cpu高速缓存
由于CPU的读写速度远高于主内存,所以为了提高效率,在CPU和主存之间设置了高速缓存,常见的为三级缓存结构。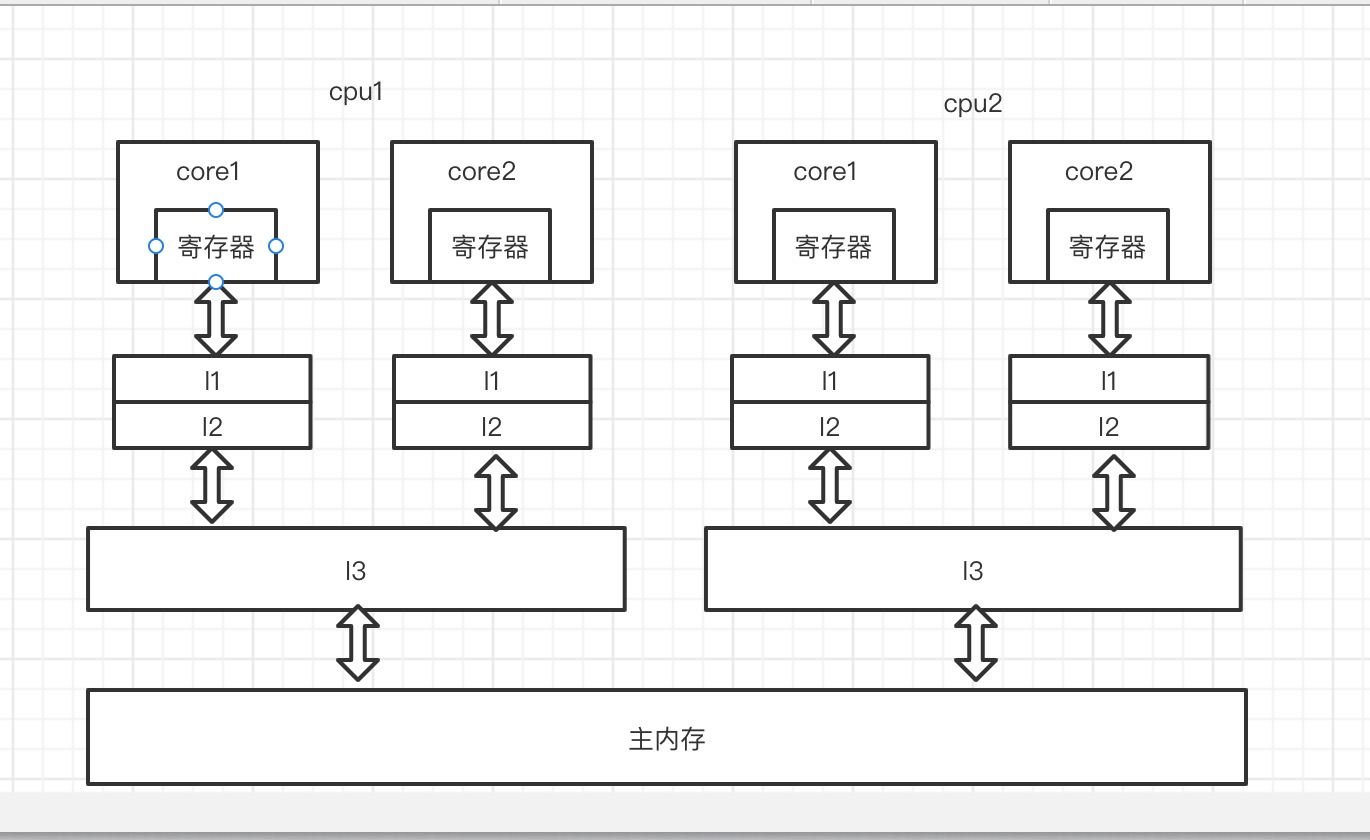
缓存一致性问题
上图可以看到,每个处理器都有独立的本地缓存,在多处理系统中就会存在缓存一致性问题. 要解决这个问题,就要确保共享操作数(数据)值的变化能够及时地 在整个系统中传播。
理论机制
处理器会自动保证基本的内存操作的原子性,但是无法保证操作对象所在内存区域跨多个缓存行、跨页表的访问的原子性。
(复杂内存操作示例:32系统在处理Long类型(64位)的时候无法保证原子性)
处理器提供两个机制来保证复杂内存操作的原子性。
(1)总线锁定
一个处理器工作时,会阻止了其他处理器和所有内存之间的通信。所有处理器对内存的访问以串行化的方式来执行,效率低
(2)缓存锁定
缓存锁定是指操作的数据内存区域被缓存在处理器的单个缓存行中,但是当操作的数据跨多个缓存行时,则处理器会调用总线锁定。
MESI协议是常用的缓存一致性协议,有4个状态:
Modified(被修改)Exclusive(独占的) Shared(共享的) Invalid(无效的)
基本思想是在 CPU 执行代码期间,会发出信号通知其他 CPU 自己正在修改共享变量,并回写到主存;其他 CPU 收到通知后就会把自己的共享变量置为无效状态,去读取回写到主存的值
伪共享问题:
因为缓存锁定的是缓存行,缓存行可能有多个变量,如果多个核的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效,即使在代码层面看这两个线程操作的数据之间完全没有关系。这种不合理的资源竞争情况就是伪共享(False Sharing)。
避免伪共享方案 :1.缓存行填充 2.使用 @sun.misc.Contended 注解(java8)
硬件层的实现
硬件层提供了一系列的内存屏障 memory barrier / memory fence(Intel的提法)来提供 一致性的能力。
内存屏障有两个能力: 1. 阻止屏障两边的指令重排序 2. 刷新处理器缓存/冲刷处理器缓存
拿X86架构来说,有几种主要的内存屏障:
1. lfence,是一种Load Barrier 读屏障
在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主 内存加载数据;
2. sfence, 是一种Store Barrier 写屏障
在写指令之后插入写屏障,能让写入缓存的最新数据写 回到主内存
3. mfence, 是一种全能型的屏障,具备lfence和sfence的能力
4. Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能
Lock前缀实现了类似的能力,它先对总线和缓存加锁,然后执行后面的指令,最后释放锁 后会把高速缓存中的数据刷新回主内存。在Lock锁住总线的时候,其他CPU的读写请求都会被 阻塞,直到锁释放。
备注:中央处理单元(CPU)主要由运算器、控制器、寄存器三部分组成,
X86,ARM是cpu的不同架构
X86和ARM处理器的第一个区别是,前者使用复杂指令集(CISC),而后者使用精简指令集(RISC)
JMM对可见性的保障
as-if-serial
as-if-serial指的是 即使编译器和处理器为了提高并行度会进行重排序优化,但是单线程程序的执行结果不能被改变。
happens-before
happens-before指的是 多线程程序如果操作A 发生在操作B之前,Java内存模型将向程序员保证A 操作的结果将对B可见,且A的执行顺序排在B之前。允许重排序,但是要保证最终结果满足上述要求。
程序员的判读标准:
不满足上述标准的就会存在可见性问题
实现:
jvm编译class文件成为汇编语言、硬件层面的处理器处理汇编语言成为机器码 都可能会对指令进行重排序
JVM层面的内存屏障能够影响上面两种排序符合as-if-serial、happens-before的理论:
StoreLoad屏障:(指令Store1; StoreLoad; Load2)在Load2及后续所有读取操作执行 前,保证Store1的写入对所有处理器可见。
有序性和可见性是相关联的。
java编码层面:
volatile实现了原子性,实现方式就是用了内存屏障

若有收获,就点个赞吧
0 人点赞
