Redis高性能的原理
- Redis是单线程的,避免了多线程的上下文切换和并发控制开销;
- Redis大部分操作时基于内存,读写数据不需要磁盘I/O,所以速度非常快;
- Redis采用了I/O多路复用机制,提高了网络I/O并发性;
- Redis提供高效的数据结构,如跳跃表、哈希表等;
过期策略
设置方式
一个key过期,并不会马上清除,而是惰性删除。
即当下次读取这个 key 时会进行检查,如果发现已经过期了,会返回空,并且立即删除掉它。
当一个key被scan的时候发现已经过期了,也会被删除。
- 定期删除
上面提到的惰性删除有一个问题,那就是,如果一个key已经过期了,但永远不会被读取到,它就会一直在内存中,浪费内存空间。
为了解决这个问题,redis又在“惰性删除”的基础上加了“定期删除”机制。
redis会随机读取一些key进行检查,如果发现它们过期了,就会立即删除它们。当然,实际的实现要比这复杂,但这是主要思想
- 内存淘汰机制
VolatileLRU 按照LRU算法逐出原有数据,但仅逐出设置了过期时间的数据(常用)
VolatileTTL 仅逐出设置了过期时间的数据,并且是按照TTL从小到大的顺序进行逐出
VolatileRandom 随机逐出原有数据,但仅逐出设置了过期时间的数据
AllKeysLRU 按照LRU算法逐出原有数据
AllKeysRandom 随机逐出原有数据
NoEviction 不逐出任何数据,新数据的写入会得到一个错误信息
持久化
- RDB 指定的时间间隔内将内存中的数据集快照写入磁盘,可手动触发、或根据配置文件周期内自动触发
- AOF 每次执行的写命令保存到硬盘,实时性更好,因此已成为主流的持久化方案
位图的使用
主从复制
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
哨兵
主节点的自动故障转移
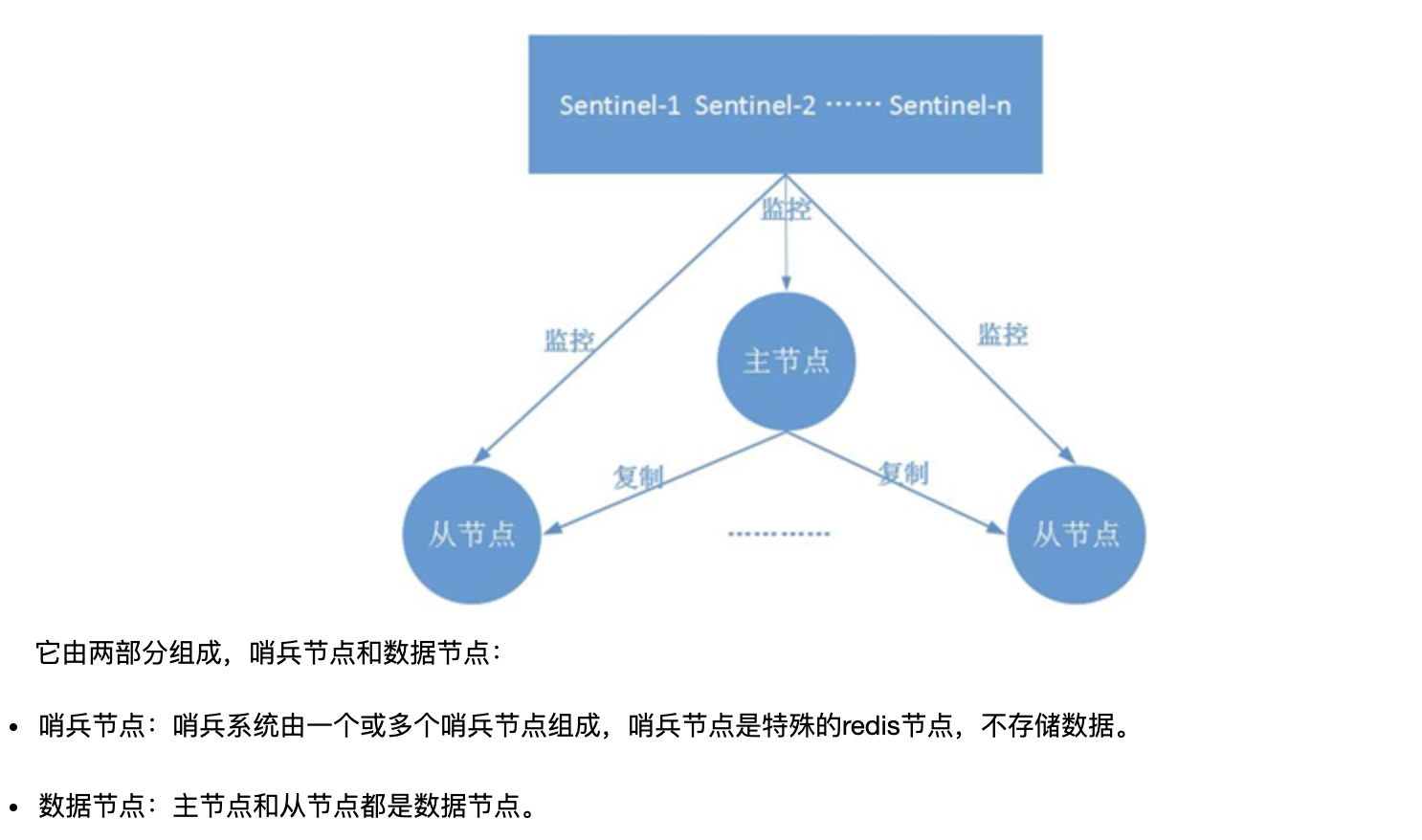
基本原理
关于哨兵的原理,关键是了解以下几个概念。
(1)定时任务:每个哨兵节点维护了3个定时任务。定时任务的功能分别如下:通过向主从节点发送info命令获取最新的主从结构;通过发布订阅功能获取其他哨兵节点的信息;通过向其他节点发送ping命令进行心跳检测,判断是否下线。
(2)主观下线:在心跳检测的定时任务中,如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线;与主观下线相对应的是客观下线。
