Collections.synchronizedList
摘要: 详细的解析:Collections.synchronizedList
- 关注要点,为什么在有synchroniezed方法的同时会出现 Collections.synchronizedList
- 知识背景: 您可能需要了解java Synchronized方法的加锁的各种机制,包括如何上锁,锁对象
- plus: 您需要不断的深化 Java加锁的各种机制
@NotThreadSafeclass BadListHelper <E> {public List<E> list = Collections.synchronizedList(new ArrayList<E>());public synchronized boolean putIfAbsent(E x) {boolean absent = !list.contains(x);if (absent)list.add(x);return absent;}}
这个示例希望实现的功能是为List提供一个原子操作:若没有则添加。因为ArrayList本身不是线程安全的,所以通过集合Collections.synchronizedList将其转换为一个线程安全的类,然后通过一个辅助的方法来为List实现这么个功能。初看起来这个方法没问题,因为也添加了synchronized关键字实现加锁了。
但是仔细分析,你会发现问题。首先对于synchronized关键字,需要说明的是,它是基于当前的对象来加锁的,上面的方法也可以这样写:
public boolean putIfAbsent(E x) {synchronized(this) {boolean absent = !list.contains(x);if (absent)list.add(x);return absent;}}
所以这里的锁其实是BadListHelper对象, 而可以肯定的是Collections.synchronizedList返回的线程安全的List内部使用的锁绝对不是BadListHelper的对象,应为你在声明和初始化这个集合的过程之中,你尚且都不知道这个对象的存在。所以BadListHelper中的putIfAbsent方法和线程安全的List使用的不是同一个锁,因此上面的这个加了synchronized关键字的方法依然不能实现线程安全性。
下面给出书中的另一种正确的实现:
@ThreadSafeclass GoodListHelper <E> {public List<E> list = Collections.synchronizedList(new ArrayList<E>());public boolean putIfAbsent(E x) {synchronized (list) {boolean absent = !list.contains(x);if (absent)list.add(x);return absent;}}}
如果你要分析这个实现是否正确,你需要搞清楚Collections.synchronizedList返回的线程安全的List内部使用的锁是哪个对象,所以你得看看Collections.synchronizedList这个方法的源码了。该方法源码如下:
