将指标时间序列数据和指标对应的测点信息, 设备信息, 案例信息集成在一起放在结构体数组中(struct array), 便于索引.
原始数据举例:
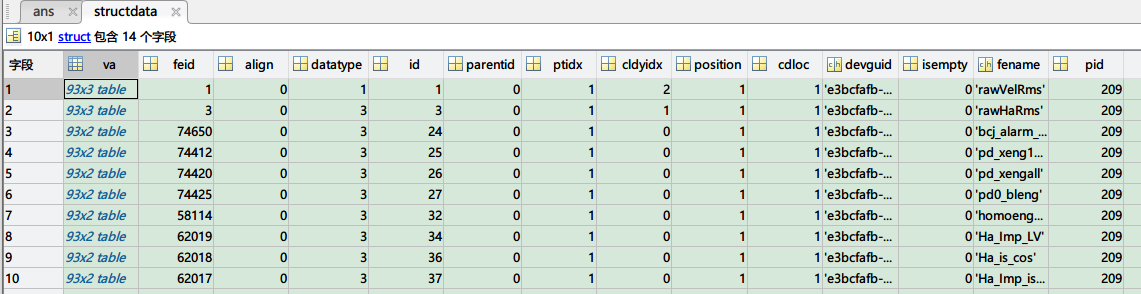
必要field:
va: 是指标时间序列table, 一列时间measdate, 一列measvalue指标值, 其他列为自定义列, 可以将各种中间结果, 比如门限,报警挂在上面. 要求是这些列的元素的个数相同
feid: 指标id
datatype: 父指标的id. 如保持架指标是通过高加波形计算出来的, 他的父指标就是高加总值.
id: 指标在lines中的编号(暂时不使用);
parentid: 暂时不使用
ptidx: 测点序号(第几个测点)
cldyidx: 第几条测量定义计算的当前指标
position: 测点所在部件的测点模型编号
cdloc: 测点所在部件的部件模型编号
devguid: 设备guid. 该指标是哪台监测设备的数据计算的
isempty: va中是否为空.
pid: 指标对应的案例编号
其他field:
fename: 指标名称
Line的实例化
lines=lnfun.Line(structdata); %将structdata包装成Line类.
emptylines=lnfun.Line(); %生成一个空的Line
- structdata里的属性都是lines的动态属性. 如lines.feid
- 原始的结构体数组保存在lines.data中
(注意:避免在变量查看窗口中直接查看lines.data, 会使editor卡顿, 推荐使用lines.view来查看)
Line的筛选
[rst_lines,ia]=lines.select(Name,Value);
[rst_lines,ia]=lines.selectrows(Name,Value); %按一一对应来筛选, 要求value1, value2, value3 寸相同
Description
从lines中选出符合条件的子lines.
Input:
Name,Value 为变参键值对.
- 支持的Name:
- 所有的struct data的属性如feid, fename, datatype, cdloc, cldyidx, position, pid等
- nthpt: 第几个测点
- nthcd: 第几个测点模型
- Value: 1xn 的数组或 1xn 的cell
Output:
rst_lines是筛选出的子lines. ia是子line在原始lines中的序号
Examples:
[line1,ia]=lines.select('nthpt',3,'nthcdloc',4,'feid',[110,111],'fename',{'a','b','c'}
% 筛选lines中的第3个测点, 第4个测点模型下feid=110或111的且femane为a或b或c的子lines
Examples:
[line1,ia]=lines.select('feid',[111,100])
%选出来的lines1的feid是按[111,100]的顺序排列的. 同样也会按照fename的顺序排列
[rst_lines,ia]=lines.selectrows(Name,Value); %按一一对应来筛选, 要求value1, value2, value3 寸相同
Examples:
[line1,ia]=lines.select('ptidx',[1,2,3],'feid',[111,100,102]);
%选出来的lines符合条件ptidx=1且feid=111, ptidx=2且feid=100, ptidx=3且feid=102的子lines
[rst_lines,ia]=lines.view %显示lines的数据简报
Examples:
lines.tojson % 转成json string 的格式
lines.fromjson %从json转成lines
lines转json后, va里的数据会删除. 主要是为了保存测量定义相关索引信息
lines.tojson
ans =
{"va":[],"feid":1,"align":0,"datatype":1,"id":1,"parentid":0,"ptidx":1,"cldyidx":2,"cdloc":1,"devguid":"e3bcfafb-6432-4861-93f5-184fffbe1a56","fename":"rawVelRms","pid":209}
lines.totable %转table, lines.va里的每一个field对应table的一列
lines.totensor(); %待实现
lines.tomatrix(); %转成矩阵
Line的索引操作
Examples: 取lines的各种属性
lines(1).feid
lines(1:3).feid
lines(lines.cdloc==3).fename
lines.feid %取所有lines的feid, 放在数组中输出
Examples:取lines中的指标数据va, va是一个table
lines(i).va.measvalue(dvbin==1)
lines(i).va.measdate
lines(i).va.wid
lines(i).va.bb %va table里的其他列
Line的扩充
Examples:
