Java集合必会14问
1)说说常见的集合有哪些吧?
答:Map接口和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
2)HashMap与HashTable的区别?
答:
- HashMap没有考虑同步,是线程不安全的;Hashtable使用了synchronized关键字,是线程安全的;
- HashMap允许K/V都为null;后者K/V都不允许为null;
- HashMap继承自AbstractMap类;而Hashtable继承自Dictionary类;
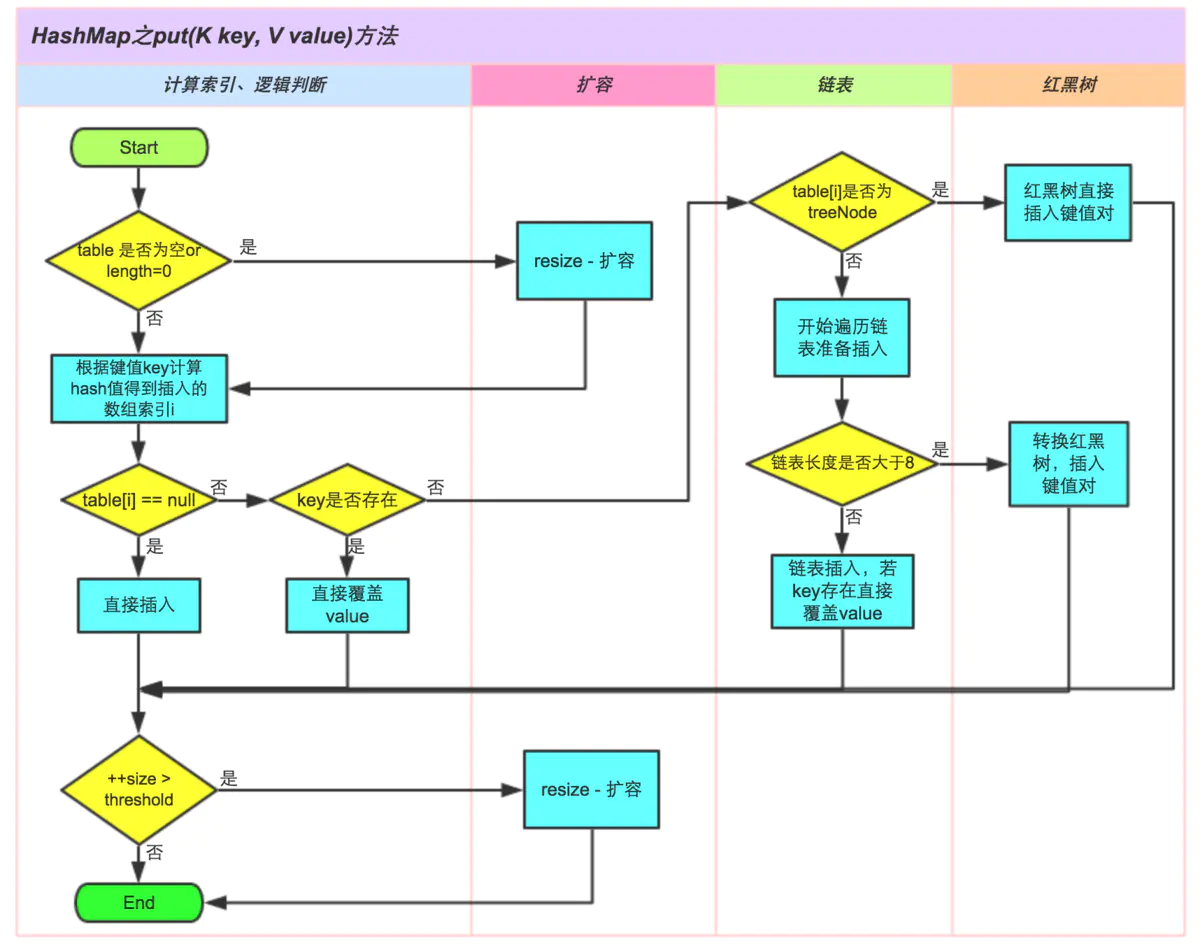
3)HashMap的put方法的具体流程?
图引用自:https://blog.csdn.net/u011240877/article/details/53358305
答:下面先来分析一下源码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;// 1.如果table为空或者长度为0,即没有元素,那么使用resize()方法扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 2.计算插入存储的数组索引i,此处计算方法同 1.7 中的indexFor()方法// 如果数组为空,即不存在Hash冲突,则直接插入数组if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 3.插入时,如果发生Hash冲突,则依次往下判断else {HashMap.Node<K,V> e; K k;// a.判断table[i]的元素的key是否与需要插入的key一样,若相同则直接用新的value覆盖掉旧的value// 判断原则equals() - 所以需要当key的对象重写该方法if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// b.继续判断:需要插入的数据结构是红黑树还是链表// 如果是红黑树,则直接在树中插入 or 更新键值对else if (p instanceof HashMap.TreeNode)e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 如果是链表,则在链表中插入 or 更新键值对else {// i .遍历table[i],判断key是否已存在:采用equals对比当前遍历结点的key与需要插入数据的key// 如果存在相同的,则直接覆盖// ii.遍历完毕后任务发现上述情况,则直接在链表尾部插入数据// 插入完成后判断链表长度是否 > 8:若是,则把链表转换成红黑树for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 对于i 情况的后续操作:发现key已存在,直接用新value覆盖旧value&返回旧valueif (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// 插入成功后,判断实际存在的键值对数量size > 最大容量// 如果大于则进行扩容if (++size > threshold)resize();// 插入成功时会调用的方法(默认实现为空)afterNodeInsertion(evict);return null;}
4)HashMap的扩容操作是怎么实现的?
答:通过分析源码我们知道了HashMap通过resize()方法进行扩容或者初始化的操作,下面是对源码进行的一些简单分析:
/*** 该函数有2中使用情况:1.初始化哈希表;2.当前数组容量过小,需要扩容*/final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;// 扩容前的数组(当前数组)int oldCap = (oldTab == null) ? 0 : oldTab.length;// 扩容前的数组容量(数组长度)int oldThr = threshold;// 扩容前数组的阈值int newCap, newThr = 0;if (oldCap > 0) {// 针对情况2:若扩容前的数组容量超过最大值,则不再扩容if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 针对情况2:若没有超过最大值,就扩容为原来的2倍(左移1位)else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}// 针对情况1:初始化哈希表(采用指定或者使用默认值的方式)else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 计算新的resize上限if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 把每一个bucket都移动到新的bucket中去for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}

若有收获,就点个赞吧
0 人点赞
