1. 引言
同步异步I/O,阻塞非阻塞I/O是程序员老生常谈的话题了,也是自己一直以来懵懵懂懂的一个话题。比如:何为同步异步?何为阻塞与非阻塞?二者的区别在哪里?阻塞在何处?为什么会有多种IO模型,分别用来解决问题?常用的框架采用的是何种I/O模型?各种IO模型的优劣势在哪里,适用于何种应用场景?
简而言之,对于I/O的认知,不能仅仅停留在字面上认识,了解内部玄机,才能深刻理解I/O,才能看清I/O相关问题的本质。
2. I/O 的定义
I/O 的全称是Input/Output。虽常谈及I/O,但想必你也一时不能给出一个完整的定义。搜索了谷歌,发现也尽是些冗长的论述。要想厘清I/O这个概念,我们需要从不同的视角去理解它。
2.1. 计算机视角
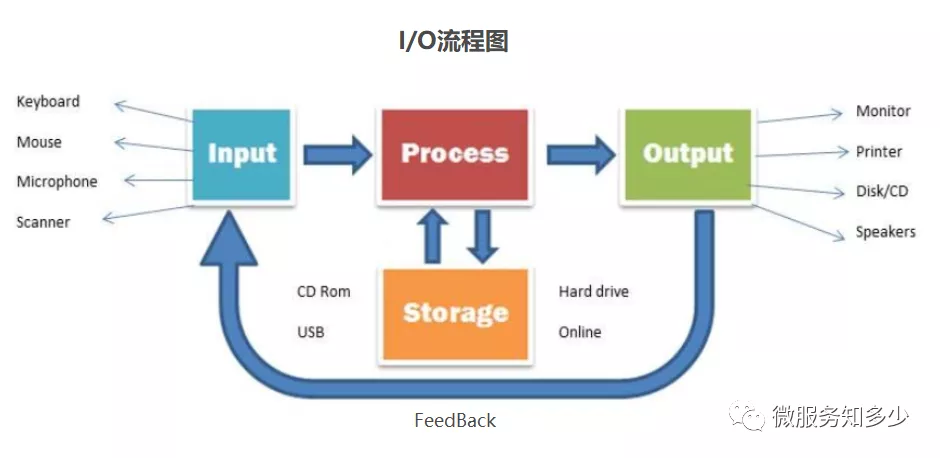
冯•诺伊曼计算机的基本思想中有提到计算机硬件组成应为五大部分:控制器,运算器,存储器,输入和输出。其中输入是指将数据输入到计算机的设备,比如键盘鼠标;输出是指从计算机中获取数据的设备,比如显示器;以及既是输入又是输出设备,硬盘,网卡等。
用户通过操作系统才能完成对计算机的操作。计算机启动时,第一个启动的程序是操作系统的内核,它将负责计算机的资源管理和进程的调度。换句话说:操作系统负责从输入设备读取数据并将数据写入到输出设备。
所以I/O之于计算机,有两层意思:
- I/O设备
- 对I/O设备的数据读写
对于一次I/O操作,必然涉及2个参与方,一个输入端,一个输出端,而又根据参与双方的设备类型,我们又可以分为磁盘I/O,网络I/O(一次网络的请求响应,网卡)等。
2.2. 程序视角
应用程序作为一个文件保存在磁盘中,只有加载到内存到成为一个进程才能运行。应用程序运行在计算机内存中,必然会涉及到数据交换,比如读写磁盘文件,访问数据库,调用远程API等等。但我们编写的程序并不能像操作系统内核一样直接进行I/O操作。
因为为了确保操作系统的安全稳定运行,操作系统启动后,将会开启保护模式:将内存分为内核空间(内核对应进程所在内存空间)和用户空间,进行内存隔离。我们构建的程序将运行在用户空间,用户空间无法操作内核空间,也就意味着用户空间的程序不能直接访问由内核管理的I/O,比如:硬盘、网卡等。
但操作系统向外提供API,其由各种类型的系统调用(System Call)组成,以提供安全的访问控制。所以应用程序要想访问内核管理的I/O,必须通过调用内核提供的系统调用(system call)进行间接访问。