lines(end+1)=lines(1); %将lines的第一个line,复制一份添加到lines的最后
line3=[line1;line2]; %将lines1和lines2合并
Examples:
%把多台设备的数据, 一起读到一个大的lines里. 当Line结构进行扩增时, 不会因为未预分配内存, 造成速度变慢
for i=1:n
if i==1
z=load([num2str(i),'.mat']);
L=z.lines;
else
L=[L;z.lines];
end
end
Examples:
lines.leftjoin({'feid','cdloc'},{'shortid'},feidmap); %将lines和feidmap这个table进行左连接, 给lines扩字段
Line的生成
Examples:
newline=oldline.new(struct_data) %将oldline中的va清空, 用struct_data填充, 返回给newline
Line的赋值
Examples:
lines(1).feid=1
lines(1:2).feid=1 % 把lines中的第一个和第二个line的feid都赋值为1
lines(1:2).feid=1:2 % 把lines中的第一个line的feid赋值1, 第二个line的feid赋值为2
lines(1).va.measvalue=1;
lines(end+1)=lines(1)
lines(1:3).fename='dd';
lines(1:3).fename={'dd','aa','cc'};
L.label=table(rand(10,1),rand(10,1)); % lines中增加一个字段, 且值为table.
Line的va操作/其他表格类数据的操作
lines(1).va.wv(:,1)=wvs % line.va里新增一个column
lines(1).label(:,:)=[] % line.label这个自定义字段的表格清空
Line的属性获取
Examples:
lines.fieldnames %line中有哪些字段
lines.len
lines.ptnum %获取lines中的测点数量.
lines.uniptidx %获取lines中所有的ptidx的去重的结果
lines.unicdloc %获取lines中所有的cdloc的去重的结果
Examples:
lines.data % 隐藏属性,
避免在变量查看窗口看原始的struct 数据, 会导致matlab非常卡
Line的数据操作
I=lines.sort(sortkey,sortdirection); %将lines排序
sortkey : 1xn cells 或者 array.
sortdirection: 1xn array, 排序方向, 升序(1), 降序(2)
Examples:
newlines=lines.sort({'feid','cdloc'},[1,2]);
lines.convert_feid_to_fename(fenametb)
查找lines中的feid, 将fenametb表格里的fename填充回lines
lines.convert_feid_to_fename()
如果不给定fenametb, 将从缺省位置读取fename table
[tSyncTime,obj]=lines.syncronize(tSyncTime,allowSynWin,minSampleInterval,isFillMissing)
Examples:
lines.syncronize(t_reference,minutes(30)/days(1),minutes(5)/days(1),0);
将lines中的数据同步, 按照t_reference作为基准同步时刻. 最小同步时间5分钟. 最大同步时间30分钟
Examples:
[tsync]=lines.syncronize([],minutes(30)/days(1),minutes(5)/days(1),0);
将lines中的数据同步, 最小同步时间5分钟. 最大同步时间30分钟
GUI操作
TrendViewer(lines);
New Feature
按照过滤条件批量处理lines中的va table.
% 批量va索引, 便于多指标的协同过滤, 如剔除误信号波形对应提取的指标.
L % lnfun.Line data: size(3x1)
L.va(1:10,:) % 依次对L的每一个lines中的va里面的table, 索引1:10行, 再包在cell里返回
ans =
1×3 cell 数组
{10×3 table} {10×3 table} {10×3 table}
% 批量va赋值
L.va=L.va(1:10,:);
创建一个lines的拷贝.
newline=lines.copy; %拷贝一个new line.
lines中添加一个表格字段
L.label=table(rand(10,1),rand(10,1)); % lines中增加一个字段, 且值为table.
L.label(:,:)=[] % line.label这个自定义字段的表格清空
将lines中的趋势数据批量打印成图片. (支持并行, 自定义布局和绘图函数)
lnfun.print_to_png(L,"enableParallel",1,"layout",[3,4],"trendplot_fcn",@my_trend_plot);

若有收获,就点个赞吧
0 人点赞
