一、基础
进程和线程
进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体
通俗来讲进程就是指在系统中正在运行的一个应用程序。ps -ef 列出所有进程 ps -ef|grep node 列出所有node进程
PID: 进程ID
PPID:当前进程的父进程ID
单线程:
定义:唯一的主线程,在收到客服端请求后,不管它的请求响应(与数据库的连接),会继续接受客户端的其他请求。
优点:
1、节约内存
2、节约上下文切换的时间
3、没有锁的问题,并发资源处理
多线程:
并不是真正在同一个时间点指向多个任务,而是通过非常快速的切换时间片来实现的。
webworker多线程(没有改变js单线程的本质):
1、完全受主线程控制
2、不能操作DOM
多进程的优缺点
优点:
- 将复杂计算委派给其他进程来提高速度
充分利用cpu资源
缺点:
创建和销毁进程开销较大
-
多进程的创建
通过
child_process可以实现一个主进程,多个子进程模式,主进程称为master进程,子进程称为worker进程。
child_process模块提供了四个方法创建子进程: child_process.exec(command[, options][, callback])
原理:调用 /bin/sh -c 执行我们传入的shell脚本,底层调用了execFile;
- child_process.execFile(file[, args][, options][, callback])
原理:调用spawn创建和执行子进程,并建立了回调,一次性将所有的stdout和stderr结果返回;
- child_process.fork(modulePath[, args][, options])
原理:通过spawn创建子进程和执行命令,通过setupchannel创建IPC用于子进程和父进程间的双向通信;
child_process.spawn(command[, args][, options])
注:api基于node16.3版本 ```javascript var cp = require(‘child_process’);
//spawn cp.spawn(‘node’, [‘worker.js’]);
//exec cp.exec(‘node worker.js’, function (err, stdout, stderr) { // some code });
//execFile cp.execFile(‘worker.js’, function (err, stdout, stderr) { // some code });
//fork cp.fork(‘./worker.js’);
| **类型** | **回调** | **进程类型** | **执行类型** | **可设置超时** || --- | --- | --- | --- | --- || spawn | × | 任意 | 命令 | √ || exec | √ | 任意 | 命令 | √ || execFile | √ | 任意 | 可执行文件 | √ || fork | × | Node | javascript文件 | √ |<a name="udVyc"></a>### 进程间通信在 NodeJS 中,子进程对象使用 `send`方法实现主进程向子进程发送数据,`message`事件实现主进程收听由子进程发来的数据。```javascript// 父进程 parent.jsconst { fork } = require('child_process');const sender = fork(__dirname + '/child.js');sender.on('message', msg => {console.log('主进程收到子进程的信息:', msg);});sender.send('Hey! 子进程');
