参考文章
Java线程池实现原理及其在美团业务中的实践 - 美团技术团队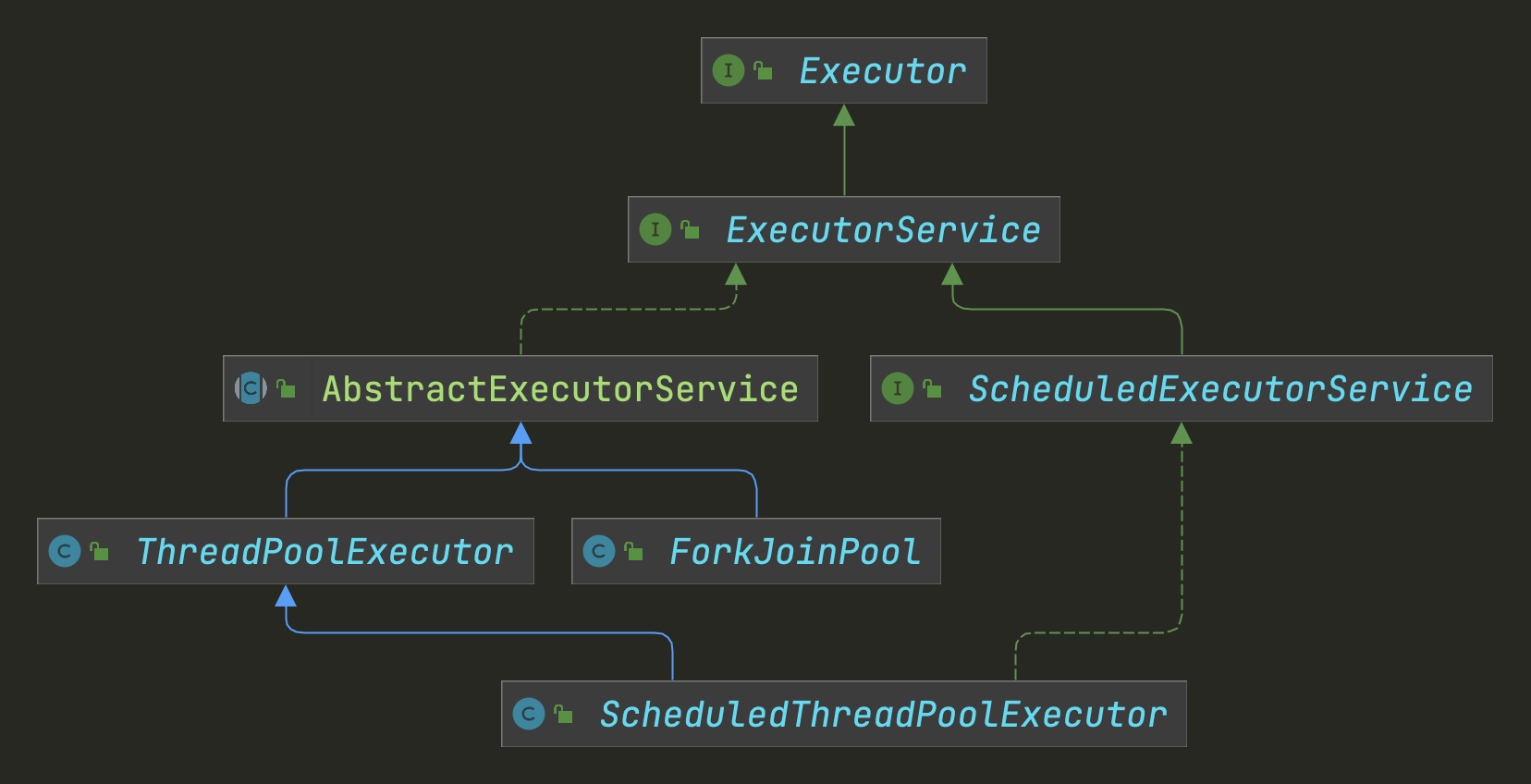
Executor接口
Executor 的设计初衷就是将
任务提交和任务执行进行解耦
public interface Executor {/*** 在将来的某个时间执行给定的命令. 命令可以在新线程、池线程或调用线程,由Executor的具体实现决定。** @command 待执行的任务* @throws RejectedExecutionException if this task cannot be accepted for execution* @throws NullPointerException if command is null*/void execute(Runnable command);}
Executor只能接受Runnable任务。
ExecutorService
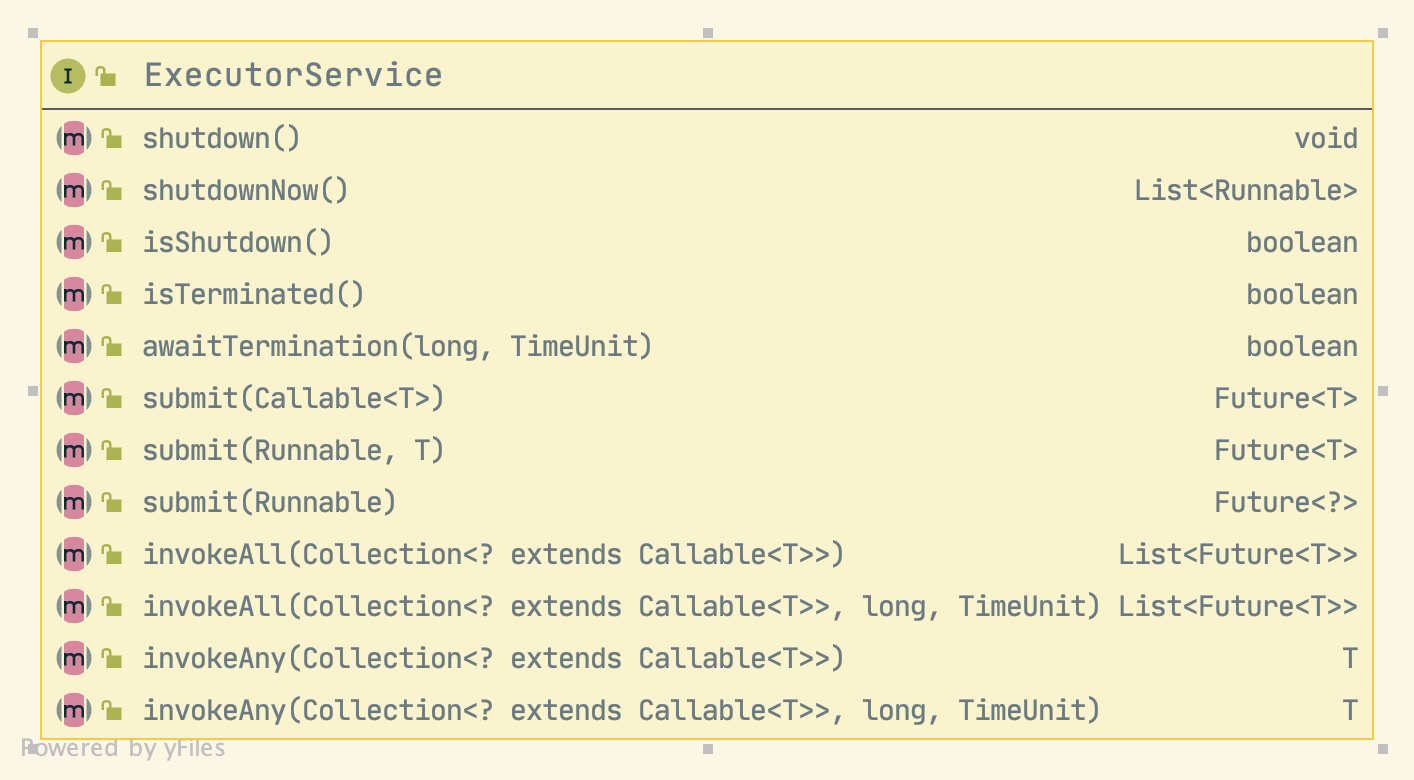