public static <T> List<T> synchronizedList(List<T> list) {return (list instanceof RandomAccess ?new SynchronizedRandomAccessList<T>(list) :new SynchronizedList<T>(list));}
通过源码,我们还需要知道ArrayList是否实现了RandomAccess接口:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
查看ArrayList的源码,可以看到它实现了RandomAccess,所以上面的synchronizedList放回的应该是SynchronizedRandomAccessList的实例。接下来看看SynchronizedRandomAccessList这个类的实现:
static class SynchronizedRandomAccessList<E> extends SynchronizedList<E> implements RandomAccess {SynchronizedRandomAccessList(List<E> list) {super(list);}SynchronizedRandomAccessList(List<E> list, Object mutex) {super(list, mutex);}public List<E> subList(int fromIndex, int toIndex) {synchronized(mutex) {return new SynchronizedRandomAccessList<E>(list.subList(fromIndex, toIndex), mutex);}}static final long serialVersionUID = 1530674583602358482L;private Object writeReplace() {return new SynchronizedList<E>(list);}}
因为SynchronizedRandomAccessList这个类继承自SynchronizedList,而大部分方法都在SynchronizedList中实现了,所以源码中只包含了很少的方法,但是通过subList方法,我们可以看到这里使用的锁对象为mutex对象,而mutex是在SynchronizedCollection类中定义的,所以再看看SynchronizedCollection这个类中关于mutex的定义部分源码:
static class SynchronizedCollection<E> implements Collection<E>, Serializable {private static final long serialVersionUID = 3053995032091335093L;final Collection<E> c; // Backing Collectionfinal Object mutex; // Object on which to synchronizeSynchronizedCollection(Collection<E> c) {if (c==null)throw new NullPointerException();this.c = c;mutex = this;}SynchronizedCollection(Collection<E> c, Object mutex) {this.c = c;this.mutex = mutex;}}
