JMM
JMM是Java的内存模型,是为了屏蔽不同计算机底层的区别而设计的一种内存模型。
对于计算机存储来说,CPU速度远远高于内存,进而发展出了高速缓存。多核系统中,每个核都有自己的高速缓存,这些高速缓存共用一个主内存。高速缓存的引入同时带来了新的缓存一致性问题。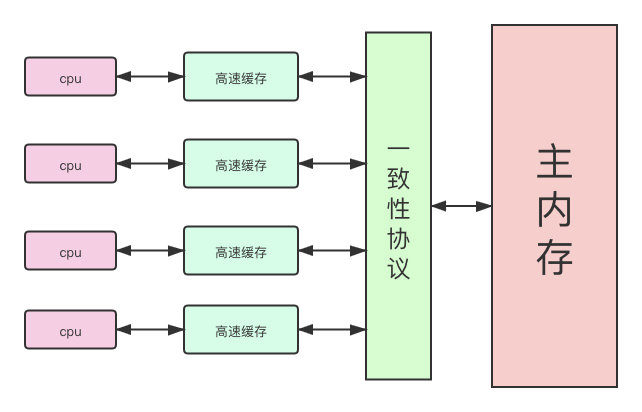
JMM描述了Java程序中各种变量的访问规则、在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
JMM的规定:
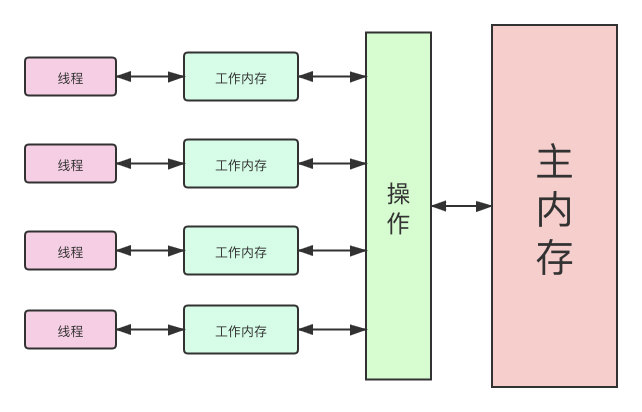
- 所有的共享变量都存储于主内存。(这里所说的是实例变量和类变量,不包含局部变量,因为局部变量是线程私有的,不存在竞争问题)
- 每个线程有工作内存,保留了被线程使用的变量的工作副本。
- 不同线程不能访问别的工作内存的变量,线程间的变量的值的传递需要通过主内存来完成。
可见性解决方案
方案1:加锁
一个线程进入synchronized代码块,线程会获得锁,清空工作内存,从主内存拷贝共享变量的最新值到工作内存,执行代码,将修改后的变量副本的值,刷新回主内存中,线程释放锁。获取不到锁的线程会阻塞等待,所以变量的值一直都是最新的。
方案2:用volatile修饰共享变量
volatile保证不同线程对共享变量操作的可见性。一个线程修改了volatile修饰的变量,当修改写回主内存时,其他线程立即看到最新的值。
volatile如何保证可见性的呢?底层原理是什么?
为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI、MOSI、Synapse、Firefly、DragonProtocol等。
MESI(缓存一致性协议)
当CPU写数据时,如果发现操作的是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,引起当其他CPU需要读取这个变量时,发现自己缓存的该变量的缓存行是无效的,那么就会从内存中重新读取。
嗅探
CPU如何发现缓存数据是否失效呢?答案是嗅探。
每个CPU通过嗅探在总线上传播的数据,来检查自己缓存的值是否过期。当发现缓存被修改,将会把自己的缓存行置为无效,当处理器自己需要修改这个数据,会重新从系统内存中读取到处理器缓存中。
总线风暴
嗅探的缺点是总线风暴。
由于volatile的MESI缓存⼀致性协议,需要不断的从主内存嗅探和cas不断循环,⽆效交互会导致总线带宽达到峰值。
所以不要⼤量使⽤Volatile,⾄于什么时候去使⽤Volatile什么时候使⽤锁,根据场景区分。
禁止指令重排
为了提高性能,编译期和处理器会对既定的代码执行顺序进行指令重排序。
重排序的类型一般有:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执⾏顺序;
- 指令级并⾏的重排序。现代处理器采⽤了指令级并⾏技术来将多条指令重叠执⾏。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执⾏顺序;
- 内存系统的重排序。由于处理器使⽤缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执⾏的。
as-if-serial
无论怎么重排序,单线程下的执行结果不能被改变,编译期、runtime和处理器都必须遵守as-if-serial语义。
volatile如何禁止重排序的呢?
