开始
本篇文章,我们主要解决以下几个小问题:
test.csv
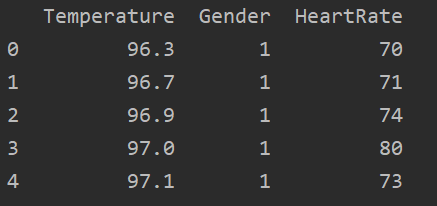
如上图所示:数据源中 test 标签页内,共计有三个字段【Temperature、Gender、HeartRate】,分别代表数据源码中的【人体体温、男女性别(1男2女)、人体心率】,且表格中共计130条数据。
数据处理
使用python代码,进行数据的预处理:
import pandas as pdpath = 'C:/Users/wb-lc576419/Desktop/test.csv'data = pd.read_csv(path)print(data.head())
查看整体的人体体温均值
import pandas as pdpath = 'C:/Users/wb-lc576419/Desktop/test.csv'data = pd.read_csv(path)print(data.mean())
最终,显示如下结果: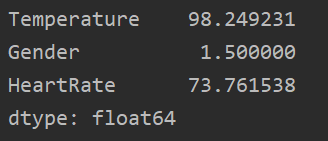
由此可知,整体的人体均值为98.249华氏度,人体心率均值为 73.76
查看人体的温度是否服从正态分布
此时,我们使用 python里面的 scipy 包,来进行KS检验
kstest 是一个很强大的检验模块,除了正态性检验,还能检验 scipy.stats 中的其他数据分布类型
import pandas as pdfrom scipy.stats import kstestpath = 'C:/Users/wb-lc576419/Desktop/test.csv'data = pd.read_csv(path)u =data['Temperature'].mean()std = data['Temperature'].std()ks_test = kstest(data['Temperature'],'norm',(u,std))print(ks_test)
最终,显示如下结果:
输出结果中第一个为统计量,第二个为P值(注:统计量越接近0就越表明数据和标准正态分布拟合的越好,如果P值大于显著性水平,通常是0.05,接受原假设,则判断样本的总体服从正态分布)
查看人体的温度中存在的异常数据有哪些
对于高斯分布的数据来说,68.27%的数据集中在一个标准差的范围内,95.45%在两个标准差的范围内,99.73%在3个标准差的范围内,因此根据这个,和平均值相差3倍标准差的点被看作异常点,但平均值和标准差太容易受异常点干扰,其有限样本击穿点是0%。
有效样本击穿点的定义是一个比例值,对超过这个比例值的的样本进行替换,评估方法将无法进行准确描述,有限样本击穿点越大,代表评估方法越robust。
因此,我们假定人体温度的数值中,和平均值相差3倍标准差的点作为异常数据,并将其输出。
import pandas as pdpath = 'C:/Users/wb-lc576419/Desktop/test.csv'data = pd.read_csv(path)u =data['Temperature'].mean()std = data['Temperature'].std()lower_limit = u-3*stdupper_limit = u+3*stdfor i in data['Temperature']:if i < lower_limit or i > upper_limit:print(i)
最终,显示如下结果:
显然,人体体温中存在的异常数据为 100.8华氏度

若有收获,就点个赞吧
0 人点赞