所以I/O之于应用程序来说,强调的通过向内核发起系统调用完成对I/O的间接访问。换句话说应用程序发起的一次IO操作实际包含两个阶段:
- IO调用阶段:应用程序进程向内核发起系统调用
- IO执行阶段:内核执行IO操作并返回
- 准备数据阶段:内核等待I/O设备准备好数据
- 拷贝数据阶段:将数据从内核缓冲区拷贝到用户空间缓冲区
- 准备数据阶段:内核等待I/O设备准备好数据
怎么理解准备数据阶段呢?对于写请求:等待系统调用的完整请求数据,并写入内核缓冲区;对于读请求:等待系统调用的完整请求数据;(若请求数据不存在于内核缓冲区)则将外围设备的数据读入到内核缓冲区。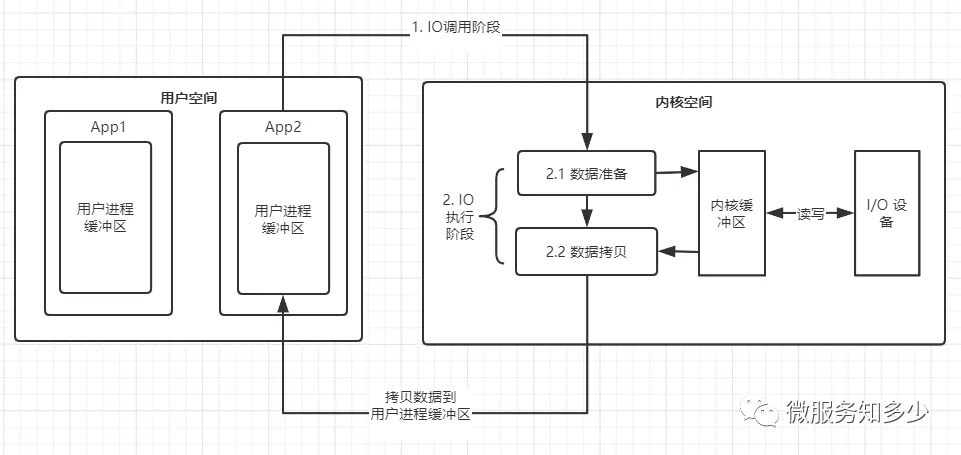
而应用程序进程在发起IO调用至内核执行IO返回之前,应用程序进程/线程所处状态,就是我们下面要讨论的第二个话题阻塞IO与非阻塞IO。
3. IO 模型之阻塞I/O(BIO)
应用程序中进程在发起IO调用后至内核执行IO操作返回结果之前,若发起系统调用的线程一直处于等待状态,则此次IO操作为阻塞IO。阻塞IO简称BIO,Blocking IO。其处理流程如下图所示: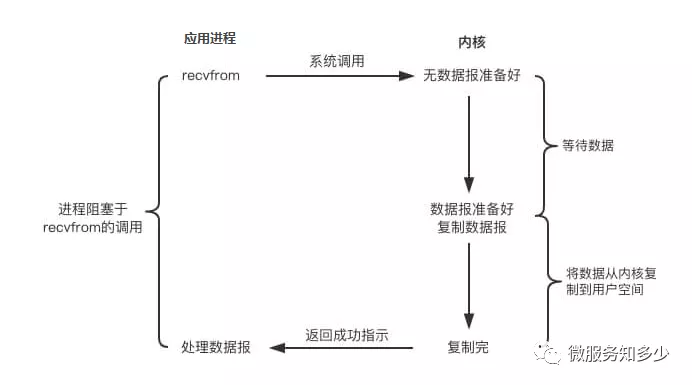
从上图可知当用户进程发起IO系统调用后,内核从准备数据到拷贝数据到用户空间的两个阶段期间用户调用线程选择阻塞等待数据返回。
因此BIO带来了一个问题:如果内核数据需要耗时很久才能准备好,那么用户进程将被阻塞,浪费性能。为了提升应用的性能,虽然可以通过多线程来提升性能,但线程的创建依然会借助系统调用,同时多线程会导致频繁的线程上下文的切换,同样会影响性能。所以要想解决BIO带来的问题,我们就得看到问题的本质,那就是阻塞二字。
4. IO 模型之非阻塞I/O(NIO)
那解决方案自然也容易想到,将阻塞变为非阻塞,那就是用户进程在发起系统调用时指定为非阻塞,内核接收到请求后,就会立即返回,然后用户进程通过轮询的方式来拉取处理结果。也就是如下图所示: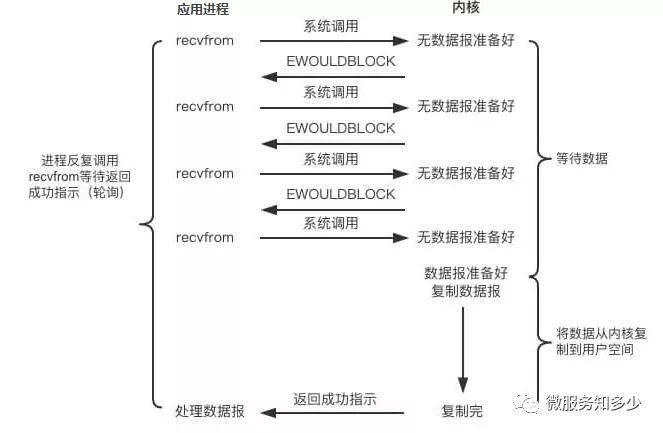
应用程序中进程在发起IO调用后至内核执行IO操作返回结果之前,若发起系统调用的线程不会等待而是立即返回,则此次IO操作为非阻塞IO模型。非阻塞IO简称NIO,Non-Blocking IO。
