MHA(Master High Availability)
(参考来源:http://www.unixfbi.com/278.html
https://github.com/yoshinorim/)
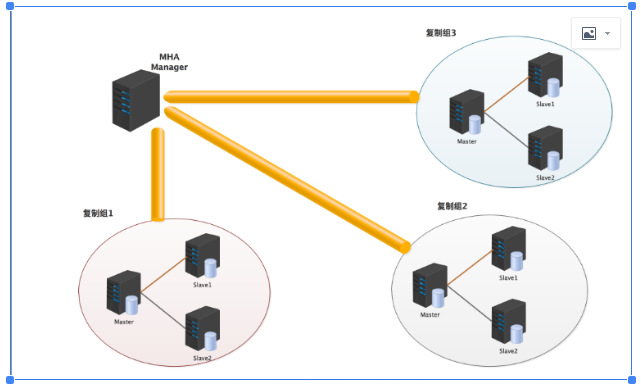
MHA架构图
版本差异:
最新是0.57版本(2018-05-07为0.58)支持了ipv6,一般不用ipv6因此不用安装这个新版本
建议用0.56的
在0.57以后的版本(如下图):[$host] 如果环境中没有perl-DBD-MySQL ,使用官方的文件可能连接不上数据库。因为语法不对需要将[]去掉。但在centos7 或安装的perl-DBD-MySQL则使用原语句即可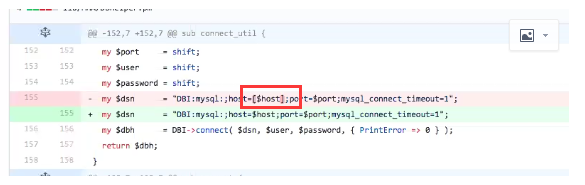
软件作用:
故障的主从切换和主从提升使MySQL具有高可用性的软件
特点
优点
能在0~30秒内完成自动故障主从切换,并且在切换过程中最大限度的保证数据的一致性。
(如果master为非系统故障可以保障数据的一致性)
1.可在9~12秒内发现master宕机。并在7~12秒内关闭master避免脑裂。
2.安装简单透明。对线长环境没有改变
3.可自动完成选择新主,完成切换,并将其他slave指向新master。切换主从的过程中队client完全透明,
4.具有自动日志补偿机制,最大程度的保证了数据的一致性
5.在线切换:秒级别切换,block时间短,对读不影响
缺点:
1.MHA Manager进程没有监控机制保证管理进程的正常进行
2.没有一个监控MHA 进行failover切换的成功性进行监控
3.注意主从切换后的备份机制的转换(例如全备)
MHA组成
由:MHA manager与MHA Node节点组成
运行机制
MHA manager 可以运行在独立一台主机上,也可以运行在一台slave上。
MHA可对多个master-slave集群进行管理。
MHA Manager 会对master进行定时探测是否存活。如果发现有故障,会从slave中选择数据最新的节点提升为master,且将其他slave的复制指向该新master。整个切换过程对client完全透明。
MHA在数据一致性上的运行机制
MHA对log有解析的功能: 该功能在mster/slave/manager上都可运行。
对relaylog的清理功能:清除没用必要保留的relaylog(切记:关闭mysql的 relay_log_purge功能)
数据(日志)补偿机制:
MHA会通过两种方式实现数据的补偿
1.通过ssh从master上获取需要补偿的日志从而完成日志一致性从而选出主
(疑问:在master主机可以访问的时候如何确认新master,是否也是从show slave
status\G中获取来确定新master)
2.当master主机宕机导致无法ssh到master时:MHA manager会从slave中选择出数据最新的节点为新的master,并通过relaylog向其他节点同步。以保证最大的一致性
为了最大程度保证master服务器宕机的数据一致性最好将MHA和半同步结合起来使用。原因是半同步有一个ACK的机制,最大程度保证了日志传送的成功率
MHA运行基本环境
一般至少需要三个节点:一主两从。其中MHA manager可运行在一台slave节点上。
但是由于考虑成本也有进行改进的MHA版本:目前淘宝 TMHA 已经支持一主一从
MHA在进行FaliOver时的运行原理(流程)
1.MHA Manager 探测发现master 可能宕机
2..尝试从master主机上获取需要补偿的二进制日志事件(binglog event),并尝试使用ssh连接mater服务器并连接MySQL共4次(默认)
需要清楚:图中—command=test 是为了确认dead master的服务器是否挂了(决定后面选slave的时候是按照master的binlog为最新还是slave的日志为最新)
3.检查配置:configuration check phase(如所有节点运行状况,确定哪些slave存活,MySQL版本信息,relay log info repository:file/table)
=======以上是发现dead master 后对dead master进行检查主要是为了看主机是否挂了=====
5,运行dead master shutdown script(如果声明了这个脚本)
6从slave集群中选出数据为最新的节点
====第7 8步是根据地2步的检查结果来决定使用哪种进行恢复数据并提升master=========
7.若dead master主机没挂
7.1将从master获取binlog日志。之后检查dead master 与新master的relay log是否有差异,有则进行应用。
7.2恢复之后声明为新master。声明出新master的change master语句。
7.3进行绑定VIP
7.4之后恢复其他slave数据 通过之前声明change master语句指向新master。
8.若master服务器宕机,则以该slave节点的日志为最新日志。并升为master,使用relaylog将其他slave节点数据拉平。将对其他slave节点进行change master
MHA的在线切换
在线切换master;此图中在进行切换时因为kill 了会话因此没有了数据修改处于静止状态,因此不存在数据不补偿
1.接触VIP
2.关闭连在原master上的业务会话
3.保证Master,slave上没有没有跟新操作(没有同步延迟)
4.S1,S2 进行stop slave,reset slave all, show master status
5.M1 S2 对S1进行change master to
6.VIP绑定在S1上
Manager 工具包和 Node 工具包
Manager 工具包主要包括以下几个工具
masterha_check_ssh : 检查 MHA 的 SSH 配置状况
masterha_check_repl: 检查 MySQL 复制状况
masterha_manger: 启动 MHA
masterha_check_status: 检测当前 MHA 运行状态
masterha_master_monitor: 检测 master 是否宕机
masterha_master_switch: 控制故障转移(自动或者手动)
masterha_conf_host: 添加或删除配置的 server 信息
Node 工具包(这些工具通常由 MHA Manager 的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs: 保存和复制 master 的二进制日志
apply_diff_relay_logs: 识别差异的中继日志事件并将其差异的事件应用于其他的 slave
filter_mysqlbinlog: 去除不必要的 ROLLBACK 事件(MHA 已不再使用这个工具)
purge_relay_logs: 清除中继日志(不会阻塞 SQL 线程)

若有收获,就点个赞吧
0 人点赞
