Zipkin 是分布式追踪系统。它的作用是收集解决微服务架构中的延迟问题所需的时序数据。它管理这些数据的收集和查找,Zipkin 的设计基于Google Dapper论文。
官方地址:https://zipkin.io/
安装
官方安装地址 https://zipkin.io/pages/quickstart.html
Docker
The Docker Zipkin project is able to build docker images, provide scripts and a docker-compose.ymlfor launching pre-built images. The quickest start is to run the latest image directly:
sudo docker run -d -p 9411:9411 openzipkin/zipkin
Java
If you have Java 8 or higher installed, the quickest way to get started is to fetch the latest release as a self-contained executable jar:
curl -sSL https://zipkin.io/quickstart.sh | bash -sjava -jar zipkin.jar
源码编译
Zipkin can be run from source if you are developing new features. To achieve this, you’ll need to get Zipkin’s source and build it.
# get the latest sourcegit clone https://github.com/openzipkin/zipkincd zipkin# Build the server and also make its dependencies./mvnw -DskipTests --also-make -pl zipkin-server clean install# Run the serverjava -jar ./zipkin-server/target/zipkin-server-*exec.jar
架构
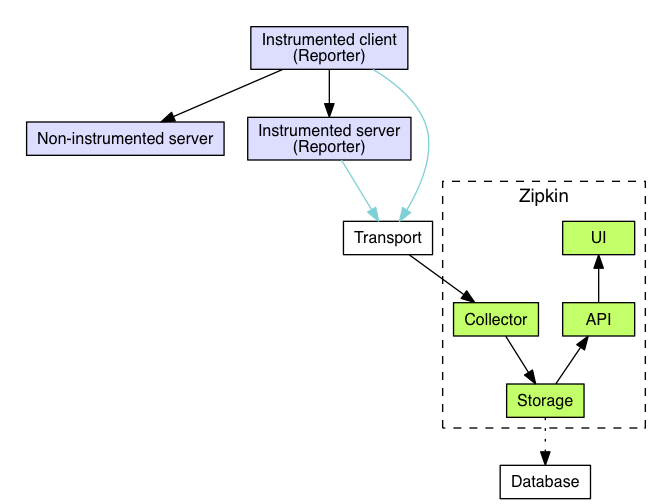
OpenZipkin主要由四个核心部分组成。
- Collector:负责收集探针Reporter埋点采集的数据,经过验证处理并建立索引。
- Storage:存储服务调用的链路数据,默认使用的是Cassandra,是因为Twitter内部大量使用了Cassandra,你也可以替换成Elasticsearch或者MySQL。
- API:将格式化和建立索引的链路数据以API的方式对外提供服务,比如被UI调用。
- UI:以图形化的方式展示服务调用的链路数据。
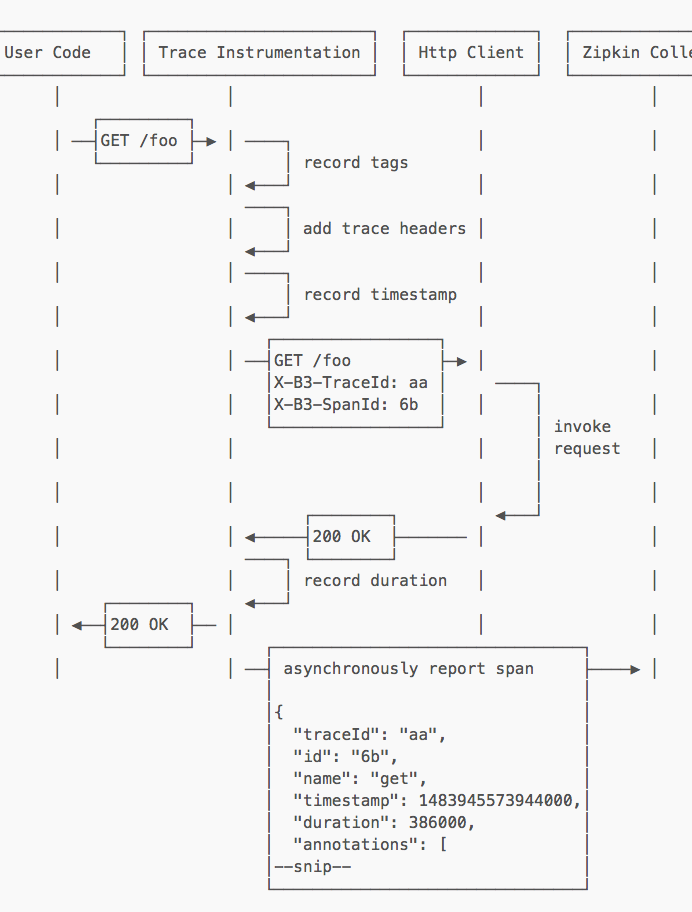
具体流程是,通过在业务的HTTP Client前后引入服务追踪代码,这样在HTTP方法“/foo”调用前,生成trace信息:TraceId:aa、SpanId:6b、annotation:GET /foo,以及当前时刻的timestamp:1483945573944000,然后调用结果返回后,记录下耗时duration,之后再把这些trace信息和duration异步上传给Zipkin Collector。
参考
https://help.aliyun.com/product/90275.html?spm=a2c4g.11186623.3.1.48b6acceQot71t
https://juejin.im/post/5ade6ef06fb9a07abc2989b9

若有收获,就点个赞吧
0 人点赞