// 子进程 child.jsprocess.on('message', msg => {console.log('子进程收到来自主进程的信息:', msg);});process.send('Hey! 主进程');
分析:fork()是spawn()的变体,用来创建Node进程,最大的特点是父子进程自带通信机制(IPC管道)
IPC
IPC的全称是Inter-Process Communication,即进程间通信;目的是为了让不同的进程能够互相访问资源并进行协调工作
实现进程间通信的技术有很多,如 命名管道、匿名管道、socket、信号量、共享内存、消息队列、Domain Socket等
Node中实现IPC通道的是管道(pipe) 技术。但此管道非彼管道,在Node中管道是个抽象层面的称呼,具体细节实现由libuv提供,在 Windows下由命名管道(named pipe)实现,*nix系统则采用Unix Domain Socket实现。表现在应用层上的进程间通信只有简单的message事件和send()方法,接口十分简洁和消息化。下图为IPC 创建和实现的示意图。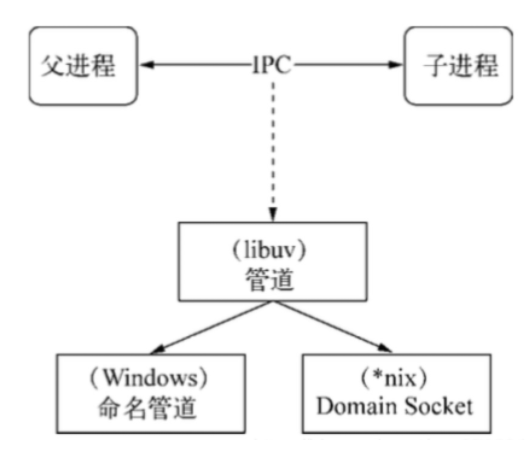
实际上,父进程会在创建子进程之前,会先创建 IPC 通道并监听这个 IPC,然后再创建子进程,通过环境变量(NODE_CHANNEL_FD)告诉子进程和 IPC 通道相关的文件描述符,子进程启动的时候根据文件描述符连接 IPC 通道,从而和父进程建立连接。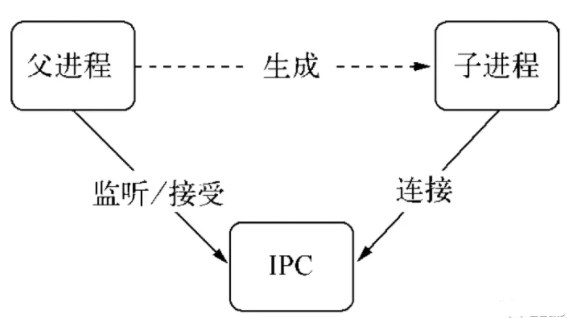
句柄传递
句柄是一种可以用来标识资源的引用的,它的内部包含了指向对象的文件资源描述符。
process.send(message[, sendHandle[, options]][, callback])
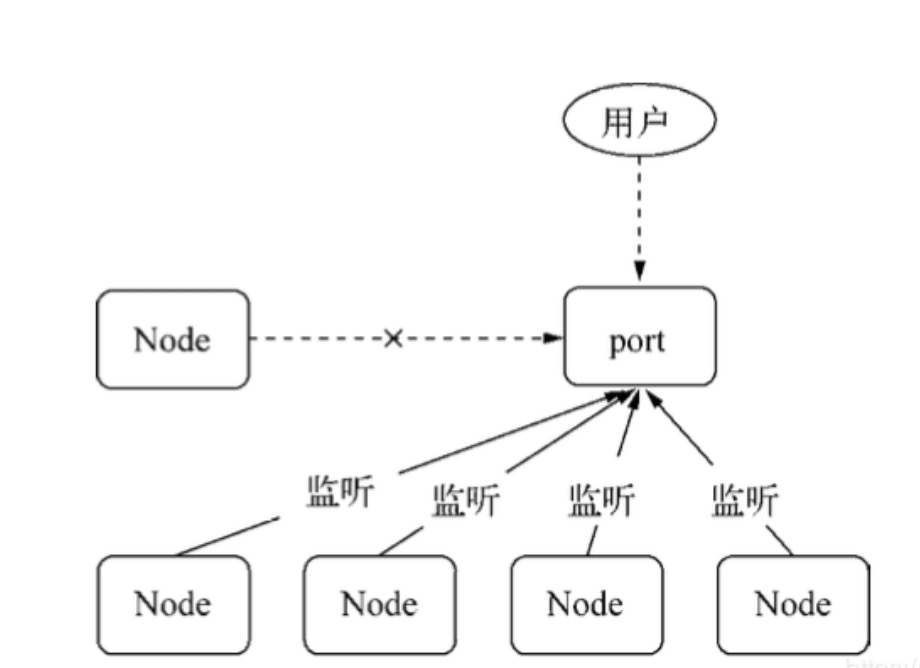
一般情况下,当我们想要将多个进程监听到一个端口下,可能会考虑使用主进程代理的方式处理: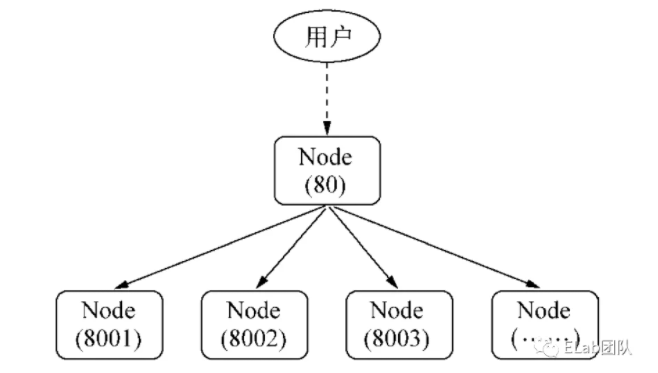
然而,这种代理方案会导致每次请求的接收和代理转发用掉两个文件描述符,而系统的文件描述符是有限的,这种方式会影响系统的扩展能力。
所以,为什么要使用句柄?原因是在实际应用场景下,建立 IPC 通信后可能会涉及到比较复杂的数据处理场景,句柄可以作为 send() 方法的第二个可选参数传入,也就是说可以直接将资源的标识通过 IPC 传输,避免了上面所说的代理转发造成的文件描述符的使用。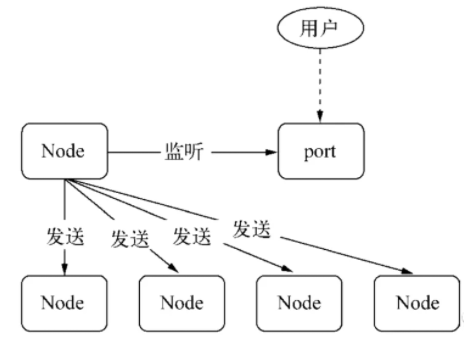
// master.jsconst cp = require("child_process")const child1 = cp.fork("child.js");const child2 = cp.fork('child.js');const server = require("net").createServer();server.on("connection",(socket)=>{socket.end('handled by parent\n');})server.listen(1337,()=>{child2.send('server', server);child1.send('server', server);server.close();})
// worker.jsprocess.on('message', function (m, server) {if (m === 'server') {server.on('connection', function (socket) {socket.end('handled by child, pid is ' + process.pid + '\n');});}});
以下是支持发送的句柄类型:
- net.Socket
- net.Server
