1. 关键字术语
final
可以用于修饰类、方法、变量
修饰类:此类不可被继承,会隐式的将所有方法指定为final方法;
修饰方法:方法不能被重写;
修饰变量:如果是基本数据类型,则其数值一旦初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象;
注:修饰方法主要是为了防止继承类修改它的含义;
被final 修饰 的 数据,编译器会有错误提示: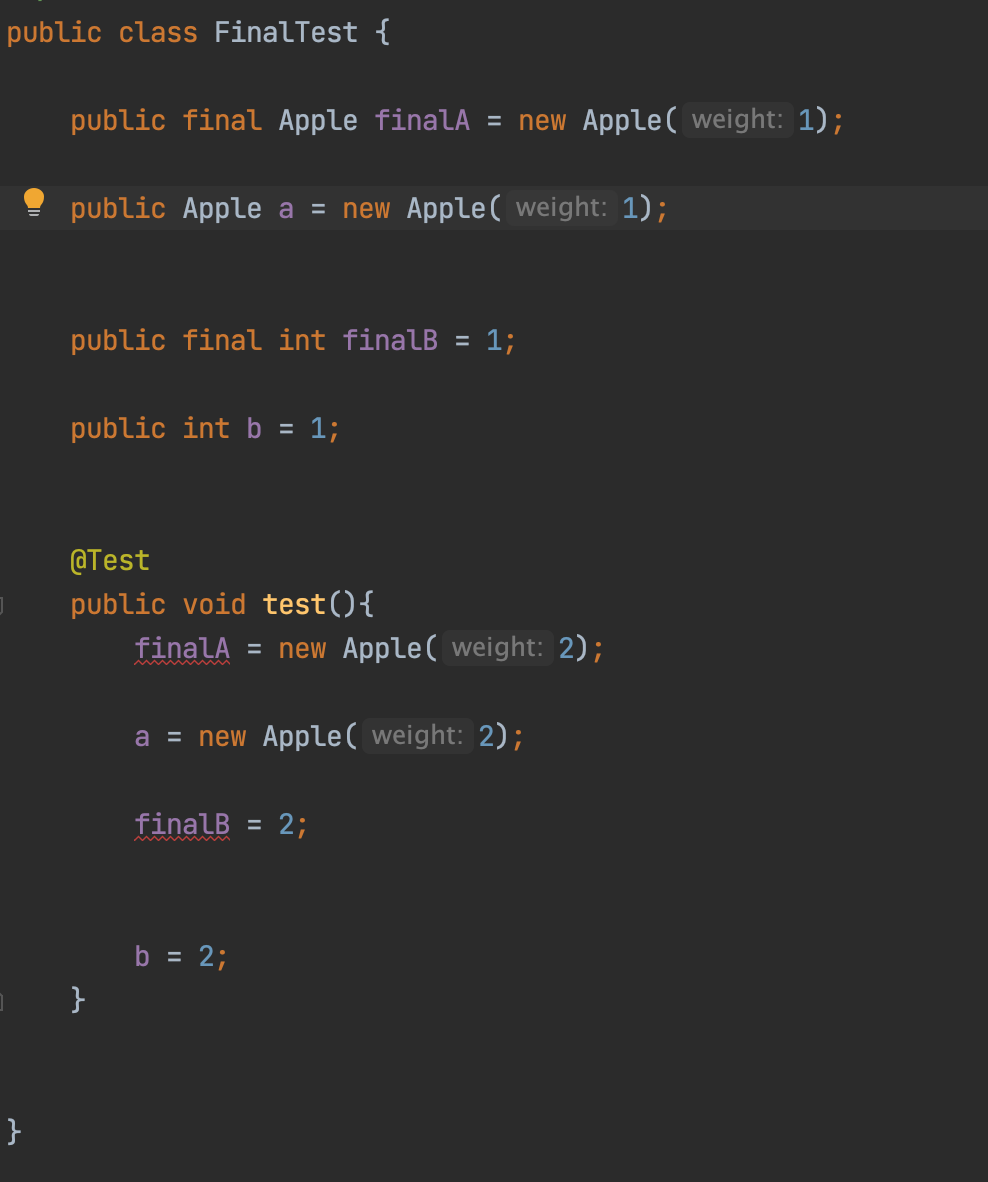
static
静态内部类:静态内部类 与 非静态内部类的区别就是,静态内部类不依赖与外部类的初始化;
静态代码块:静态代码块 定义在类中的方法外,静态代码块的非静态代码块之前执行(静态代码块 -> 非静态代码块 -> 构造方法)
修饰成员变量和成员方法:被static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享;
存放在内存区的方法区;
junit 和 main 运行java区别?