// 启动有序关机,执行以前提交的任务,但不接受新任务。如果调用已经关闭,则调用没有其他效果。void shutdown();// 尝试停止所有正在执行的任务,停止正在等待的任务的处理,并返回正在等待执行的任务的列表。List<Runnable> shutdownNow();// Executor是否已经shutdownboolean isShutdown();// 判断如果shutdown后所有任务是否都已完成boolean isTerminated();// 阻塞,直到所有任务在关闭请求后完成执行,或超时发生,或当前线程中断(以先发生的为准)。boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
�ExecutorService可以接受Callable任务。
<T> Future<T> submit(Callable<T> task);<T> Future<T> submit(Runnable task, T result);Future<?> submit(Runnable task);
ThreadPoolExecutor
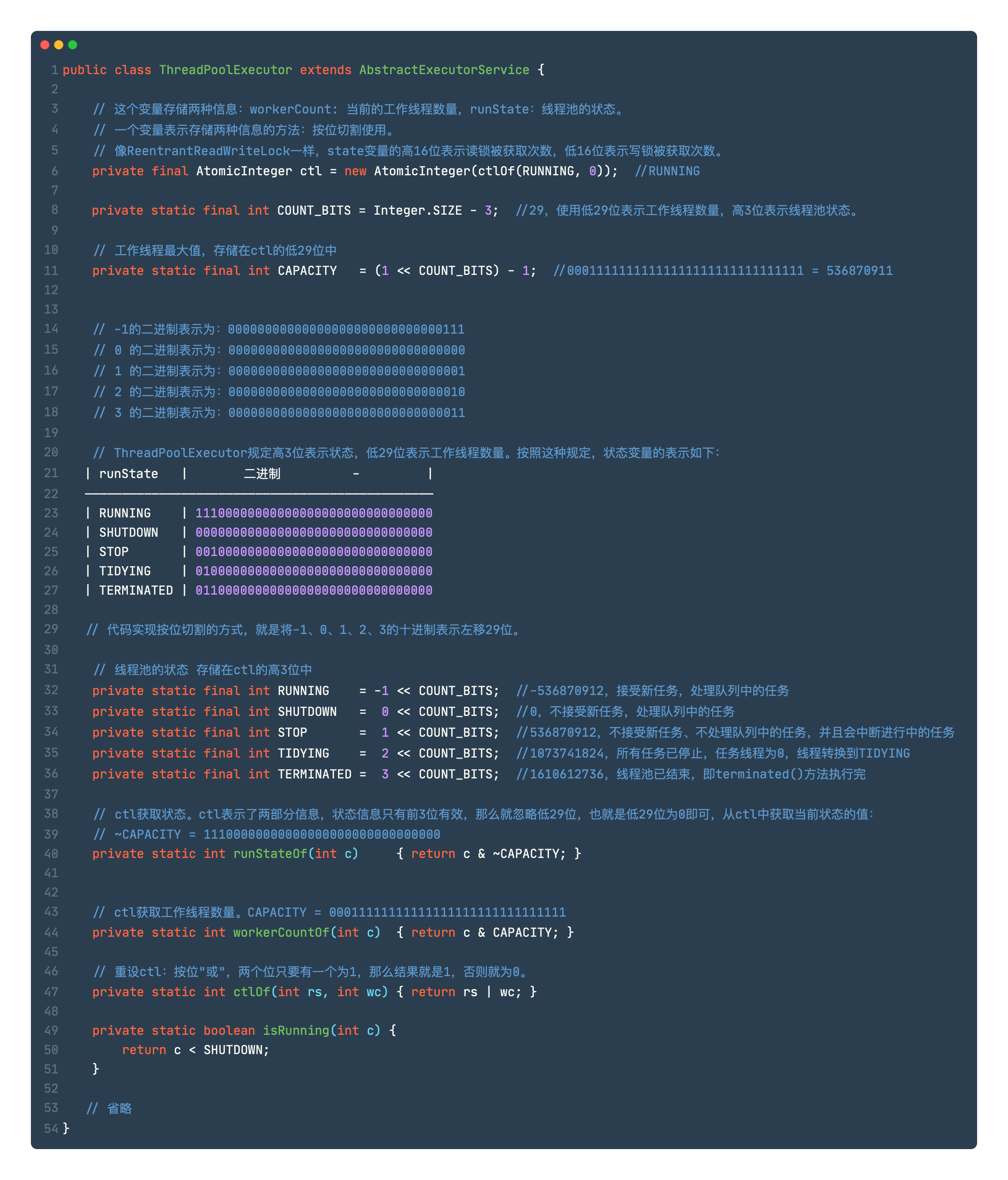
ctl & 线程池状态
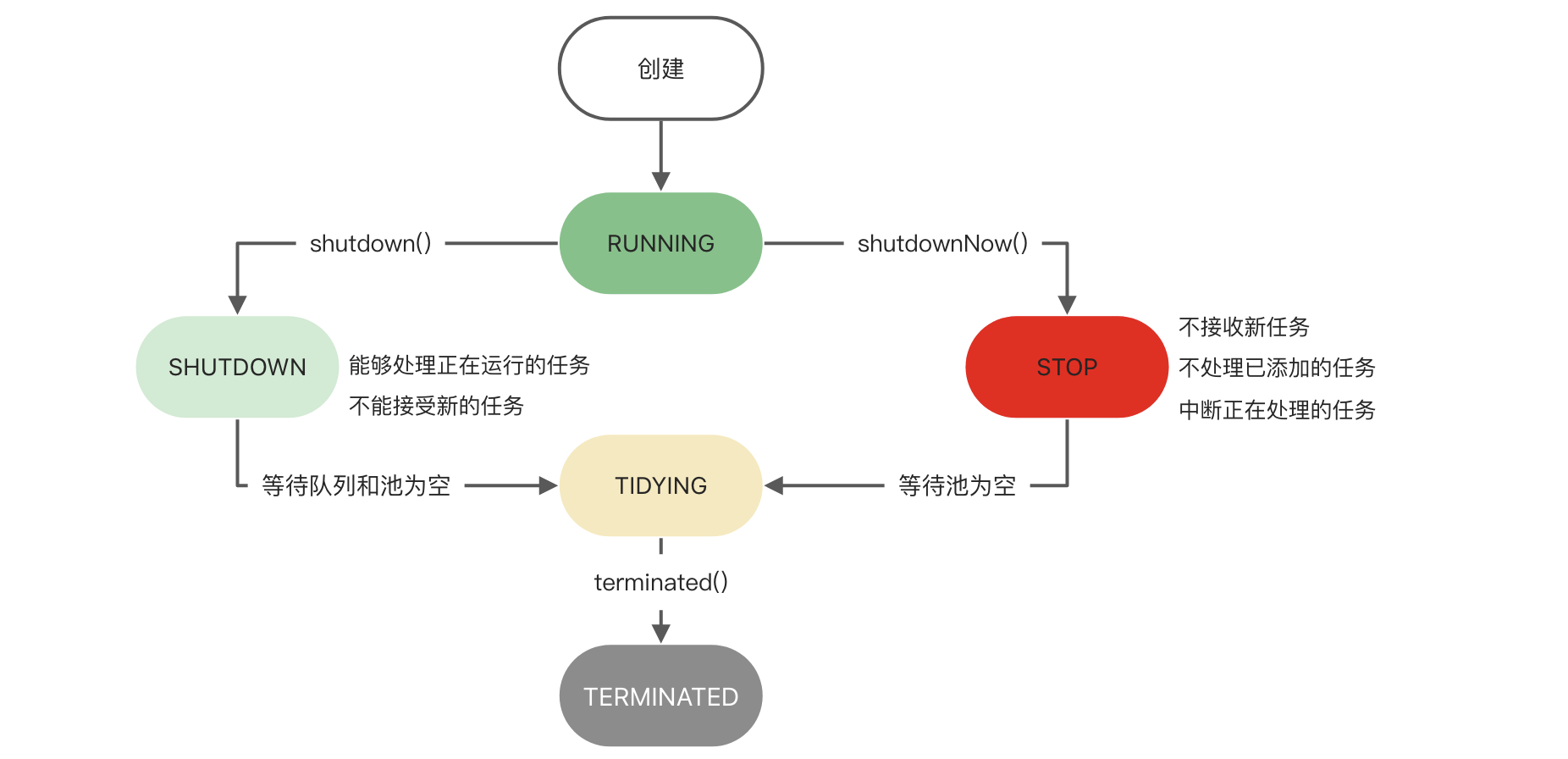
线程池生命周期流转
