1. HashMap 简介
java.util.Map 中,此接口有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap, 类继承关系图如下所示:
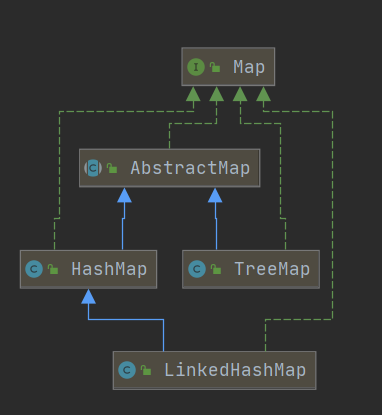
各类特点如下:
- HashMap: 根据hashCode 存储数据,访问速度快,仅允许一条记录key = null,允许多条记录的值为null;
- LinkedHashMap: hashMap 的子类,保存了插入的顺序,遍历时根据插入顺序遍历;
- TreeMap: 实现SortMap 接口,能够根据键值排序;key必须实现Comparable接口;
存储结构
HashMap 是数组+链表+红黑树(JDK1.8增加了红黑树);
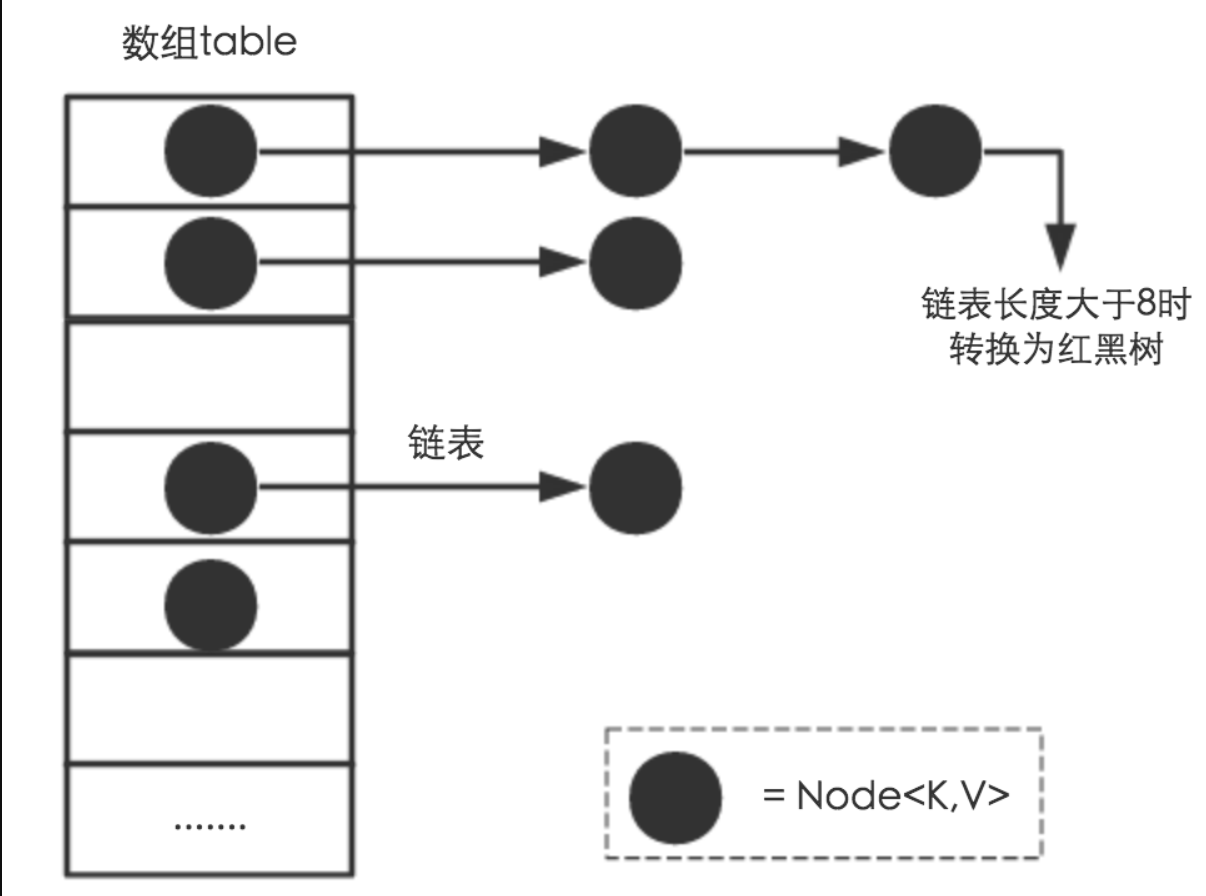
1) 数据存储在Node[]table (即 哈希桶数组)这个成员变量里;
static class Node<K,V> implements Map.Entry<K,V> {final int hash; //用来定位数组索引位置final K key;V value;Node<K,V> next; //链表的下一个nodeNode(int hash, K key, V value, Node<K,V> next) { ... }public final K getKey(){ ... }public final V getValue() { ... }public final String toString() { ... }public final int hashCode() { ... }public final V setValue(V newValue) { ... }public final boolean equals(Object o) { ... }}
Node是内部类,存储了键、值、哈希值;
2)哈希冲突的解决,链地址法,即数组+链表;
功能方法
hash值计算