(3)客观下线:哨兵节点在对主节点进行主观下线后,会通过sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
(4)选举领导者哨兵节点:当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为领导者。
(5)故障转移:选举出的领导者哨兵,开始进行故障转移操作,该操作大体可以分为3个步骤:
在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点;然后选择优先级最高的从节点(由slave-priority指定);如果优先级无法区分,则选择复制偏移量最大的从节点;如果仍无法区分,则选择runid最小的从节点。
更新主从状态:通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
将已经下线的主节点(即6379)设置为新的主节点的从节点,当6379重新上线后,它会成为新的主节点的从节点。
集群
1、数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出……。
2、高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
设计集群方案时,至少要考虑以下因素:
(1)高可用要求:根据故障转移的原理,至少需要3个主节点才能完成故障转移,且3个主节点不应在同一台物理机上;每个主节点至少需要1个从节点,且主从节点不应在一台物理机上;因此高可用集群至少包含6个节点。
(2)数据量和访问量:估算应用需要的数据量和总访问量(考虑业务发展,留有冗余),结合每个主节点的容量和能承受的访问量(可以通过benchmark得到较准确估计),计算需要的主节点数量。
(3)节点数量限制:Redis官方给出的节点数量限制为1000,主要是考虑节点间通信带来的消耗。在实际应用中应尽量避免大集群;如果节点数量不足以满足应用对Redis数据量和访问量的要求,可以考虑:(1)业务分割,大集群分为多个小集群;(2)减少不必要的数据;(3)调整数据过期策略等。
(4)适度冗余:Redis可以在不影响集群服务的情况下增加节点,因此节点数量适当冗余即可,不用太大。
参考

若有收获,就点个赞吧
0 人点赞