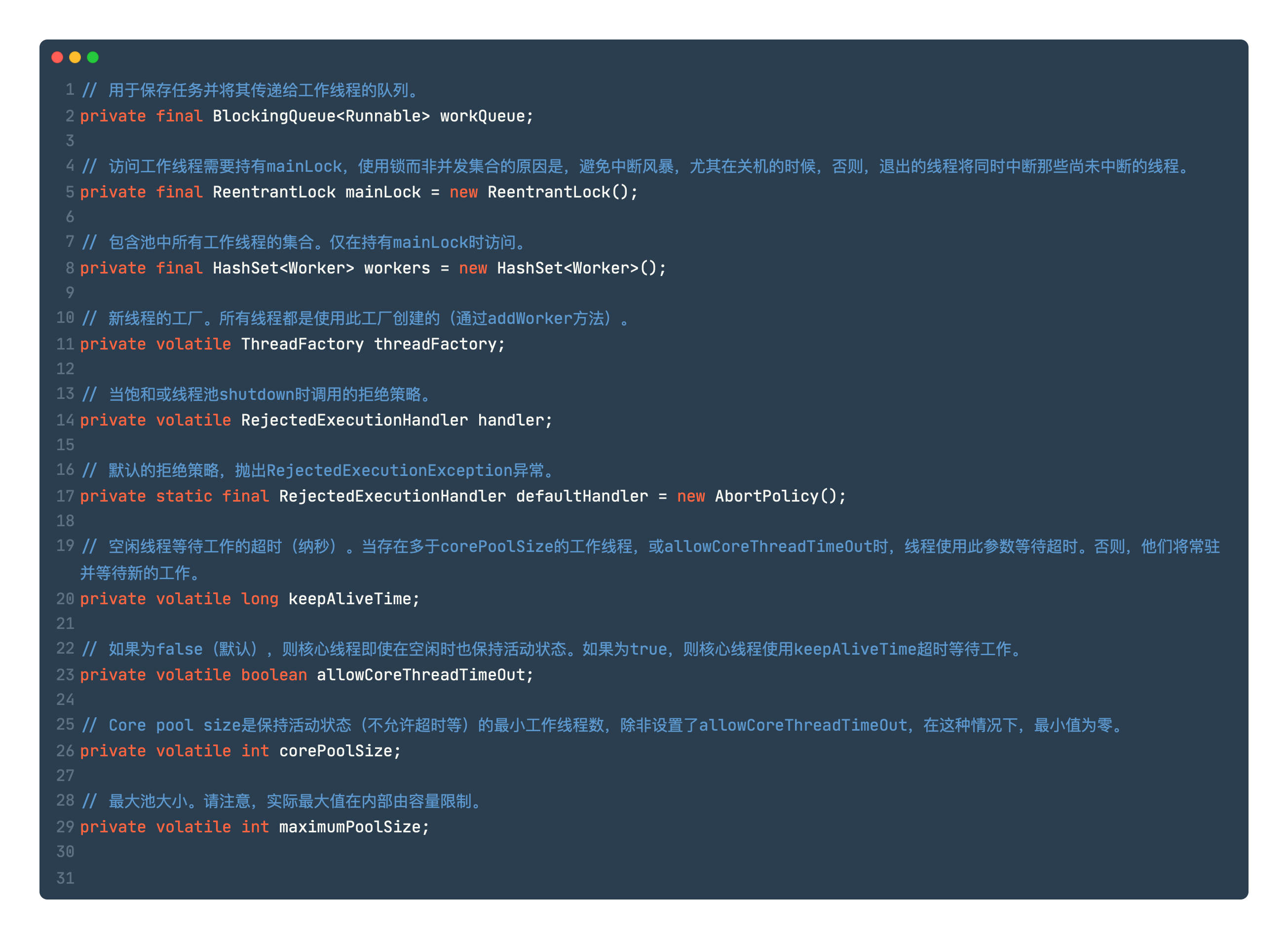
线程池的重要参数
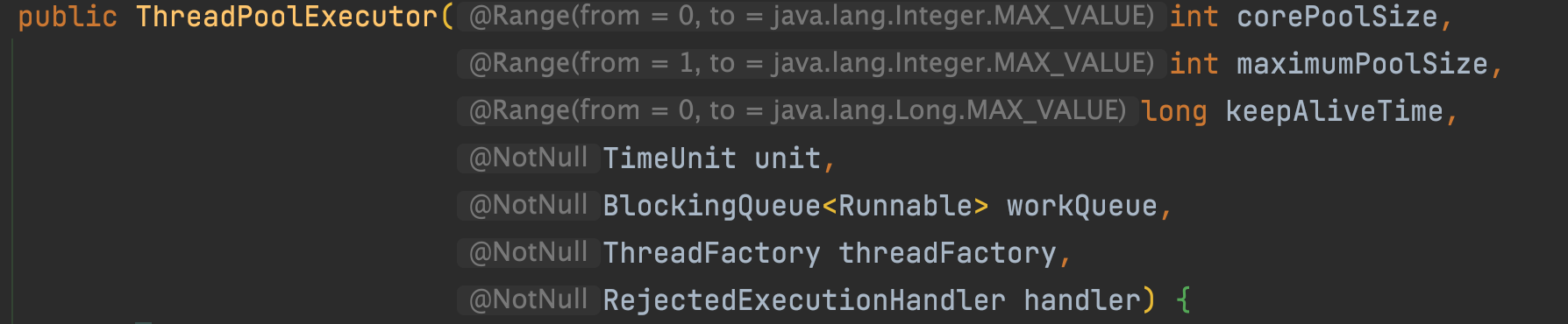
execute方法
public void execute(Runnable command) {if (command == null)throw new NullPointerException();/** Proceed in 3 steps:** 1. 如果运行的线程少于corePoolSize, 尝试启动一个新的线程,并将给定命令作为它的第一个任务。对addWorker的调用以原子方式检查运行状态和工作线程数量。* 2. 如果任务成功入队,仍需进行再次检查是否应该添加线程,因为可能2次检查之间线程可能已死亡If a task can be successfully queued, then we still need to double-check whether we should have added a thread (because existing ones died since last checking) or that the pool shut down