然而,非阻塞IO虽然相对于阻塞IO大幅提升了性能,但依旧不是完美的解决方案,其依然存在性能问题,也就是频繁的轮询导致频繁的系统调用,会耗费大量的CPU资源。比如当并发很高时,假设有1000个并发,那么单位时间循环内将会有1000次系统调用去轮询执行结果,而实际上可能只有2个请求结果执行完毕,这就会有998次无效的系统调用,造成严重的性能浪费。有问题就要解决,那NIO问题的本质就是频繁轮询导致的无效系统调用。
5. IO模型之IO多路复用
解决NIO的思路就是降解无效的系统调用,如何降解呢?我们一起来看看以下几种IO多路复用的解决思路。
5.1. IO多路复用之select/poll
Select是内核提供的系统调用,它支持一次查询多个系统调用的可用状态,当任意一个结果状态可用时就会返回,用户进程再发起一次系统调用进行数据读取。换句话说,就是NIO中N次的系统调用,借助Select,只需要发起一次系统调用就够了。其IO流程如下所示: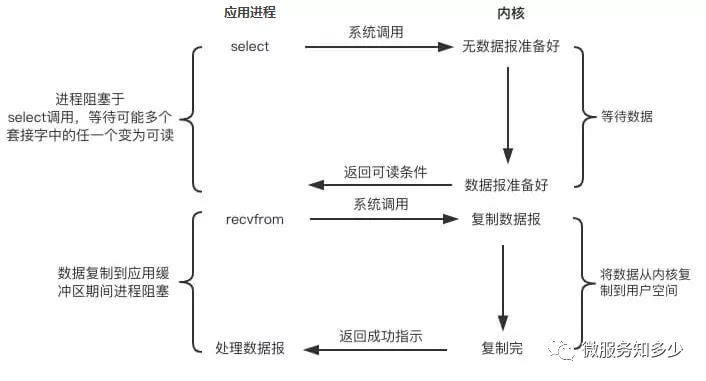
但是,select有一个限制,就是存在连接数限制,针对于此,又提出了poll。其与select相比,主要是解决了连接限制。
select/epoll 虽然解决了NIO重复无效系统调用用的问题,但同时又引入了新的问题。问题是:
- 用户空间和内核空间之间,大量的数据拷贝
- 内核循环遍历IO状态,浪费CPU时间
换句话说,select/poll虽然减少了用户进程的发起的系统调用,但内核的工作量只增不减。在高并发的情况下,内核的性能问题依旧。所以select/poll的问题本质是:内核存在无效的循环遍历。
5.2. IO多路复用之epoll
针对select/pool引入的问题,我们把解决问题的思路转回到内核上,如何减少内核重复无效的循环遍历呢?变主动为被动,基于事件驱动来实现。其流程图如下所示: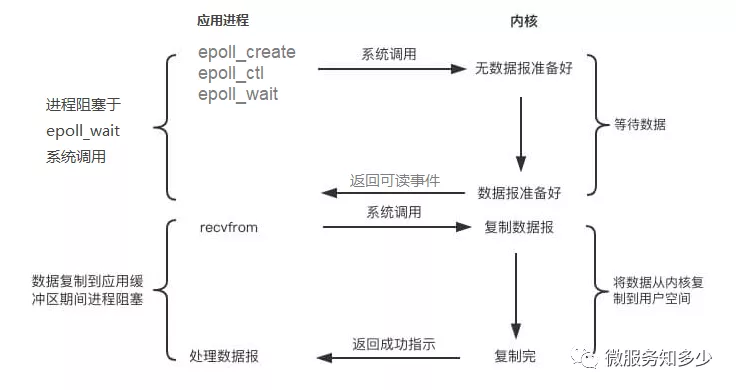
epoll相较于select/poll,多了两次系统调用,其中epollcreate建立与内核的连接,epollctl注册事件,epoll_wait阻塞用户进程,等待IO事件。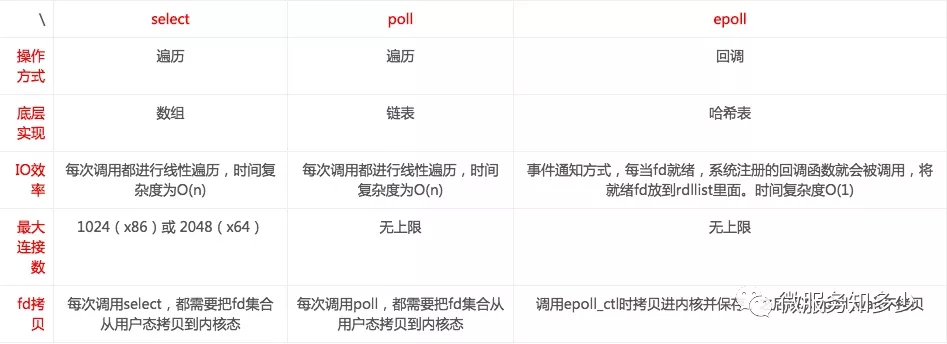
epoll,已经大大优化了IO的执行效率,但在IO执行的第一阶段:数据准备阶段都还是被阻塞的。所以这是一个可以继续优化的点。