可以看到mutex就是当前的SynchronizedCollection对象,而SynchronizedRandomAccessList继承自SynchronizedList,SynchronizedList又继承自SynchronizedCollection,所以SynchronizedRandomAccessList中的mutex也就是SynchronizedRandomAccessList的this对象。所以在GoodListHelper中使用的锁list对象,和SynchronizedRandomAccessList内部的锁是一致的,所以它可以实现线程安全性。
class BadListHelper <E> {public List<E> list = Collections.synchronizedList(new ArrayList<E>());public synchronized boolean putIfAbsent(E x) {boolean absent = !list.contains(x);if (absent)list.add(x);return absent;}}
putIfAbsent方法和List并不是使用的同一个锁对象,List使用的锁对象并不是BadListHelper,而是list。假如A线程进入putIfAbsent方法,list这个锁并没有被获取(A线程获取的是 BadListHelper这个对象),所以其他线程还能够获得list锁对象来改变list对象。boolean absent = !list.contains(x);当线程到这串代码结束时,其他线程获得list锁对象,从而就能调用list的方法来改变list对象,这时候就可能导致!list.contains(x)改变,即域absent并不是A线程得到的布尔类型。所以这个类并不是线程安全的。
获得变量的锁就可以改变变量,没有获得变量锁的就不能改变,获得方法的锁就可以执行方法里面的语句。
一 JDK 提供的并发容器总结
JDK提供的这些容器大部分在 java.util.concurrent 包中。
- ConcurrentHashMap: 线程安全的HashMap
- CopyOnWriteArrayList: 线程安全的List,在读多写少的场合性能非常好,远远好于Vector.
- ConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,这是一个非阻塞队列。
- BlockingQueue: 这是一个接口,JDK内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
- ConcurrentSkipListMap: 跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