since entry into this method.So we recheck state and if necessary roll back the enqueuing if stopped, or start a new thread if there are none.** 3. If we cannot queue task, then we try to add a new* thread. If it fails, we know we are shut down or saturated* and so reject the task.*/int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))//addWorker方法的第二个参数标识是否为核心工作线程return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) {//任务入队int recheck = ctl.get();if (!isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);} else if (!addWorker(command, false))//队列已满,增加非核心线程reject(command);}
线程池的工作流程
当一个任务(runnable)被添加时
一、判断当前线程数量是否达到核心线程最大值(corePoolSize),若当前线程数
二、判断队列是否已满,若未满,则进入队列等待,若已满,则尝试创建非核心线程。
三、线程总数最大值(maximumPoolSize)= 核心线程最大值(corePoolSize)+ 非核心线程最大值。线程池未满,则可以创建非核心线程。
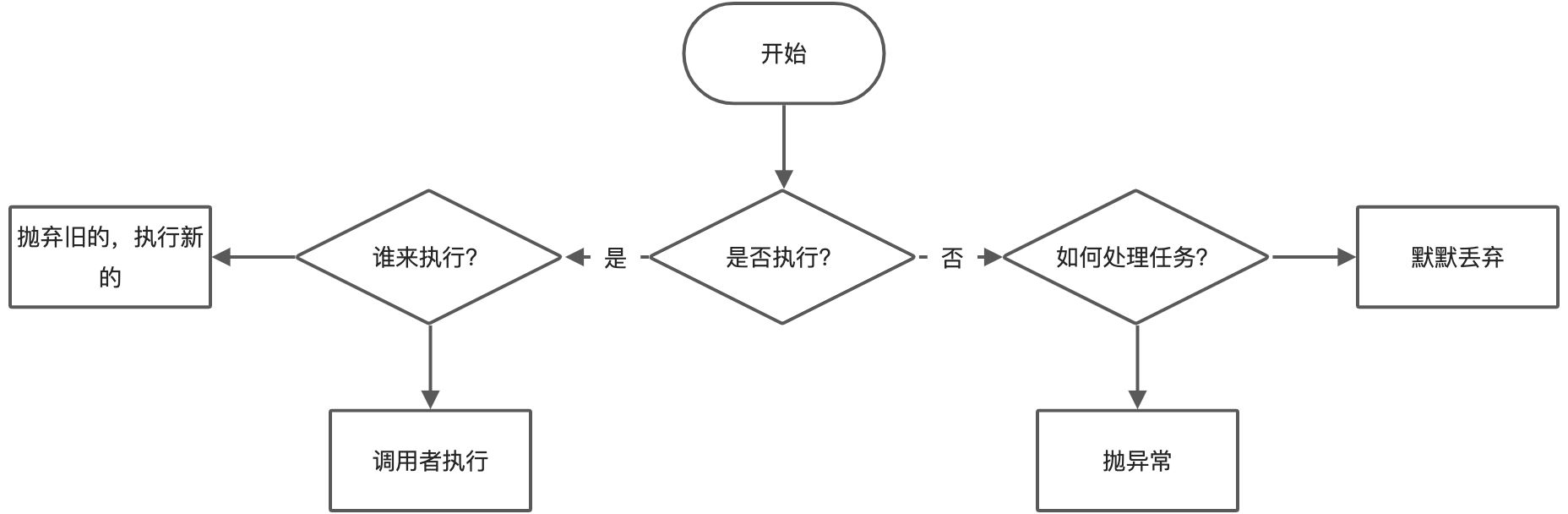
四、若线程池已满,则由处理器(handler)抛出异常。
五、几经波折任务终于进入线程池,并被完成了。经过非核心线程闲置存活时间(keepAliveTime) 后,非核心线程被销毁。计量单位(TimeUnit unit) 可以从微秒、毫秒到小时、天。
六、还有个未提到的threadFactory(线程工厂),用来创建线程。
Worker
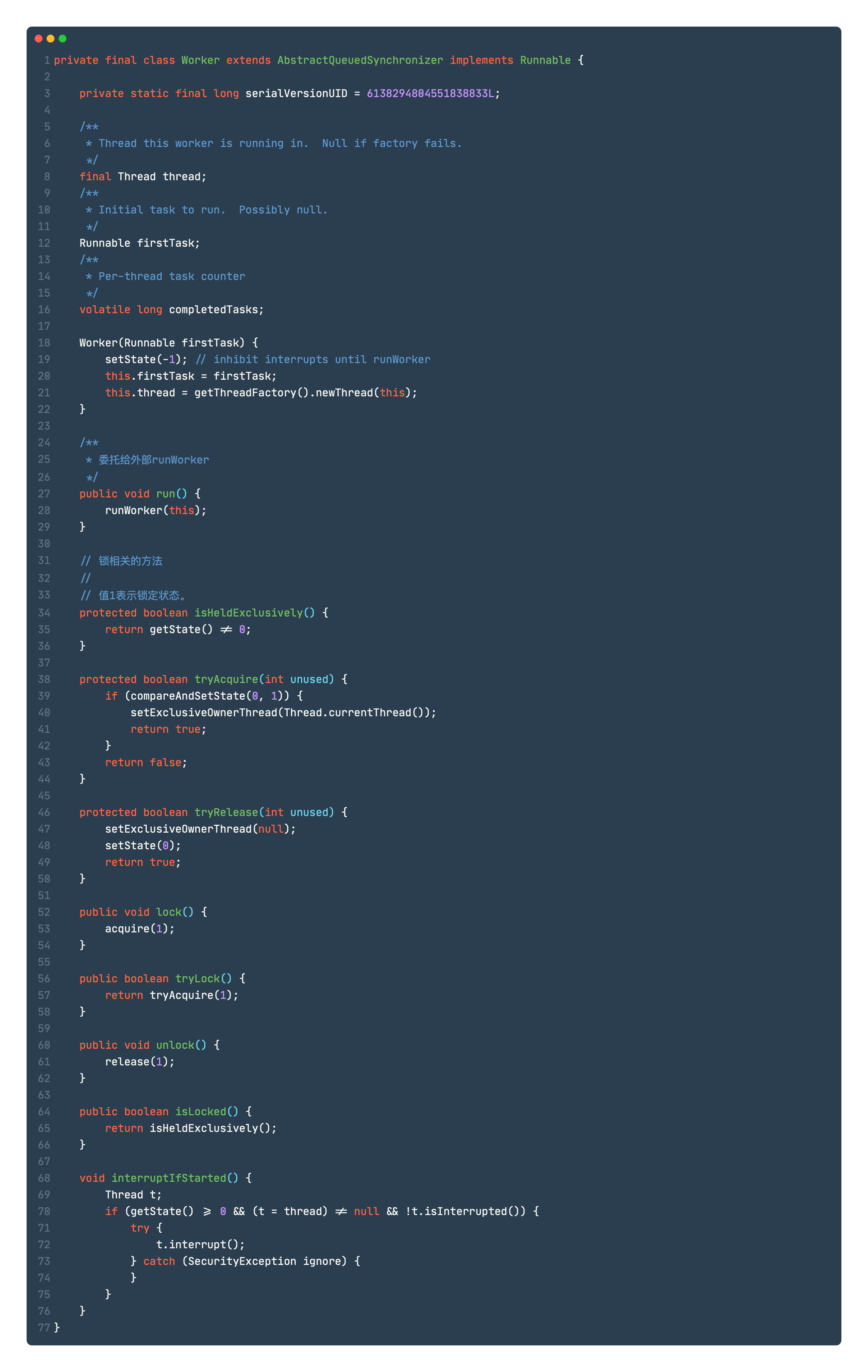
worker为什么继承AbstractQueuedSynchronizer?