内存屏障
Java编译期会在生成指令时,在适当的位置插入内存屏障指令来禁止特定类型的处理器重排序。
volatile写是在前⾯和后⾯分别插⼊内存屏障,⽽volatile读操作是在后⾯插⼊两个内存屏障。
 |
 |
|---|---|
happens-before
内存屏障指令比较难记,从JDK5开始,提出了happens-before的概念,通过这个概念来阐述操作之间的内存可⻅性。
如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
volatile域规则:对⼀个volatile域的写操作,happens-before于任意线程后续对这个volatile域的读。
无法保证原子性
原子性是指:一个操作,要么完全成功,要么完全失败。
假设现在有N个线程对同⼀个变量进⾏累加也是没办法保证结果是对的,因为读写这个过程并不是原⼦性的。
要解决也简单,要么⽤原⼦类,⽐如AtomicInteger,要么加锁(记得关注Atomic的底层)。
应用场景
单例模式
class Singleton {// 可见性和指令重排序都保证private volatile static Singleton instance = null;// 私有构造方法private Singleton(){}public static Singleton getInstance() {// 第一重检查锁if(instance == null){// 同步锁定代码块synchronized (Singleton.class){// 第二重检查锁if(instance == null){//注意:非原子操作instance = new Singleton();}}}return instance;}}
为什么需要双检锁?
对象的创建实际上有3个步骤:
- 分配内存空间
- 调用构造器,初始化实例
- 返回地址给引用
这3步可能发⽣指令重排序的,那有可能构造函数在对象初始化完成前就赋值完成了,在内存⾥⾯开辟了⼀⽚存储区域后直接返回内存的引⽤,这个时候还没真正的初始化完对象。但是别的线程判断instance!=null,直接拿去⽤了,其实这个对象是个半成品,那就有空指针异常了。
volatile与synchronized的区别
volatile只能修饰实例变量和类变量,⽽synchronized可以修饰⽅法,以及代码块。
volatile保证数据的可⻅性,但是不保证原⼦性(多线程进⾏写操作,不保证线程安全);synchronized是⼀种排他(互斥)的机制。volatile⽤于禁⽌指令重排序:可以解决单例双重检查对象初始化代码执⾏乱序问题。
volatile可以看做是轻量版的synchronized,volatile不保证原⼦性,但是如果是对⼀个共享变量进⾏多个线程的赋值,⽽没有其他的操作,那么就可以⽤volatile来代替synchronized,因为赋值本身是有原⼦性的,⽽volatile⼜保证了可⻅性,所以就可以保证线程安全了。
总结
- volatile适⽤于以下场景:某个属性被多个线程共享,其中有⼀个线程修改了此属性,其他线程可以⽴即得到修改后的值,⽐如boolean flag;或者作为触发器,实现轻量级同步。
- volatile属性的读写操作都是⽆锁的,它不能替代synchronized,因为它没有提供原⼦性和互斥性。因为⽆锁,不需要花费时间在获取锁和释放锁上,所以说它是低成本的。
- volatile提供了可⻅性,任何⼀个线程对其的修改将⽴⻢对其他线程可⻅,volatile属性不会被线程缓存,始终从主存中读取。
- volatile只能作⽤于属性,⽤volatile修饰属性,编译器就不会对这个属性做指令重排序。
- volatile提供了happens-before保证,对
volatile变量v的写操作happens-before所有其他线程后续对v的读操作。 - volatile可以使得long和double的赋值是原⼦的。
- volatile可以在单例双重检查中实现可⻅性和禁⽌指令重排序,从⽽保证安全性。

若有收获,就点个赞吧
0 人点赞