- net.Native
- dgram.Socket
- dgram.Native
句柄发送与还原: send() 方法在发送消息前,会将消息组装成 handle 和 message,这个 message 会经过 JSON.stringify 序列化,也就是说,传递句柄的时候,不会将整个对象传递过去,在 IPC 通道传输的都是字符串,传输后通过 JSON.parse 还原成对象。
为什么多个进程可以监听同一个端口呢?
原因是主进程通过 send() 方法向多个子进程发送属于该主进程的一个服务对象的句柄,所以对于每一个子进程而言,它们在还原句柄之后,得到的服务对象是一样的,当网络请求向服务端发起时,进程服务是抢占式的,所以监听相同端口时不会引起异常。
Cluster
用途:
- 在服务器上同时启动多个进程, 这些进程可以同时监听一个端口
- 每个进程里都跑的是同一份源代码(好比把以前一个进程的工作分给多个进程去做)
- Worker 进程的数量一般根据服务器的 CPU 核数来定,这样就可以完美利用多核资源 ```javascript var cluster = require(‘cluster’); var os = require(‘os’); // 获取CPU 的数量 var numCPUs = os.cpus().length; var process = require(‘process’)
console.log(‘numCPUs:’, numCPUs) var workers = {}; if (cluster.isMaster) { // 主进程分支 cluster.on(‘death’, function (worker) { // 当一个工作进程结束时,重启工作进程 delete workers[worker.pid]; worker = cluster.fork(); workers[worker.pid] = worker; }); // 初始开启与CPU 数量相同的工作进程 for (var i = 0; i < numCPUs; i++) { var worker = cluster.fork(); workers[worker.pid] = worker; } } else { // 工作进程分支,启动服务器 require(‘./app’); } // 当主进程被终止时,关闭所有工作进程 process.on(‘SIGTERM’, function () { for (var pid in workers) { process.kill(pid); } process.exit(0); });
```javascript// app.jsconst http = require('http')const server = http.createServer((req, res) => {res.write('hello http!')res.end()})server.listen(3030, () => {console.log('server is listening on http://localhost:3030')})console.log(`worker ${process.pid} start`)
简单来说,cluster 模块是 child_process 模块和 net 模块的组合应用。
cluster 启动时,内部会启动 TCP 服务器,将这个 TCP 服务器端 socket 的文件描述符发给工作进程。
在 cluster 模块应用中,一个主进程只能管理一组工作进程,其运作模式没有 child_process 模块那么灵活,但是更加稳定。
参考资料:
- 浅析 NodeJS 多进程和集群
- node文档
-
RPC调用
Remote Procedure Call(远程过程调用),用于BFS与后台链接的过程;
二进制协议: 更小的数据包体积;
- 更快的编解码速度;
多路复用:
和Ajax有什么相同点?
