Ref: https://pdai.tech/md/java/thread/java-thread-x-juc-executor-ForkJoinPool.html
ForkJoinPool 是 JDK 7 加入的一个线程池类。Fork/Join 技术是分治算法 (Divide-and-Conquer) 的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。@pdai
带着问题去理解 Fork/Join 框架
- Fork/Join 主要用来解决什么样的问题?
- Fork/Join 框架是在哪个 JDK 版本中引入的?
- Fork/Join 框架主要包含哪三个模块?模块之间的关系是怎么样的?
- ForkJoinPool 类继承关系?
- ForkJoinTask 抽象类继承关系?在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
- 整个 Fork/Join 框架的执行流程 / 运行机制是怎么样的?
- 具体阐述 Fork/Join 的分治思想和 work-stealing 实现方式?
- 有哪些 JDK 源码中使用了 Fork/Join 思想?
- 如何使用 Executors 工具类创建 ForkJoinPool?
- 写一个例子:用 ForkJoin 方式实现 1+2+3+…+100000?
Fork/Join 在使用时有哪些注意事项?结合 JDK 中的斐波那契数列实例具体说明。
1.Fork/Join 框架简介
Fork/Join 框架是 Java 并发工具包中的一种可以将一个大任务拆分为很多小任务来异步执行的工具,自 JDK1.7 引入。
1.1 三个模块及关系
Fork/Join 框架主要包含三个模块:
任务对象: ForkJoinTask (包括 RecursiveTask、RecursiveAction 和 CountedCompleter)
- 执行 Fork/Join 任务的线程: ForkJoinWorkerThread
- 线程池: ForkJoinPool
这三者的关系是: ForkJoinPool 可以通过池中的 ForkJoinWorkerThread 来处理 ForkJoinTask 任务。
ForkJoinPool 只接收 ForkJoinTask 任务 (在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),
- RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,
- RecursiveAction 是一个无返回值的 RecursiveTask,
- CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
1.2 分治算法 (Divide-and-Conquer)
分治算法 (Divide-and-Conquer) 把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制: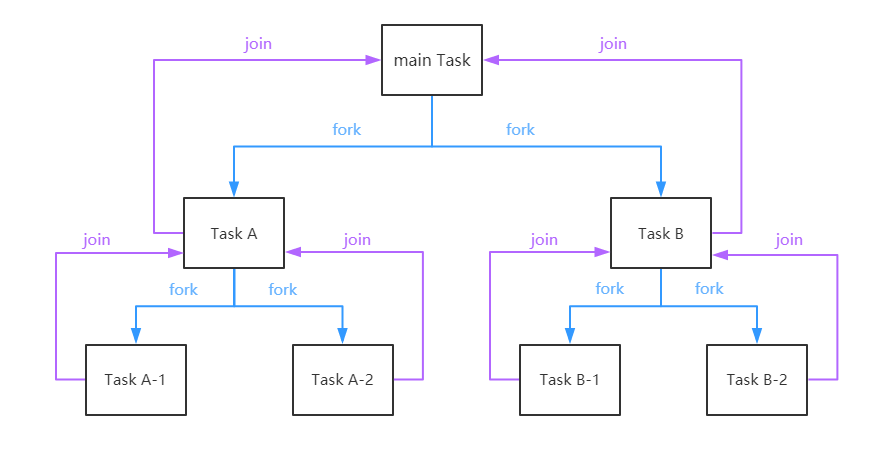
- 这里也可以一并看下: 算法思想 - 分治算法
1.3 work-stealing (工作窃取) 算法