6. IO 模型之信号驱动IO(SIGIO)
信号驱动IO与BIO和NIO最大的区别就在于,在IO执行的数据准备阶段,不会阻塞用户进程。如下图所示:当用户进程需要等待数据的时候,会向内核发送一个信号,告诉内核我要什么数据,然后用户进程就继续做别的事情去了,而当内核中的数据准备好之后,内核立马发给用户进程一个信号,说”数据准备好了,快来查收“,用户进程收到信号之后,立马调用recvfrom,去查收数据。
乍一看,信号驱动式I/O模型有种异步操作的感觉,但是在IO执行的第二阶段,也就是将数据从内核空间复制到用户空间这个阶段,用户进程还是被阻塞的。
综上,你会发现,不管是BIO还是NIO还是SIGIO,它们最终都会被阻塞在IO执行的第二阶段。那如果能将IO执行的第二阶段变成非阻塞,那就完美了。
7. IO 模型之异步IO(AIO)
异步IO真正实现了IO全流程的非阻塞。用户进程发出系统调用后立即返回,内核等待数据准备完成,然后将数据拷贝到用户进程缓冲区,然后发送信号告诉用户进程IO操作执行完毕(与SIGIO相比,一个是发送信号告诉用户进程数据准备完毕,一个是IO执行完毕)。其流程如下: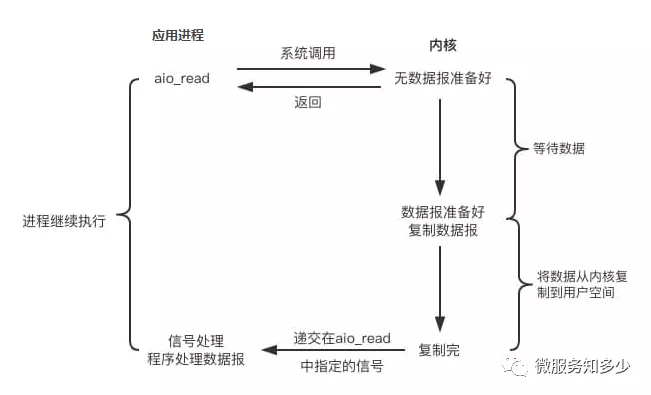
所以,之所以称为异步IO,取决于IO执行的第二阶段是否阻塞。因此前面讲的BIO,NIO和SIGIO均为同步IO。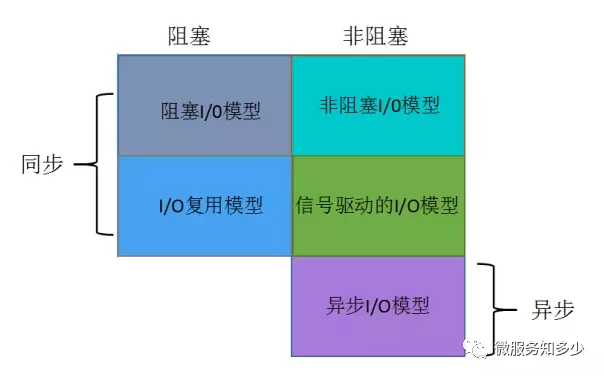
8. 总结
梳理完这些IO模型后,之前一直处于懵懂状态的阻塞,非阻塞,同步异步IO,终于算是有个概念了。同时也纠正了自己一直以来的误解,所以一路走来,愈发觉得返璞归真的重要性,只有如此,才能在快速更迭的技术演进中,以不变应万变。
本文综合多方资料写就,难免纰漏,但只有写下来,才能得以指正。所以,烦请各位看官不吝赐教。
参考资料:
- 程序员应该这样理解IO
- IO复用模型同步,异步,阻塞,非阻塞及实例详解
- 服务器网络编程之 IO 模型
- http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html
- 同步I/O(阻塞I/O,非阻塞I/O),异步I/O
- 马士兵:权威讲解nio,epoll,多路复用
- Linux 内核详解以及内核缓冲区技术

若有收获,就点个赞吧
0 人点赞
