Shenandoah
厂商:RedHat,贡献给了OpenJDK
定位:低延迟垃圾收集器
状态:实验性
限制:Oracle JDK无法使用
适用版本:详见 https://wiki.openjdk.java.net/display/shenandoah
网址:https://wiki.openjdk.java.net/display/shenandoah
和G1对比,相同点:
- 基于Region的内存布局
- 有用于存放大对象的Humongous Region
- 回收策略也同样是优先处理回收价值最大的Region
和G1对比,不同点:
- 并发的整理算法
- Shenandoah默认是不使用分代收集的
- 解决跨region引用的机制不同,G1主要基于Rememberd Set、CardTable,而Shenandoah是基于连接矩阵(Connection Matrix)去实现的。
启用参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
适用场景:
- 低延迟、响应快的业务场景
工作步骤:
- 初始标记(Initial Marking):与G1一样,首先标记与GC Roots直接关联的对象,存在Stop The World
- 并发标记(Concurrent Marking)与G1一样,标记出全部可达的对象,该阶段并发执行,无Stop The World
- 最终标记(Final Marking)统计出回收价值最高的Region、构建回收集(Collection Set)。存在Stop The World
- 并发清理(Concurrent Cleanup)用于清理那些整个区域内连一个存活对象都没有找到的Region(这类Region被称为Immediate Garbage Region)
- 并发回收(Concurrent Evacuation)并发回收阶段是Shenandoah与之前HotSpot中其他收集器的核心差异。在这个阶段,Shenandoah要把回收集里面的存活对象先复制一份到其他未被使用的Region之中。复制对象这件事情如果将用户线程冻结起来再做那是相当简单的,但如果两者必须要同时并发进行的话,就变得复杂起来了。其困难点是在移动对象的同时,用户线程仍然可能不停对被移动的对象进行读写访问,移动对象是一次性的行为,但移动之后整个内存中所有指向该对象的引用都还是旧对象的地址,这是很难一瞬间全部改变过来的。对于并发回收阶段遇到的这些困难,Shenandoah将会通过读屏障和被称为“Brooks Pointers”的转发指针来解决。并发回收阶段运行的时间长短取决于回收集的大小。