work-stealing (工作窃取) 算法:线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务 (如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并 (join) 的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程 (ForkJoinWorkerThread) 都对应一个任务队列 (WorkQueue),工作线程优先处理来自自身队列的任务 (LIFO 或 FIFO 顺序,参数 mode 决定),然后以 FIFO 的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的一个 WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能 push、pop、poll
- push/pop 只能被队列的所有者线程调用,而 poll 可以被其他线程调用。
- 划分的子任务调用 fork 时,都会被 push 到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获出任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用 poll 方法窃取任务。
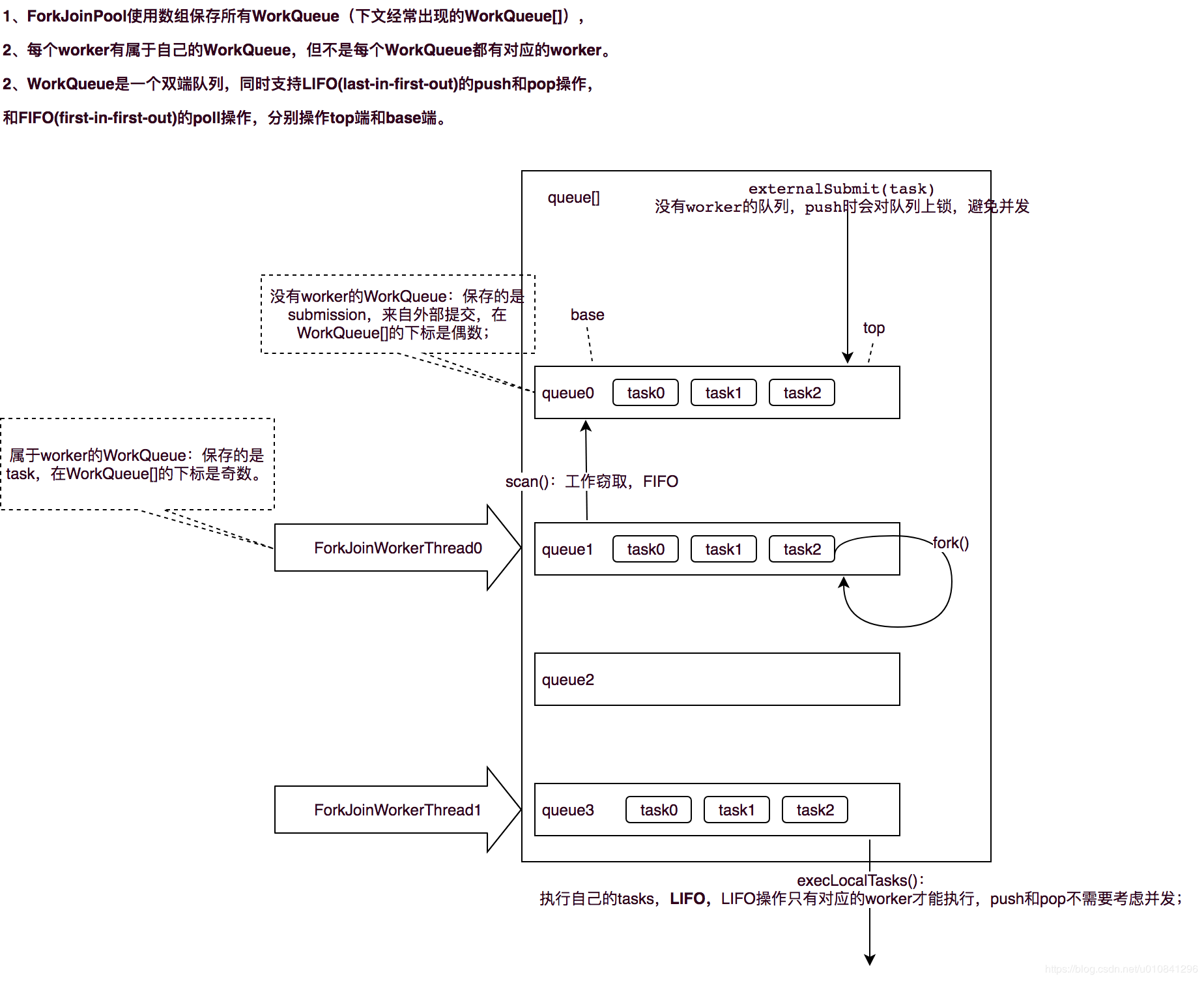
1.4 Fork/Join 框架的执行流程
上图可以看出 ForkJoinPool 中的任务执行分两种:
- 直接通过 FJP 提交的外部任务 (external/submissions task),存放在 workQueues 的偶数槽位;
- 通过内部 fork 分割的子任务 (Worker task),存放在 workQueues 的奇数槽位。
Fork/Join 框架的执行流程: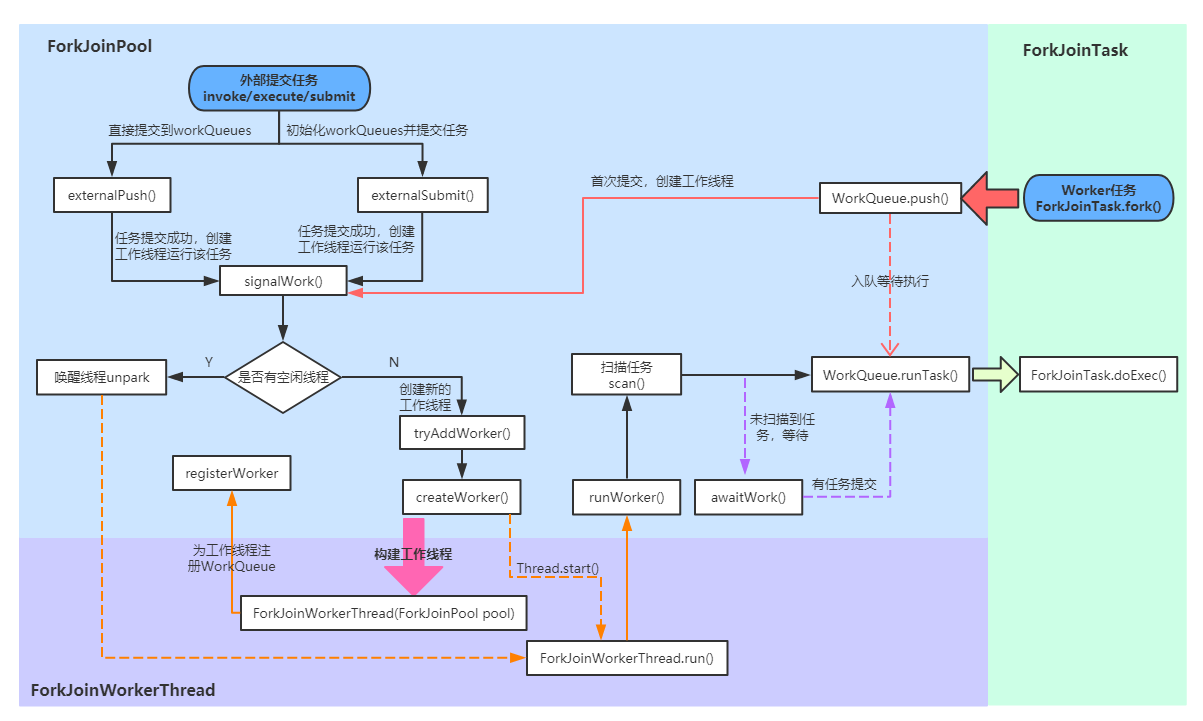
后续的源码解析将围绕上图进行。
2.Fork/Join 类关系
2.1 ForkJoinPool 继承关系
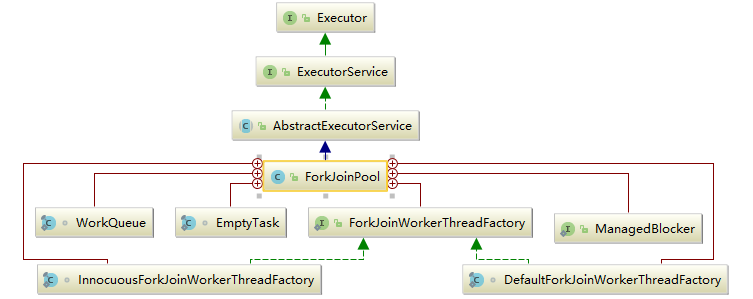
内部类介绍:
- ForkJoinWorkerThreadFactory: 内部线程工厂接口,用于创建工作线程 ForkJoinWorkerThread
- DefaultForkJoinWorkerThreadFactory: ForkJoinWorkerThreadFactory 的默认实现类
- InnocuousForkJoinWorkerThreadFactory: 实现了 ForkJoinWorkerThreadFactory,无许可线程工厂,当系统变量中有系统安全管理相关属性时,默认使用这个工厂创建工作线程。
- EmptyTask: 内部占位类,用于替换队列中 join 的任务。
- ManagedBlocker: 为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用在可能会阻塞的任务 (如在 Phaser 中用于等待 phase 到下一个 generation)。
- WorkQueue: ForkJoinPool 的核心数据结构,本质上是 work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 对象任务,使用 @Contented 注解修饰防止伪共享。
- 工作线程在运行中产生新的任务 (通常是因为调用了 fork ()) 时,此时可以把 WorkQueue 的数据结构视为一个栈,新的任务会放入栈顶 (top 位);工作线程在处理自己工作队列的任务时,按照 LIFO 的顺序。
- 工作线程在处理自己的工作队列同时,会尝试窃取一个任务 (可能是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 的队列,窃取的任务位于其他线程的工作队列的队首 (base 位)。