// 方法一:static final int hash(Object key) { //jdk1.8 & jdk1.7int h;// h = key.hashCode() 为第一步 取hashCode值// h ^ (h >>> 16) 为第二步 高位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}// 方法二:static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的return h & (length-1); //第三步 取模运算}
注: 方法1、方法2 实质上 java7、8是都有的;只不过java8 没有把indexFor抽象成一个方法;
put方法
public V put(K key, V value) {// 对key的hashCode()做hashreturn putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 步骤①:tab为空则创建if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 步骤②:计算index,并对null做处理if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 步骤③:节点key存在,直接覆盖valueif (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// 步骤④:判断该链为红黑树else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 步骤⑤:该链为链表else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key,value,null);//链表长度大于8转换为红黑树进行处理if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// key已经存在直接覆盖valueif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// 步骤⑥:超过最大容量 就扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
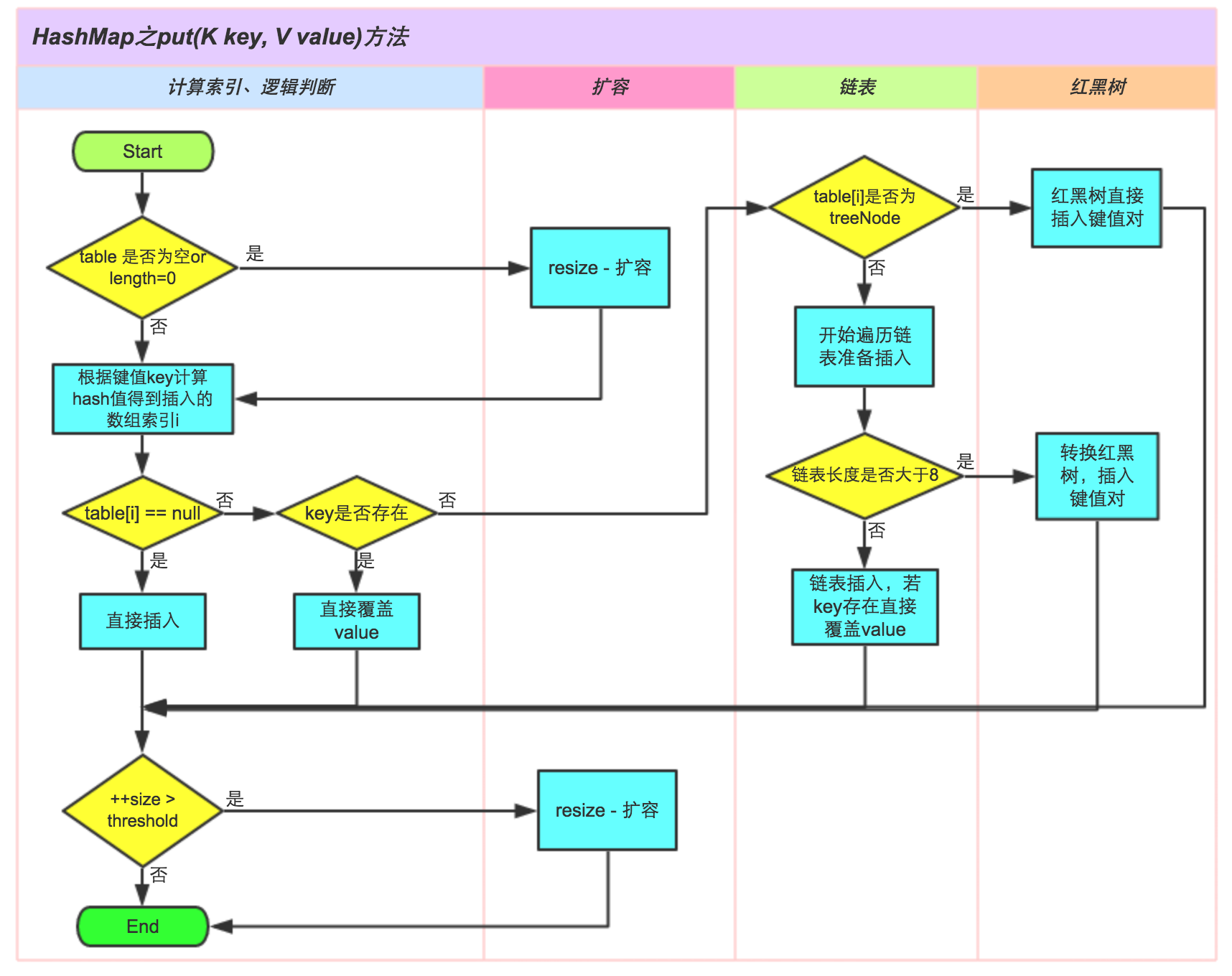
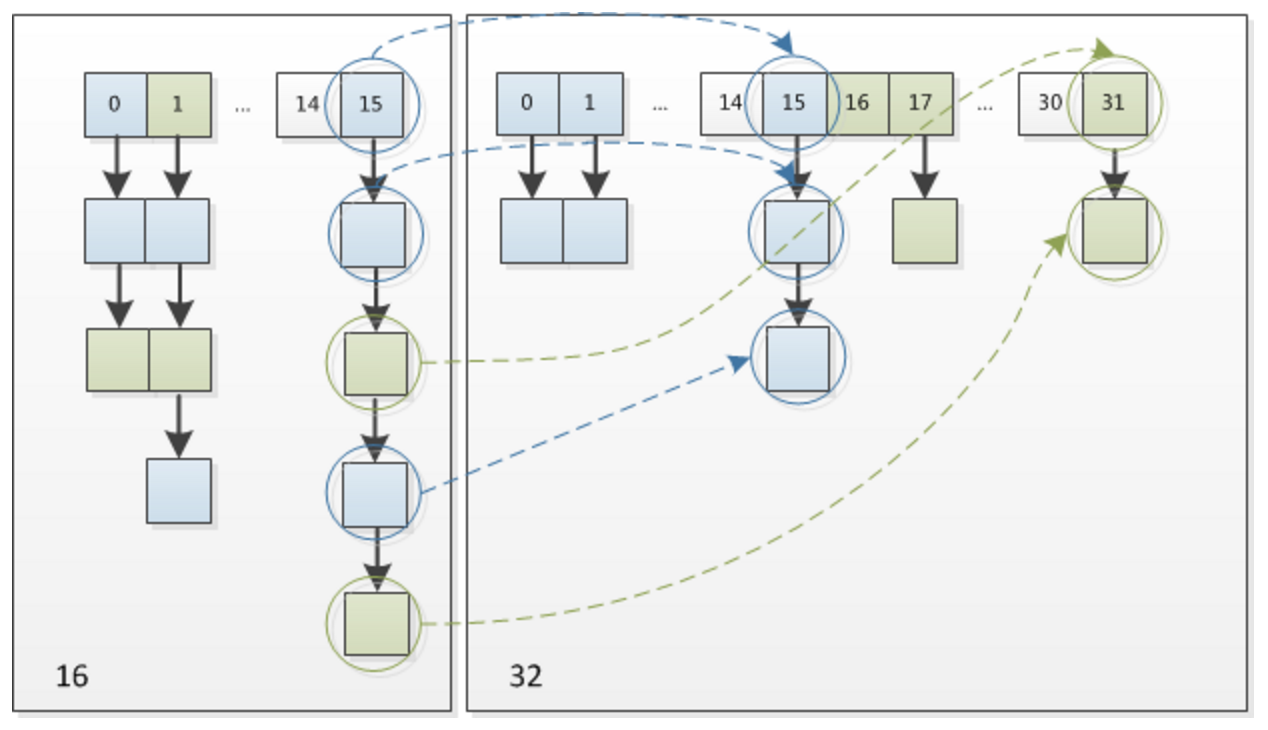
扩容机制
新建一个新数组,迁移数据;
Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}
经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置
注意点:扩容后数据的保存位置可能不一样。位置 = key的哈希与高位运算结果 + oldCap;
2. ConcurrentHashMap
Map的派生类,api基本与HashMap一致,加入了同步操作;
1.7版本ConcurrentHashMap由一个个Segment组成,简单来说,ConcurrentHashMap是一个Segment数组,通过继承ReentrantLock来进行加锁,通过每次锁住一个segment来保证segment内的操作的线程安全性;
点击查看【processon】
理论上最多支持16个并发写入操作;
相对于1.7版本,1.8的改进
1)取消了segment的分段设计,直接采用Node数组来保存数据,并采用Node数组元素作为锁(减少并发冲突的概率);
2)由数组+单向链表,改为数组+单向链表+红黑树结构;链表数量大于8,自动变为红黑树,查询复杂度降低至O(logN);
3) 计算元素个数 方式不一样;
1.7 是连续计算两次 数量,如果两次一样则返回; 如果不一样,则给每一个segement 加锁重新计算元素个数:
1.8 是volatitle baseCount , cellCount[] , 累加起来;
addCount