�workQueue的类型选择
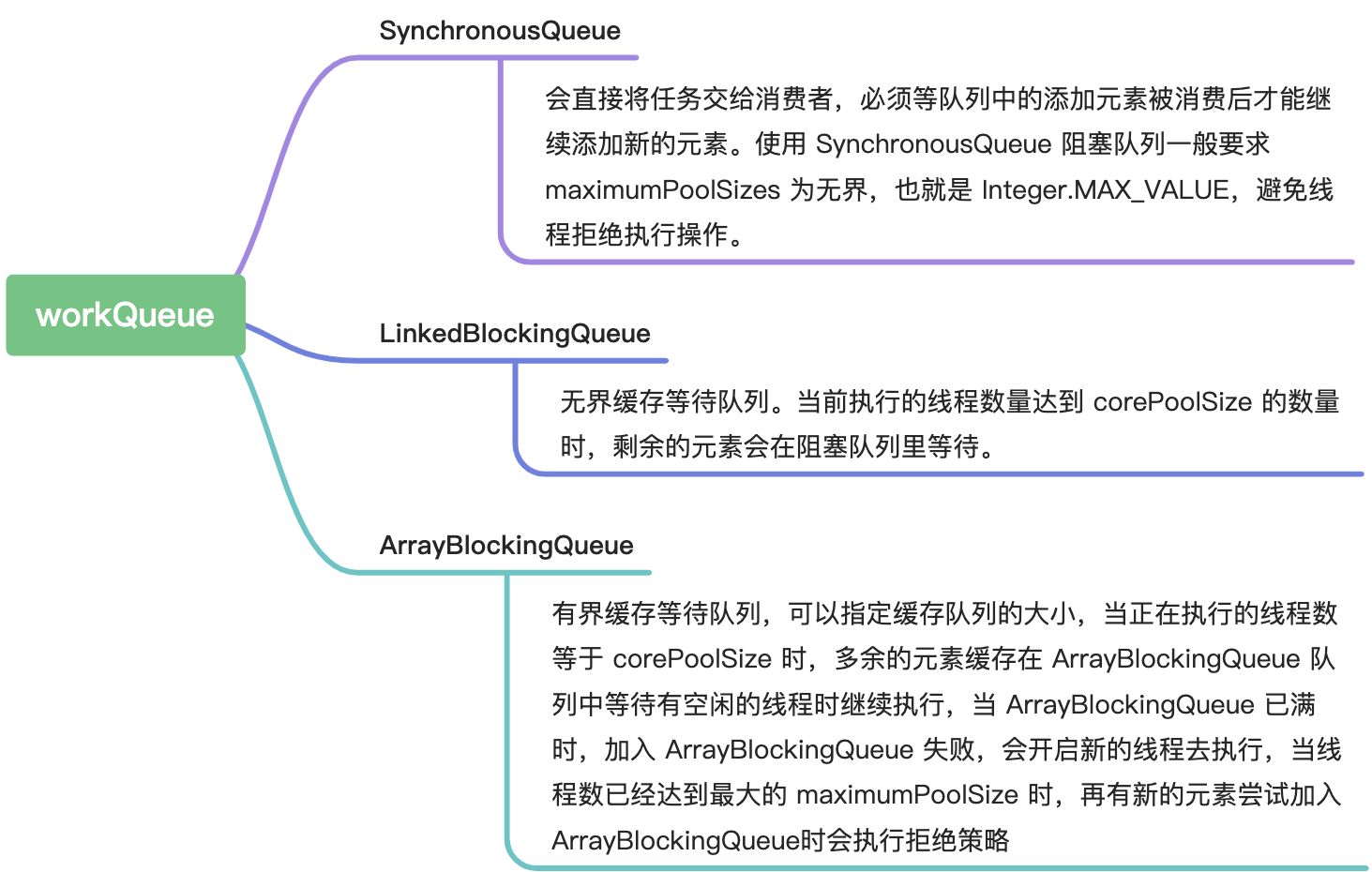
对于LBQ,容易导致OOM,这里有一个优化的队列实现,可以防止OOM:
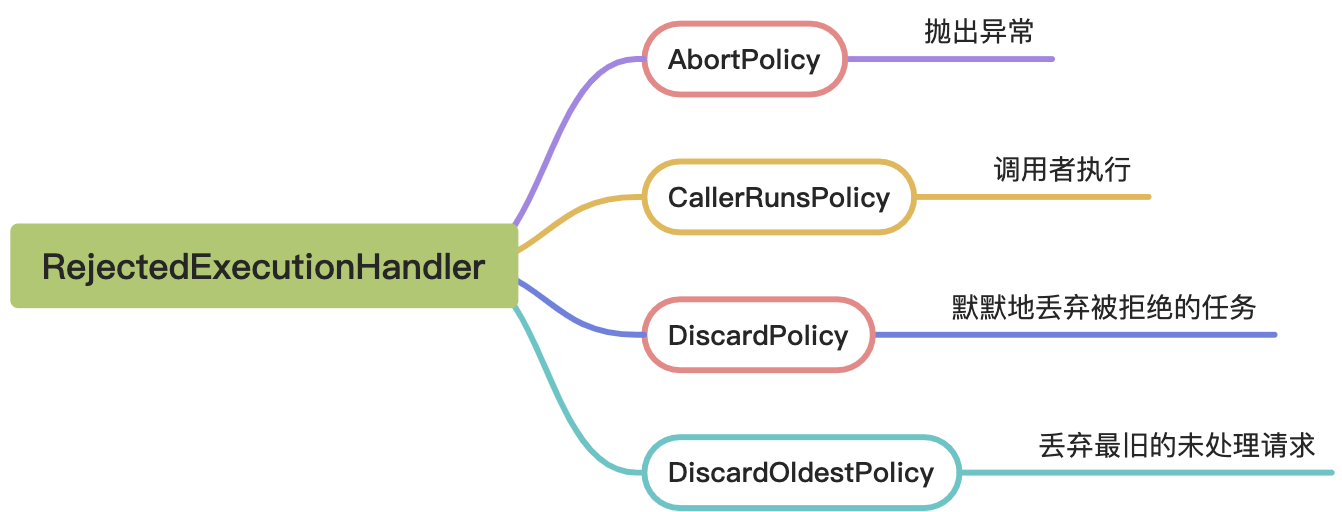
RejectedExecutionHandler
Executors
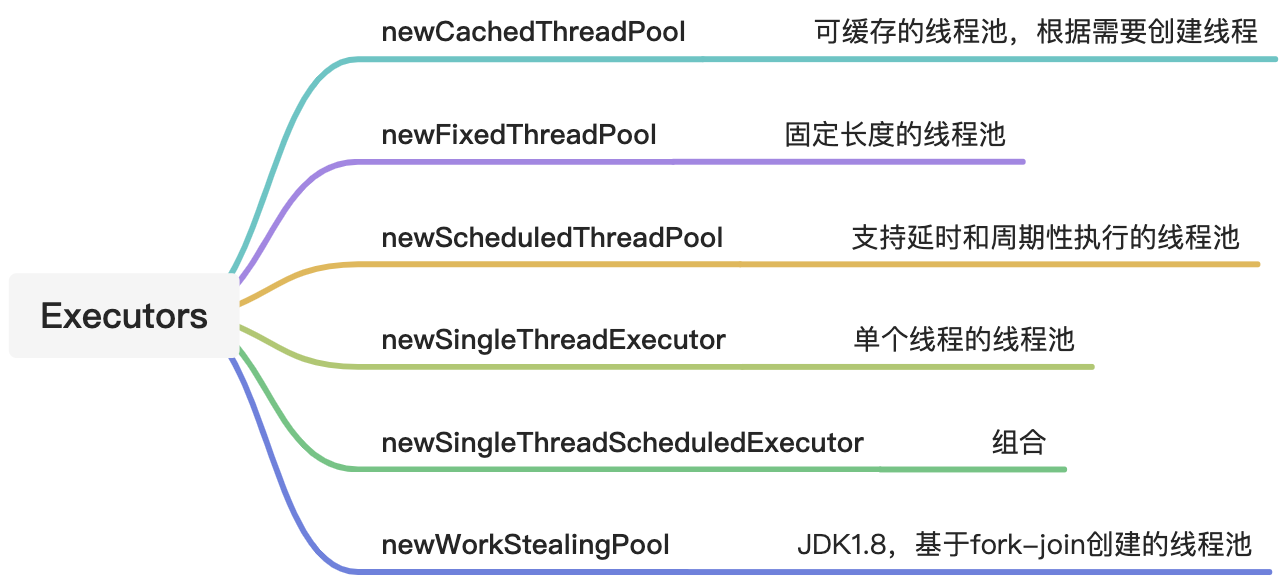
newCachedThreadPool
根据需要创建新线程的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());//SynchronousQueue不存储任务
}
CachedThreadPool 为什么要使用 SynchronousQueue 作为其队列呢?SynchronousQueue 它的特点是实际上它的内部是不存储的。那为什么还想用它呢?这是因为我们在这种线程池的情况下,根本就不需要它来存储。有任务过提交来了,直接将任务交给新的线程去执行了,新的线程的数量又是不受限制的,不需要一个队列来存储任务,有新的任务提交过来,直接让新的线程去执行新的任务任务,所以这个时候就选择了 SynchronousQueue 作为这种线程池的队列,它的效率会比较高一些,不需要在存储到队列中去中缓存。
newFixedThreadPool
固定线程数量的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());//LinkedBlockingQueue阻塞队列
}
newScheduledThreadPool
拥有固定线程数量的定时线程任务的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
ScheduleThreadPool 使用的是延迟队列,延迟队列具有的功能就是可以把队列里面的任务根据时间先后去做延迟,所以也是非常符合它的使用场景的。
newSingleThreadExecutor
一个工作线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
为什么要把 FixedThreadPool 和 SingleThreadExecutor 的队列设置为 LinkedBlockingQueue 呢?这实际上都是有原因的,这个队列的选择恰恰是满足我们线程池功能的,比如 FixedThreadPool 线程池,它固定的有 10 个线程,由于线程数量已经不能再往上膨胀了,所以不得不用一个能够存储很多的,或者是无限多的队列来去存储我们的任务。新进来的任务的数量是没办法估计,所以只能在自身上来解决问题,就把这个阻塞队列的容量设置为无限,这就是选择 LinkedBlockingQueue 的原因。
newSingleThreadScheduledExecutor
只有一个线程的定时线程任务的线程池
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
newWorkStealingPool
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),//并行度
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);//handler、asyncMode
}
关闭线程池的方式
ForkJoinPool
ForkJoinPool线程池最大的特点就是分叉(fork)合并(join),将一个大任务拆分成多个小任务,并行执行,再结合工作窃取模式(worksteal)提高整体的执行效率,充分利用CPU资源。
ForkJoinPool使用分治算法,用相对少的线程处理大量的任务,将一个大任务一拆为二,以此类推,每个子任务再拆分一半,直到达到最细颗粒度为止,即设置的阈值停止拆分,然后从最底层的任务开始计算,往上一层一层合并结果,简单的流程如下图: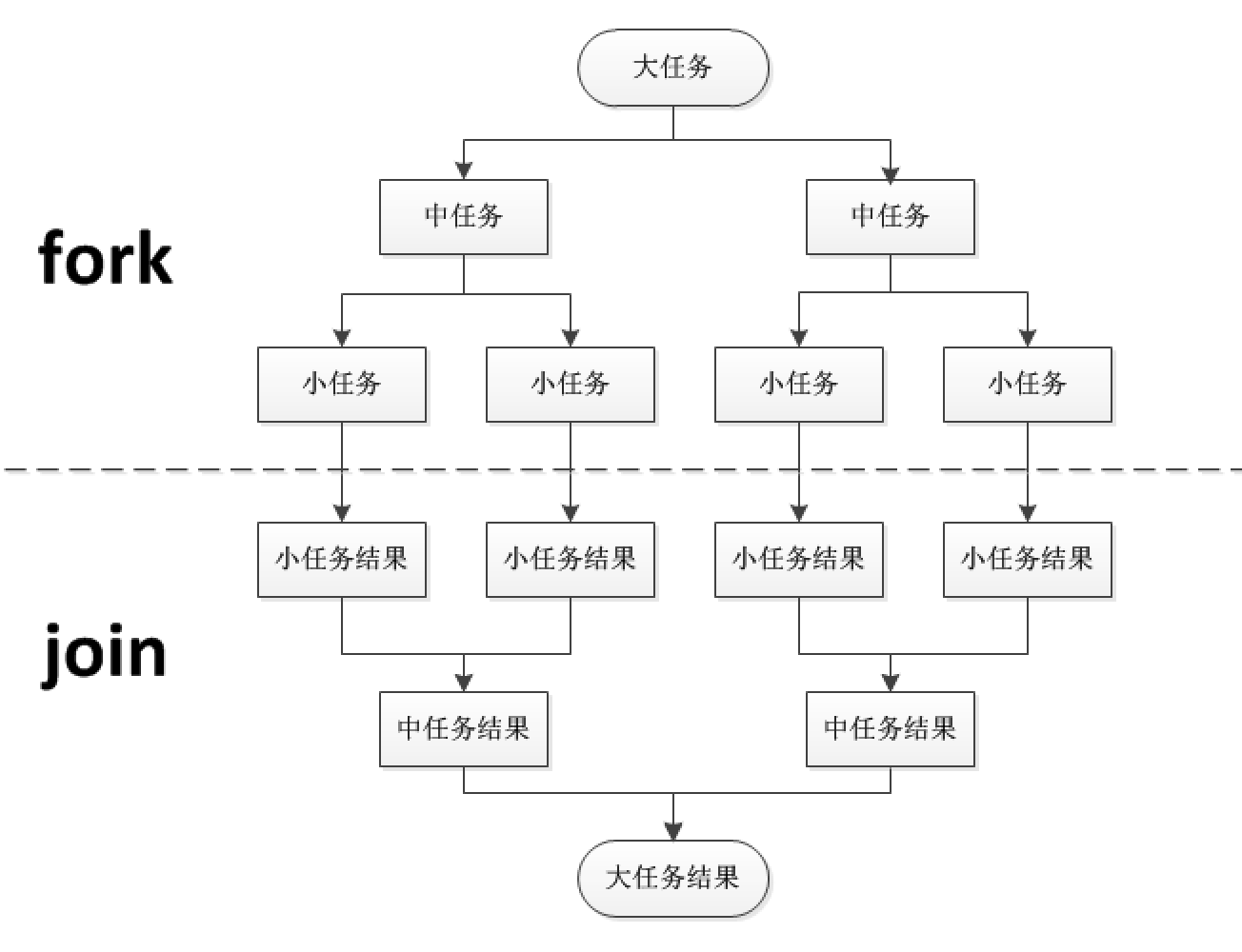