- 伪共享状态:缓存系统中是以缓存行 (cache line) 为单位存储的。缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64 个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
2.2 ForkJoinTask 继承关系
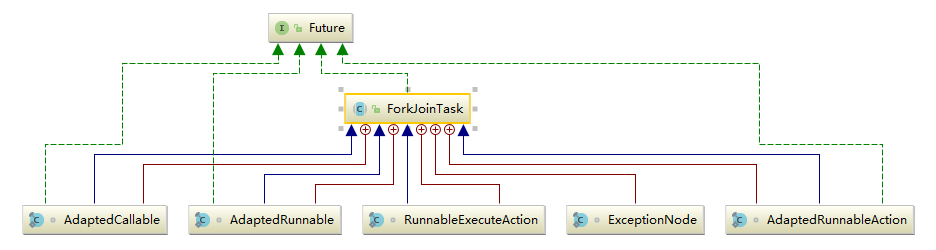
ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务,实际上 ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。 其内部类都比较简单,ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务 (因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/java/thread/java-thread-x-juc-executor-ForkJoinPool.html
3.Fork/Join 的陷阱与注意事项
使用 Fork/Join 框架时,需要注意一些陷阱,在下面 斐波那契数列例子中你将看到示例:
3.1 避免不必要的 fork ()
划分成两个子任务后,不要同时调用两个子任务的 fork () 方法。
表面上看上去两个子任务都 fork (),然后 join () 两次似乎更自然。但事实证明,直接调用 compute () 效率更高。因为直接调用子任务的 compute () 方法实际上就是在当前的工作线程进行了计算 (线程重用),这比 “将子任务提交到工作队列,线程又从工作队列中拿任务” 快得多。
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的 invokeAll 方法,因为使用它们能避免不必要的 fork ()。
3.2 注意 fork ()、compute ()、join () 的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
right.fork(); // 计算右边的任务long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)long rightAns = right.join(); // 等待右边的结果return leftAns + rightAns;
如果我们写成:
left.fork(); // 计算完左边的任务long leftAns = left.join(); // 等待左边的计算结果long rightAns = right.compute(); // 再计算右边的任务return leftAns + rightAns;
或者:
long rightAns = right.compute(); // 计算完右边的任务left.fork(); // 再计算左边的任务long leftAns = left.join(); // 等待左边的计算结果return leftAns + rightAns;
这两种实际上都没有并行。
3.3 选择合适的子任务粒度