// putVal() 采用synchronized对同步代码块加锁;最后调用addCount()
// x:这次需要在表中新增的元素个数,check标识是否需要进行扩容检查(>0,检查);
private final void addCount(long x, int check) {CounterCell[] as; long b, s;// 判断 counterCells 是否为空,1. 如果为空,就通过 cas 操作尝试修改 baseCount 变量,对这个变量进行原子累加操作(做这个操作的意义是:如果在没有竞争的情况下,仍然采用 baseCount 来记录元素个数)2. 如果 cas 失败说明存在竞争,这个时候不能再采用 baseCount 来累加,而是通过CounterCell 来记录if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {CounterCell a; long v; int m;boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {fullAddCount(x, uncontended);return;}if (check <= 1)return;s = sumCount();}//....}
CounterCells初始化图解
初始化长度为 2 的数组,然后随机得到指定的一个数组下标,将需要新增的值加入到对应下
标位置处
3. 经典问题
1)JDK1.8 HashMap扩容为神马是原数组的两倍?
为了减少hash次数,通过与运算( node.hash() & oldCapSize ),得出0,1;
0位置不用变,1位置 = 当前位置+capSize
2) 链表神马时候变为红黑树?
单个链数量大于8 且总元素大于 64
小于6转化成链表
参考
Java 8系列之重新认识HashMap
ConcurrentHashMap实现线程安全的底层原理, 1.7和1.8的比较
hashmap头插法和尾插法区别_一个跟面试官扯皮半个小时的HashMap

若有收获,就点个赞吧
0 人点赞
