踩坑
Server sent charset unknown to the client
版本
php 5.6 mysqld 8.0.17 for Linux on x86_64 (Source distribution)
报错
SQLSTATE[HY000] [2054] Server sent charset unknown to the client
了解SQL
SQL发音:字母S-Q-L 或单词 sequel
数据库 database
表 table
列和数据类型
比如char 和varchar的区别及性能比较
获取创建表的原始SQL
命令行工具导出表结构
mysqldump -u root -p -d 数据库名 [表名] > /tmp/export.sql
行
主键
应该总是定义主键
检索数据
检索所有列
通配符 * 在不确定列的名字很方便,但是能不用就不要用,因为会降低检索和应用程序的性能
DISTINCT去重
该关键字必须放在所有字段开头,并且不能部分使用DISTINCT,该关键字作用于所有的列,不仅仅是跟在其后的那一列。例如,你指定了 SELECT DISTINCT vand_id, prod_price
字段计算
AS别名
字段拼接
ConCat (Mysql 或 MariaDB)
+ SQL Server
|| DB2 Oracle PostgreSQL SQLlite
四则运算
函数
字符串
时间日期
数值
汇总数据
WHERE过滤数据
WHERE子句操作符
=
<>
!=
<
<=
!<
>
>=
!>
BETWEEN
IN
IS NULL
NOT (否定后面所有的条件,有点类似 <> ,但在某些复杂子句会用到,比如IN)
组合WHERE子句
LIKE通配符过滤
百分号 %
下划线 _ 匹配单个字符
方括号 [] 指定一个字符集
性能差,尽量不要用
尽量不要用在搜索模式的开始处
注意通配符的位置
分组数据
GROUP BY
GROUP BY 必须在WHERE之后,ORDER BY 之前
除聚集计算语句外,SELECT语句中的每一列都必须出现在GROUP BY 子句中
HAVING
WHERE 在数据分组前过滤,HAVING在数据分组后进行过滤
HAVING支持WHERE的所有操作符
限制检出结果
limit offset 的使用
大表limit翻页优化(待验证 TODO)SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
排序
保证order by 是SELECT语句中的最后一条子句
按多个列排序时,order by 多个字段 用逗号分隔
注释
单行注释 —
多行注释 / /
子查询
mysql支持子查询是从4.1版本开始的
在WHERE后使用子查询进行过滤
SELECT cust_idFROM OrdersWHERE order_num IN ( SELECT order_numFROM orderItemsWHERE pro_id = 'RGAN01') ;
作为子查询的SELECT语句只能查询单个列
作为计算字段的使用子查询
SELECT cust_name,
cust_status,
(SELECT COUNT(*)
FROM Orders
WHERE Orders.cust_id = Customers.cust_id ) AS orders
FROM Customers
ORDER BY cust_name;
表别名
联结表
直接FROM多个表
SELECT vend_name, prod_name, prod_price
FROM Vendors, Products
WHERE Vendors.vend_id = Products.vend_id;
内联结
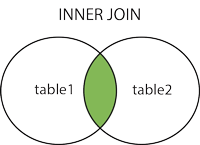
SELECT vend_name, prod_name, prod_price
FROM Vendors INNER JOIN Products
ON Vendors.vend_id = Products.vend_id;
INNER JOIN 与 JOIN 是相同的
联表比较消耗资源和性能
给定的SQL操作一般不止一种方法
自联结 self join
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';
许多DBMS处理联结远比处理子查询快的多,应该试一下两种方法,确定哪一种的性能更好
自然联结 natural join
外联结 outer join
LEFT OUTER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
mysql不支持全联结,可以用SQL Server测试
UNION组合查询
UNION必须有两条或以上的SELECT的语句组成
每个查询必须包含相同的列、表达式或聚集函数
列数据类型必须兼容,类型不必完全相同,但必须是DBMS可以隐含转换的类型
UNION会自动去重,如果想改变可以用 UNION ALL
插入数据
数据插入
插入完整的行
INSERT INTO Customers
VALUES ('100000009',
'Toy Land',
'123 Any Street',
'New York',
'NY',
'1111',
'USA',
'',
''
)
这种用法并不安全,高度依赖表中列的定义次序和字段
最好,指定字段插入对应的值
插入行的一部分
INSERT INTO Customers(cust_id,
cust_name)
VALUES ('100000009',
'Toy Land'
)