二 ConcurrentHashMap
ConcurrentHashMap 同样也分为 1.7 、1.8 版,两者在实现上略有不同。
Base 1.7
先来看看 1.7 的实现,下面是他的结构图: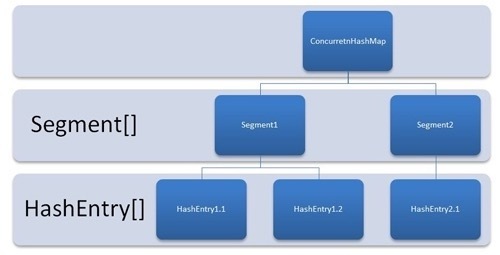
如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
它的核心成员变量:
/*** Segment 数组,存放数据时首先需要定位到具体的 Segment 中。*/final Segment<K,V>[] segments;transient Set<K> keySet;transient Set<Map.Entry<K,V>> entrySet;
Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {private static final long serialVersionUID = 2249069246763182397L;// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶transient volatile HashEntry<K,V>[] table;transient int count;transient int modCount;transient int threshold;final float loadFactor;}
看看其中 HashEntry 的组成: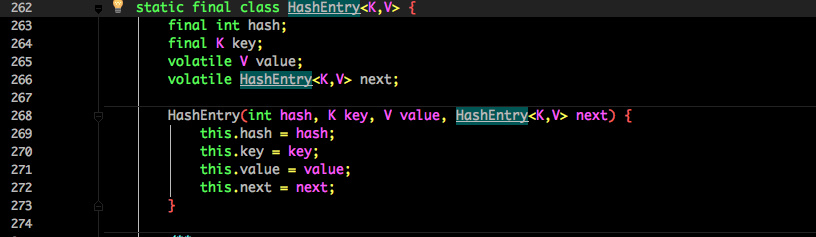
和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
下面也来看看核心的 put get 方法。
put 方法
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();int hash = hash(key);int j = (hash >>> segmentShift) & segmentMask;if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);return s.put(key, hash, value, false);}
首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。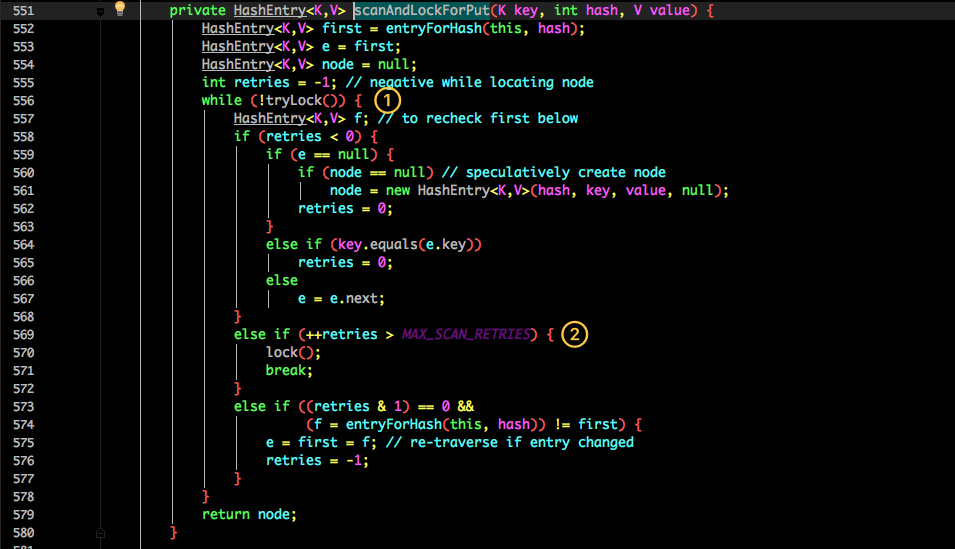
- 尝试自旋获取锁。
- 如果重试的次数达到了
MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功。
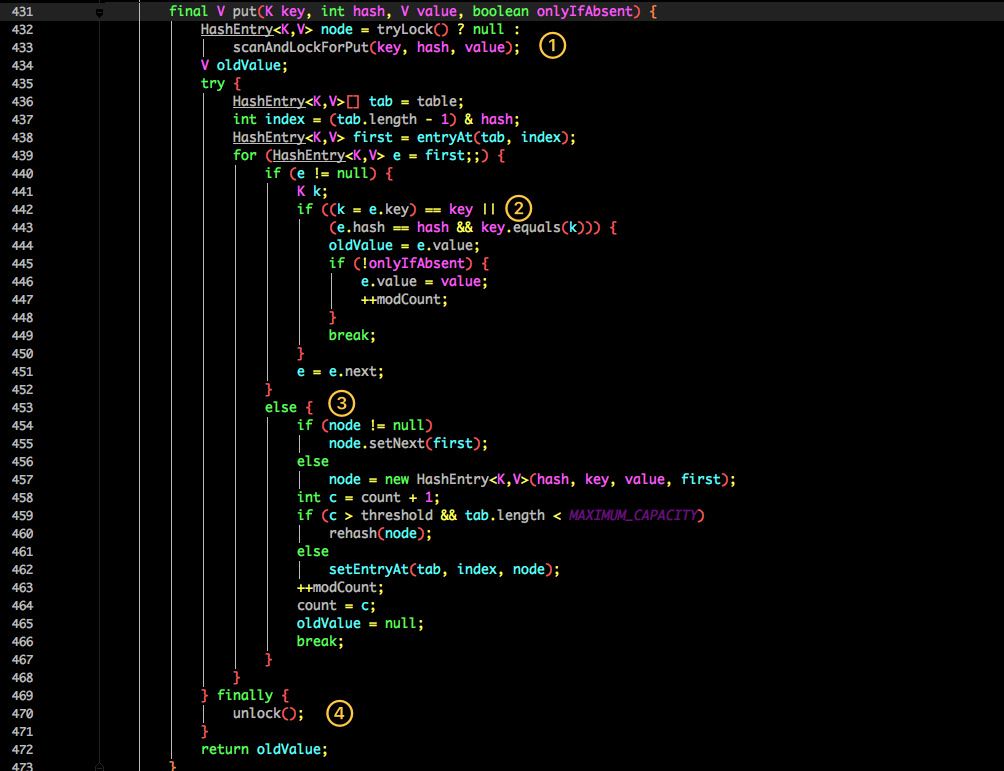
再结合图看看 put 的流程。
- 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
- 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
- 最后会解除在 1 中所获取当前 Segment 的锁。