- 初始引用更新(Initial Update Reference)并发回收阶段复制对象结束后,还需要把堆中所有指向旧对象的引用修正到复制后的新地址,这个操作称为引用更新。引用更新的初始化阶段实际上并未做什么具体的处理,设立这个阶段只是为了建立一个线程集合点,确保所有并发回收阶段中进行的收集器线程都已完成分配给它们的对象移动任务而已。初始引用更新时间很短,会产生一个非常短暂的停顿。
- 并发引用更新(Concurrent Update Reference)真正开始进行引用更新操作,这个阶段是与用户线程一起并发的,时间长短取决于内存中涉及的引用数量的多少。主要是按照内存物理地址的顺序,线性地搜索出引用类型,把旧值改为新值即可。
- 最终引用更新(Final Update Reference)解决了堆中的引用更新后,还要修正存在于GC Roots中的引用。这个阶段是Shenandoah的最后一次停顿,停顿时间只与GC Roots的数量相关
- 并发清理(Concurrent Cleanup)经过并发回收和引用更新之后,整个回收集中所有的Region已再无存活对象,这些Region都变成Immediate Garbage Regions了,最后再调用一次并发清理过程来回收这些Region的内存空间,供以后新对象分配使用
TIPS
步骤较多,重点是:并发标记、并发回收、并发引用更新这三个阶段。
性能表现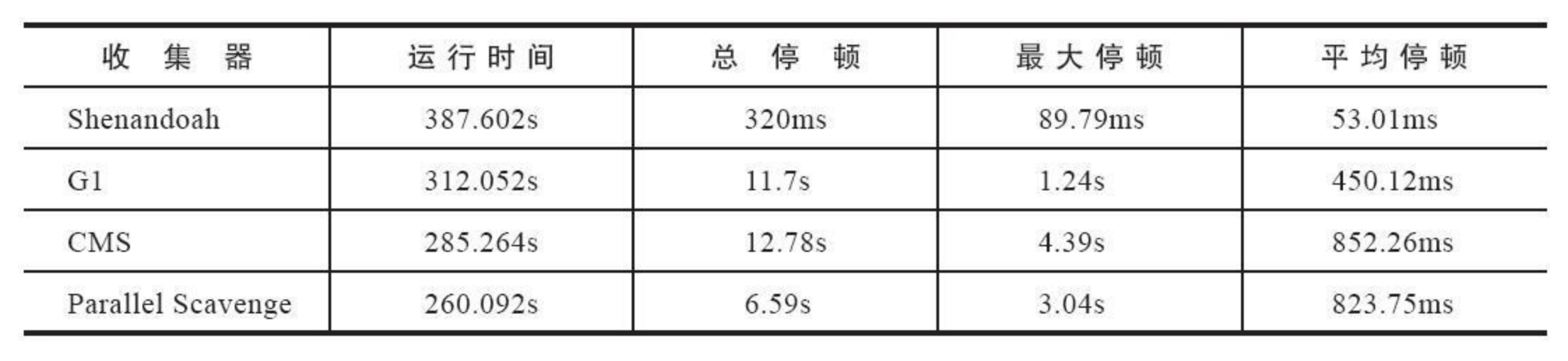
ZGC
厂商:Oracle
定位:低延迟垃圾收集器
状态:实验性
限制:JDK14之前,无法在Windows、macOS机器上使用,每个版本的特性解介绍详见:https://wiki.openjdk.java.net/display/zgc/Main
核心技术:染色指针技术
适用场景:
- 低延迟、响应快的业务场景
启用参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
内存布局:
- ZGC也采用基于Region的堆内存布局,但与它们不同的是,ZGC的Region(在一些官方资料中将它称为Page或者ZPage,本章为行文一致继续称为Region)具有动态性,可以动态创建和销毁,以及动态的区域容量大小。region的容量:
- 小型Region(Small Region):容量固定为2MB,用于放置小于256KB的小对象。
- 中型Region(Medium Region):容量固定为32MB,用于放置大于等于256KB但小于4MB的对象。