插入检索出的数据
INSERT INTO Customers(cust_id,
cust_name)
SELECT cust_id,
cust_name
FROM CustNew;
从一个表复制到另一个表
SELECT *
INTO CustCopy
FROM Customers;
或者这样拷贝表结构和数据
CREATE TABLE 新表
AS
SELECT * FROM 旧表
mysql 严格模式 Strict Mode说明
默认为null字段
text字段
还有其他
更新数据
UPDATE
SET 字段1 = 值,
字段2 = 值
WHERE 具体提交
#批量更新
UPDATE categories
SET display_order = CASE id
WHEN 1 THEN 3
WHEN 2 THEN 4
WHEN 3 THEN 5
END,
title = CASE id
WHEN 1 THEN 'New Title 1'
WHEN 2 THEN 'New Title 2'
WHEN 3 THEN 'New Title 3'
END
WHERE id IN (1,2,3)
记得不要省略WHERE条件,否则会更新所有行
删除数据
DELETE FROM 表名
WHERE 具体条件
一定要加WHERE条件,如果的确想删除数据可以用 TRUNCATE TABLE语句
在删除前可用SELECT WHERE 条件进行测试
表操作
创建表
CREATE TABLE Products
(
prod_id char(10) PRIMARY NOT NULL,
vend_id char(10) NOT NULL,
prod_name char(254) NOT NULL,
prod_price decimal(8,2) NOT NULL,
prod_desc varchar(1000) DEFAULT '',
);
使用NULL值, 尽量不要用NULL,更多人使用的是默认值
指定默认值
!!字段指定类型和长度,长度指的是字符个数,不是字节数,可以多留意下
更新表
增加列
ALTER TABLE tableName
ADD fields char(20);
#批量增加
ALTER TABLE tableName
ADD COLUMN char(20),
ADD COLUMN char1(20);
删除列
ALTER TABLE tableName
DROP COLUMN fieldName;
删除表
Drop TABLE tableName;
重命名表
视图
视图是虚拟的表,与包含的数据的表不一样,视图只包含使用时动态检索数据的查询。
mysql从5.0开始支持视图
好处:
重用SQL语句;
简化复杂的SQL操作;
使用表的一部分而不是整个表;
保护数据,只需授予特定部分的权限;
更改数据格式和表示,视图可返回与底层表的表示和格式不同的数据;
注意性能问题,应用前最好测试
创建视图
分区
MySQL自身提供一种分区的机制,可以按照一定的分区算法(list、Range、hash、key)将一种表里面的数据保存在不同的分区
分表
场景:数据量非常大,比如500万条数据,性能会非常低
创建多个表,最后在总表中 库信息设置为 type=merge union=(table1,table2)
集群(TODO)
主从复制
mysql中有一种日志,叫做bin日志(二进制日志),会记录下所有修改过数据库的sql语句。主从复制的原理实际是多台服务器都开启bin日志,然后主服务器会把执行过的sql语句记录到bin日志中,之后把这个bin日志发给从服务器,在从服务器再把bin日志中记录的sql语句同样的执行一遍。这样从服务器上的数据就和主服务器相同了。
存储过程
事物
原子性(Atomicity)
一致性(Consistency)
-
READ UNCOMMITTED:未提交读
READ COMMITTED:提交读/不可重复读
REPEATABLE READ:可重复读(MYSQL默认事务隔离级别)
SERIALIZEABLE:可串行化
持久性(Durability)
事务级别设置
SET GLOBAL tx_isolation='READ-COMMITTED';
游标
约束
索引
分类
建立表结构时添加的索引
主键唯一索引
唯一索引
普通索引
联合索引
- 最左匹配原则
依据是否聚簇区分
聚簇索引
非聚簇索引
索引底层数据结构
hash索引
b-tree索引
b+tree索引
聚簇索引优缺点
相关数据保持在一起,叶子节点可保存相邻的记录
因为索引和数据在一起,所以查找数据通常比非聚簇索引更快,并且显然按主键存取唯一记录或进行小范围的主键扫描最高效
聚簇索引对I/O密集型的负荷性能提升最佳
插入操作很依赖插入的顺序,按主键顺序插入是最快的
更新聚簇索引的成本比较高,因为InnoDB不得不将更新的行移动到新的位置
全盘扫描的性能不佳,尤其是数据存储得不那么紧密时,或者因为页分裂而导致屋里存储不连续
二级索引的叶节点存储了主键的索引的值,如果主键采用的是比较长的字符,那么索引可能比较大,且通过二级索引查找数据也需要进行二次索引查找
使用索引的场景和注意事项
复合索引的最左前缀原则,如
idx_a_b_c,WHERE a=?WHERE a=? AND b=? AND c=?WHERE a=? AND c=? #改查询只用到了索引a列信息索引列上的范围查找,如 WHERE …
BETWEEN..AND/>/<等范围操作符时,如果查找成本太高,可能会全盘扫描(IN 不属于范围查找)Join列,如
SELECT ... FROM a JOIN b ON ...那么数据库可能会全表扫a,并用a表每一个id去探测b表的索引查找匹配的记录where 子句
