Ref: https://www.jianshu.com/p/bf1d7eee28d0
雅虎的 Chief Scientist ,Udi Manber 曾说过,在 yahoo 所应用的算法中,最重要的三个是:Hash,Hash 和 Hash。git 用 sha1 判断文件更改,密码用 MD5 生成摘要后加盐等等对 Hash 的应用可看出,Hash 的在计算机世界扮演着多么重要的角色。
1.HashMap 的复杂度
在介绍 HashMap 的实现之前,先考虑一下,HashMap 与 ArrayList 和 LinkedList 在数据复杂度上有什么区别。下图是他们的性能对比图:
| 获取 | 查找 | 添加/删除 | 空间 | 时间 |
|---|---|---|---|---|
| ArrayList | O(1) | O(1) | O(N) | O(N) |
| LinkedList | O(N) | O(N) | O(1) | O(N) |
| HashMap | O(N/Bucket_size) | O(N/Bucket_size) | O(N/Bucket_size) | O(N) |
可以看出 HashMap 整体上性能都非常不错,但是不稳定,为 O(N/Buckets),N 就是以数组中没有发生碰撞的元素,Buckets 是因碰撞产生的链表。
注:发生碰撞实际上是非常稀少的,所以 N/Bucket_size 约等于1
HashMap 是对 Array 与 Link 的折衷处理,Array 与 Link 可以说是两个速度方向的极端,Array注重于数据的获取,而处理修改(添加/删除)的效率非常低;Link由于是每个对象都保持着下一个对象的指针,查找某个数据需要遍历之前所有的数据,所以效率比较低,而在修改操作中比较快。
2.HashMap 的实现
2.1 对 key 进行 Hash 计算
在 JDK8 中,由于使用了红黑树来处理大的链表开销,所以 hash 这边可以更加省力了,只用计算 hashCode 并移动到低位就可以了。
static final int hash(Object key) {int h;// 计算hashCode 并无符号移动到低位return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
举个例子: 363771819^(363771819 >>> 16)
0001 0101 1010 1110 1011 0111 1010 1011 (363771819)
0000 0000 0000 0000 0001 0101 1010 1110 (5550) XOR
————————————————————— =
0001 0101 1010 1110 1010 0010 0000 0101 (363766277)
这样做可以实现了高低位更加均匀地混到一起。
Java 中几个常用的哈希码(hashCode)的算法:
- Object 类的 hashCode:返回对象的经过处理后的内存地址,由于每个对象的内存地址都不一样,所以哈希码也不一样。这个是 native 方法,取决于 JVM 的内部设计,一般是某种 C 地址的偏移。
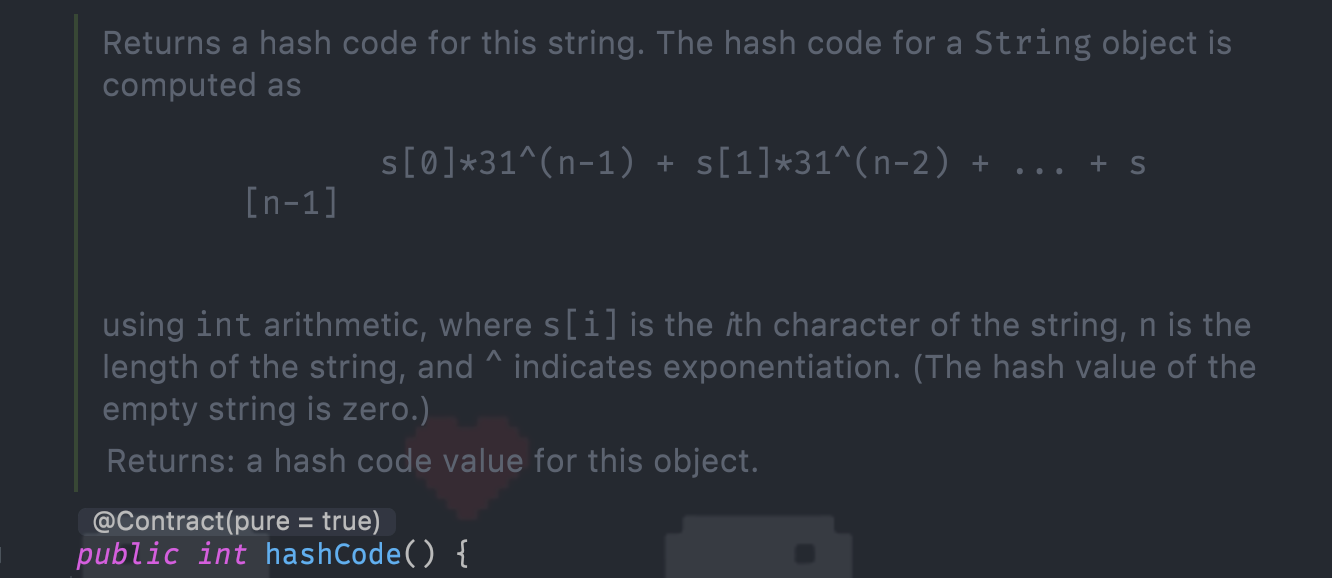
- String 类的 hashCode:根据 String 类包含的字符串的内容,根据一种特殊算法返回哈希码,只要字符串的内容相同,返回的哈希码也相同。
- Integer 等包装类,返回的哈希码就是 Integer 对象里所包含的那个整数的数值,例如 Integer i1 = new Integer(100), i1.hashCode 的值就是 100 。由此可见,2个一样大小的Integer对象,返回的哈希码也一样。
- int,char 这样的基础类,它们不需要 hashCode,如果需要存储时,将进行自动装箱操作,计算方法同上。
2.2 获取到数组的 index 的位置