- 大型Region(Large Region):容量不固定,可以动态变化,但必须为2MB的整数倍,用于放置4MB或以上的大对象。每个大型Region中只会存放一个大对象,这也预示着虽然名字叫作“大型Region”,但它的实际容量完全有可能小于中型Region,最小容量可低至4MB。大型Region在ZGC的实现中是不会被重分配(重分配是ZGC的一种处理动作,用于复制对象的收集器阶段,稍后会介绍到)的,因为复制一个大对象的代价非常高昂
工作步骤:
- 并发标记(Concurrent Mark):与G1、Shenandoah一样,并发标记是遍历对象图做可达性分析的阶段,前后也要经过类似于G1、Shenandoah的初始标记、最终标记(尽管ZGC中的名字不叫这些)的短暂停顿,而且这些停顿阶段所做的事情在目标上也是相类似的。与G1、Shenandoah不同的是,ZGC的标记是在指针上而不是在对象上进行的,标记阶段会更新染色指针中的Marked 0、Marked 1标志位。
- 并发预备重分配(Concurrent Prepare for Relocate):这个阶段需要根据特定的查询条件统计得出本次收集过程要清理哪些Region,将这些Region组成重分配集(Relocation Set)。重分配集与G1收集器的回收集(Collection Set)还是有区别的,ZGC划分Region的目的并非为了像G1那样做收益优先的增量回收。相反,ZGC每次回收都会扫描所有的Region,用范围更大的扫描成本换取省去G1中记忆集的维护成本。因此,ZGC的重分配集只是决定了里面的存活对象会被重新复制到其他的Region中,里面的Region会被释放,而并不能说回收行为就只是针对这个集合里面的Region进行,因为标记过程是针对全堆的。此外,在JDK 12的ZGC中开始支持的类卸载以及弱引用的处理,也是在这个阶段中完成的。
- 并发重分配(Concurrent Relocate):重分配是ZGC执行过程中的核心阶段,这个过程要把重分配集中的存活对象复制到新的Region上,并为重分配集中的每个Region维护一个转发表(Forward Table),记录从旧对象到新对象的转向关系。
- 并发重映射(Concurrent Remap):重映射所做的就是修正整个堆中指向重分配集中旧对象的所有引用,这一点从目标角度看是与Shenandoah并发引用更新阶段一样的,但是ZGC的并发重映射并不是一个必须要“迫切”去完成的任务,因为前面说过,即使是旧引用,它也是可以自愈的,最多只是第一次使用时多一次转发和修正操作。
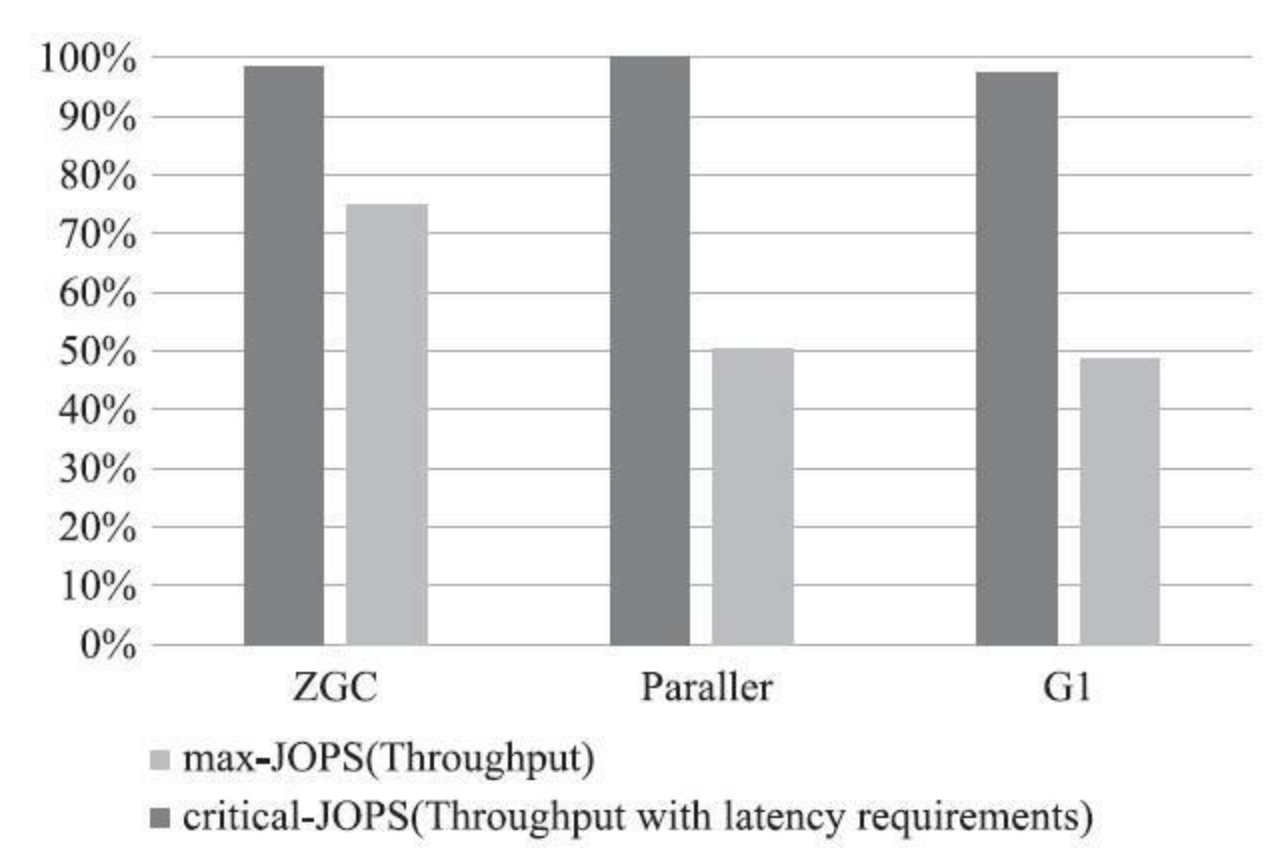
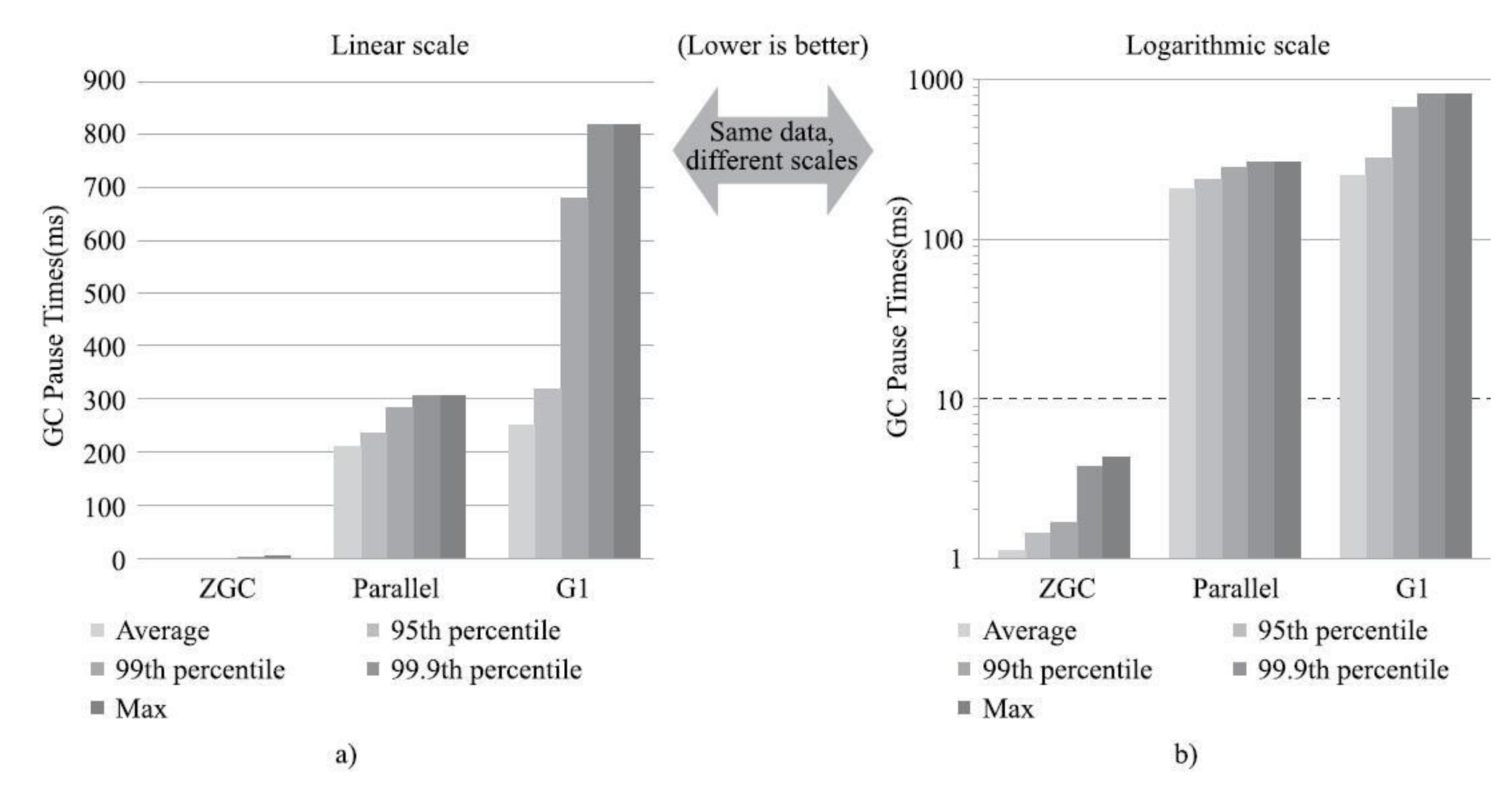
