内容简介
一。工具命令概述
二。工具详细介绍
1) masterha_check_ssh
2) masterha_check_repl
3) masterha_check_status
4)masterha_master_switch
三。参考文档
https://www.jianshu.com/p/6173dae5ed7a
一。工具命令概述
masterha_check_ssh : 检查MHA的SSH配置。
masterha_check_repl : 检查MySQL复制。
masterha_manager : 启动MHA。
masterha_check_status : 检测当前MHA运行状态。
masterha_master_monitor : 监测master是否宕机。
masterha_master_switch : 控制故障转移(自动或手动)。
masterha_conf_host : 添加或删除配置的server信息
save_binary_logs : 保存和复制master的二进制日志。
apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。
filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。
二.工具详细介绍
masterha_check_ssh :
命令: master_chek_ssh —global_conf= —conf=
检查MHA的SSH配置。(参考3运行前测试命令-debug)
masterha_check_repl :
命令: master_chek_ssh —global_conf= —conf=
检查MySQL复制(参考:3运行前测试命令-debug)
masterha_master_switch
在线切换命令:
在线切换(Mha manager进程(binlog server进程可选)是关闭的,Mha结构是正常的环境,适用于生产系统硬件、软件升级维护等场景)
[root@mysql-zst3 app1]# masterha_master_switch —master_state=alive
—conf=/etc/masterha/app1.conf —orig_master_is_new_slave
将master从host1切换到host2,切换完成,host1不再参与新环境的复制
masterha_master_switch —conf=/etc/app1.cnf —master_state=alive —new_master_host=host2 —running_updates_limit=5
参数:
—orig_master_is_new_slave:指将现master进行change master to 操作到新master。不加则不进行操作
—running_updates_limit=10000
切换时选master 如果有延迟的话,mha切换不会成功,加上此参数表示切换在此时间范围内都可以切换(单位为 s),但是切换的时间长短是由recover时relay日志大小决定
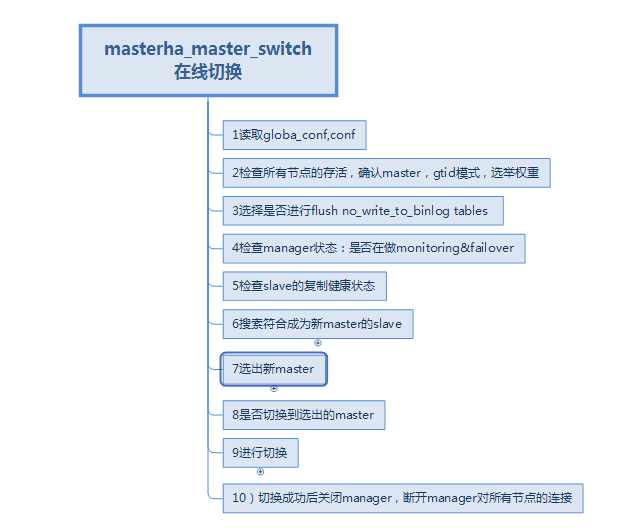
切换流程
masterha_master_switch在线切换
1.找global_conf 并读取。找到conf并读取
2.检测所有节点存活状态,确认复制模式(GTID),并确定主从关系,确定slave选举权重
3.提醒是否在master 上执行flush no_write_to_binlog tables(目的是为了后面操作不写道binlog中影响复制恢复等) ,确定后执行
4.检测MHA 没有做别的事情(monitoring or failover)
5.检测所有slave的复制健康状态
6.搜索符合条件成为新master的slave:log版本,log-bin=enable,Relay log info repository,master是谁,选举权重;
还有不参与选举master的slave:no_master=1
7.选举新master:
Searching from candidate_master slaves which have received the latest relay log events..
8.提醒是否切换
9 进行切换
切换步骤
1)检测原master 是否不是其他MySQL的slave,并临时change master to虚拟主机上。
2)对slave执行,将所有slave change master to 到一个虚拟主机上
3)检查旧master配置(应同第2步检测内容一致),并断开连接
4)A)在manager上执行 online change script —command=stop 将新旧master 的read_only都设置为1.拒绝所有update的操作.

这个脚本做的事情是:新master上设置read_only=1,
删除vip
在原master设置read_only=1
kill 所有应用thread(连接)
锁住所有表禁止所有的用户的写入(包括root)。flush table with read lock
show master status 查看原master 的log_file:pos: mysql-bin.000008:154
获取新master状态,并尝试将原master的通过realylog文件将log_file:pos在新master上进行应用,完成后stop thread。完成同步数据
获取新master当前的NMlog=log_file:pos。并生成change master to 语句,复制起点位NMlog
B)再次执行online change script --command=start。指定新master。恢复写权限
这个脚本做的事情是:在新master read_only=0
在新master 增加VIP
(并行更该现在slave 到新master,注意不能开启删除relay_log规则)
在其他所有slave上使用relay log进行恢复(从新master上获取)
停止sql thread
重置其他slave的复制信息,并执行在上一步执行online change script 生成的change master to 语句到新master上
对原master进行解锁表(unlock tables)
将原master change 到新master上
11.切换完成后断开所有节点的连接(manager 会关闭)
切换流程图

purge_relay_logs
MHA 在发生切换的过程中,从库的恢复过程中依赖于 relay log 的相关信息,所以这里要将 relay log 的自动清除设置为 OFF,采用手动清除 relay log 的方式。在默认情况下,从服务器上的中继日志会在 SQL 线程执行完毕后被自动删除。但是在 MHA 环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在 ext3 的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在 linux 系统中通过硬链接删除大文件速度会很快。(在 mysql 数据库中,删除大表时,通常也采用建立硬链接的方式)
参数介绍
--user mysql //用户名
--password mysql //密码
--port //端口号
--workdir //指定创建 relay log 的硬链接的位置,默认是/var/tmp,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除
--disable_relay_log_purge //默认情况下,如果 relay_log_purge=1,脚本会什么都不清理,自动退出,通过设定这个参数,当 relay_log_purge=1 的情况下会将 relay_log_purge 设置为 0。清理 relay log 之后,最后将参数设置为 OFF。
使用实例
设置定时任务处理relay_log
执行脚本
cat purge_relay_log.sh
#!/bin/bash ·1
user=root
passwd=unixfbi
port=3306
log_dir='/data/masterha/log'
work_dir='/data'
purge='/usr/local/bin/purge_relay_logs'
if [ ! -d $log_dir ]
then
mkdir $log_dir -p
fi
$purge --user=$user --password=$passwd --disable_relay_log_purge --port=$port --workdir=$work_dir >> $log_dir/purge_relay_logs.log 2>&1
设置定时任务.
crontab -l
0 4 * /bin/bash /root/purge_relay_log.sh

若有收获,就点个赞吧
0 人点赞