- 都是两个计算机之间的网络通行;
- 需要双方约定一个数据格式;
和Ajax有什么不同点?
- 不一定使用DNS作为寻址过程;
- 顶层协议一般不使用HTTP;
-
TCP通信方式:
单工通信
- 半双工通信
-
全双工的通信通道搭建:
关键在于应用层协议需要有标记标号的字段;
- 处理以下情况,需要有标记包长的字段;
- 粘包
- 不完整包
-
非阻塞I/O:
同步异步取决于被调用者,他来决定是马上给你答案,还是回头再给。
阻塞非阻塞取决于调用者,在等待答案的过程中,调用方是否可以干别的事。什么场合下使用
需要处理大量并发的输入输出,在向客户端响应时,应用程序不需要进行非常复杂的处理。
聊天服务器
- 电子商务网站
nexTick: 把回调函数放在当前执行栈的底部
setImmediate:把回调函数放在事件队列的底部 (放不重要的事情)
进制转换
let a = 0b10100;//二进制console.log(a);let b = 0o24;//八进制console.log(b);let c = 20;//十进制let d = 0x14;console.log(d);//十六进制//如何把任意进制转成十进制console.log(parseInt("0x10",16));//如何把十进制转成任意进制console.log(c.toString(2));// 八进制 转成十六进制
Buffer是node的核心模块,开发者可以利用它来处理二进制数据,比如文件流的读写、网络请求数据的处理等。
buffer
/*** alloc 表示分配一块有初始值的内容,不第二项会把所有的字节设置为0, buffer存的都是16进制**/Buffer.alloc(size[, fill[, encoding]])Buffer.alloc(6,2)//一个长度为6字节初始值为2的Buffer/*** allocUnsafe 分配一块没有初始化的内存**/let buf2 = Buffer.allocUnsafe(6);// 输出的内容是内存的旧数据,每次都不同/*** from 拷贝数据**/const buf1 = Buffer.from('buffer');const buf2 = Buffer.from(buf1);buf1[0] = 0x61;console.log(buf1.toString()); // 打印: aufferconsole.log(buf2.toString()); // 打印: buffer/*** concat buffer合并**/Buffer.concat(list[, totalLength])let buf3 = Buffer.from('你');let buf4 = Buffer.from('好');let result = Buffer.concat([buf3,buf4]);console.log(result);
/*** string_decoder* 它的出现是为了解决乱码问题*/let buf9 = Buffer.from('认真生活');let buf10 = buf9.slice(0,5);//5let buf11 = buf9.slice(5,7);//7let buf12 = buf9.slice(7);console.log('buf10', buf10.toString());console.log('buf11', buf11.toString());console.log('buf12', buf12.toString());let {StringDecoder} = require('string_decoder');let sd = new StringDecoder();//write就是读取buffer的内容,返回一个字符串//write的时候会判断是不是一个字符,如果是的话就输出不是的话则缓存在对象内部,// 等下次write的时候会把前面缓存的字符加到第二次write的buffer上再进行判断console.log(sd.write(buf10));//认console.log(sd.write(buf11));//真console.log(sd.write(buf12));//生活
fs
/*** readFile 读取文件**/fs.readFile(path[, options], callback)fs.readFile() 函数会缓冲整个文件。 为了最小化内存成本,尽可能通过 fs.createReadStream() 进行流式传输。/*** writeFile**/fs.writeFile(file, data[, options], callback)/*** write 写入文件,当调用write方法写入文件的时候,并不会直接定入物理文件,* 而是会先写入缓存区,在批量写入物理文件**/fs.write(fd, buffer[, offset[, length[, position]]], callback)fs.write(fd, string[, position[, encoding]], callback)// 如果 typeof position !== 'number',则数据会被写入当前的位置/*** read**/fs.read(fd, buffer, offset, length, position, callback)// position 参数指定从文件中开始读取的位置。 如果 position 为 null,// 则从当前文件位置读取数据,并更新文件位置。 如果 position 是整数,则文件位置将保持不变。/*** readdir 获取一个目录下的所有文件或目录**/fs.readdir(path[, options], callback)/*** unlink 删除一个文件**/fs.unlink(path, callback)/*** rmdir 删除一个空目录**/fs.rmdir(path, callback)/*** open 打开文件**/fs.open(path, flags[, mode], callback)