增加索引
alter table tableName add index indexName(column1,column2);
触发器
优化
配置优化
查询优化
常见策略
优化数据访问
较少对数据库的访问,如使用缓存
减少实际扫描的记录数,如只select需要字段,如在慢查询入职中看到Rows_examined比较高的值,需要添加索引或增加筛选条件,如少用或尽量不用Like之类的模糊查询特别是模糊前缀的查询
重写sql
把复杂的的查询分解为多个简单的查询
大量的数据操作分批执行
尽量避免联表,建议在程序应用层实现联结功能
重新设计库表
重写或增加索引都解决不了的问题,可能要修改表结构,比如增加缓存表暂存统计数据,或增加冗余字段以减少联结,进行反范式的设计,是解决数据库性能何可伸缩性的极佳策略
添加索引
数据备份
数据库中的数据很有可能被弄坏或者被误操作: 数据都是永久性且不可逆.
Mysql的数据备份有很多种方式: 文件备份, 单表数据备份, SQL备份,增量备份
存储引擎
mysql> SHOW ENGINES;
+------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | YES | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| MyISAM | DEFAULT | Default engine as of MySQL 3.23 with great performance | NO | NO | NO |
+------------+---------+----------------------------------------------------------------+--------------+------+------------+
用户管理
创建新用户
CREATE USER username@host IDENTIFIED BY 'password';
CREATE USER 'homestead'@'localhost' IDENTIFIED WITH mysql_native_password BY 'homestead';
删除用户
新用户创建完成,但是此刻如果以此用户登陆的话,会报错,因为我们还没有为这个用户分配相应权限,分配权限的命令如下:
GRANT ALL PRIVILEGES ON database.* TO 'username'@'localhost' IDENTIFIED BY 'password';
注意:用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
授予username用户在所有数据库上的所有权限。
如果此时发现刚刚给的权限太大了,如果我们只是想授予它在某个数据库上的权限,那么需要切换到root 用户撤销刚才的权限,重新授权:
EVOKE ALL PRIVILEGES ON *.* FROM 'username'@'localhost';GRANT ALL PRIVILEGES ON wordpress.* TO 'username'@'localhost' IDENTIFIED BY 'password';
甚至还可以指定该用户只能执行 select 和 update 命令:
GRANT SELECT, UPDATE ON wordpress.* TO 'username'@'localhost' IDENTIFIED BY 'password';
密码管理
密码修改
mysql5.7.9之后,就没有了password函数
use mysql;
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
FLUSH PRIVILEGES;
ps -ef | grep mysql - checks if mysql/mysqld is one of the running processes.
pkill mysqld - kills the daemon, if it is running.
密码重置
The server requested authentication method unknown to the client [caching_sha2_password] 错误解决
1 修改 my.cnf文件,增加 default_authentication_plugin= mysql_native_password设置
2 新增加一个用户,比如homestead , 用语句REATE USER 'homestead'@'localhost' IDENTIFIED WITH mysql_native_password BY 'homestead';
3 执行 flush privileges
4 重启mysql 服务器重新连接
安全
SQL注入
1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双”-“进行转换等。
2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
参考资料:
《SQL必知必会》
MySQL性能优化总结
MYSQL性能优化的最佳20+条经验
MySQL索引为什么要用B+树实现?
mysql索引类型 normal, unique, full text (留意下索引的存储的数据结构和多列索引的描述)
MYSQL优化之碎片整理
mysql中explain的type的解释

若有收获,就点个赞吧
0 人点赞