Epsilon
Epsilon(A No-Op Garbage Collector)垃圾回收器控制内存分配,但是不执行任何垃圾回收工作。一旦java的堆被耗尽,jvm就直接关闭。设计的目的是提供一个完全消极的GC实现,分配有限的内存分配,最大限度降低消费内存占用量和内存吞吐时的延迟时间。一个好的实现是隔离代码变化,不影响其他GC,最小限度的改变其他的JVM代码。
定位:不干活儿的垃圾收集器
状态:实验性
启用参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC
适用场景:
- Performance testing,什么都不执行的GC非常适合用于差异性分析。no-op GC可以用于过滤掉GC诱发的新能损耗,比如GC线程的调度,GC屏障的消耗,GC周期的不合适触发,内存位置变化等。此外有些延迟者不是由于GC引起的,比如scheduling hiccups, compiler transition hiccups,所以去除GC引发的延迟有助于统计这些延迟。
- Memory pressure testing, 在测试java代码时,确定分配内存的阈值有助于设置内存压力常量值。这时no-op就很有用,它可以简单地接受一个分配的内存分配上限,当内存超限时就失败。例如:测试需要分配小于1G的内存,就使用-Xmx1g参数来配置no-op GC,然后当内存耗尽的时候就直接crash。
- VM interface testing, 以VM开发视角,有一个简单的GC实现,有助于理解VM-GC的最小接口实现。它也用于证明VM-GC接口的健全性。
- Extremely short lived jobs, 一个短声明周期的工作可能会依赖快速退出来释放资源,这个时候接收GC周期来清理heap其实是在浪费时间,因为heap会在退出时清理。并且GC周期可能会占用一会时间,因为它依赖heap上的数据量。
- Last-drop latency improvements, 对那些极端延迟敏感的应用,开发者十分清楚内存占用,或者是几乎没有垃圾回收的应用,此时耗时较长的GC周期将会是一件坏事。
Last-drop throughput improvements, 即便对那些无需内存分配的工作,选择一个GC意味着选择了一系列的GC屏障,所有的OpenJDK GC都是分代的,所以他们至少会有一个写屏障。避免这些屏障可以带来一点点的吞吐量提升。
参考文档
周志明《深入理解Java虚拟机》
- https://www.jianshu.com/p/a06c8e9e7931

若有收获,就点个赞吧
0 人点赞