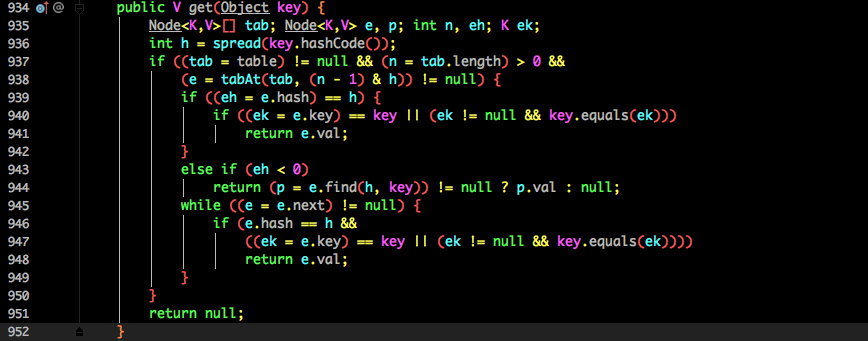
get 方法
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h = hash(key);long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;}
get 逻辑比较简单:
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
Base 1.8
1.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题。
那就是查询遍历链表效率太低。
因此 1.8 做了一些数据结构上的调整。
首先来看下底层的组成结构: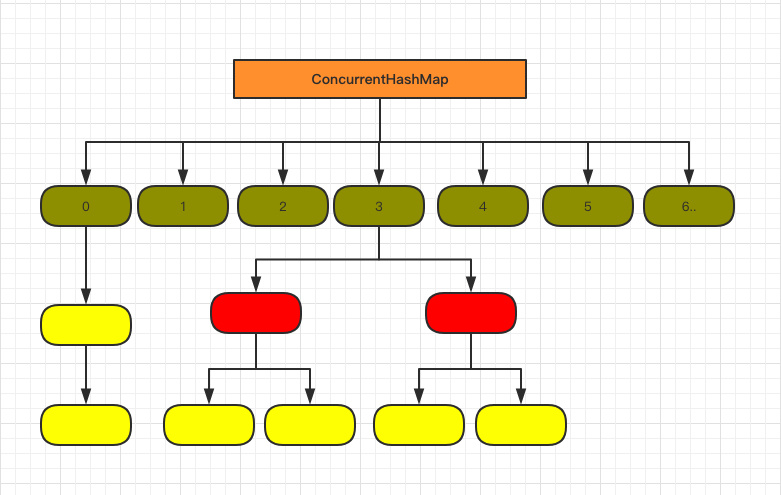
看起来是不是和 1.8 HashMap 结构类似?
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。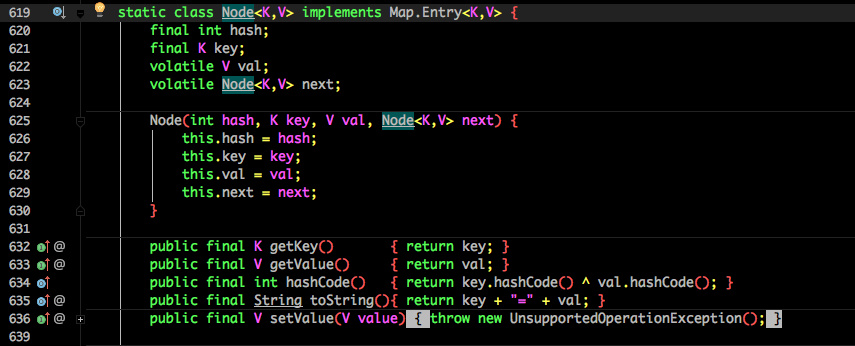
也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。
其中的 val next 都用了 volatile 修饰,保证了可见性。
put 方法
重点来看看 put 函数: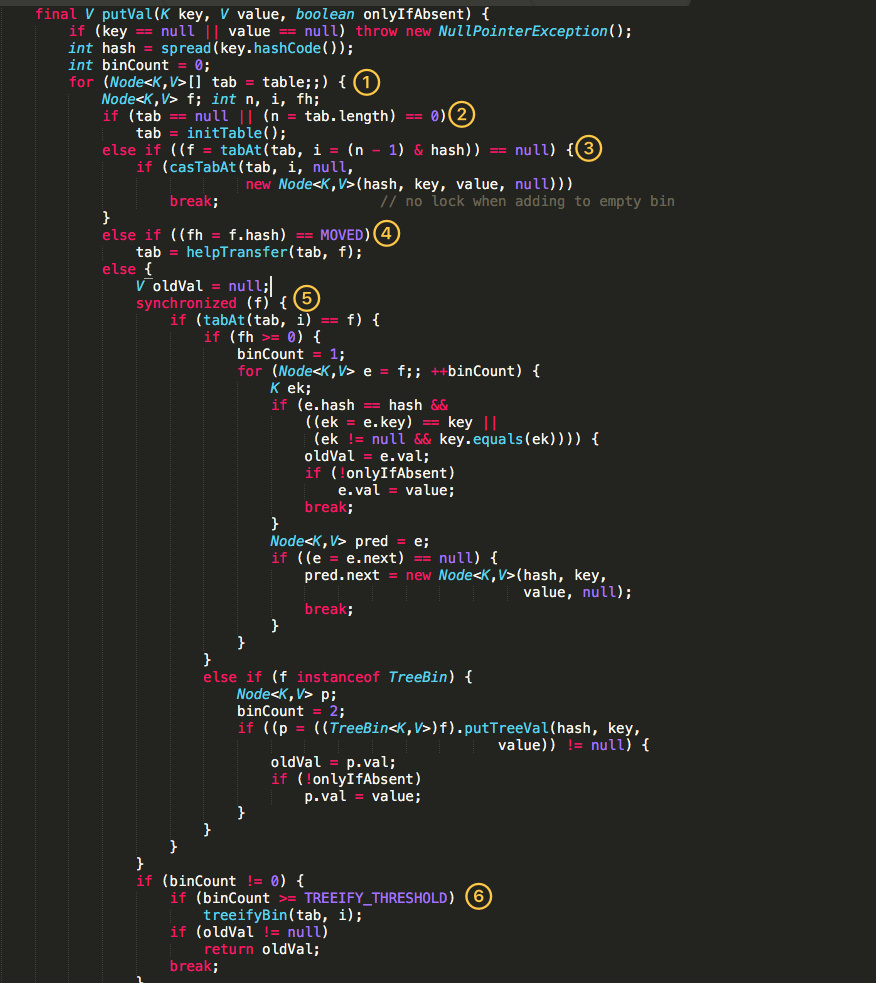
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
f即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树。get 方法
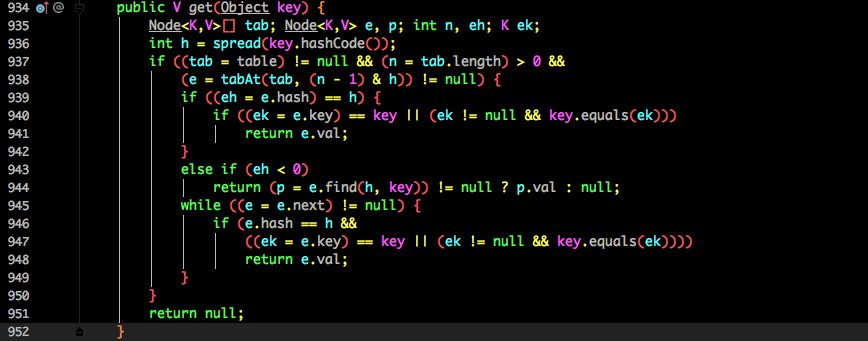
根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(
O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
三 CopyOnWriteArrayList
3.1 CopyOnWriteArrayList 简介
public class CopyOnWriteArrayList<E>extends Objectimplements List<E>, RandomAccess, Cloneable, Serializable
在很多应用场景中,读操作可能会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问List的内部数据,毕竟读取操作是安全的。
这和我们之前在多线程章节讲过 ReentrantReadWriteLock 读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。JDK中提供了 CopyOnWriteArrayList 类比相比于在读写锁的思想又更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。那它是怎么做的呢?
