Disruptor实现了队列的功能并且是一个有界队列,可以用于生产者-消费者模型.
设计的原因:
juc下面有堵塞队列了,为什么还要设计Disruptor呢?
Disruptor是高性能的内存队列,juc包下堵塞队列的问题如下,以至于性能没那么高
- juc下的队列大部分采用加ReentrantLock锁方式保证线程安全。在稳定性要求特别高的系统
中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列。 - 加锁的方式通常会严重影响性能。线程会因为竞争不到锁而被挂起,等待其他线程释放锁而唤
醒,这个过程存在很大的开销,而且存在死锁的隐患。 - 有界队列通常采用数组实现。但是采用数组实现又会引发另外一个问题false sharing(伪
共享)。
设计方案:
(1)环形数组结构 RingBuffer
选择数组的原因:数组占用的内存空间连续,相对链表能加快垃圾回收,同时,数组对处理器的缓存机制更加友好(空间局 部性原理:高速缓存会缓存附近位置,之后用到就不用读主存)。
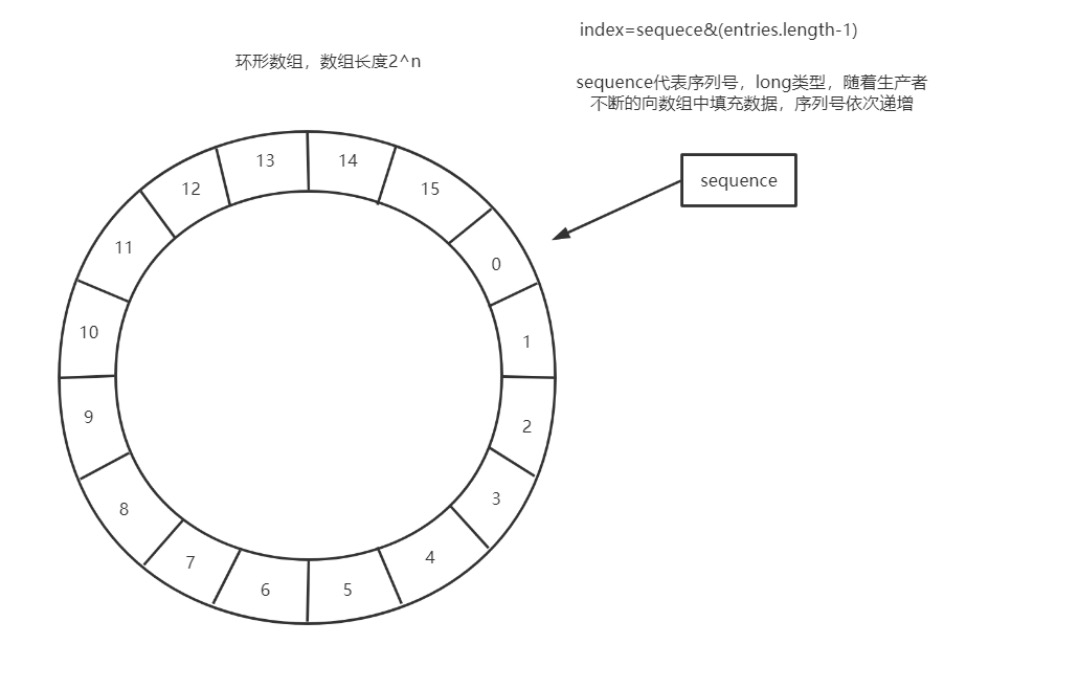
Disruptor要求设置数组长度为2的n次幂。在知道索引(index)下标的情况下,存与 取数组上的元素时间复杂度只有O(1),而这个index我们可以通过序列号与数组的长 度取模来计算得出,index=sequence % entries.length。这里用到用位运算来计算效 率更高,此时array.length必须是2的幂次方,index=sequece&(entries.length-1) 。 (序列号(sequence),用以指向下一个可用的元素)
当所有位置都放满了,再放下一个时,就会出现覆盖问题,导致数据丢失,如何避免呢
Disruptor给提供多种策略,比较常用的:
- BlockingWaitStrategy策略,常见且默认的等待策略,当这个队列里满了,不执行 覆盖,而是阻塞等待。使用ReentrantLock+Condition实现阻塞,最节省cpu,但高并发 场景下性能最差。适合CPU资源紧缺,吞吐量和延迟并不重要的场景
- SleepingWaitStrategy策略,会在循环中不断等待数据。先进行自旋等待如果不成 功,则使用Thread.yield()让出CPU,并最终使用LockSupport.parkNanos(1L)进行线程休 眠,以确保不占用太多的CPU资源。因此这个策略会产生比较高的平均延时。典型的应用 场景就是异步日志。
- YieldingWaitStrategy策略,这个策略用于低延时的场合。消费者线程会不断循环监 控缓冲区变化,在循环内部使用Thread.yield()让出CPU给别的线程执行时间。如果需要一个高性能的系统,并且对延时比较有严格的要求,可以考虑这种策略。
- BusySpinWaitStrategy策略: 采用死循环,消费者线程会尽最大努力监控缓冲区的 变化。对延时非常苛刻的场景使用,cpu核数必须大于消费者线程数量。推荐在线程绑定到 固定的CPU的场景下使用
(2)无锁设计 CAS
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接 在该位置写入或者读取数据。
(3)利用缓存行填充解决了伪共享的问题
(4)实现了基于事件驱动的生产者消费者模型(观察者模式)
消费者时刻关注着队列里有没有消息,一旦有新消息产生,消费者线程就会立刻把它消费

若有收获,就点个赞吧
0 人点赞