function copy(source,target){let size = 3; // 每次来三个let buffer = Buffer.alloc(3);fs.open(path.join(__dirname,source),'r',function(err,rfd){fs.open(path.join(__dirname,target),'w',function(err,wfd){function next(){fs.read(rfd,buffer,0,size,null,function(err,bytesRead){if(bytesRead>0){ // 读取完毕了 没读到东西就停止了fs.write(wfd,buffer,0,bytesRead,null,function(err,byteWritten){next();})}else{fs.close(rfd,function(){}); // 读取的// 强行把缓存区的数据写入文件,并且关闭fs.fsync(wfd,function(){ // 确保内容 写入到文件中fs.close(wfd,function(){ // 写入的console.log('关闭','拷贝成功')})})}})}next();})});}copy('1.txt','2.txt');
// 如果是异步的永远不能用for循环function mkdirSync(dir,callback){let paths = dir.split('/');!function next(index){if(index>paths.length) return callback();let newPath = paths.slice(0,index).join('/');fs.access(newPath,fs.constants.R_OK, function(err) {if (err) {// 如果文件不存在就创建这个文件fs.mkdir(newPath, function(err) {next(index + 1); // 创建后 继续创建下一个});} else {next(index + 1); //这个文件夹存在了 那就创建下一个文件夹}});}(1);}mkdirSync('a/e/w/q/m/n',function(){console.log('完成')});
// 同步删除function rmdirp(dir) {let files = fs.readdirSync(dir);files.forEach(function(file) {let current = dir + '/' + file;let child = fs.statSync(current);if (child.isDirectory()) {rmdirp(current);} else {fs.unlinkSync(current);}});fs.rmdirSync(dir);}rmdirp('a');// 异步删除文件夹function rmdir(dir) {return new Promise(function (resolve, reject) {fs.stat(dir, (err, stat)=> {if(stat.isDirectory()){fs.readdir(dir, (err, files) => {if (err) return reject(err);// 先删除当前目录的子文件夹或文件,在删除自己return Promise.all(files.map(item => rmdir(path.join(dir,item)))).then(res => {fs.rmdir(dir, resolve);});});}else{fs.unlinkSync(dir, resolve);}})})}rmdir('a');
fs.watchFile('./1.txt',function(current,prev){if(Date.parse(current.ctime)==0){console.log('删除')}else if(Date.parse(prev.ctime) === 0){console.log('创建')}else{console.log('修改');}});
path
// 环境变量分割符, 因为在不同的操作系统下,分割符不一样// window ; mac linux :path.delimiter// 文件路径分隔符path.stepconsole.log(path.sep);console.log(path.win32.sep);console.log(path.posix.sep); // linux// 获取文件名path.basename()path.basename('/foo/bar/baz/asdf/quux.html', '.html'); // 返回: 'quux'// 获取文件扩展名path.extname()
stream
- 可读流
可读流事实上工作在下面两种模式之一: flowing 和 paused
在flowing模式下,可读流自动从系统底层读取数据,并通过EventEmiter接口的事件尽快将数据提供给应用。
在paused模式下,必须显示调用stream.read()方法来从流中读取数据片段。
所用初始工作模式为paused的Readable流,可以通过下面三种途径切换到flowing模式:
- 监听’data’事件
- 调用stream.resume()方法
- 调用stream.pipe()方法将数据发送到Writable
可读流可以通过下面途径切换到paused模式:
- 如果不存在管道目标(pipe destination), 可以通过调用stream.puase()方法实现;
- 如果存在管道目标,可以通过取消’data’事件监听,并调用stream.unpipe()方法移除所用管道目标来实现。
如果Readable切换到flowing模式,且没有消费者处理流中的数据,这些数据将会丢失。比如,调用了 readabel.reaume()方法却没有监听’data’事件,或是取消了’data’事件,就有可能出现这种情况。
/*** 创建一个可读流* highWaterMark 缓冲区文件大小,默认64 kb* 监听它的data事件,当你一旦开始监听data事件的时候,流就开始读文件的内容并且发射data;**/let rs = fs.createReadStream(path[, options])rs.on('data',function(data){ // 暂停模式 -> 流动模式console.log(data);rs.pause(); // 暂停方法 表示暂停读取,暂停data事件触发});rs.setEncoding('utf8'); // buffer转为字符串rs.on('end',function(){console.log('end')});/*** 当你监听readable事件的时候,会进入暂停模式,可读流会马上向底层读取文件,然后把读取到的文件放在缓存* 区里。* res.read(0);只填充缓存,并不会发射data事件,但是会反射stream.emit('readable')事件。* 当读完指定的字节后,如果可读流发现剩下的字节以及比最高水位线小了。则会立马再次读取填满。**/rs.on('readable',function(){let result = rs.read(1); // read不加参数表示读取整个缓存区数据。console.log(result.toString(), rs._readableState.length); // 缓存区的个数setTimeout(function(){console.log(rs._readableState.length);},1000)});