3.2 CopyOnWriteArrayList 是如何做到的?
CopyOnWriteArrayList 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
从 CopyOnWriteArrayList 的名字就能看出CopyOnWriteArrayList 是满足CopyOnWrite 的ArrayList,所谓CopyOnWrite 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
3.3 CopyOnWriteArrayList 读取和写入源码简单分析
3.3.1 CopyOnWriteArrayList 读取操作的实现
读取操作没有任何同步控制和锁操作,理由就是内部数组 array 不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。
/** The array, accessed only via getArray/setArray. */private transient volatile Object[] array;public E get(int index) {return get(getArray(), index);}@SuppressWarnings("unchecked")private E get(Object[] a, int index) {return (E) a[index];}final Object[] getArray() {return array;}
3.3.2 CopyOnWriteArrayList 写入操作的实现
CopyOnWriteArrayList 写入操作 add() 方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
/*** Appends the specified element to the end of this list.** @param e element to be appended to this list* @return {@code true} (as specified by {@link Collection#add})*/public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();//加锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();//释放锁}}
四 ConcurrentLinkedQueue
Java提供的线程安全的 Queue 可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。
从名字可以看出,ConcurrentLinkedQueue这个队列使用链表作为其数据结构.ConcurrentLinkedQueue 应该算是在高并发环境中性能最好的队列了。它之所有能有很好的性能,是因为其内部复杂的实现。
ConcurrentLinkedQueue 内部代码我们就不分析了,大家知道ConcurrentLinkedQueue 主要使用 CAS 非阻塞算法来实现线程安全就好了。
ConcurrentLinkedQueue 适合在对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的ConcurrentLinkedQueue来替代。
五 BlockingQueue
5.1 BlockingQueue 简单介绍
上面我们己经提到了 ConcurrentLinkedQueue 作为高性能的非阻塞队列。下面我们要讲到的是阻塞队列——BlockingQueue。阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
BlockingQueue 是一个接口,继承自 Queue,所以其实现类也可以作为 Queue 的实现来使用,而 Queue 又继承自 Collection 接口。下面是 BlockingQueue 的相关实现类: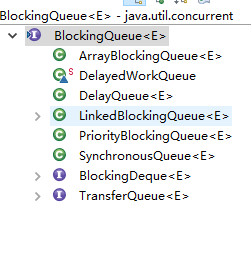
下面主要介绍一下:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,这三个 BlockingQueue 的实现类。
5.2 ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。ArrayBlockingQueue一旦创建,容量不能改变。其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞。