计算了Hash,我们现在要把它插入数组中了i = (tab.length - 1) & hash;
通过位运算,确定了当前的位置,因为 HashMap 数组的大小总是 2^n,所以实际的运算就是 (0xfff…ff) & hash ,这里的 tab.length-1 相当于一个 mask,滤掉了大于当前长度位的 hash,使每个 i 都能插入到数组中。2.3 生成包装类
这个对象是一个包装类,Nodestatic class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;// getter and setter .etc.}
2.4 插入包装类到数组
(1) 如果输入当前的位置是空的,就插进去,如图,左为插入前,右为插入后
0 0
| |
1 -> null 1 - > null
| |
2 -> null 2 - > null
| |
.. -> null .. - > null
| |
i -> null i - > new node
| |
n -> null n - > null
(2) 如果当前位置已经有了node,且它们发生了碰撞,则新的放到前面,旧的放到后面,这叫做链地址法处理冲突。
0 0
| |
1 -> null 1 - > null
| |
2 -> null 2 - > null
| |
..-> null ..- > null
| |
i -> old i - > new - > old
| |
n -> null n - > null
我们可以发现,失败的 hashCode 算法会导致 HashMap 的性能由数组下降为链表,所以想要避免发生碰撞,就要提高 hashCode 结果的均匀性。
3.扩容
如果当表中的 75% 已经被占用,即视为需要扩容了:(threshold = capacity * load factor ) < size
它主要有两个步骤:
- 容量加倍
-
3.1 容量加倍
左移1位,就是扩大到两倍,用位运算取代了乘法运算
newCap = oldCap << 1;
newThr = oldThr << 1;3.2 遍历计算 Hash
for (int j = 0; j < oldCap; ++j) { Node<K,V> e; //如果发现当前有Bucket if ((e = oldTab[j]) != null) { oldTab[j] = null; //如果这里没有碰撞 if (e.next == null) //重新计算Hash,分配位置 newTab[e.hash & (newCap - 1)] = e; //这个见下面的新特性介绍,如果是树,就填入树 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //如果是链表,就保留顺序....目前就看懂这点 else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } }由此可以看出扩容需要遍历并重新赋值,成本非常高,所以选择一个好的初始容量非常重要。
4.扩容如何提升性能?
解决扩容损失:如果知道大致需要的容量,把初始容量设置好以解决扩容损失; 比如我现在有 1000 个数据,需要 1000/0.75 = 1333 个坑位,又 1024 < 1333 < 2048,所以最好使用 2048 作为初始容量。
解决碰撞损失:使用高效的 HashCode 与 loadFactor,这个…由于 JDK8 的高性能出现,这儿问题也不大了。
5.HashMap 与 HashTable 的主要区别
在很多的 Java 基础书上都已经说过了,他们的主要区别其实就是 Table 全局加了线程同步保护。
HashTable 线程更加安全,代价就是因为它粗暴的添加了同步锁,所以会有性能损失。
- 其实有更好的 concurrentHashMap 可以替代 HashTable,一个是方法级,一个是实例对象级。

若有收获,就点个赞吧
0 人点赞