junit 没有守护线程;
main有守护线程;
在执行线程类似的测试时,junit 不太方便,需要主线程 sleep();
this
用于引用类的当前示例;
super
contiue、break、return
continue : 跳出当前循环,进行下一次循环;
break: 跳出当前循环;
return: 方法返回;
深拷贝 和 浅拷贝
浅拷贝
描述: 基本数据类型是值拷贝,引用类型是引用地址的拷贝;
实现方式: 实现Cloneable 接口
深拷贝
描述:在拷贝引用变量的同时,会为引用类型的数据,开辟出一个独立的内存空间;实现真正内容上的拷贝;
实现方式:实现Cloneable 接口
方法
为啥java 中仅有值传递
值传递:在函数调用的时候,将实际参数复制一份,调用过程仅会改变复制数的值,不会影响到实际参数;
引用传递:在调用函数时,将实际的参数地址传递给函数,这样在函数对参数进行修改后,会影响到实际参数;
示例如下:
1) 基本数据类型;
函数入参更改时,是改的副本的值,原值自然不会变化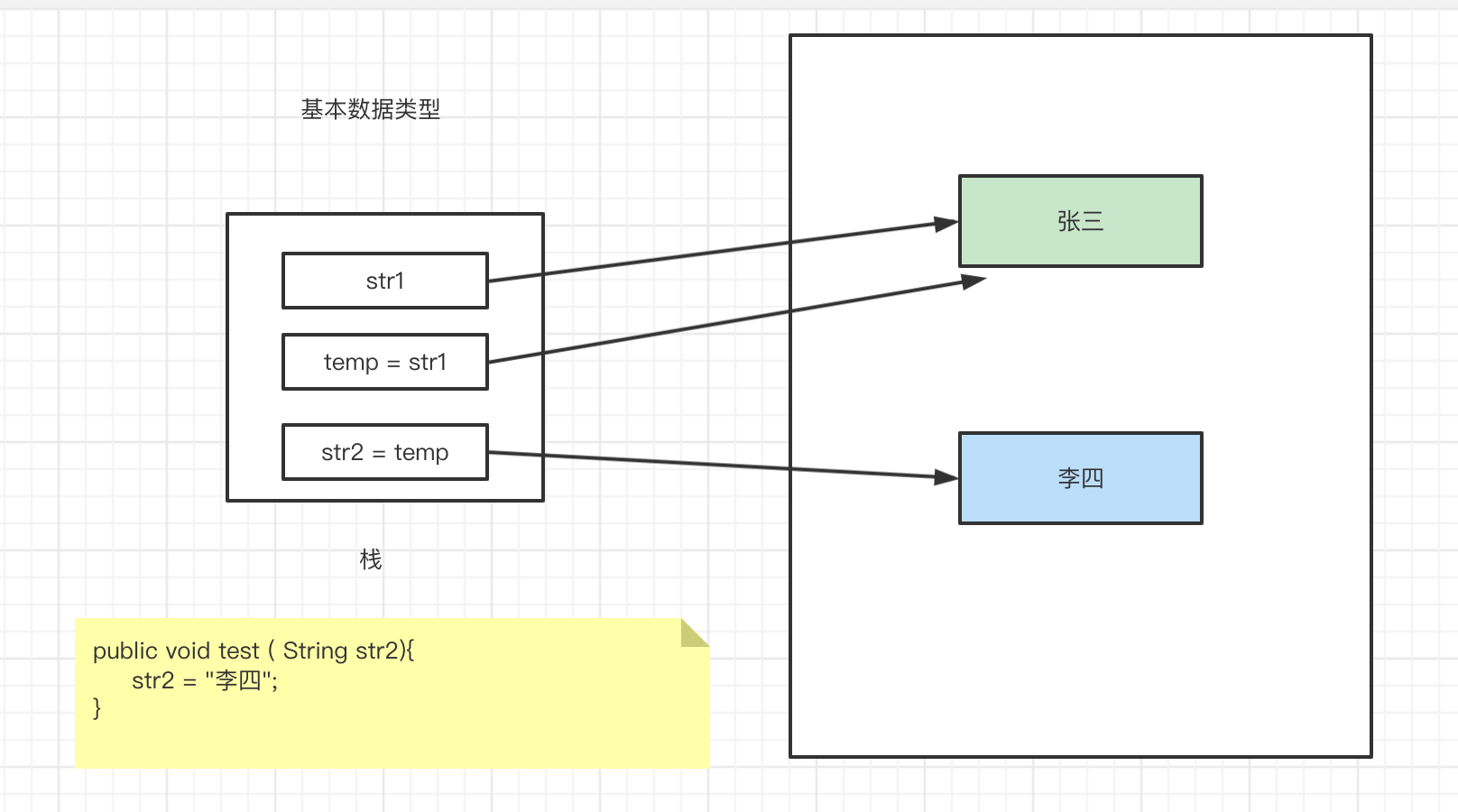
2)对象类型;
函数入参更改后,改的是引用类型对应堆中的值,原值和入参指的地方一致,自然会一起改喽;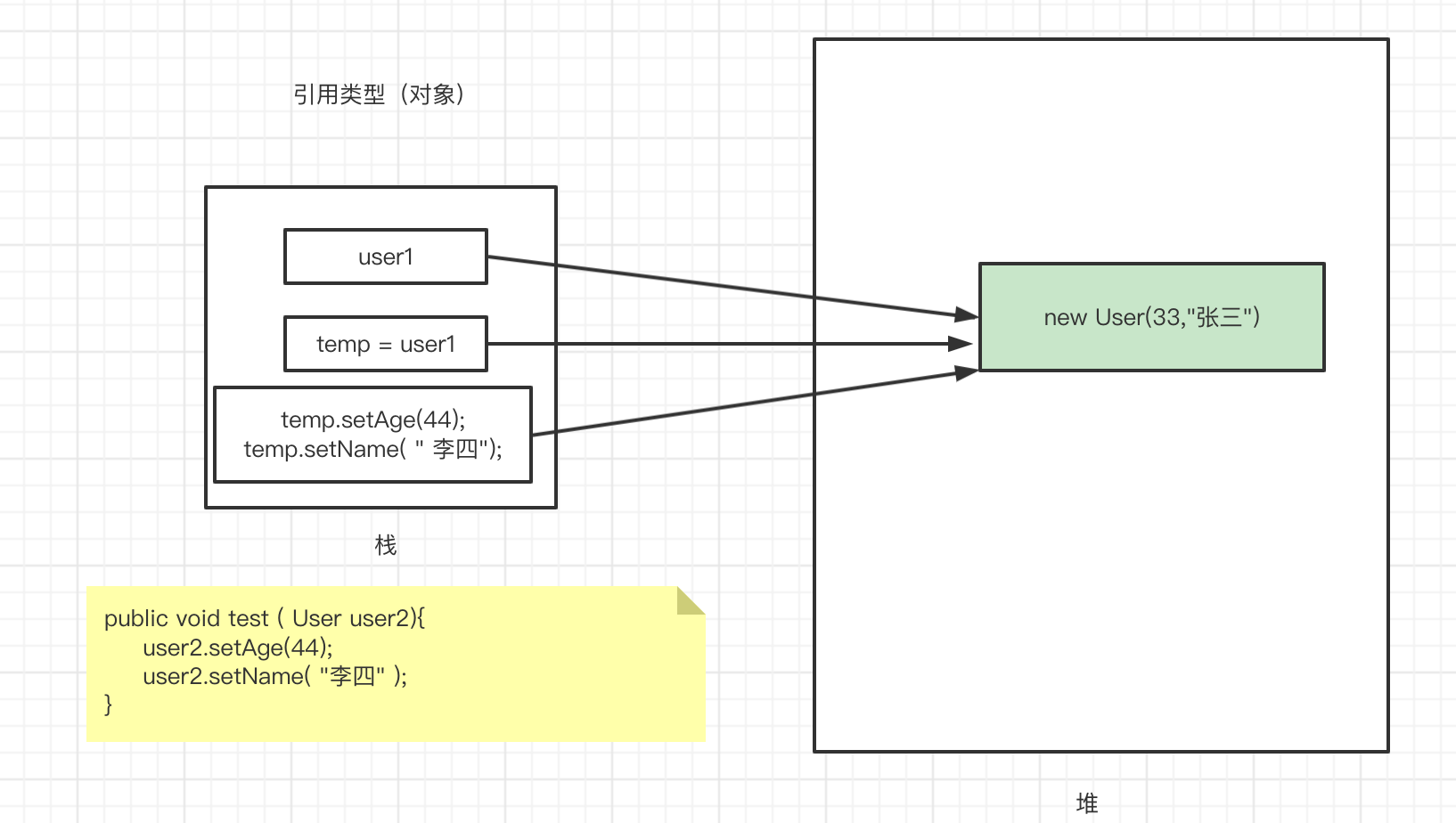
参见 : 为什么大家都说Java中只有值传递?