ArrayBlockingQueue 默认情况下不能保证线程访问队列的公平性,所谓公平性是指严格按照线程等待的绝对时间顺序,即最先等待的线程能够最先访问到 ArrayBlockingQueue。而非公平性则是指访问 ArrayBlockingQueue 的顺序不是遵守严格的时间顺序,有可能存在,当 ArrayBlockingQueue 可以被访问时,长时间阻塞的线程依然无法访问到 ArrayBlockingQueue。如果保证公平性,通常会降低吞吐量。如果需要获得公平性的 ArrayBlockingQueue,可采用如下代码:
private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);5.3 LinkedBlockingQueue
LinkedBlockingQueue 底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用,同样满足FIFO的特性,与ArrayBlockingQueue 相比起来具有更高的吞吐量,为了防止 LinkedBlockingQueue 容量迅速增,损耗大量内存。通常在创建LinkedBlockingQueue 对象时,会指定其大小,如果未指定,容量等于Integer.MAX_VALUE。
相关构造方法:
/***某种意义上的无界队列* Creates a {@code LinkedBlockingQueue} with a capacity of* {@link Integer#MAX_VALUE}.*/public LinkedBlockingQueue() {this(Integer.MAX_VALUE);}/***有界队列* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.** @param capacity the capacity of this queue* @throws IllegalArgumentException if {@code capacity} is not greater* than zero*/public LinkedBlockingQueue(int capacity) {if (capacity <= 0) throw new IllegalArgumentException();this.capacity = capacity;last = head = new Node<E>(null);}
5.4 PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。默认情况下元素采用自然顺序进行排序,也可以通过自定义类实现 compareTo() 方法来指定元素排序规则,或者初始化时通过构造器参数 Comparator 来指定排序规则。
PriorityBlockingQueue 并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
推荐文章:
《解读 Java 并发队列 BlockingQueue》
https://javadoop.com/post/java-concurrent-queue
六 ConcurrentSkipListMap
下面这部分内容参考了极客时间专栏《数据结构与算法之美》以及《实战Java高并发程序设计》。
为了引出ConcurrentSkipListMap,先带着大家简单理解一下跳表。
对于一个单链表,即使链表是有序的,如果我们想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,跳表就不一样了。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是 O(logn) 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
跳表的本质是同时维护了多个链表,并且链表是分层的,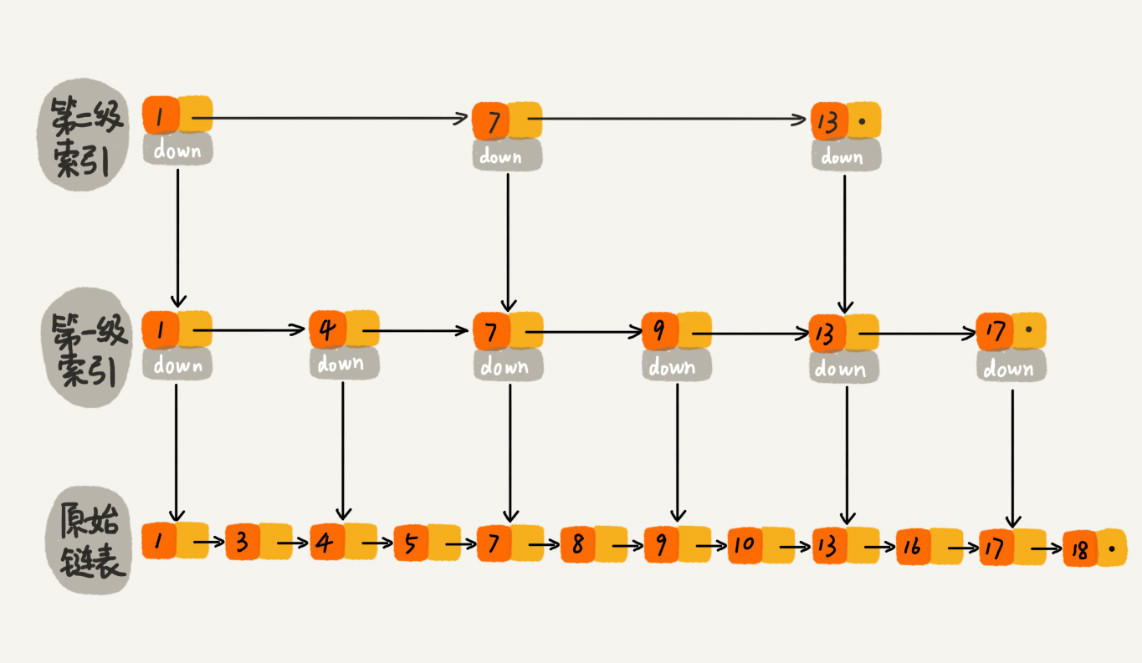
最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集。
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素18。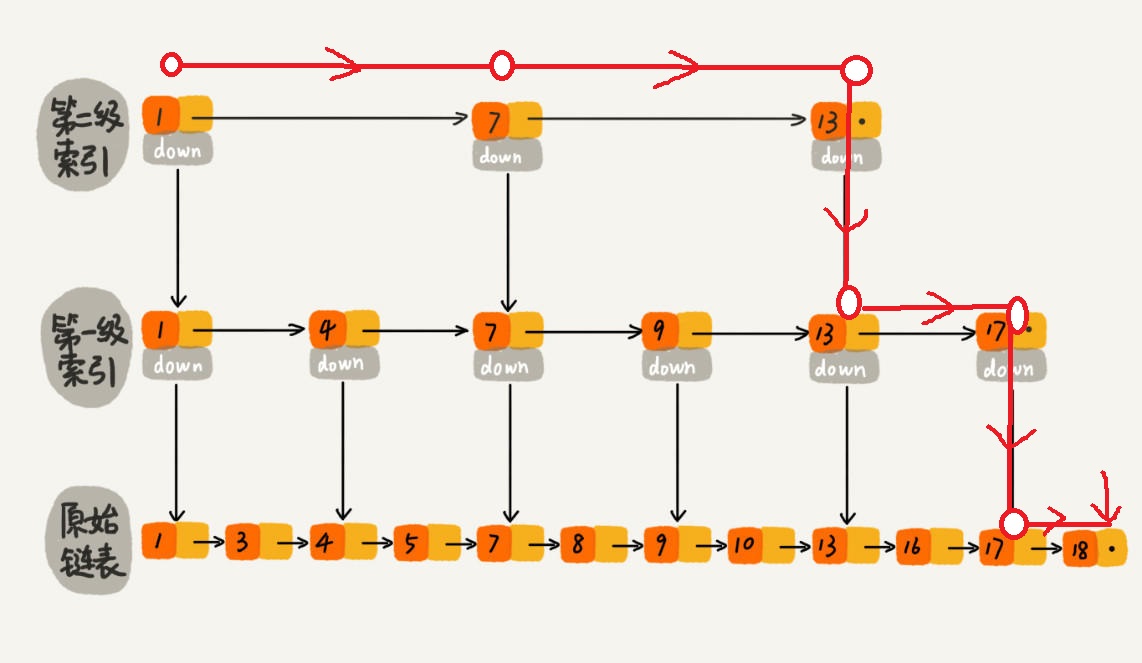
查找18 的时候原来需要遍历 18 次,现在只需要 7 次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
从上面很容易看出,跳表是一种利用空间换时间的算法。
使用跳表实现Map 和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。JDK 中实现这一数据结构的类是ConcurrentSkipListMap。
七 参考

若有收获,就点个赞吧
0 人点赞
