前面我们学习了线程隔离和信号量的理论知识,同学们有没有身体力行,试着去做一个小项目落地呢?这一小节,我们将介绍一个Hystrix的好搭档,Turbine聚合服务。
同学们知道每年双11的销量统计是从哪里来的吗?那就听老师给大家讲讲六大门派围攻光明顶的故事。
每年的双11是阿里全公司上下的一场大会战,最高作战指挥部就是一间叫“光明顶”的大会议室。里面坐着各门派的掌门和长老们(偶尔也有厉害的小杂兵),他们两眼直勾勾的盯着一块大屏幕,屏幕上是当天双11的实时成交额,各路剁手的亲们就像围攻光明顶的六大派,不断推高这个数字。
那我们光明顶上的屏幕是实时从数万个服务节点拉取信息吗?我们来看看屏幕背后的服务做了哪两件事:
- 聚合信息:双11各路服务节点数量庞大,我们需要有一个机制来汇总每个节点的成交额信息,把成交信息聚合到一个点,并且这个聚合操作又不能影响到主链路。
- 大盘展示:有了聚合信息,接下来就要构建一个大盘,只从聚合后的单点位置拉取数据然后展示出来。
可见这个监控大盘并不负责聚集成交数据,而是依靠某种后台的机制将信息聚集在一点,大盘只要展示就好了。我们如果想监控Hystrix的实时状态,知晓服务熔断、异常的数量变化,也可以通过这种先聚合信息后大盘展示的方法来做。
今天我们可以一同去Hystrix的光明顶Turbine走一走看一看。
聚沙成塔 - Turbine收集器
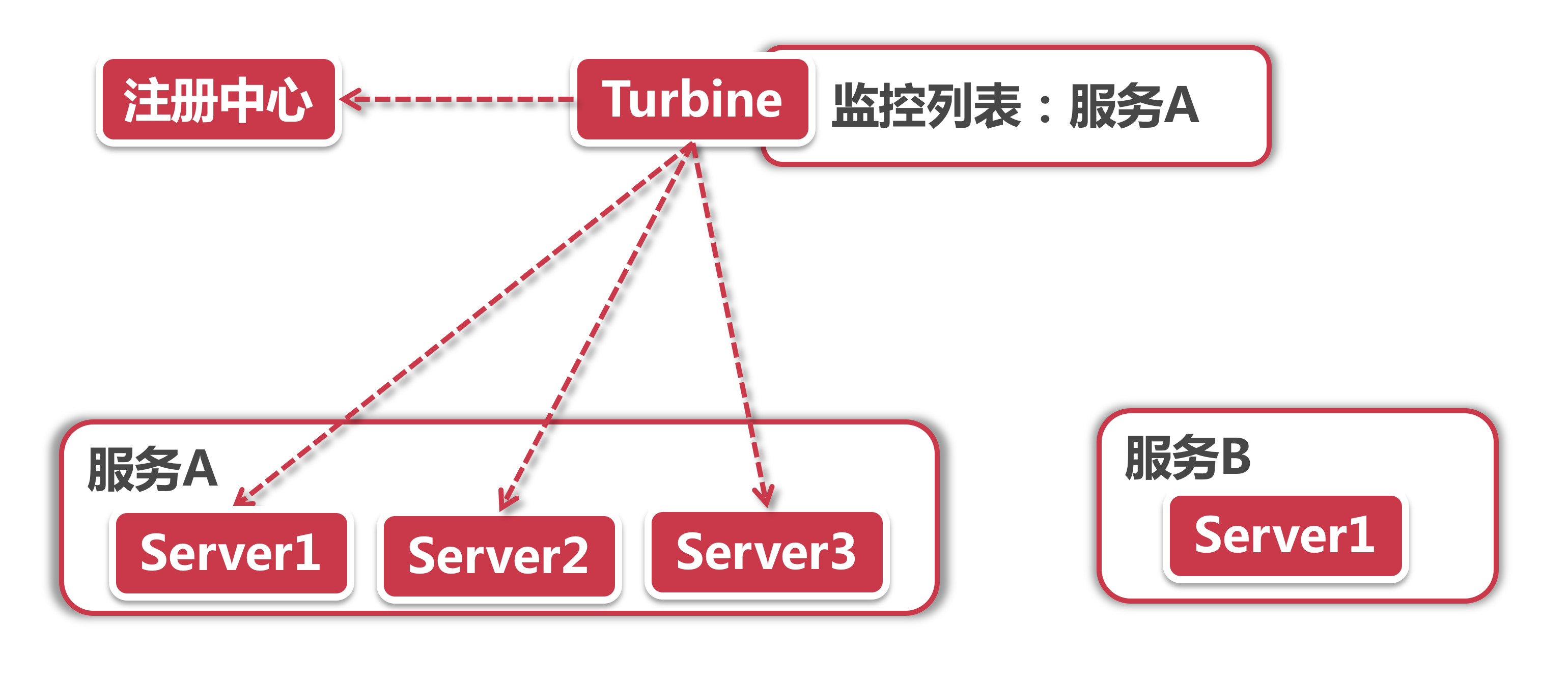
Turbine其实也是一个服务节点,它正是借助Eureka的服务发现来完成信息聚合的。
- 配置监控服务和集群:在Turbine里我们需要配置目标服务,也就是需要Turbine实时监控的服务名称。如果应用的部署结构比较复杂,比如说分了几个大集群,这时一个Turbine节点可能就无法监管这么多的服务节点了。我们可以启用多个Turbine聚合服务,每个服务指定一个集群,用来聚合这个集群下所有服务节点的Hystrix状态。在默认单cluster的部署结构下,Turbine默认监管default cluster(课程也是采用默认配置)。