重载和 重写
这两个概念,个人觉得 不用可以去记,
可以根据是否是继承来判断:
发生继承的,才有重写可能嘛,重写一般是为了丰富功能,【参数、返回值 要与 父类型保持一致】
未发生继承的,在一个类里面,叫重载,重载一般是为了方便调用,给予一些参数默认值
自动拆装箱
// 装箱Integer i = 1;// 拆箱int j = i;
自旋锁与互斥锁
自旋锁
主要是通过 while(true ) 加 CAS 实现;
优点:
不会挂起线程,一直会等到资源变成可以用的时候,操作; 会消耗cpu 时间片,但线程一直处于用户态,避免了【用户态】到【内核态】的 上下文切换;
支持线程中断;
缺点:
适用于等待时间很短的场景,耗时操作的话会导致cpu 消耗过大,因为cpu 一直在这等着资源嘛;
场景:
AQS 中 加入等待队列 enq 方法;
互斥锁
获取锁时,有线程已经占用了,就等待或者干脆就放弃了;
用到的地方: 重入锁的 公平锁;
2. 基本数据类型
String
字符串常量池
String s1 = "hello world ";String s2 = new String("hello world ");s2.intern();
3. 集合
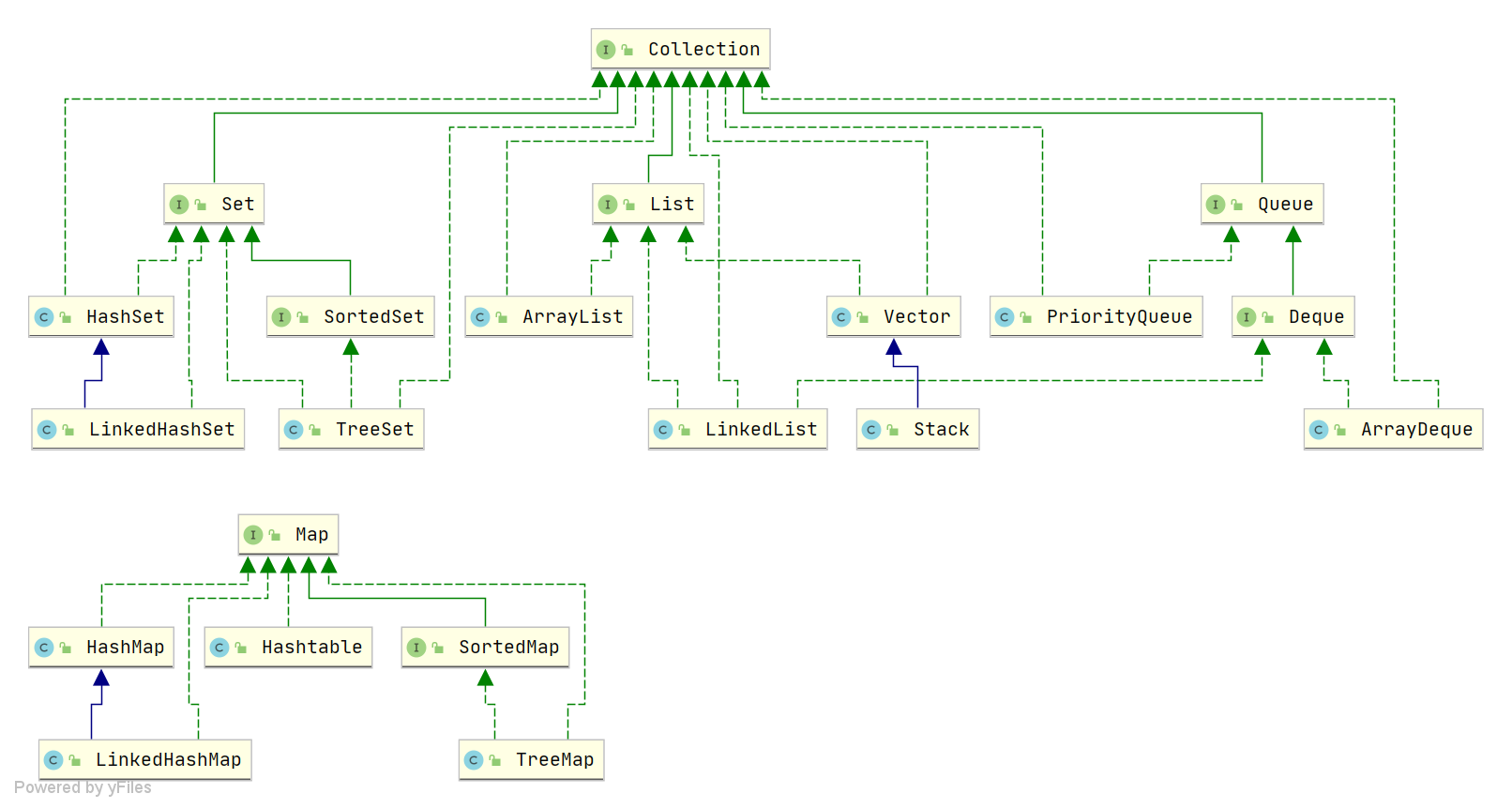
List
这里特性均为 ArrayList
底层数数组:Object[]
新增、查找时间复杂度是 O(1);
指定位置删除、插入,时间复杂度是:O(n-1)
存储有序数据;底层是数组结构;
默认容量 10 ,扩容 1.5 倍;
调用System.copyArray(), copy 源数组到目前数组;
Set
储存无序、不可重复的数据;
HashSet 底层是HashMap, 只不过value 中没有值而已;
Map
HashMap1.7 和1.8 的区别
0) hash方法优化
static final int hash(Object key) {int h;// key.hashCode():返回散列值也就是hashcode// ^ :按位异或// >>>:无符号右移,忽略符号位,空位都以0补齐return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}