- 行读取器
- Unix系统里,每行结尾只有换行”(line feed)”, 即”\n”;
- Windows系统里面,每行结尾是”<回车><换行>”,即”\r\n”;
- Mac系统里,每行结尾是”回车”(carriage return), 即”\r”
换行 \n 10 0A 回车 \r 13 0D
// LineReader 行读取器let fs = require('fs');let EventEmitter = require('events');// 在window下 换行回车是\r\n 0x0d 0x0a ASCII// 在mac下 只是\nlet path = require('path');class LineReader extends EventEmitter {constructor(path) {super();this.RETURN = 0x0d;this.LINE = 10;this.buffer = [];this._rs = fs.createReadStream(path); // 默认情况下会先读highWaterMarkthis.on('newListener', (eventName) => {if (eventName === 'line') {this._rs.on('readable', () => {let char;// 读出来的内容都是buffer类型while (char = this._rs.read(1)) {let current = char[0];switch (current) {// 当碰到\r时表示这一行ok了case this.RETURN:this.emit('line', Buffer.from(this.buffer).toString());this.buffer.length = 0;let c = this._rs.read(1);// 读取\r后 看一下下一个是不是\n 如果不是就表示他是一个正常的内容if (c[0] !== this.LINE) {this.buffer.push(c[0]);}break;case this.LINE:// mac只有\r 没有\nthis.emit('line', Buffer.from(this.buffer).toString());this.buffer.length = 0;default:this.buffer.push(current);}}});this._rs.on('end', () => {this.emit('line', Buffer.from(this.buffer).toString());this.buffer.length = 0});}})}}let lineReader = new LineReader(path.join(__dirname, './2.txt'));lineReader.on('line', function (data) {console.log(data); // abc , 123 , 456 ,678})
/*** 创建一个可写流* highWaterMark 缓冲区文件大小* 往可写流里写数据的时候,不是会立刻写入文件的,而是先写入缓存区,缓存区的大小是就是highWaterMark,* 默认值是**/fs.createWriteStream(path[, options])
/*** 自定义可读流**/let {Readable} = require('stream');// 想实现什么流 就继承这个流// Readable里面有一个read()方法,默认掉_read()// Readable中提供了一个push方法你调用push方法就会触发data事件let index = 9;class MyRead extends Readable{_read(){// 可读流什么时候停止呢? 当push null的时候停止if(index-->0)return this.push('123');this.push(null);}}let mr = new MyRead;mr.on('data',function(data){console.log(data.toString());});/*** 自定义可写流**/let {Writable} = require('stream');// 可写流实现_write方法// 源码中默认调用的是Writable中的write方法class MyWrite extends Writable{_write(chunk,encoding,callback){console.log(chunk.toString());callback(); // clearBuffer}}let mw = new MyWrite();mw.write('你好','utf8',()=>{console.log(1);})mw.write('你好','utf8',()=>{console.log(1);});
let {Transform} = require('stream');let fs = require('fs');let rs = fs.createReadStream('./user.json');let t = Transform({transform(chunk, encoding, cb) {// 向可读流里的缓存区里放this.push(chunk.toString().toUpperCase());cb()}});process.stdin.pipe(t).pipe(process.stdout)let toJSON = Transform({readableObjectMode: true, // 就可以向可读流里放对象transform(chunk,encoding,cb){// 向可读流里的缓存区里放this.push(JSON.parse(chunk.toString()))}})let outJSON = Transform({writableObjectMode: true,transform(chunk,encoding,cb){console.log(chunk);cb()}})rs.pipe(toJSON).pipe(outJSON);
