汉字存储占用空间大小与编码方式的关系
在讨论数组存储汉字之前,首先要明确一个基本概念:汉字存储占用空间大小与使用何种编码方式有关。
我们常用的中文编码有 GB2312、GBK、GB18030,GB 全称 GuoBiao 国标,GBK 全称 GuoBiaoKuozhan 国标扩展。GB18030 编码兼容 GBK,GBK 兼容 GB2312。
几种常见中文编码之间兼容性如下图: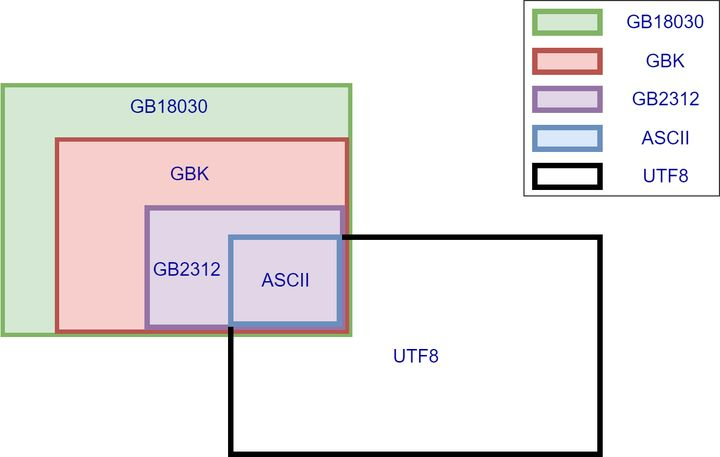
常见的中文编码 GB2312(国标简体中文字符集)和 GBK(国标扩展)使用 2 个字节编码来表示一个汉字。GB18030 编码中多出来的部分使用 4bytes 编码,相同的部分依然还是使用 2 个字节编码。GBK 和 GB2312 比 ASCII 多出来的字都是 2bytes,GB18030比GBK多出来的字都是4bytes。
而更通用的 UTF-8 编码使用 3 个字节编码来表示一个汉字。
UTF-8 编码汉字的小瑕疵
对于中文汉字来说,所有常用汉字的 Unicode 值都可以用 3 字节的 UTF8 表示出来,而 GBK 编码的汉字基本是 2 字节(GB18030 虽 4 字节但是日常没人会写那些字)。这也就导致了,如果把 GBK 编码的中文文本另存为 UTF8 编码,体积会大 50% 左右。这也是 UTF8 的一点小瑕疵,存储同样的汉字,体积比 GBK 要大 50%。
不过在「可表示世界上所有文字」这一巨大优势面前,UTF8 的这点小瑕疵可以忽略了,所以日常开发中最常使用 UTF-8 编码。
切换编码方式时编程应注意的事项
当我们从 GB2312、GBK、GB18030 编码切换到 UTF-8 编码时,单个汉字所占用的存储空间会发生变化,这时就容易发生数组长度不够的问题。
//使用 GB2312、GBK、GB18030 编码时,每个汉字占两个字节。//此时「汉字」两个汉字将占四个字节,还有一个字节的'\0',数组长度刚刚好。char a[5] = "汉字";//能够成功初始化数组。//但如果切换到 UTF-8 编码,每个汉字将占三个字节。//此时光「汉字」两个汉字就将占用六个字节,那么原来 5 的数组长度显然就不够用了。char a[5] = "汉字";//初始化数组失败,会报错://error: #144: a value of type "char [7]" cannot be used to initialize an entity of type "const char [5]"
参考链接

若有收获,就点个赞吧
0 人点赞