- 服务发现:连接Eureka注册中心,利用服务发现机制拉取服务节点列表,从中找到上一步中配置的指定服务都有哪些服务节点。
- 聚合信息:这一步聚合操作是Turbine的核心功能,它并不是让各个服务节点把自己的信息上报给Turbine,因为对服务节点来说它们并不知道自己是否在Turbine的监控名单上。这一步其实是由Turbine主动发起的,从服务节点的指定”/actuator”路径下的Hystrix监控接口获取信息。
如果客户端集成了Hystrix,可以在“/actuator”服务中找到Hystrix的healthcheck url,Turbine正是从这个url获取Hystrix当前状态。
监控大盘

有料就要show出来,后台服务再牛,不叫人看到也没用。Hystrix提供了一个监控大盘的服务叫Dashboard,可以简单地通过@EnableHystrixDashboard注解直接开启,它会采用图形化的方式将每个服务的运行状态显示出来,它提供了两个维度的监控:
- 单一节点监控:通过直接访问服务节点的“/actuator”接口,获取当前节点的Hystrix监控信息。
- Turbine聚集信息监控:通过访问Turbine服务的“/actuator”接口,获取经过聚合后的Hystrix监控信息。
通过大盘监控,我们就可以实时掌握服务的健康度状态,知晓哪些服务正处于熔断状态,以便及时排查问题。
小结
这一节我们学习了如何使用Turbine聚集Hystrix监控信息,并展示在大盘上。下一节我就带大家手把手去创建一个Turbine服务,然后开启监控大盘。
学习Tips:在工作里,会做和会show都是很重要的技能。很多研发人员沉浸在埋头做事情中,忽略了拓展自己的影响力。正所谓千里马常有而伯乐不常有,一个比较现实的情况就是,老板不在乎你“做”的过程,你也不能期望别人主动发现你的才能,我们要花点心思让自己的努力可以被其他人知道。这不是说溜须拍马,而是一个“销售”自己,推广自己的机会,越往上这个能力越重要。

若有收获,就点个赞吧
0 人点赞