双工流:又能读 又能写,而且读取可以没关系(互不干扰);
let {Duplex} = require(‘stream’);
二、进阶
部署
1、主要解决问题
- 故障恢复
- 多核利用
- 多进程共享 ```javascript var cluster = require(‘cluster’); var os = require(‘os’); // 获取CPU 的数量 var numCPUs = os.cpus().length; var process = require(‘process’)
console.log(‘numCPUs:’, numCPUs) var workers = {}; if (cluster.isMaster) { // 主进程分支 cluster.on(‘death’, function (worker) { // 当一个工作进程结束时,重启工作进程 delete workers[worker.pid]; worker = cluster.fork(); workers[worker.pid] = worker; }); // 初始开启与CPU 数量相同的工作进程 for (var i = 0; i < numCPUs; i++) { var worker = cluster.fork(); workers[worker.pid] = worker; } } else { // 工作进程分支,启动服务器 var app = require(‘./app’); app.use(async (ctx, next) => { console.log(‘worker’ + cluster.worker.id + ‘,PID:’ + process.pid) next() }) app.listen(3000); } // 当主进程被终止时,关闭所有工作进程 process.on(‘SIGTERM’, function () { for (var pid in workers) { process.kill(pid); } process.exit(0); });
require(‘./test’)
```javascript// 利用了node的child_process,缺点:一个进程开启一个端口const child_process = require('child_process');require('./test.js')const fork = []for (var i = 0; i < 2; i++) {var worker_process = child_process.fork("app.js", [3000 + i]);worker_process.on('close', function (code) {console.log('子进程已退出,退出码 ' + code);});fork.push(worker_process)}process.on('SIGTERM', function () {fork.forEach(worker_process.kill())process.exit(0);});
PM2的应用
- 内建负载均衡
- 线程守护,keep alive
- 0秒停机重载,维护升级的时候不不需要停机
- 现在 Linux (stable) & MacOSx (stable) & Windows (stable).多平台⽀支持
- 停⽌止不不稳定的进程(避免⽆无限循环)
- 控制台检测 https://id.keymetrics.io/api/oauth/login#/register
- 提供 HTTP API
三、应用
关键字搜索
```javascript const fs = require(“fs”); const path = require(“path”);
function writeLog(writeStream, log) { writeStream.write(log + “\n”); }
function createWriteStream(fileName) { const fullFileName = path.join(__dirname, fileName); const writeStream = fs.createWriteStream(fullFileName, { flags: “w” }); return writeStream; }
const accessWriteStream = createWriteStream(“china-provice-city-map.js”);
function access(log) { writeLog(accessWriteStream, log); }
const codeAll = {};
const setProvice = async () => { const fileNameAll = fs.readdirSync(“./china-main-city”); fileNameAll.forEach((filepath, idx) => { const fullPath = path.join(__dirname, “./china-main-city”, filepath); const code = filepath.split(“.”)[0]; const file = fs.readFileSync(fullPath, “utf8”); try { const str = file.toString(); const nameAll = []; str.replace(/\”name\”\:\s*?\”(.+?)\”+?/g, (match, group1) => { nameAll.push(group1); }); codeAll[code] = nameAll; } catch (error) { console.log(“error”, filepath, error); } }); access(“var provice = “ + JSON.stringify(codeAll)); };
setProvice();
```

若有收获,就点个赞吧
0 人点赞