ForkJoinPool适合在有限的线程数下完成有父子关系的任务场景,比如:快速排序,二分查找,矩阵乘法,线性时间选择等场景,以及数组和集合的运算。
工作窃取的实现原理
工作窃取算法是指某个线程从其他队列里窃取任务来执行。对于一个比较大的任务,可以把它分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务需要处理,于是它就去其他线程的队列里窃取一个任务来执行。由于此时它们访问同一个队列,为了减小竞争,通常会使用双端队列。被窃取任务的线程永远从双端队列的头部获取任务,窃取任务的线程永远从双端队列的尾部获取任务。
工作窃取算法的优缺点
优点:充分利用线程进行并行计算,减少了线程间的竞争。
缺点:双端队列只存在一个任务时会导致竞争,会消耗更多的系统资源,因为需要创建多个线程和多个双端队列。
使用ForkJoinPool
创建一个 ForkJoinPool
// 并行级别表示你想要传递给 ForkJoinPool 的任务所需的线程或 CPU 数量。
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
提交任务到 ForkJoinPool
就像提交任务到 ExecutorService 那样,把任务提交到 ForkJoinPool。你可以提交两种类型的任务。一种是没有任何返回值的(一个 “行动”),另一种是有返回值的(一个”任务”)。这两种类型分别由 RecursiveAction 和 RecursiveTask 表示。
RecursiveAction示例
RecursiveAction 是一种没有任何返回值的任务。它只是做一些工作,比如写数据到磁盘,然后就退出了。
一个 RecursiveAction 可以把自己的工作分割成更小的几块,这样它们可以由独立的线程或者 CPU 执行。
MyRecursiveAction 将一个虚构的 workLoad 作为参数传给自己的构造子。如果 workLoad 高于一个特定阀值,该工作将被分割为几个子工作,子工作继续分割。如果 workLoad 低于特定阀值,该工作将由 MyRecursiveAction 自己执行。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveAction;
public class MyRecursiveAction extends RecursiveAction {
private long workLoad = 0;
public MyRecursiveAction(long workLoad) {
this.workLoad = workLoad;
}
@Override
protected void compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
List<MyRecursiveAction> subtasks = new ArrayList<MyRecursiveAction>();
subtasks.addAll(createSubtasks());
for(RecursiveAction subtask : subtasks){
subtask.fork();
}
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
}
}
private List<MyRecursiveAction> createSubtasks() {
List<MyRecursiveAction> subtasks = new ArrayList<MyRecursiveAction>();
MyRecursiveAction subtask1 = new MyRecursiveAction(this.workLoad / 2);
