel: 并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
对比总结
- HashTable : 使用了 synchronized 关键字对 put 等操作进行加锁;
- ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
- ConcurrentHashMap JDK1.8: 则使用数组 + 链表 + 红黑树数据结构和 CAS 原子操作实现;

若有收获,就点个赞吧
0 人点赞