1) 1.7 之前是链表+ 数组 , 1.8 是数组+链表+ 红黑树 ;红黑树是在链表长度大于8且 总长度大于 64 时进行的;
链表长度大于8,且长度小于64,增加元素时,首选是扩容;
2) 扩容是 1.7 需要重新计算哈希值, 1.8 不用,进行了优化, 现在位置 + capcity ;
3) 1.7 扩容,头插法 可能导致 环形链表死循环;
1.8 扩容, 尾插法,可能导致 数据覆盖
HashMap 1.8 值覆盖如何产生的?
假设 A、B线程都在进行put 操作,且 Put 的key 的hash 值一样;
A 在执行完成 hash 且完成碰撞检测后,CPU时间片交由B 执行; 此时就会产生覆盖操作;
负载因子为何是0.75
是空间和查询效率的权衡; 负载因子太大,趋近于1 ,空间占用率高,但查询效率低;
HashMap死循环分析
HashMap 之所有在并发下造成死循环,是因为,多个线程并发进行时,
一个线程先完成了扩容,将原先的Map 的链表重新散列到自己的表中,并且链表变成了倒叙,
后一个线程再扩充时,又进行自己的散列,再次将倒叙的列表变成正序。 于是就形成了一个环形链表;
当get 表中不存在的元素时,造成了死循环。
在1.8中,链表扩容转化为红黑树,没有相关的问题;
hashCode 和equals
hashCode() 的作用是获取哈希码,它实际返回一个int 整数。这个哈希码的作用是确定改对象在哈希表中的索引位置; Object 对象中此方法属于native方法;
queals 比较的是 内容是否一致;
public boolean equals(Object obj) {return (this == obj);}
对于HashMap 来说, Key 对象重写 equals ,必须重写 hashcode , 因为先比较的是hashcode
4. 线程
线程生命周期
神马是死锁?
多个线程被同时阻塞,都在等待某一资源被释放;
线程启动为神马不能直接调用run,而是调用start?
run() 方法内容是用户定义的,直接运行的话,就是执行一个普通方法;
start() 方法会做一些线程启动的 准备,比如将线程设置为就绪态,然后调用start0 native 方法启动;
参见:
线程池
5. 参见

若有收获,就点个赞吧
0 人点赞