MyRecursiveAction subtask2 = new MyRecursiveAction(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
}
RecursiveTask示例
RecursiveTask 是一种会返回结果的任务。它可以将自己的工作分割为若干更小任务,并将这些子任务的执行结果合并到一个集体结果。可以有几个水平的分割和合并。以下是一个 RecursiveTask 示例:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveTask;
public class MyRecursiveTask extends RecursiveTask<Long> {
private long workLoad = 0;
public MyRecursiveTask(long workLoad) {
this.workLoad = workLoad;
}
protected Long compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
List<MyRecursiveTask> subtasks = new ArrayList<MyRecursiveTask>();
subtasks.addAll(createSubtasks());
for(MyRecursiveTask subtask : subtasks){
subtask.fork();
}
long result = 0;
for(MyRecursiveTask subtask : subtasks) {
result += subtask.join();
}
return result;
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
return workLoad * 3;
}
}
private List<MyRecursiveTask> createSubtasks() {
List<MyRecursiveTask> subtasks = new ArrayList<MyRecursiveTask>();
MyRecursiveTask subtask1 = new MyRecursiveTask(this.workLoad / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
}
MyRecursiveTask 类继承自 RecursiveTask,这也就意味着它将返回一个 Long 类型的结果。
MyRecursiveTask 示例也会将工作分割为子任务,并通过 fork() 方法对这些子任务计划执行。
此外,本示例还通过调用每个子任务的 join() 方法收集它们返回的结果。子任务的结果随后被合并到一个更大的结果,并最终将其返回。对于不同级别的递归,这种子任务的结果合并可能会发生递归。
问题
- 线程池创建出来后,工作线程是空的吗?
- —是,但是可以调用prestartAllCoreThreads或者prestartCoreThread方法,提前创建工作线程。
- 核心线程会被剔除吗?
- —会。调用allowCoreThreadTimeOut(boolean value)方法设置允许核心线程过期清除。
- 工作线程数量如何设置合理?
合理的线程数量=CPU数量*CPU使用率*(1+等待时间/计算时间)- 如果是计算密集型,线程绝大部分消耗都在CPU计算处理上,那启动再多的线程也无济于事,所以
线程数量=cpu个数比较合适。 - 如果是IO密集型,线程很大部分消耗在等待上,所以可以启动更多的线程,但是线程数量不能超过线程池的上限,也就是上面我们已经阐述过的计算方式。
- 任务队列如何设置合理?

若有收获,就点个赞吧
0 人点赞