选择划分子任务的粒度 (顺序执行的阈值) 很重要,因为使用 Fork/Join 框架并不一定比顺序执行任务的效率高:如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork () 子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是:任务应该执行 100~10000 个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是 “上上策”。
和其他 Java 代码一样,Fork/Join 框架测试时需要 “预热” 或者说执行几遍才会被 JIT (Just-in-time) 编译器优化,所以测试性能之前跑几遍程序很重要。
3.4 避免重量级任务划分与结果合并
Fork/Join 的很多使用场景都用到数组或者 List 等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免 System.arraycopy 这样耗时耗空间的操作,从而最小化任务的处理开销。
4.再深入理解
4.1 有哪些 JDK 源码中使用了 Fork/Join 思想?
我们常用的数组工具类 Arrays 在 JDK 8 之后新增的并行排序方法 (parallelSort) 就运用了 ForkJoinPool 的特性,还有 ConcurrentHashMap 在 JDK 8 之后添加的函数式方法 (如 forEach 等) 也有运用。
4.2 使用 Executors 工具类创建 ForkJoinPool
Java8 在 Executors 工具类中新增了两个工厂方法:
// parallelism定义并行级别public static ExecutorService newWorkStealingPool(int parallelism);// 默认并行级别为JVM可用的处理器个数// Runtime.getRuntime().availableProcessors()public static ExecutorService newWorkStealingPool();
4.3 关于 Fork/Join 异常处理
Java 的受检异常机制一直饱受诟病,所以在 ForkJoinTask 的 invoke ()、join () 方法及其衍生方法中都没有像 get () 方法那样抛出个 ExecutionException 的受检异常。
所以你可以在 ForkJoinTask 中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) {if (ex != null)ForkJoinTask.<RuntimeException>uncheckedThrow(ex);}@SuppressWarnings("unchecked")static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {throw (T)t; // rely on vacuous cast}
关于 Java 你不知道的 10 件事中已经指出,JVM 实际并不关心这个异常是受检异常还是运行时异常,受检异常这东西完全是给 Java 编译器用的:用于警告程序员这里有个异常没有处理。
但不可否认的是 invoke、join () 仍可能会抛出运行时异常,所以 ForkJoinTask 还提供了两个不提取结果和异常的方法 quietlyInvoke ()、quietlyJoin (),这两个方法允许你在所有任务完成后对结果和异常进行处理。
使用 quitelyInvoke () 和 quietlyJoin () 时可以配合 isCompletedAbnormally () 和 isCompletedNormally () 方法使用。

若有收获,就点个赞吧
0 人点赞
